






写在最前面,本身是要求的cv课程的实验内容,在这里记录一下自己的实验历程。一开始使用的是阿里云平台,因为阿里云平台有三个月免费的GPU可以使用,但不知道为什么,一直有一个错误无法解决,于是转战kaggle,关于kaggle的注册教程在我的一篇博客中,链接:Kaggle的使用分享_kaggle新建dataset怎么打开使用-CSDN博客
目录
3.运行test.py\train.py\detect.py
Part1 Kaggle平台跑通YOLOv3
1.数据集介绍
我直接使用的是kaggle平台上面的数据集,没有下载coco2014数据集然后再压缩上传到kaggle上,但是kaggle平台上这个数据集好像有一点点问题,运行test.py的时候会看到找不到某张图片,可能这个数据集缺失了,或者官方的COCO2014数据集已更新,但是运行train.py和detect.py时是没有任何问题的。(大家直接在kaggle上面搜索这个数据集,然后新建一个notebook就可以了)

(点击上图中的New Notebook,这个数据集就会自动上传到新建的notebook中。)
打开刚刚建立的notebook,可以在右侧看到数据集已经导入了
2.获取YOLOv3代码及环境配置
大家可以去GitHub官网上下载,然后上传到kaggle上,由于实验课上提供了这部分内容,所以我直接用的课上给的,然后上传到Kaggle上。(注意:要以压缩包的形式上传,然后导入到当前的notebook中,kaggle会自行解压缩。)
github链接:https://github.com/eriklindernoren/PyTorch-YOLOv3
2.1将YOLOv3相关代码放到Output中:
(代码导入到kaggle中,会在Input中,但Input中是没有办法修改的,所以我们将它放到Output中,执行下面的代码,将其中的路径换成你自己的代码存放的路径)
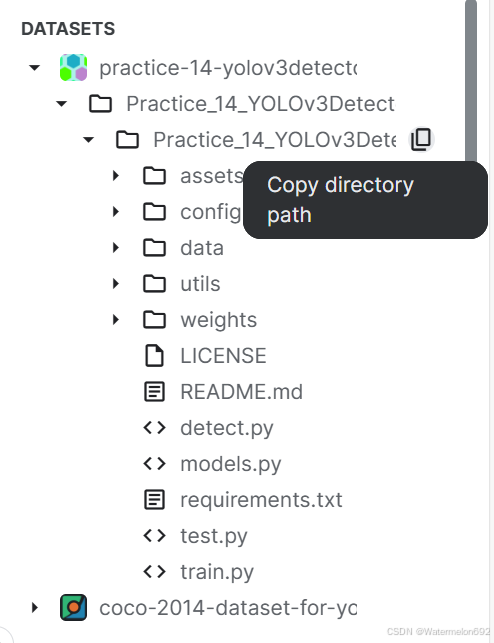
!cp -r /kaggle/input/practice-14-yolov3detector/Practice_14_YOLOv3Detector/Practice_14_YOLOv3Detector /kaggle/working/(在notebook中运行上面的代码后,我们可以在Output中看到下图)
2.2根据README.md文件进行操作
我们打开README.md文件,按照文件中的步骤一步步操作(操作时一定要注意路径)
基于神经网络的单阶段目标检测器
以下是pytorch版本的YOLOv3代码
[code](https://github.com/eriklindernoren/PyTorch-YOLOv3)
该代码仓库仍处于持续更新中,因此本目录下的代码与教材编写阶段的代码存在细微差别,读者可以访问上述链接获得最新的代码。
使用方法
安装代码依赖的环境
sudo pip3 install -r requirements.txt
下载预训练的模型参数
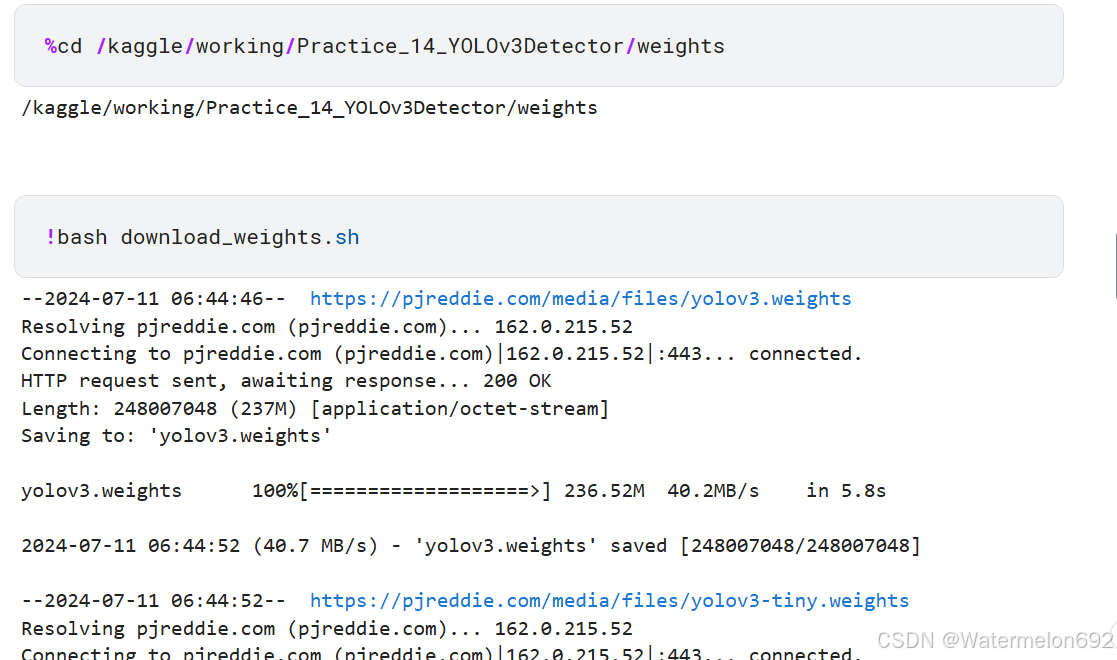
cd weights/
bash download_weights.sh
下载COCO数据集
cd data/
bash get_coco_dataset.sh
测试代码
python3 test.py --weights_path weights/yolov3.weights
在COCO数据集上训练模型
python3 train.py --data_config config/coco.data --pretrained_weights weights/darknet53.conv.74
自定义训练
通过提供不同的命令行参数,即可控制模型训练的配置
python3 train.py [-h] [--epochs EPOCHS] [--batch_size BATCH_SIZE]
[--gradient_accumulations GRADIENT_ACCUMULATIONS]
[--model_def MODEL_DEF] [--data_config DATA_CONFIG]
[--pretrained_weights PRETRAINED_WEIGHTS] [--n_cpu N_CPU]
[--img_size IMG_SIZE]
[--checkpoint_interval CHECKPOINT_INTERVAL]
[--evaluation_interval EVALUATION_INTERVAL]
[--compute_map COMPUTE_MAP]
[--multiscale_training MULTISCALE_TRAINING]有几点需要注意:
1.在安装依赖的环境时,代码应该改为,①不要加sudo;②requirements.txt文件的地址一定要指明

2.下载预训练的模型参数:还是要注意路径!!!
3.不用下载COCO数据集,前面已经导入了kaggle平台上的COCO数据集了,但需要①CLONE COCO API,②Set Up Image Lists
先查看get_coco_dataset.sh
#!/bin/bash
# CREDIT: https://github.com/pjreddie/darknet/tree/master/scripts/get_coco_dataset.sh
# Clone COCO API
git clone https://github.com/pdollar/coco
cd coco
mkdir images
cd images
# Download Images(下载网址有问题,我改成了官网上的)
#wget -c https://pjreddie.com/media/files/train2014.zip
#wget -c https://pjreddie.com/media/files/val2014.zip
wget -c http://images.cocodataset.org/zips/val2014.zip
wget -c http://images.cocodataset.org/zips/train2014.zip
# Unzip
unzip -q train2014.zip
unzip -q val2014.zip
cd ..
# Download COCO Metadata
wget -c https://pjreddie.com/media/files/instances_train-val2014.zip
wget -c https://pjreddie.com/media/files/coco/5k.part
wget -c https://pjreddie.com/media/files/coco/trainvalno5k.part
wget -c https://pjreddie.com/media/files/coco/labels.tgz
tar xzf labels.tgz
unzip -q instances_train-val2014.zip
# Set Up Image Lists
paste <(awk "{print \"$PWD\"}" <5k.part) 5k.part | tr -d '\t' > 5k.txt
paste <(awk "{print \"$PWD\"}" <trainvalno5k.part) trainvalno5k.part | tr -d '\t' > trainvalno5k.txt①CLONE COCO API
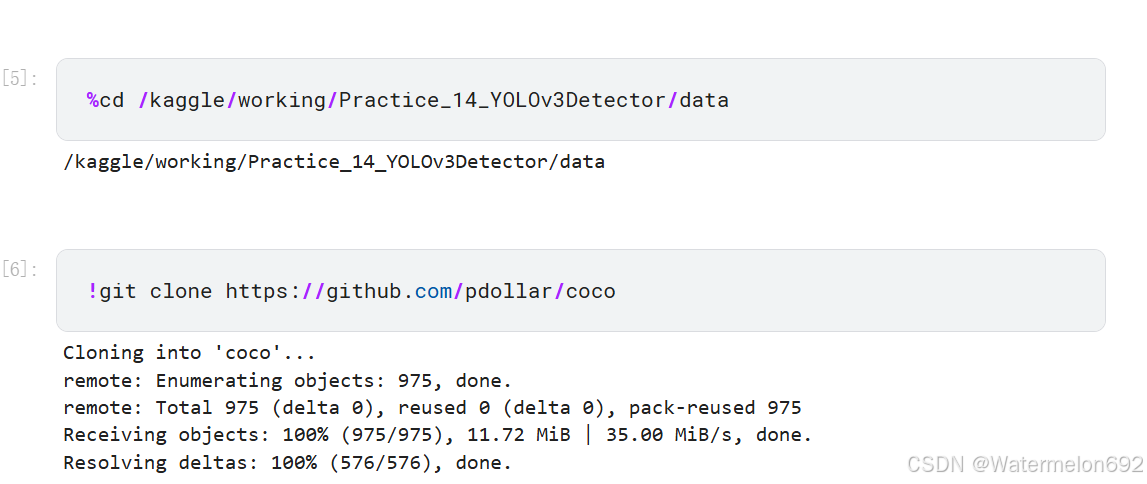
②Set Up Image Lists
$PWD 替换为 /kaggle/input/coco-2014-dataset-for-yolov3/coco2014,保证图像的列表地址是可以对应上的,代码如下。(根据自己的路径替换)
!wget -c https://pjreddie.com/media/files/coco/5k.part
!paste <(awk "{print \"/kaggle/input/coco-2014-dataset-for-yolov3/coco2014\"}" <5k.part) 5k.part | tr -d '\t' > 5k.txt
!wget -c https://pjreddie.com/media/files/coco/trainvalno5k.part
!paste <(awk "{print \"/kaggle/input/coco-2014-dataset-for-yolov3/coco2014\"}" <trainvalno5k.part) trainvalno5k.part | tr -d '\t' > trainvalno5k.txt
%ls 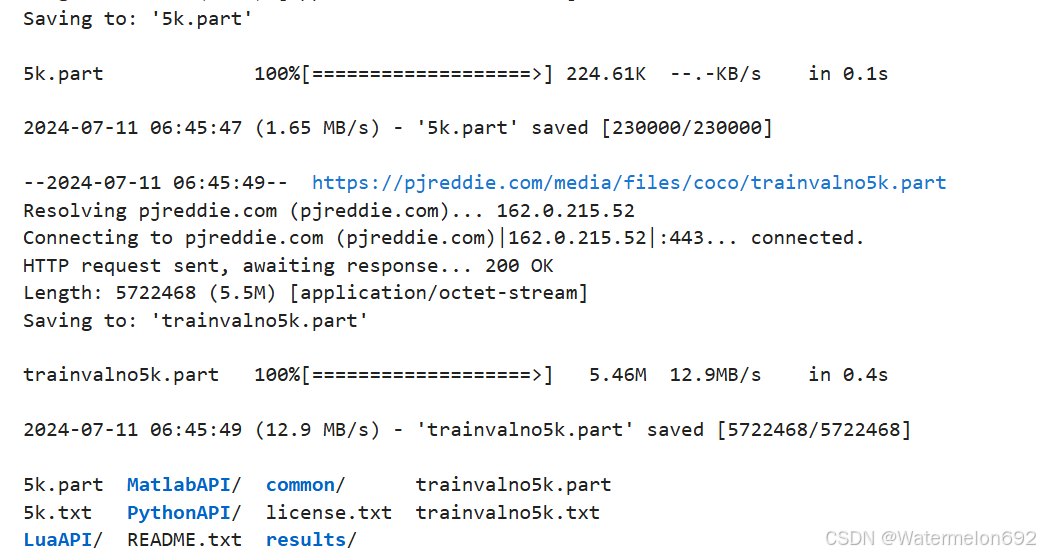
(这时可以查看右边的Output,看看在xxx/data/coco中是否有5k.txt和trainlno5k.txt这两个文件)
4.先别急着测试和训练,有几点需要修改,放在下面2.3中
2.3进行测试和训练前需要修改的内容
参考的blog:YOLOv3~ COCO_yolov3 coco-CSDN博客
1.修改coco.data配置文件(首先要先进入到存放coco.data的文件夹下,只需要使用cd换盘符命令即可)
原来项目的配置文件 coco.data内容:
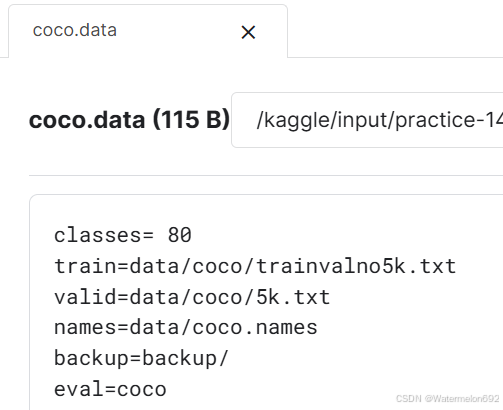
修改后的coco.data内容:
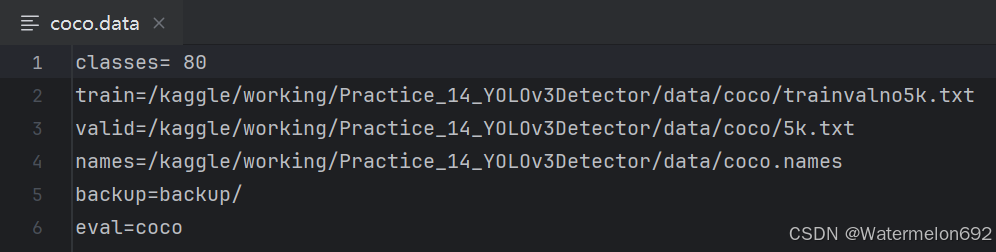
使用 readlines 读取 coco.data 文件的内容到列表里,接下来修改 train,valid,names 的地址
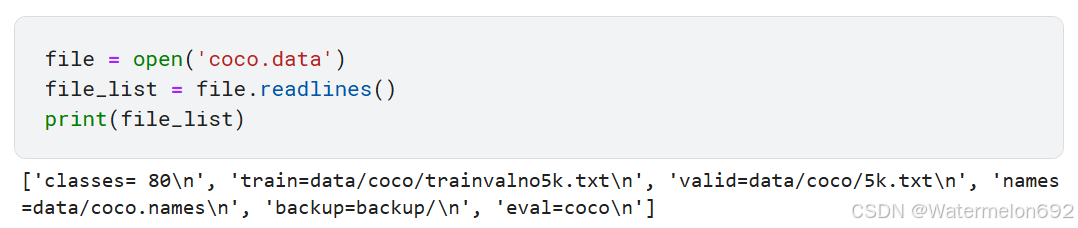
使用索引找到需要修改的地址
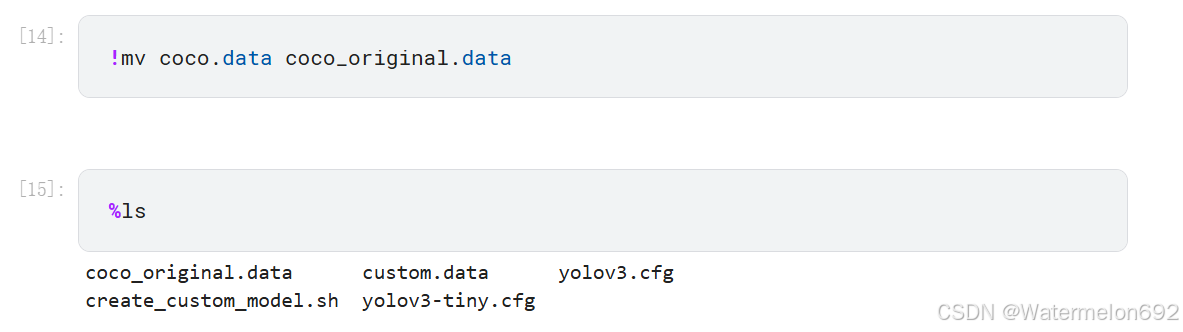
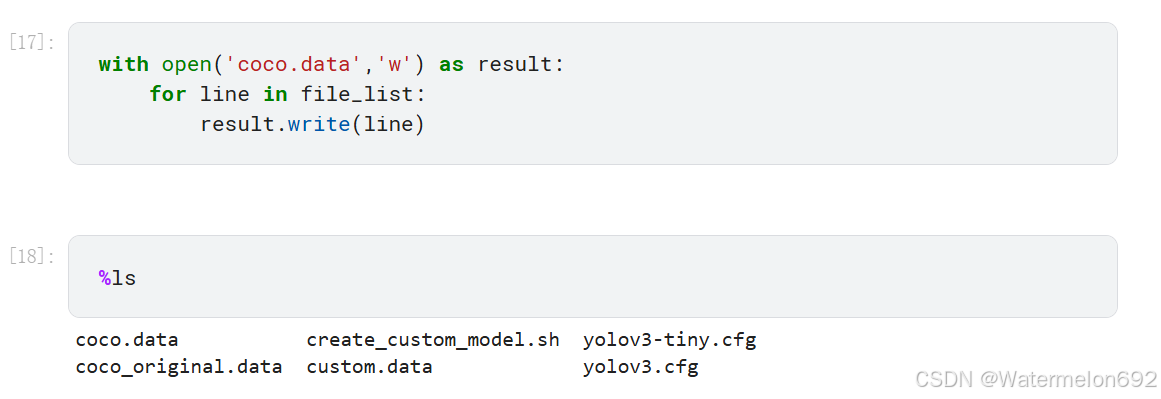
将 coco.data 更名为 coco_original.data,新建 coco.data 文件,把列表 file_list 的每一行写入 coco.data 文件里
上面的代码:方便读者自取
#假设已经进入到了存放coco.data的文件夹下
file = open('coco.data')
file_list = file.readlines()
print(file_list)
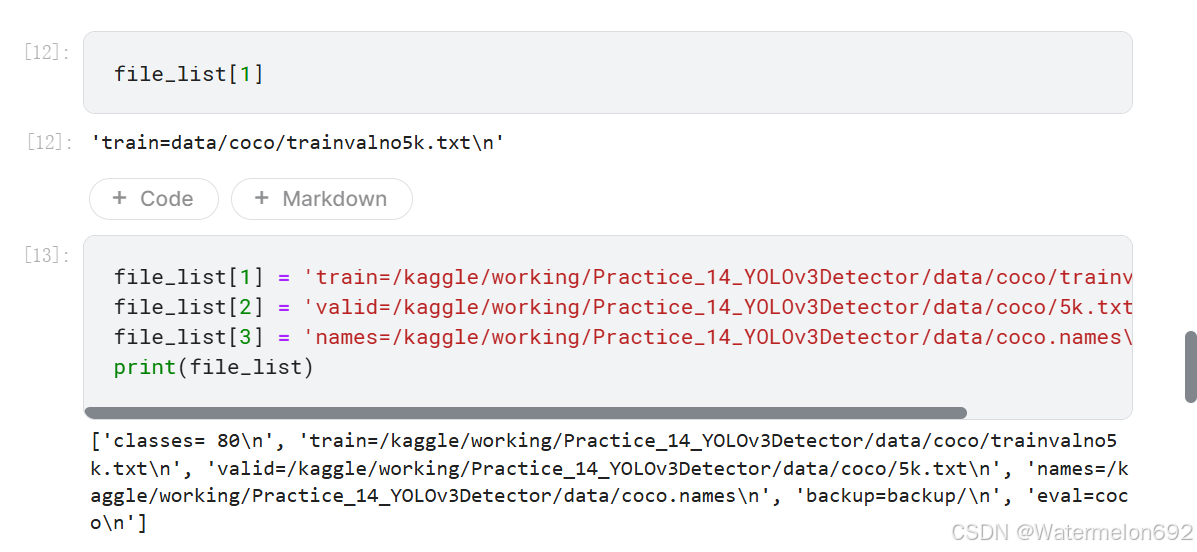
file_list[1]
#地址换成自己的
file_list[1] = 'train=/kaggle/working/Practice_14_YOLOv3Detector/data/coco/trainvalno5k.txt\n'
file_list[2] = 'valid=/kaggle/working/Practice_14_YOLOv3Detector/data/coco/5k.txt\n'
file_list[3] = 'names=/kaggle/working/Practice_14_YOLOv3Detector/data/coco.names\n'
print(file_list)
#将 coco.data 更名为 coco_original.data,新建 coco.data 文件,把列表 file_list 的每一行写入 coco.data 文件里
!mv coco.data coco_original.data
%ls
with open('coco.data','w') as result:
for line in file_list:
result.write(line)
%ls
2.运行train.py时,可能调用logger()函数时报错,这时需要修改一下utils文件下的logger.py(如果不报错,则无需修改)

import tensorflow as tf
# class Logger(object):
# def __init__(self, log_dir):
# """Create a summary writer logging to log_dir."""
# # self.writer = tf.summary.FileWriter(log_dir)
# self.writer = tf.summary.create_file_writer(log_dir)
# def scalar_summary(self, tag, value, step):
# """Log a scalar variable."""
# summary = tf.Summary(value=[tf.Summary.Value(tag=tag, simple_value=value)])
# self.writer.add_summary(summary, step)
# def list_of_scalars_summary(self, tag_value_pairs, step):
# """Log scalar variables."""
# summary = tf.Summary(value=[tf.Summary.Value(tag=tag, simple_value=value) for tag, value in tag_value_pairs])
# self.writer.add_summary(summary, step)
class Logger(object):
def __init__(self, log_dir):
"""Create a summary writer logging to log_dir."""
# self.writer = tf.summary.FileWriter(log_dir)
self.writer = tf.summary.create_file_writer(log_dir)
def scalar_summary(self, tag, value, step):
"""Log a scalar variable."""
#summary = tf.Summary(value=[tf.Summary.Value(tag=tag, simple_value=value)])
#self.writer.add_summary(summary, step)
with self.writer.as_default():
tf.summary.scalar(tag, value, step=step)
self.writer.flush()
# summary = tf.Summary(value=[tf.Summary.Value(tag=tag, simple_value=value)])
# self.writer.add_summary(summary, step)
def list_of_scalars_summary(self, tag_value_pairs, step):
"""Log scalar variables."""
# summary = tf.Summary(value=[tf.Summary.Value(tag=tag, simple_value=value) for tag, value in tag_value_pairs])
#self.writer.add_summary(summary, step)
with self.writer.as_default():
for tag, value in tag_value_pairs:
tf.summary.scalar(tag, value, step=step)
self.writer.flush()
# summary = tf.Summary(value=[tf.Summary.Value(tag=tag, simple_value=value) for tag, value in tag_value_pairs])
# self.writer.add_summary(summary, step)2.4其他错误
①由于我使用的Kaggle中的GPU是T4*2,即两块Tesla T4,所以出现下面的错误

解决方法:在运行train.py前指定使用的GPU(在train.py最前面加入下面代码或者在notebook中执行train.py前加入下面代码)
import os
import torch
# 设置要使用的GPU编号,例如使用第一块GPU
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
# 确认CUDA是否可用
if torch.cuda.is_available():
# 确认当前设备
current_device = torch.cuda.current_device()
print(f"Currently using CUDA Device {current_device}: {torch.cuda.get_device_name(current_device)}")
else:
print("CUDA is not available.")
训练时可以在notebook的最上方看到使用的具体是哪个GPU,下图中第一张是:os.environ["CUDA_VISIBLE_DEVICES"] = "1"
第二张是:os.environ["CUDA_VISIBLE_DEVICES"] = "0"


②用魔法打败魔法

由于数据集太大了,所以运行内存可能不够,我没找到什么好的解决办法。只能看概率多运行几次train.py,有时train.py就可以顺利训练数据,不会出现这个错误
③运行test.py时缺少图


哭死简直,这个kaggle平台上的COCO2014数据集好像有数据损失,大家可以用自己从官方下载的。这里推荐一个下载方式,由于数据集太大了,从网页直接下载有时候不稳定,会有数据集损失,大家可以用百度网盘中的离线下载,然后再保存到本地。

3.运行test.py\train.py\detect.py
①test.py
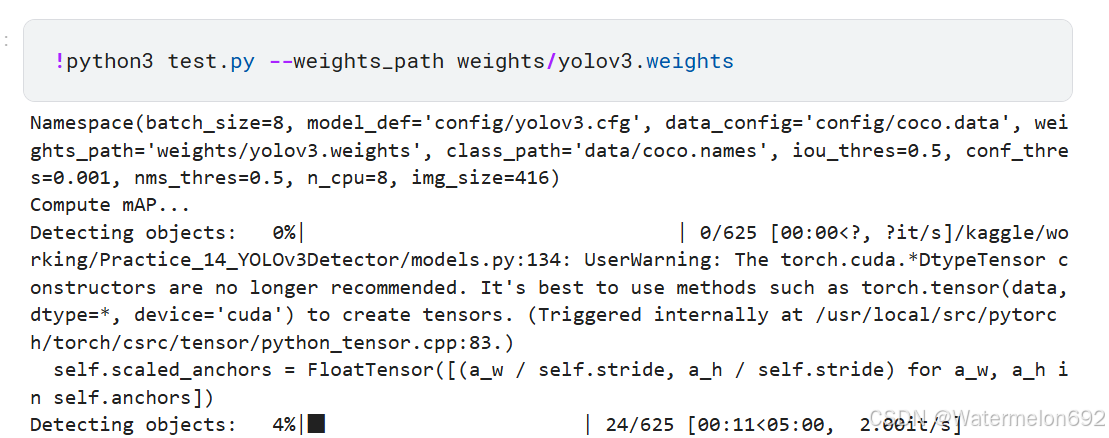
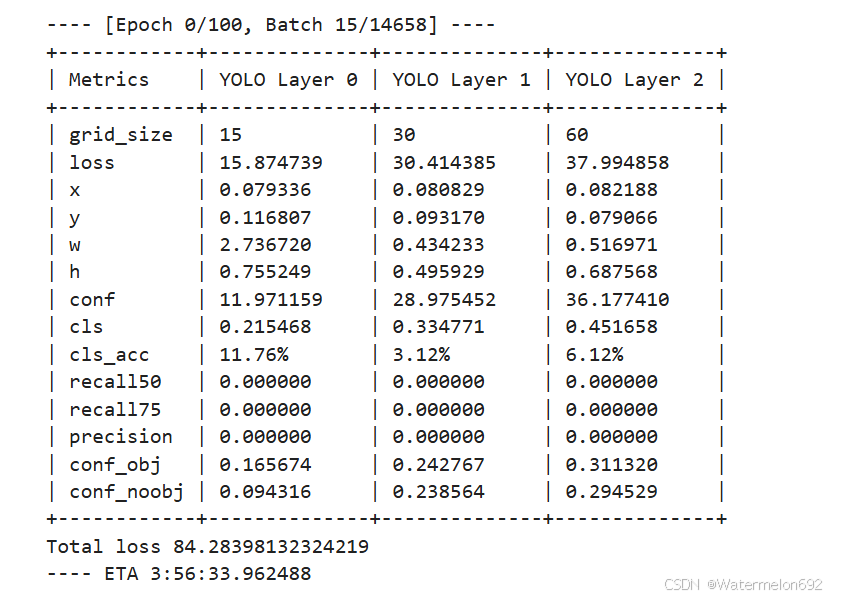
②train.py

③detect.py
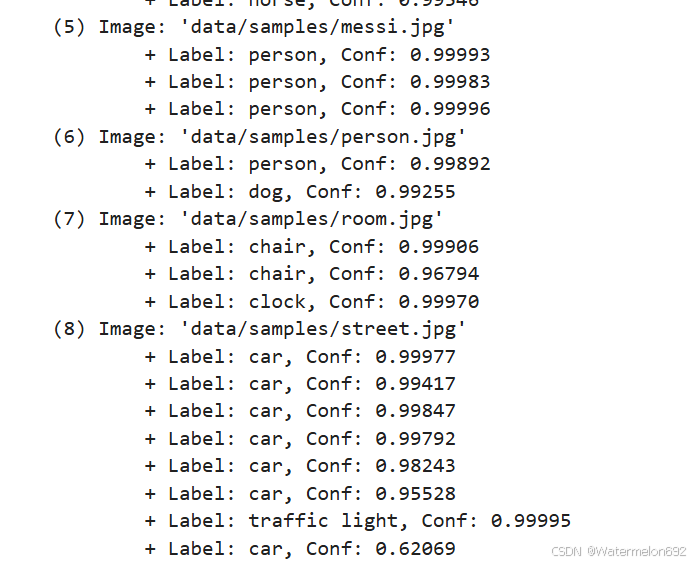
在我们的data/samples下,代码提供了我们几个样本
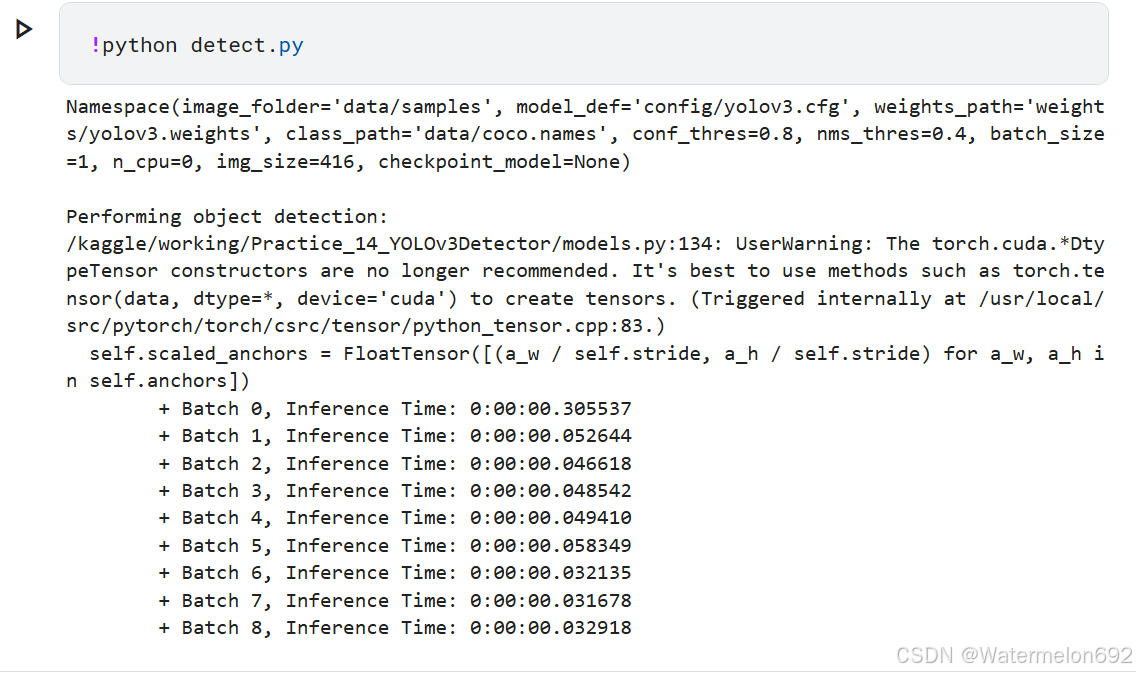
detect.py运行结束后,会将结果放在output文件夹下,将图片下载下来就可以看到模型已经将我们的samples全部标注好了

对于每一张samples图片,模型输出其labels与置信度
写在最后:我将kaggle里面的notebook导出来了,大家可以参考一下整体过程
链接:https://pan.baidu.com/s/1Hm7RLoHxduA1-KAWnHdmNg?pwd=m1g1
提取码:m1g1
Part2 阿里云平台
由于这个没跑通,而且错误改了一天也没改掉,所以暂时不打算写了。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









