







因为做实验需要用到气象数据,找数据花费了很多时间,此处想吐槽一下,为什么我们国家自己的数据集要下架啊!!!!!!!还好还好,还有国外公开数据,我是用的@王_晓磊分享的数据集,已经整理到最近23年8月份了,数据很全,当然也可以自己去NCDC官网下载
数据处理教程主要参考,包括前期转换也是参考他们的教程python实现美国国家气候数据中心NCDC预处理,按年重采样为年度数据,并保存为Excel格式
NCDC气象数据的提取与处理(三):python批量将站点数据重采样为日数据
我想转化为一年为单位的日均城市气象数据,所以还需要自己处理,但我怕一次性处理出来数据太粗糙(其实是自己实在废柴,不会搞),做数据处理的过程中遇到了好多问题,记录一下过程:
数据下载
去了@王_晓磊微博下载的
isd-lite数据为xlsx
参考教程:NCDC气象数据的提取与处理(二):python批量转换isd-lite数据为xlsx
数据提取和处理
这部分做了两类,
一种是根据教程NCDC气象数据的提取与处理(三):python批量将站点数据重采样为日数据
做了类似的,但不是我想要的,本来是处理了所有,把同一年所有站点日均值放在同一个Excel中,但超内存了,随即作罢
另一种是根据python实现美国国家气候数据中心NCDC预处理,按年重采样为年度数据,并保存为Excel格式
教程,把时间尺度修改为了日尺度,具体代码:
import os
import pandas as pd
import numpy as np
from tqdm import tqdm
folderPath = r"读取路径"
outputPath = r"输出路径"
def Preprocess(folderPath, outputPath):
nullStationDir = {} # 字典保存站点数据不足的站点文件
folders = os.listdir(folderPath) # 获取上级文件路径下的所有年份文件夹
# 以年为单位遍历
for folder in folders:
fileList = [] # 当年所有站点文件的绝对路径列表
nullStationList = [] # 当年数据不足的站点文件列表
if os.path.splitext(folder)[-1] == "": # 通过后缀判断文件是否为文件夹
# 获取年份文件夹下所有站点文件的绝对路径,并保存到列表fileList中
for root, _, files in os.walk(f"{folderPath}\\{folder}"):
for file in files:
if os.path.splitext(file)[-1] == '.xlsx':
fileList.append(os.path.join(root, file))
# 初始化一个空的数据框用于之后向里面添加站点数据,根据需要修改,输出Excel你所需的列名,名称可更改
daily = pd.DataFrame(
columns=['station', 'Date', '平均温度(°C)', '平均露点温度(°C)', '平均气压(hPa)', '云量', '平均风向(°)',
'平均风速(m/s)', '累计降雨(mm)'])
# 获得站点文件个数
# total = len(fileList)
# 通过站点文件的列表遍历年份文件夹下的所有站点文件
# for idx, station in enumerate(fileList, 1):
for stationPath in tqdm(fileList, desc=f"{folder}年站点"):
stationCode = os.path.split(stationPath)[-1][0:6] # 站点文件绝对路径->站点文件名->站点号
# print("*" * 10, stationCode, f'({idx}/{total})', "*" * 10)
# 读取站点文件,根据需要选取列,这里的列名是输入的Excel里面列名,名称不可改
data = pd.read_excel(stationPath,
usecols=['Date', '温度', '1小时雨量', '6小时雨量', '露点温度', '气压', '风向',
'风速', '云量'])
data = data.set_index('Date') # 设置日期为索引便于重采样
# 将数据按日期重采样到日尺度并计算日均值(温度、露点温度、气压、云量),同时删除不需要列
meanData = data[~data["风向"].isin([np.nan, 0])]
meanData = data.resample('D').mean()
meanData.drop(columns=["1小时雨量", "6小时雨量", "风向", "风速"], axis=1, inplace=True)
# 将数据按日期重采样到日尺度并计算日累加值(1小时雨量、6小时雨量),同时删除不需要的温度
sumData = data.resample('D').sum()
sumData.drop(columns=["温度", "露点温度", "气压", "风向", "风速", "云量", ], axis=1, inplace=True)
# 去除无风天后,将数据按日期重采样到日尺度并计算日均值(风向、风速),同时删除不需要列
windData = data[~data["风向"].isin([np.nan, 0])]
windMeanData = windData.resample('D').mean()
windMeanData.drop(columns=["1小时雨量", "6小时雨量", "温度", "露点温度", "气压", "云量"], axis=1,
inplace=True)
# 将均值表和累加表横向关联,合并为新的表,并将1小时和6小时降雨量两列合并,同时添加新的站点列
df = pd.merge(meanData.reset_index(), windMeanData.reset_index())
df = pd.merge(df, sumData.reset_index())
df['降雨'] = df['1小时雨量'] + df['6小时雨量']
df.drop(columns=["1小时雨量", "6小时雨量"], axis=1, inplace=True)
df.insert(0, 'station', int(stationCode)) # 新建一列用于存储站点信息,注意转换数据类型 str->int
# 重命名数据框列名,要与daily一致
df = df.rename(columns={"温度": "平均温度(°C)", "露点温度": "平均露点温度(°C)", "气压": "平均气压(hPa)",
"风向": "平均风向(°)", "风速": "平均风速(m/s)", "降雨": "累计降雨(mm)"})
# 在每轮循环中将站点数据纵向关联合并到daily数据框
daily = pd.concat([daily, df])
# 将合并完的daily数据重置索引,并将日期转换为整型
daily = daily.reset_index(drop=True)
daily['Date'] = pd.to_datetime(daily['Date'], format='%Y-%m-%d') # 将日期转换为 datetime 类型
# 使用 ExcelWriter() 对象保存 Excel 文件,并指定日期格式
savePath = f'{outputPath}\\{folder}.xlsx'
with pd.ExcelWriter(savePath, mode='w', datetime_format='yyyy/mm/dd') as writer:
daily.to_excel(writer, index=False)
# 保存当年不足数据
nullStationDir[folder] = nullStationList
return nullStationDir
nullData = Preprocess(folderPath, outputPath)
基本获得的数据是可以用的,但降雨具体该怎么求呢?有点子困惑,而且云量也没计算
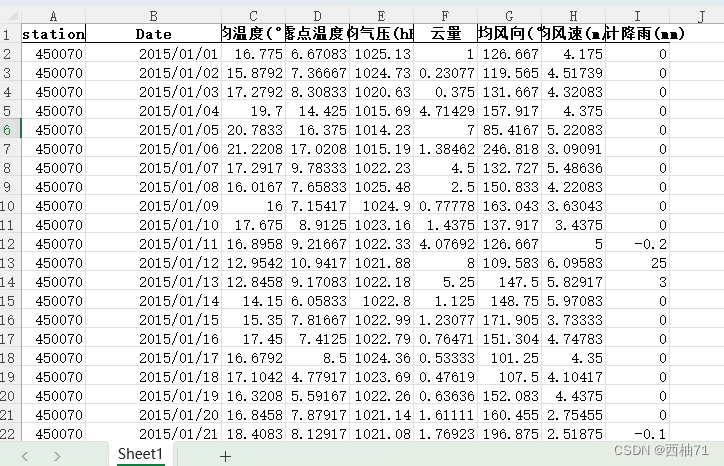
站点的城市信息
站点日均有了,接下来就是计算城市了,所以需要匹配一下城市等信息 ,所以需要站点和城市的对应信息:

数据是使用ArcGIS连接处理获得的,教程很多,网上随便扒的
气象数据添加城市等信息
直接代码:
import os
import pandas as pd
# 指定文件夹路径和指定Excel文件路径
folder_path = r'站点日均数据的文件夹路径'
excel_file_path = r'站点和城市对应的Excel表格'
# 读取指定Excel文件
df_excel = pd.read_excel(excel_file_path)
# 创建存储修改后数据的文件夹
output_folder = r'存储路径'
os.makedirs(output_folder, exist_ok=True)
# 遍历文件夹中的Excel文件
for file_name in os.listdir(folder_path):
# 构建Excel文件路径
file_path = os.path.join(folder_path, file_name)
# 读取文件
df = pd.read_excel(file_path)
# 将station列和STATION_ID列进行对比,找出匹配的数据
merged_df = pd.merge(df, df_excel, how='left', left_on='station', right_on='STATION_ID')
# 将匹配的数据添加到station行
df.loc[:, 'STATION_NA'] = merged_df['STATION_NA'].values
# df.loc[:, 'LAT'] = merged_df['LAT'].values
# df.loc[:, 'LON'] = merged_df['LON'].values
df.loc[:, 'ELEV_M_'] = merged_df['ELEV_M_'].values
df.loc[:, 'City'] = merged_df['City'].values
df.loc[:, 'Province'] = merged_df['Province'].values
# 构建存储修改后数据的文件路径
output_file_path = os.path.join(output_folder, file_name)
# 保存修改后的文件
df.to_excel(output_file_path, index=False)
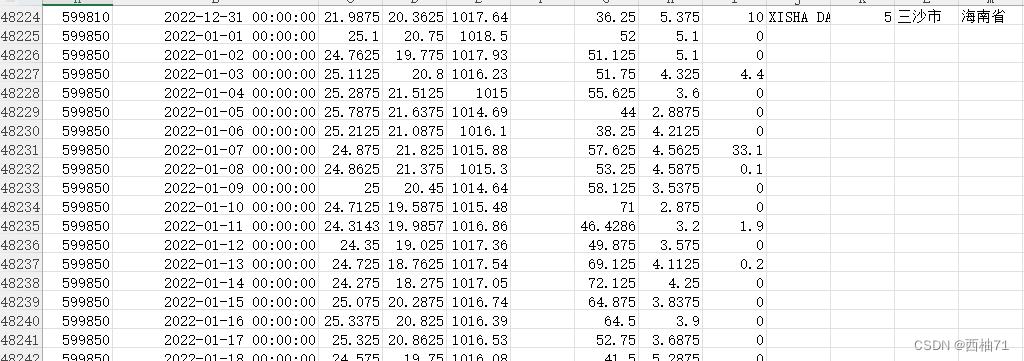
输出数据就是这样的

但是,我的错,在站点城市信息处理时,大概是我的地图数据不完整,我发现有一个站点没有匹配到城市信息,确认了一下,即使加了,也没有城市和省份信息,不过流程就是如此啦
后续工作进行Excel表格处理一下好了,代码实在是我的 弱项,一个错误我需要排查好久。。。。。。好多数据处理都是摸索着来的,后面重现的时候,发现过程和步骤都忘记了,这次记录一下
城市日均值
import pandas as pd
import os
# 指定包含Excel文件的文件夹路径
folder_path = r'存有匹配了城市信息的站点日均数据文件夹路径'
# 指定输出文件夹路径,一定要和输入路径不一样,不然会死循环下去的!!!
output_folder_path = r'输出存储路径'
# 获取文件夹中的所有Excel文件名
excel_files = [f for f in os.listdir(folder_path) if f.endswith('.xlsx')]
# 逐个读取并处理每个Excel文件
for file_name in excel_files:
# 构建文件的完整路径
file_path = os.path.join(folder_path, file_name)
# 读取Excel文件
data = pd.read_excel(file_path)
# 将需要计算均值的列转换为数值类型
numeric_cols = ['平均温度(°C)', '平均露点温度(°C)', '平均气压(hPa)', '云量', '平均风向(°)', '平均风速(m/s)',
'累计降雨(mm)']
data[numeric_cols] = data[numeric_cols].apply(pd.to_numeric, errors='coerce')
# 按城市和省份分组并计算平均值,忽略空值
city_province_avg = data.groupby(['Province', 'City', 'Date'])[numeric_cols].mean().dropna().reset_index()
# 从输入文件名生成输出文件名
output_file_name = file_name.split('.')[0] + '_avg.xlsx'
output_path = os.path.join(output_folder_path, output_file_name)
# 将计算得到的平均值保存为新的Excel文件
city_province_avg.to_excel(output_path, index=False)
# 输出完成提示
print('文件处理完成:', output_file_name)
如果有和我一样的代码小白,且需要处理气象数据,希望能帮到你一点点
新手加小白,若有不足,欢迎大家指正!















 323
323











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









