







目录
2.1 Azkaban Executor Server的启动
一、全流程调度——Azkaban基础
1、Azkaban概论
1.1 为什么需要工作流调度系统

1.2 常见工作流调度系统
1)简单的任务调度:直接使用Linux的Crontab来定义;
2)复杂的任务调度:开发调度平台或使用现成的开源调度系统,比如Ooize、Azkaban、 Airflow、DolphinScheduler等。
1.3 Azkaban与Oozie对比
总体来说,Ooize相比Azkaban是一个重量级的任务调度系统,功能全面,但配置使用也更复杂。如果可以不在意某些功能的缺失,轻量级调度器Azkaban是很不错的候选对象。
2、Azkaban部署
部分配置详情见视频及文档
2.1 Azkaban Executor Server的启动

启动:bin/start-exec.sh
激活(可以直接在102上激活):
[atguigu@hadoop102 azkaban-exec]$ curl -G "hadoop102:12321/executor?action=activate" && echo
[atguigu@hadoop103 azkaban-exec]$ curl -G "hadoop103:12321/executor?action=activate" && echo
[atguigu@hadoop104 azkaban-exec]$ curl -G "hadoop104:12321/executor?action=activate" && echo
2.2 Web Server的启动

登陆用户是自己创建的
3、 Work Flow案例实操
3.1 YAML语言简介

3.2 HelloWorld案例

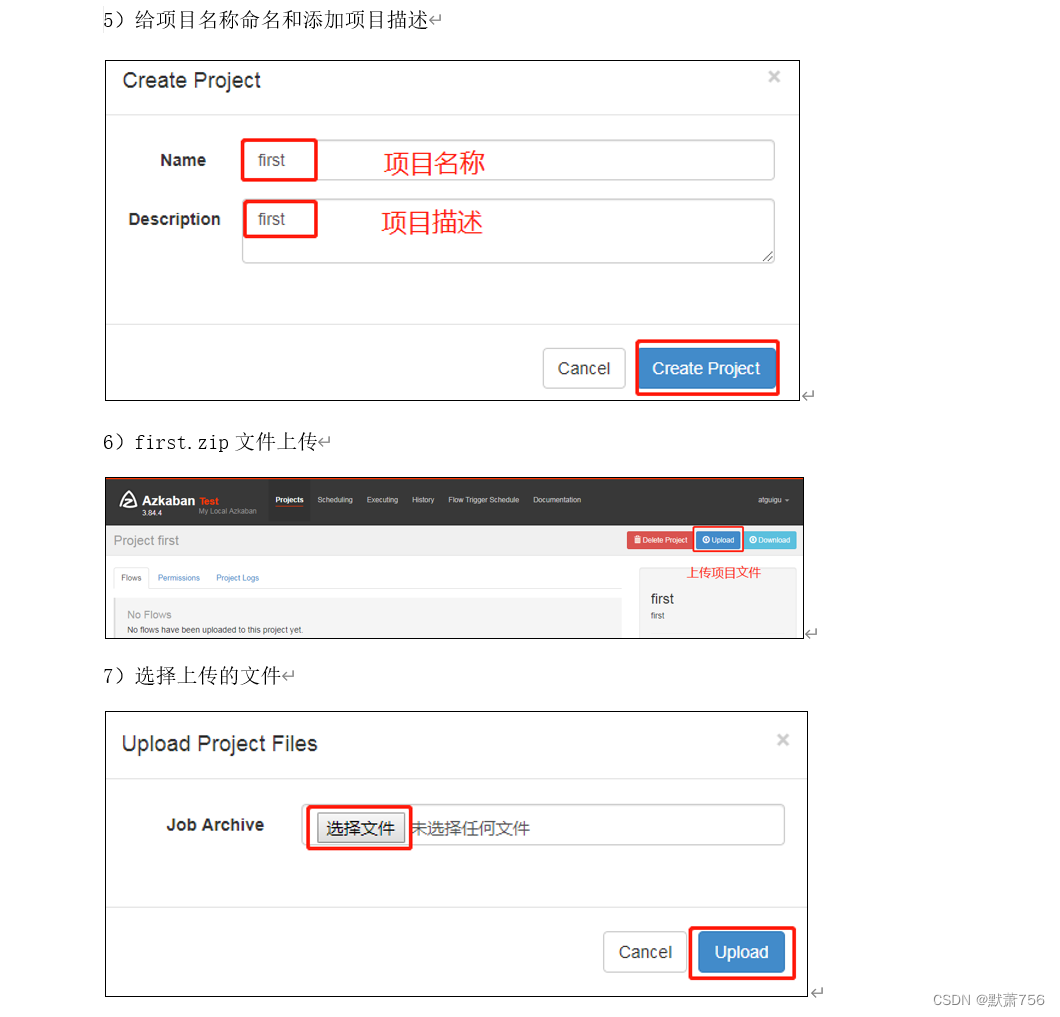

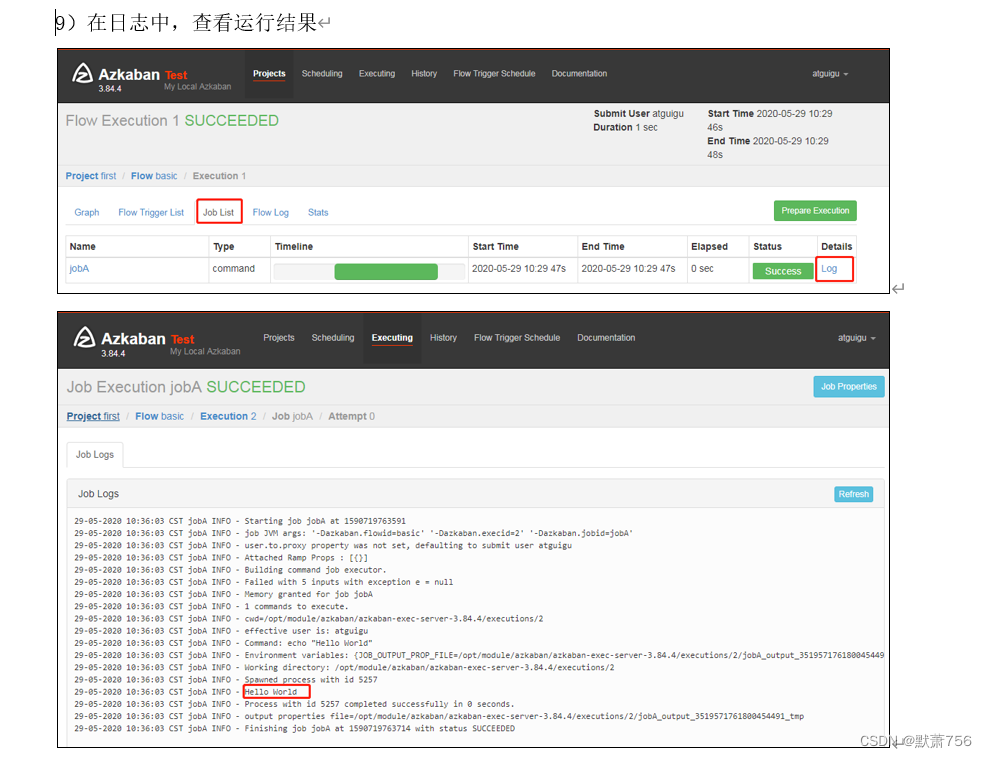
3.3 作业依赖案例

3.4 自动失败重试案例

这里的command命令执行的是一个不存在的脚本,因此会失败
自动失败重试只需要在你需要重试的脚本的config下加入retries和retry.backoff参数即可
注意:

3.5 手动失败重试案例
需求:JobA=》JobB(依赖于A)=》JobC=》JobD=》JobE=》JobF。生产环境,任何Job都有可能挂掉,可以根据需求执行想要执行的Job。
具体步骤:
1)编译配置流
nodes:
- name: JobA
type: command
config:
command: echo "This is JobA."
- name: JobB
type: command
dependsOn:
- JobA
config:
command: echo "This is JobB."
- name: JobC
type: command
dependsOn:
- JobB
config:
command: echo "This is JobC."
- name: JobD
type: command
dependsOn:
- JobC
config:
command: echo "This is JobD."
- name: JobE
type: command
dependsOn:
- JobD
config:
command: echo "This is JobE."
- name: JobF
type: command
dependsOn:
- JobE
config:
command: echo "This is JobF."
2)将修改后的basic.flow和azkaban.project压缩成five.zip文件
3)重复2.3.1节HelloWorld后续步骤。
方法1:

执行完毕后的位置点这个就可以跳过之前成功的地方
方法2:
返回主页

这里点disable就可以跳过
Enable和Disable下面都分别有如下参数:
Parents:该作业的上一个任务
Ancestors:该作业前的所有任务
Children:该作业后的一个任务
Descendents:该作业后的所有任务
Enable All:所有的任务
二、全流程调度——Azkaban进阶
1、JavaProcess作业类型案例
Azkaban内置任务类型有两种:command类型和JavaProcess
JavaProcess类型可以运行一个自定义主类方法,type类型为javaprocess,可用的配置为:
Xms:最小堆
Xmx:最大堆
classpath:类路径
java.class:要运行的Java对象,其中必须包含Main方法
main.args:main方法的参数
案例:
1)新建一个azkaban的maven工程
2)创建包名:com.atguigu
3)创建AzTest类
package com.atguigu;
public class AzTest {
public static void main(String[] args) {
System.out.println("This is for testing!");
}
}
4)打包成jar包azkaban-1.0-SNAPSHOT.jar
5)新建testJava.flow,内容如下
nodes:
- name: test_java
type: javaprocess
config:
Xms: 96M
Xmx: 200M
java.class: com.atguigu.AzTest

2、条件工作流案例
条件工作流功能允许用户自定义执行条件来决定是否运行某些Job。条件可以由当前Job的父Job输出的运行时参数构成,也可以使用预定义宏。在这些条件下,用户可以在确定Job执行逻辑时获得更大的灵活性,例如,只要父Job之一成功,就可以运行当前Job。
2.1 运行时参数案例
1)基本原理
(1)父Job将参数写入JOB_OUTPUT_PROP_FILE环境变量所指向的文件
(2)子Job使用 ${jobName:param}来获取父Job输出的参数并定义执行条件
2)支持的条件运算符:
(1)== 等于
(2)!= 不等于
(3)> 大于
(4)>= 大于等于
(5)< 小于
(6)<= 小于等于
(7)&& 与
(8)|| 或
(9)! 非
3)案例:
需求:
JobA执行一个shell脚本。
JobB执行一个shell脚本,但JobB不需要每天都执行,而只需要每个周一执行。

2.2 预定义宏案例
Azkaban中预置了几个特殊的判断条件,称为预定义宏。
预定义宏会根据所有父Job的完成情况进行判断,再决定是否执行。可用的预定义宏如下:
(1)all_success: 表示父Job全部成功才执行(默认)
(2)all_done:表示父Job全部完成才执行
(3)all_failed:表示父Job全部失败才执行
(4)one_success:表示父Job至少一个成功才执行
(5)one_failed:表示父Job至少一个失败才执行
1)案例
需求:
JobA执行一个shell脚本
JobB执行一个shell脚本
JobC执行一个shell脚本,要求JobA、JobB中有一个成功即可执行

3、定时执行案例


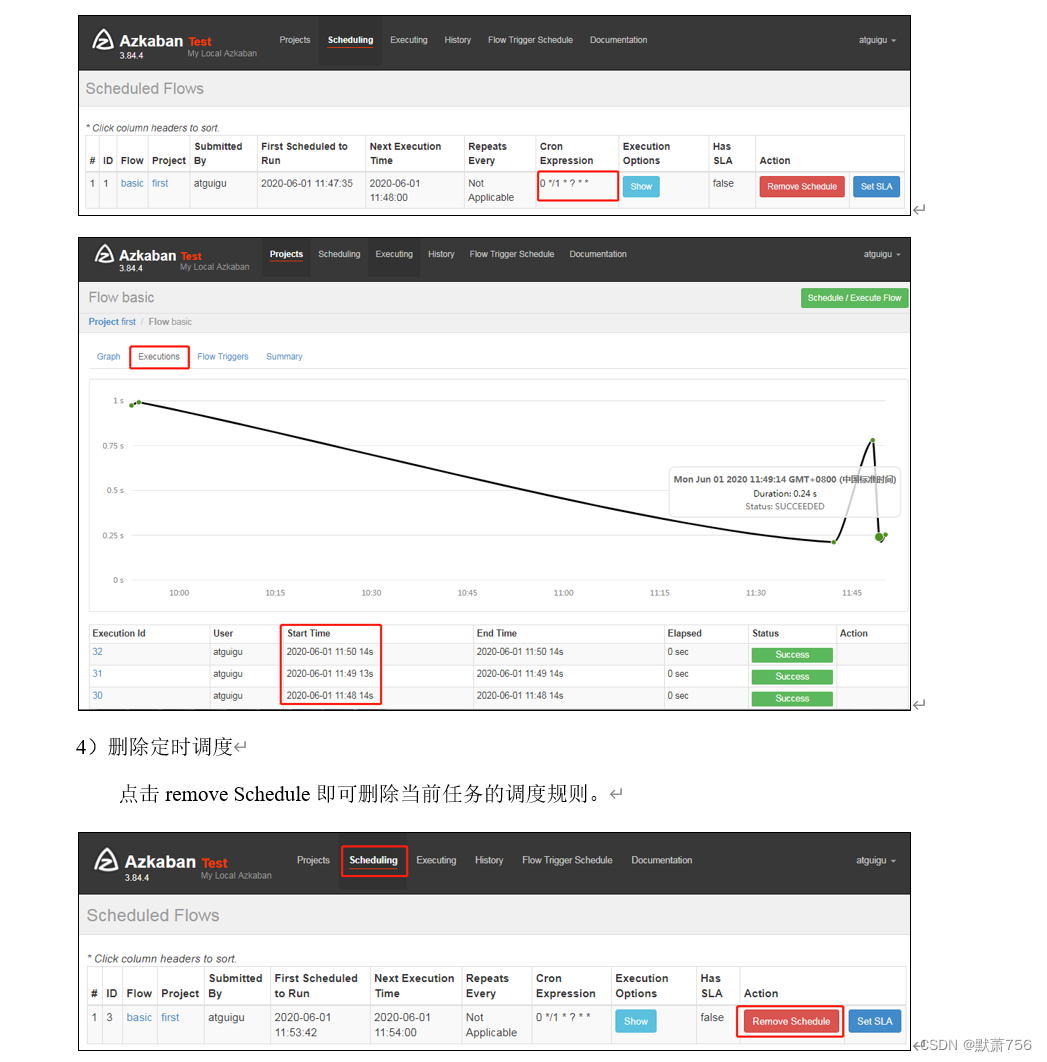
4、邮箱报警案例
4.1 注册邮箱

这里也可以使用qq邮箱等


5、电话报警案例
5.1 第三方告警平台集成
有时任务执行失败后邮件报警接收不及时,因此可能需要其他报警方式,比如电话报警。如有类似需求,可与第三方告警平台进行集成,例如睿象云。



6、Azkaban多Executor模式注意事项
Azkaban多Executor模式是指,在集群中多个节点部署Executor。在这种模式下, Azkaban web Server会根据策略,选取其中一个Executor去执行任务。
为确保所选的Executor能够准确的执行任务,我们须在以下两种方案任选其一,推荐使用方案二。
方案一:指定特定的Executor(hadoop102)去执行任务。
1)在MySQL中azkaban数据库executors表中,查询hadoop102上的Executor的id。
mysql> use azkaban;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> select * from executors;
+----+-----------+-------+--------+
| id | host | port | active |
+----+-----------+-------+--------+
| 1 | hadoop103 | 35985 | 1 |
| 2 | hadoop104 | 36363 | 1 |
| 3 | hadoop102 | 12321 | 1 |
+----+-----------+-------+--------+
3 rows in set (0.00 sec)
2)在执行工作流程时加入useExecutor属性,如下

方案二:在Executor所在所有节点部署任务所需脚本和应用。
在实际中方案一不推荐使用
三、全流程调度——Mysql与Sqoop
1、创建MySQL数据库和表
1)创建gmall_report数据库

注:SQL语句
CREATE DATABASE `gmall_report` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'2)创建表
(1)访客统计
DROP TABLE IF EXISTS ads_visit_stats;
CREATE TABLE `ads_visit_stats` (
`dt` DATE NOT NULL COMMENT '统计日期',
`is_new` VARCHAR(255) NOT NULL COMMENT '新老标识,1:新,0:老',
`recent_days` INT NOT NULL COMMENT '最近天数,1:最近1天,7:最近7天,30:最近30天',
`channel` VARCHAR(255) NOT NULL COMMENT '渠道',
`uv_count` BIGINT(20) DEFAULT NULL COMMENT '日活(访问人数)',
`duration_sec` BIGINT(20) DEFAULT NULL COMMENT '页面停留总时长',
`avg_duration_sec` BIGINT(20) DEFAULT NULL COMMENT '一次会话,页面停留平均时长',
`page_count` BIGINT(20) DEFAULT NULL COMMENT '页面总浏览数',
`avg_page_count` BIGINT(20) DEFAULT NULL COMMENT '一次会话,页面平均浏览数',
`sv_count` BIGINT(20) DEFAULT NULL COMMENT '会话次数',
`bounce_count` BIGINT(20) DEFAULT NULL COMMENT '跳出数',
`bounce_rate` DECIMAL(16,2) DEFAULT NULL COMMENT '跳出率',
PRIMARY KEY (`dt`,`recent_days`,`is_new`,`channel`)
) ENGINE=INNODB DEFAULT CHARSET=utf8;
(2)页面路径分析
DROP TABLE IF EXISTS ads_page_path;
CREATE TABLE `ads_page_path` (
`dt` DATE NOT NULL COMMENT '统计日期',
`recent_days` BIGINT(20) NOT NULL COMMENT '最近天数,1:最近1天,7:最近7天,30:最近30天',
`source` VARCHAR(255) DEFAULT NULL COMMENT '跳转起始页面',
`target` VARCHAR(255) DEFAULT NULL COMMENT '跳转终到页面',
`path_count` BIGINT(255) DEFAULT NULL COMMENT '跳转次数',
UNIQUE KEY (`dt`,`recent_days`,`source`,`target`) USING BTREE
) ENGINE=INNODB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
(3)用户统计
DROP TABLE IF EXISTS ads_user_total;
CREATE TABLE `ads_user_total` (
`dt` DATE NOT NULL COMMENT '统计日期',
`recent_days` BIGINT(20) NOT NULL COMMENT '最近天数,0:累积值,1:最近1天,7:最近7天,30:最近30天',
`new_user_count` BIGINT(20) DEFAULT NULL COMMENT '新注册用户数',
`new_order_user_count` BIGINT(20) DEFAULT NULL COMMENT '新增下单用户数',
`order_final_amount` DECIMAL(16,2) DEFAULT NULL COMMENT '下单总金额',
`order_user_count` BIGINT(20) DEFAULT NULL COMMENT '下单用户数',
`no_order_user_count` BIGINT(20) DEFAULT NULL COMMENT '未下单用户数(具体指活跃用户中未下单用户)',
PRIMARY KEY (`dt`,`recent_days`)
) ENGINE=INNODB DEFAULT CHARSET=utf8;
(4)用户变动统计
DROP TABLE IF EXISTS ads_user_change;
CREATE TABLE `ads_user_change` (
`dt` DATE NOT NULL COMMENT '统计日期',
`user_churn_count` BIGINT(20) DEFAULT NULL COMMENT '流失用户数',
`user_back_count` BIGINT(20) DEFAULT NULL COMMENT '回流用户数',
PRIMARY KEY (`dt`)
) ENGINE=INNODB DEFAULT CHARSET=utf8;
(5)用户行为漏斗分析
DROP TABLE IF EXISTS ads_user_action;
CREATE TABLE `ads_user_action` (
`dt` DATE NOT NULL COMMENT '统计日期',
`recent_days` BIGINT(20) NOT NULL COMMENT '最近天数,1:最近1天,7:最近7天,30:最近30天',
`home_count` BIGINT(20) DEFAULT NULL COMMENT '浏览首页人数',
`good_detail_count` BIGINT(20) DEFAULT NULL COMMENT '浏览商品详情页人数',
`cart_count` BIGINT(20) DEFAULT NULL COMMENT '加入购物车人数',
`order_count` BIGINT(20) DEFAULT NULL COMMENT '下单人数',
`payment_count` BIGINT(20) DEFAULT NULL COMMENT '支付人数',
PRIMARY KEY (`dt`,`recent_days`) USING BTREE
) ENGINE=INNODB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
(6)用户留存率分析
DROP TABLE IF EXISTS ads_user_retention;
CREATE TABLE `ads_user_retention` (
`dt` DATE DEFAULT NULL COMMENT '统计日期',
`create_date` VARCHAR(255) NOT NULL COMMENT '用户新增日期',
`retention_day` BIGINT(20) NOT NULL COMMENT '截至当前日期留存天数',
`retention_count` BIGINT(20) DEFAULT NULL COMMENT '留存用户数量',
`new_user_count` BIGINT(20) DEFAULT NULL COMMENT '新增用户数量',
`retention_rate` DECIMAL(16,2) DEFAULT NULL COMMENT '留存率',
PRIMARY KEY (`create_date`,`retention_day`) USING BTREE
) ENGINE=INNODB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
(7)订单统计
DROP TABLE IF EXISTS ads_order_total;
CREATE TABLE `ads_order_total` (
`dt` DATE NOT NULL COMMENT '统计日期',
`recent_days` BIGINT(20) NOT NULL COMMENT '最近天数,1:最近1天,7:最近7天,30:最近30天',
`order_count` BIGINT(255) DEFAULT NULL COMMENT '订单数',
`order_amount` DECIMAL(16,2) DEFAULT NULL COMMENT '订单金额',
`order_user_count` BIGINT(255) DEFAULT NULL COMMENT '下单人数',
PRIMARY KEY (`dt`,`recent_days`)
) ENGINE=INNODB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
(8)各省份订单统计
DROP TABLE IF EXISTS ads_order_by_province;
CREATE TABLE `ads_order_by_province` (
`dt` DATE NOT NULL,
`recent_days` BIGINT(20) NOT NULL COMMENT '最近天数,1:最近1天,7:最近7天,30:最近30天',
`province_id` VARCHAR(255) NOT NULL COMMENT '统计日期',
`province_name` VARCHAR(255) DEFAULT NULL COMMENT '省份名称',
`area_code` VARCHAR(255) DEFAULT NULL COMMENT '地区编码',
`iso_code` VARCHAR(255) DEFAULT NULL COMMENT '国际标准地区编码',
`iso_code_3166_2` VARCHAR(255) DEFAULT NULL COMMENT '国际标准地区编码',
`order_count` BIGINT(20) DEFAULT NULL COMMENT '订单数',
`order_amount` DECIMAL(16,2) DEFAULT NULL COMMENT '订单金额',
PRIMARY KEY (`dt`, `recent_days` ,`province_id`) USING BTREE
) ENGINE=INNODB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
(9)品牌复购率
DROP TABLE IF EXISTS ads_repeat_purchase;
CREATE TABLE `ads_repeat_purchase` (
`dt` DATE NOT NULL COMMENT '统计日期',
`recent_days` BIGINT(20) NOT NULL COMMENT '最近天数,1:最近1天,7:最近7天,30:最近30天',
`tm_id` VARCHAR(255) NOT NULL COMMENT '品牌ID',
`tm_name` VARCHAR(255) DEFAULT NULL COMMENT '品牌名称',
`order_repeat_rate` DECIMAL(16,2) DEFAULT NULL COMMENT '复购率',
PRIMARY KEY (`dt` ,`recent_days`,`tm_id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
(10)商品统计
DROP TABLE IF EXISTS ads_order_spu_stats;
CREATE TABLE `ads_order_spu_stats` (
`dt` DATE NOT NULL COMMENT '统计日期',
`recent_days` BIGINT(20) NOT NULL COMMENT '最近天数,1:最近1天,7:最近7天,30:最近30天',
`spu_id` VARCHAR(255) NOT NULL COMMENT '商品ID',
`spu_name` VARCHAR(255) DEFAULT NULL COMMENT '商品名称',
`tm_id` VARCHAR(255) NOT NULL COMMENT '品牌ID',
`tm_name` VARCHAR(255) DEFAULT NULL COMMENT '品牌名称',
`category3_id` VARCHAR(255) NOT NULL COMMENT '三级品类ID',
`category3_name` VARCHAR(255) DEFAULT NULL COMMENT '三级品类名称',
`category2_id` VARCHAR(255) NOT NULL COMMENT '二级品类ID',
`category2_name` VARCHAR(255) DEFAULT NULL COMMENT '二级品类名称',
`category1_id` VARCHAR(255) NOT NULL COMMENT '一级品类ID',
`category1_name` VARCHAR(255) NOT NULL COMMENT '一级品类名称',
`order_count` BIGINT(20) DEFAULT NULL COMMENT '订单数',
`order_amount` DECIMAL(16,2) DEFAULT NULL COMMENT '订单金额',
PRIMARY KEY (`dt`,`recent_days`,`spu_id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8;
(11)活动统计
DROP TABLE IF EXISTS ads_activity_stats;
CREATE TABLE `ads_activity_stats` (
`dt` DATE NOT NULL COMMENT '统计日期',
`activity_id` VARCHAR(255) NOT NULL COMMENT '活动ID',
`activity_name` VARCHAR(255) DEFAULT NULL COMMENT '活动名称',
`start_date` DATE DEFAULT NULL COMMENT '开始日期',
`order_count` BIGINT(11) DEFAULT NULL COMMENT '参与活动订单数',
`order_original_amount` DECIMAL(16,2) DEFAULT NULL COMMENT '参与活动订单原始金额',
`order_final_amount` DECIMAL(16,2) DEFAULT NULL COMMENT '参与活动订单最终金额',
`reduce_amount` DECIMAL(16,2) DEFAULT NULL COMMENT '优惠金额',
`reduce_rate` DECIMAL(16,2) DEFAULT NULL COMMENT '补贴率',
PRIMARY KEY (`dt`,`activity_id` )
) ENGINE=INNODB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
(12)优惠券统计
DROP TABLE IF EXISTS ads_coupon_stats;
CREATE TABLE `ads_coupon_stats` (
`dt` DATE NOT NULL COMMENT '统计日期',
`coupon_id` VARCHAR(255) NOT NULL COMMENT '优惠券ID',
`coupon_name` VARCHAR(255) DEFAULT NULL COMMENT '优惠券名称',
`start_date` DATE DEFAULT NULL COMMENT '开始日期',
`rule_name` VARCHAR(200) DEFAULT NULL COMMENT '优惠规则',
`get_count` BIGINT(20) DEFAULT NULL COMMENT '领取次数',
`order_count` BIGINT(20) DEFAULT NULL COMMENT '使用(下单)次数',
`expire_count` BIGINT(20) DEFAULT NULL COMMENT '过期次数',
`order_original_amount` DECIMAL(16,2) DEFAULT NULL COMMENT '使用优惠券订单原始金额',
`order_final_amount` DECIMAL(16,2) DEFAULT NULL COMMENT '使用优惠券订单最终金额',
`reduce_amount` DECIMAL(16,2) DEFAULT NULL COMMENT '优惠金额',
`reduce_rate` DECIMAL(16,2) DEFAULT NULL COMMENT '补贴率',
PRIMARY KEY (`dt`,`coupon_id` )
) ENGINE=INNODB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
2、Sqoop导出脚本
#!/bin/bash
hive_db_name=gmall
mysql_db_name=gmall_report
export_data() {
/opt/module/sqoop/bin/sqoop export \
--connect "jdbc:mysql://hadoop102:3306/${mysql_db_name}?useUnicode=true&characterEncoding=utf-8" \
--username root \
--password 000000 \
--table $1 \
--num-mappers 1 \
--export-dir /warehouse/$hive_db_name/ads/$1 \
--input-fields-terminated-by "\t" \
--update-mode allowinsert \
--update-key $2 \
--input-null-string '\\N' \
--input-null-non-string '\\N'
}
case $1 in
"ads_activity_stats" )
export_data "ads_activity_stats" "dt,activity_id"
;;
"ads_coupon_stats" )
export_data "ads_coupon_stats" "dt,coupon_id"
;;
"ads_order_by_province" )
export_data "ads_order_by_province" "dt,recent_days,province_id"
;;
"ads_order_spu_stats" )
export_data "ads_order_spu_stats" "dt,recent_days,spu_id"
;;
"ads_order_total" )
export_data "ads_order_total" "dt,recent_days"
;;
"ads_page_path" )
export_data "ads_page_path" "dt,recent_days,source,target"
;;
"ads_repeat_purchase" )
export_data "ads_repeat_purchase" "dt,recent_days,tm_id"
;;
"ads_user_action" )
export_data "ads_user_action" "dt,recent_days"
;;
"ads_user_change" )
export_data "ads_user_change" "dt"
;;
"ads_user_retention" )
export_data "ads_user_retention" "create_date,retention_day"
;;
"ads_user_total" )
export_data "ads_user_total" "dt,recent_days"
;;
"ads_visit_stats" )
export_data "ads_visit_stats" "dt,recent_days,is_new,channel"
;;
"all" )
export_data "ads_activity_stats" "dt,activity_id"
export_data "ads_coupon_stats" "dt,coupon_id"
export_data "ads_order_by_province" "dt,recent_days,province_id"
export_data "ads_order_spu_stats" "dt,recent_days,spu_id"
export_data "ads_order_total" "dt,recent_days"
export_data "ads_page_path" "dt,recent_days,source,target"
export_data "ads_repeat_purchase" "dt,recent_days,tm_id"
export_data "ads_user_action" "dt,recent_days"
export_data "ads_user_change" "dt"
export_data "ads_user_retention" "create_date,retention_day"
export_data "ads_user_total" "dt,recent_days"
export_data "ads_visit_stats" "dt,recent_days,is_new,channel"
;;
esac

3、全流程调度
3.1 数据准备

3.2 编写Azkaban工作流程配置文件
1)编写azkaban.project文件,内容如下
azkaban-flow-version: 2.02)编写gmall.flow文件,内容如下
nodes:
- name: mysql_to_hdfs
type: command
config:
command: /home/atguigu/bin/mysql_to_hdfs.sh all ${dt}
- name: hdfs_to_ods_log
type: command
config:
command: /home/atguigu/bin/hdfs_to_ods_log.sh ${dt}
- name: hdfs_to_ods_db
type: command
dependsOn:
- mysql_to_hdfs
config:
command: /home/atguigu/bin/hdfs_to_ods_db.sh all ${dt}
- name: ods_to_dim_db
type: command
dependsOn:
- hdfs_to_ods_db
config:
command: /home/atguigu/bin/ods_to_dim_db.sh all ${dt}
- name: ods_to_dwd_log
type: command
dependsOn:
- hdfs_to_ods_log
config:
command: /home/atguigu/bin/ods_to_dwd_log.sh all ${dt}
- name: ods_to_dwd_db
type: command
dependsOn:
- hdfs_to_ods_db
config:
command: /home/atguigu/bin/ods_to_dwd_db.sh all ${dt}
- name: dwd_to_dws
type: command
dependsOn:
- ods_to_dim_db
- ods_to_dwd_log
- ods_to_dwd_db
config:
command: /home/atguigu/bin/dwd_to_dws.sh all ${dt}
- name: dws_to_dwt
type: command
dependsOn:
- dwd_to_dws
config:
command: /home/atguigu/bin/dws_to_dwt.sh all ${dt}
- name: dwt_to_ads
type: command
dependsOn:
- dws_to_dwt
config:
command: /home/atguigu/bin/dwt_to_ads.sh all ${dt}
- name: hdfs_to_mysql
type: command
dependsOn:
- dwt_to_ads
config:
command: /home/atguigu/bin/hdfs_to_mysql.sh all
3)将azkaban.project、gmall.flow文件压缩到一个zip文件,文件名称必须是英文。


















 2148
2148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









