






目录
1 应用背景
1.1 简介
随着信息技术的迅猛发展,数据通信的需求日益增加。大数据时代要求更高效的数据存储和传输方法,以应对海量信息的处理需求。哈夫曼编码作为一种有效的数据压缩技术,它通过构建最优的前缀码,为高频字符分配较短的码字,低频字符分配较长的码字,以此达到数据压缩的目的。
1.2 背景
通信系统中的挑战与哈夫曼编码的应用背景:
- 经存储空间限制:在服务器和终端设备中,存储资源是有限的。哈夫曼编码通过有效压缩数据,减少了存储空间的需求,使得相同容量的设备能够存储更多的信息。
- 传输带宽限制:网络带宽是通信系统中的宝贵资源。哈夫曼编码减少了数据传输量,从而节约了带宽,提高了网络的传输效率。
- 能耗问题:移动设备和无线传感器等对能耗极为敏感。数据压缩能减少数据的发送和接收次数,降低能耗,延长设备的工作时间。
- 实时性要求:在某些应用场景下,如在线视频、远程会议等,对数据传输的实时性要求极高。哈夫曼编码通过减少数据量,有助于降低延迟,提升实时性能。
1.3 意义
哈夫曼编码方法在通信系统中的意义:
- 确成本节约:数据压缩降低了存储和传输的成本,对于企业和用户来说,这意味着直接的经济利益。
- 效率提升:通过压缩数据,哈夫曼编码提高了数据处理速度,缩短了处理时间,提升了整体工作效率
- 技术支持:哈夫曼编码为通信技术的创新和发展提供了支持。例如,在5G和物联网技术中,高效的数据编码技术是实现高速通信的关键技术之一。
- 质量改善:压缩后的数据在传输过程中受到干扰的可能性降低,减少了数据错误,提升了通信质量。
- 适应性强:哈夫曼编码不仅适用于文本数据,还可以应用于图像、音频和视频等多种类型的数据,具有广泛的应用范围。
2 设计方案
2.1 系统框图
系统可以获取传入图片信息,包括图片的长宽高,以及像素频率表,根据像素频率表可以生成哈夫曼编码表,根据哈夫曼编码表不仅可以将原始图片编码为二进制字符串,还可以将编码串还原为原始图像,并且获取编码效率。
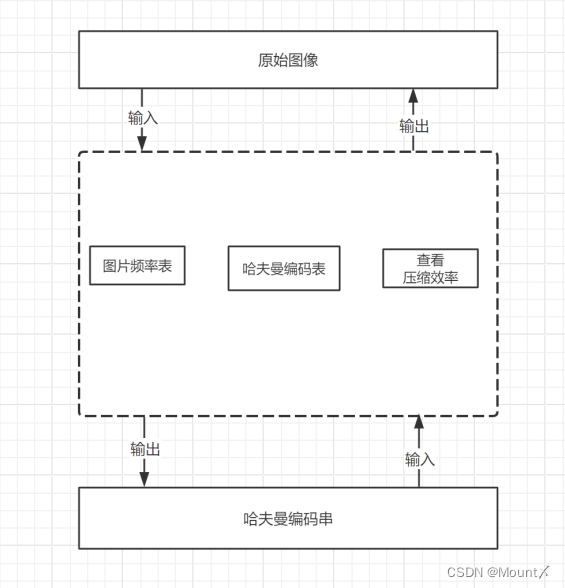
图1 系统框架图
2.2 基本原理
哈夫曼编码,又称霍夫曼编码,是一种可变长度的无损数据压缩算法,由David A. Huffman于1952年提出。该算法基于字符出现的频率构建最优前缀码,使得常用字符用较短的码表示,而不常用的字符用较长的码表示,从而有效减少编码后的总长度,达到数据压缩的目的。
基本原理是:统计各字符的出现频率并以字符为节点构建哈夫曼树,然后通过该树为每个字符生成对应的二进制编码。具体步骤如下:
- 统计字符频率:首先扫描待编码的数据,统计每个字符的出现频率。将字符按频率由低到高排序,准备构建哈夫曼树。
- 构建哈夫曼树:初始化:将每个字符看作一个独立节点,并将节点作为叶子节点加入优先队列(频率越低优先级越高)。迭代:每次从队列中取出两个权值最小的节点作为左右子节点,合并成一个新的二叉树,新节点的权值为两子节点权值之和。将新节点加入队列,重复此过程,直到队列中只剩一个节点,这个节点就是哈夫曼树的根节点。
- 生成编码:从根节点开始,对每条路径进行0或1的赋值(通常左分支为0,右分支为1),直至所有叶子节点。这样每个字符都得到一个唯一的二进制编码。
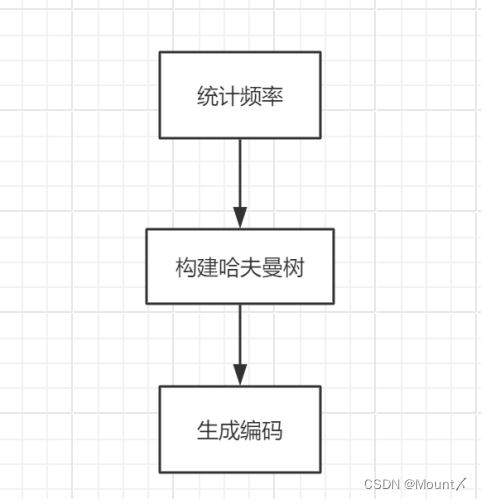
图2 基本原理图
2.3 算法实现
可采用python作为核心编程语言进行功能实现,首先使用opencv库读入图片,获取图片的像素值信息,使用numpy库像素矩阵展平为一维数组,接着使用字典统计并储存像素点频率信息;
获取频率信息后可以使用优先队列PriorityQueue构建哈夫曼树,从而获取哈夫曼编码表,使用编码表对图片的一维像素矩阵进行编码,从而获得哈夫曼编码;
获取编码后可以与原图片信息量作比较,分析编码效率;
还可以根据哈夫曼编码表,将哈夫曼编码还原为像素数组,从而还原成为原图片。
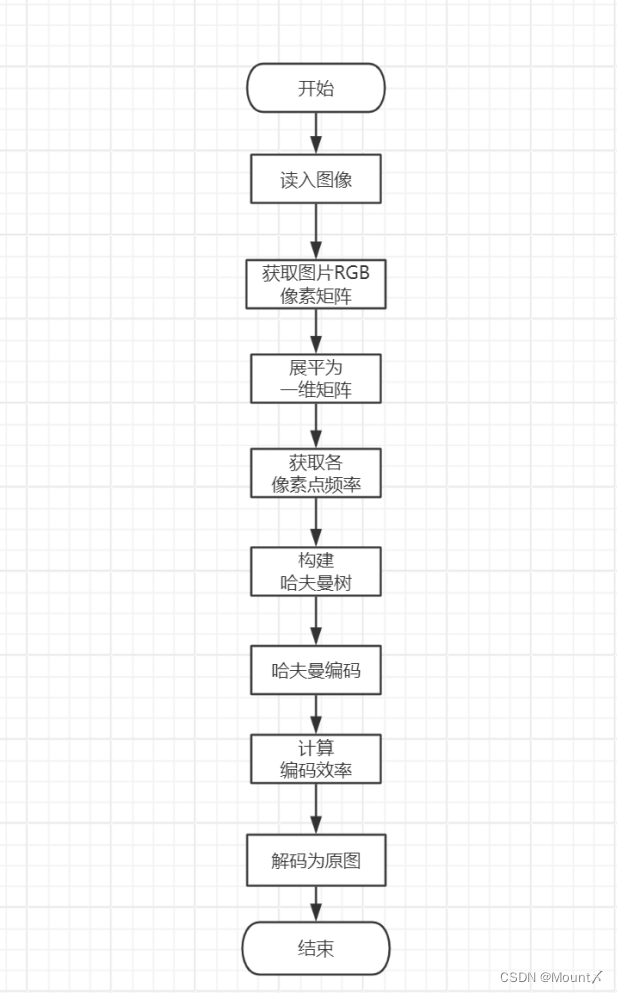
图3 算法流程图
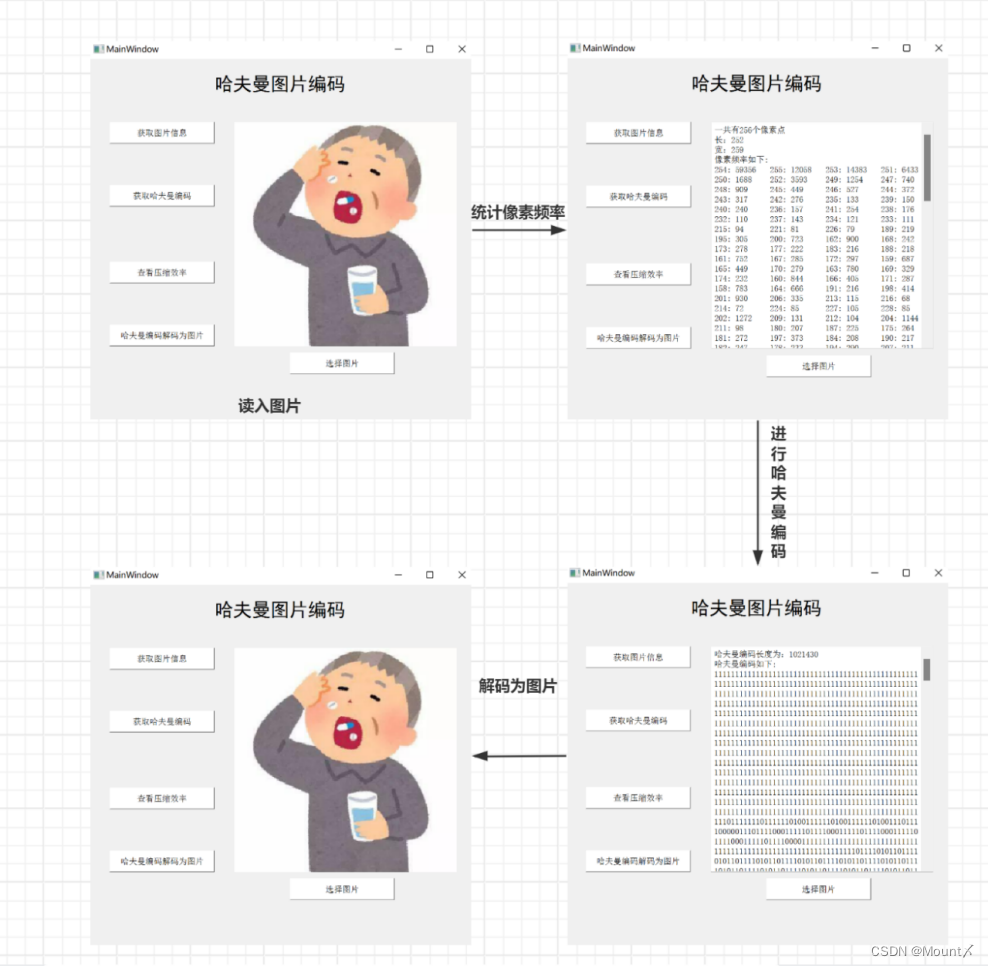
图4 软件使用图
3 结果分析
3.1 编码效率分析
统计字符频率和码长:首先扫描待编码的数据,统计每个字符的出现频率及其对应的哈夫曼编码长度。假设有n个不同的字符,第i个字符出现的概率为pi,其对应的编码长度为li。平均码长计算公式为:
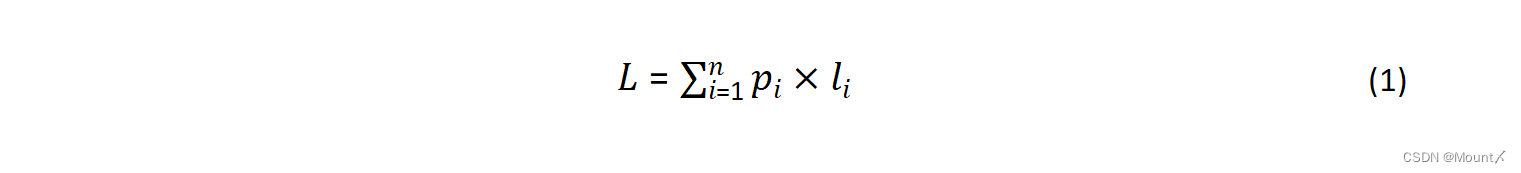
计算信源熵:信源熵H表示的是数据的原始信息量,计算公式为:
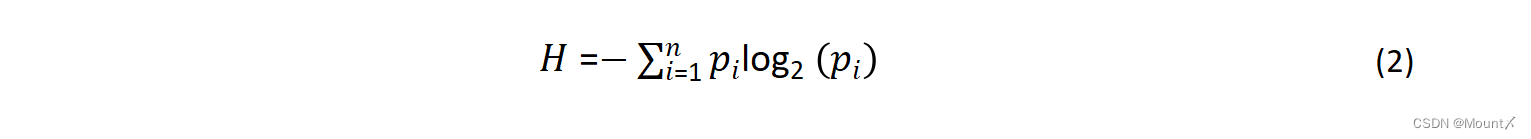
计算编码效率:使用下面的公式,可以计算出哈夫曼编码的效率(其中L为哈夫曼编码的平均码长,H为信源熵):
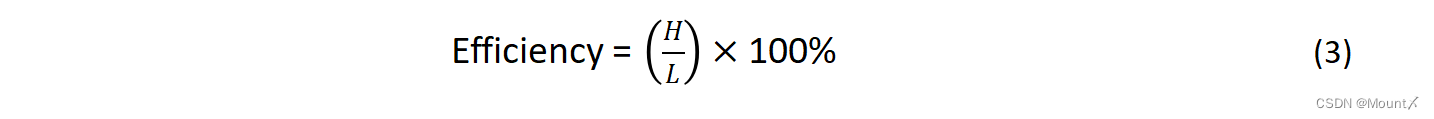
3.2 压缩率分析
计算原始图片大小:原始图片的像素矩阵是有R、G、B三个通道构成,每个通道都有一个二维像素矩阵,且每个像素值的范围都再0-255,大小为1Byte , 1Byte=8Bit。所以原始图片所占内存为:
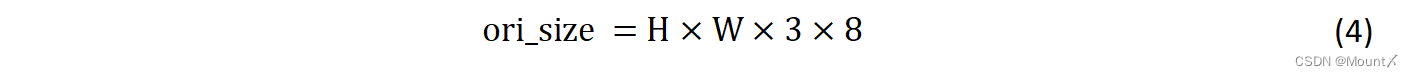
计算压缩后编码大小:图片被压缩为哈夫曼编码,一个哈夫曼编码就是1个2进制码,所以编码后所占内存为(Len为哈夫曼编码长度):

计算压缩率:
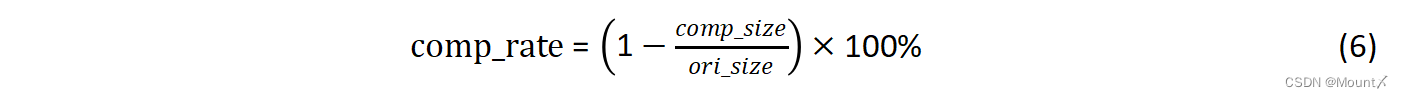
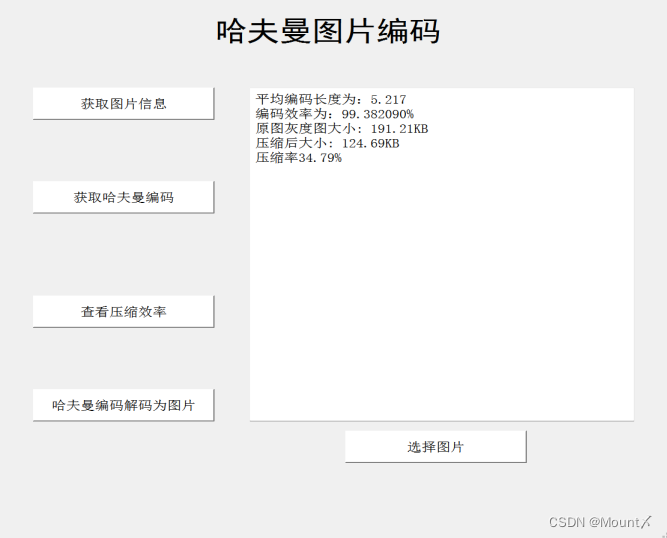
图5 编码效率图
3.3 图片对比
哈夫曼编码为一种无损数据压缩技术,在保证压缩效率的同时,还可以保留图片的原始信息。可以看到,图片经过编码再解码后,成功恢复出原始图片,且与原始图片各点像素值保持一致。 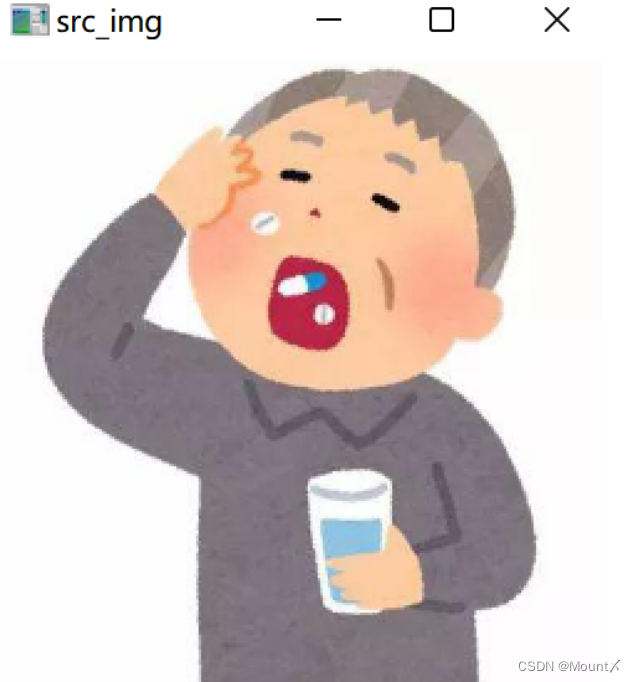

图6 原始图片 图7 解码图片
3.4 总结
在完成本次课程设计报告的过程中,我完成了以下任务:
- 实现哈夫曼编码:利用Python语言,我成功实现了哈夫曼编码算法。这个算法基于字符出现的频率来构建最优前缀码,以此实现数据压缩。具体步骤包括统计图片文件中每个像素值的频率,构建哈夫曼树,并生成对应的哈夫曼编码表。
- 性能分析:我对所实现的哈夫曼编码进行了效率分析和性能评估。通过对比压缩前后的文件大小,我计算了压缩比,并对编码和解码的时间进行了测量,以评估算法的运行效率。
- 图片恢复质量对比:为了验证压缩算法的效果,我对比了原始图片与经过哈夫曼编码压缩再解码恢复的图片。通过视觉检查和文件大小比较,我发现两者之间没有明显差异,证明了哈夫曼编码在图片压缩领域的有效性。
通过这项课程设计,我不仅加深了对哈夫曼编码原理的理解,也获得了实际编程实现的经验。性能评估表明,哈夫曼编码在图片压缩方面具有良好的压缩比和可接受的编码解码效率。最重要的是,经过压缩和解压过程的图片质量没有损失,这表明了哈夫曼编码在保证数据完整性方面的优越性。这次实践对我的编程技能和深入理解信源编码技术都有很大帮助。
代码如下:
hfm.py
import cv2
from queue import PriorityQueue
import numpy as np
import math
import struct
class HuffmanNode(object):
def __init__(self, value, key=None, symbol='', left_child=None, right_child=None):
'''
初始化哈夫曼树的节点
:param value: 节点的值,i.e. 元素出现的频率
:param key: 节点代表的元素,非叶子节点为None
:param symbol: 节点的哈夫曼编码,初始化必须为空字符串
:param left_child: 左子节点
:param right_child: 右子节点
'''
self.left_child = left_child
self.right_child = right_child
self.value = value
self.key = key
assert symbol == ''
self.symbol = symbol
def __eq__(self, other):
'''
用于比较两个HuffmanNode的大小,等于号,根据value的值比较
:param other:
:return:
'''
return self.value == other.value
def __gt__(self, other):
'''
用于比较两个HuffmanNode的大小,大于号,根据value的值比较
:param other:
:return:
'''
return self.value > other.value
def __lt__(self, other):
'''
用于比较两个HuffmanNode的大小,小于号,根据value的值比较
:param other:
:return:
'''
return self.value < other.value
def createTree(hist_dict: dict) -> HuffmanNode:
'''
构造哈夫曼树
可以写一个HuffmanTree的类
:param hist_dict: 图像的直方图,dict = {pixel_value: count}
:return: HuffmanNode, 哈夫曼树的根节点
'''
# 借助优先级队列实现直方图频率的排序,取出和插入元素很方便
q = PriorityQueue()
# 根据传入的像素值和频率字典构造哈夫曼节点并放入队列中
for k, v in hist_dict.items():
# 这里放入的都是之后哈夫曼树的叶子节点,key都是各自的元素
q.put(HuffmanNode(value=v, key=k))
# 判断条件,直到队列中只剩下一个根节点
while q.qsize() > 1:
# 取出两个最小的哈夫曼节点,队列中这两个节点就不在了
l_freq, r_freq = q.get(), q.get()
# 增加他们的父节点,父节点值为这两个哈夫曼节点的和,但是没有key值;左子节点是较小的,右子节点是较大的
node = HuffmanNode(value=l_freq.value + r_freq.value, left_child=l_freq, right_child=r_freq)
# 把构造的父节点放在队列中,继续排序和取放、构造其他的节点
q.put(node)
# 队列中只剩下根节点了,返回根节点
return q.get()
def walkTree_VLR(root_node: HuffmanNode, symbol=''):
'''
前序遍历一个哈夫曼树,同时得到每个元素(叶子节点)的编码,保存到全局的Huffman_encode_dict
:param root_node: 哈夫曼树的根节点
:param symbol: 用于对哈夫曼树上的节点进行编码,递归的时候用到,为'0'或'1'
:return: None
'''
# 为了不增加变量复制的成本,直接使用一个dict类型的全局变量保存每个元素对应的哈夫曼编码
global Huffman_encode_dict
# 判断节点是不是HuffmanNode,因为叶子节点的子节点是None
if isinstance(root_node, HuffmanNode):
# 编码操作,改变每个子树的根节点的哈夫曼编码,根据遍历过程是逐渐增加编码长度到完整的
root_node.symbol += symbol
# 判断是否走到了叶子节点,叶子节点的key!=None
if root_node.key != None:
# 记录叶子节点的编码到全局的dict中
Huffman_encode_dict[root_node.key] = root_node.symbol
# 访问左子树,左子树在此根节点基础上赋值'0'
walkTree_VLR(root_node.left_child, symbol=root_node.symbol + '0')
# 访问右子树,右子树在此根节点基础上赋值'1'
walkTree_VLR(root_node.right_child, symbol=root_node.symbol + '1')
return
def encodeImage(src_img: np.ndarray, encode_dict: dict):
'''
用已知的编码字典对图像进行编码
:param src_img: 原始图像数据,必须是一个向量
:param encode_dict: 编码字典,dict={element:code}
:return: 图像编码后的字符串,字符串中只包含'0'和'1'
'''
img_encode = ""
assert len(src_img.shape) == 1, '`src_img` must be a vector'
for pixel in src_img:
img_encode += encode_dict[pixel]
return img_encode
def writeBinImage(img_encode: str, huffman_file: str):
'''
把编码后的二进制图像数据写入到文件中
:param img_encode: 图像编码字符串,只包含'0'和'1'
:param huffman_file: 要写入的图像编码数据文件的路径
:return:
'''
# 文件要以二进制打开
with open(huffman_file, 'wb') as f:
# 每8个bit组成一个byte
for i in range(0, len(img_encode), 8):
# 把这一个字节的数据根据二进制翻译为十进制的数字
img_encode_dec = int(img_encode[i:i + 8], 2)
# 把这一个字节的十进制数据打包为一个unsigned char,大端(可省略)
img_encode_bin = struct.pack('>B', img_encode_dec)
# 写入这一个字节数据
f.write(img_encode_bin)
def readBinImage(huffman_file: str, img_encode_len: int):
'''
从二进制的编码文件读取数据,得到原来的编码信息,为只包含'0'和'1'的字符串
:param huffman_file: 保存的编码文件
:param img_encode_len: 原始编码的长度,必须要给出,否则最后一个字节对不上
:return: str,只包含'0'和'1'的编码字符串
'''
code_bin_str = ""
with open(huffman_file, 'rb') as f:
# 从文件读取二进制数据
content = f.read()
# 从二进制数据解包到十进制数据,所有数据组成的是tuple
code_dec_tuple = struct.unpack('>' + 'B' * len(content), content)
for code_dec in code_dec_tuple:
# 通过bin把解压的十进制数据翻译为二进制的字符串,并填充为8位,否则会丢失高位的0
# 0 -> bin() -> '0b0' -> [2:] -> '0' -> zfill(8) -> '00000000'
code_bin_str += bin(code_dec)[2:].zfill(8)
# 由于原始的编码最后可能不足8位,保存到一个字节的时候会在高位自动填充0,读取的时候需要去掉填充的0,否则读取出的编码会比原来的编码长
# 计算读取的编码字符串与原始编码字符串长度的差,差出现在读取的编码字符串的最后一个字节,去掉高位的相应数量的0就可以
len_diff = len(code_bin_str) - img_encode_len
# 在读取的编码字符串最后8位去掉高位的多余的0
code_bin_str = code_bin_str[:-8] + code_bin_str[-(8 - len_diff):]
return code_bin_str
def decodeHuffman(img_encode: str, huffman_tree_root: HuffmanNode):
'''
根据哈夫曼树对编码数据进行解码
:param img_encode: 哈夫曼编码数据,只包含'0'和'1'的字符串
:param huffman_tree_root: 对应的哈夫曼树,根节点
:return: 原始图像数据展开的向量
'''
img_src_val_list = []
# 从根节点开始访问
root_node = huffman_tree_root
# 每次访问都要使用一位编码
for code in img_encode:
# 如果编码是'0',说明应该走到左子树
if code == '0':
root_node = root_node.left_child
# 如果编码是'1',说明应该走到右子树
elif code == '1':
root_node = root_node.right_child
# 只有叶子节点的key才不是None,判断当前走到的节点是不是叶子节点
if root_node.key != None:
# 如果是叶子节点,则记录这个节点的key,也就是哪个原始数据的元素
img_src_val_list.append(root_node.key)
# 访问到叶子节点之后,下一次应该从整个数的根节点开始访问了
root_node = huffman_tree_root
return np.asarray(img_src_val_list)
def decodeHuffmanByDict(img_encode: str, encode_dict: dict):
'''
另外一种解码策略是先遍历一遍哈夫曼树得到所有叶子节点编码对应的元素,可以保存在字典中,再对字符串的子串逐个与字典的键进行比对,就得到相应的元素是什么。
用C语言也可以这么做。
这里不再对哈夫曼树重新遍历了,因为之前已经遍历过,所以直接使用之前记录的编码字典就可以。
:param img_encode: 哈夫曼编码数据,只包含'0'和'1'的字符串
:param encode_dict: 编码字典dict={element:code}
:return: 原始图像数据展开的向量
'''
img_src_val_list = []
decode_dict = {}
# 构造一个key-value互换的字典,i.e. dict={code:element},后边方便使用
for k, v in encode_dict.items():
decode_dict[v] = k
l = 0
r = 1
while r <= len(img_encode):
decode = img_encode[l: r]
if decode in decode_dict:
img_src_val_list.append(decode_dict[decode])
l = r
r += 1
return np.asarray(img_src_val_list)
def decodeHuffmanByDict2(img_encode: str, encode_dict: dict):
img_src_val_list = []
decode_dict = {}
# 构造一个key-value互换的字典,i.e. dict={code:element},后边方便使用
for k, v in encode_dict.items():
decode_dict[v] = k
# s用来记录当前字符串的访问位置,相当于一个指针
s = 0
# 只要没有访问到最后
while s + 1 < len(img_encode):
# 遍历字典中每一个键code
for k in decode_dict.keys():
# 如果当前的code字符串与编码字符串前k个字符相同,k表示code字符串的长度,那么就可以确定这k个编码对应的元素是什么
if k == img_encode[s:s + len(k)]:
img_src_val_list.append(decode_dict[k])
# 指针移动k个单位
s += len(k)
# 如果已经找到了相应的编码了,就可以找下一个了
break
return np.asarray(img_src_val_list)
Huffman_encode_dict = {}
if __name__ == '__main__':
path = "./yao.png"
src_img = cv2.imread(path)
# 记录原始图像的尺寸,后续还原图像要用到
src_img_w, src_img_h = src_img.shape[:2]
# 把图像展开成一个行向量
src_img_ravel = src_img.ravel()
print('原图展开长度', len(src_img_ravel))
# {pixel_value:count},保存原始图像每个像素对应出现的次数,也就是直方图
hist_dict = {}
# 得到原始图像的直方图,出现次数为0的元素(像素值)没有加入
for p in src_img_ravel:
if p not in hist_dict:
hist_dict[p] = 1
else:
hist_dict[p] += 1
# 构造哈夫曼树
huffman_root_node = createTree(hist_dict)
# 遍历哈夫曼树,并得到每个元素的编码,保存到Huffman_encode_dict,这是全局变量
walkTree_VLR(huffman_root_node)
# global Huffman_encode_dict
print('哈夫曼编码字典:', Huffman_encode_dict)
# 根据编码字典编码原始图像得到二进制编码数据字符串
img_encode = encodeImage(src_img_ravel, Huffman_encode_dict)
# print(img_encode)
# 把二进制编码数据字符串写入到文件中,后缀为bin
writeBinImage(img_encode, 'huffman_bin_img_file.bin')
print('哈夫曼编码长度为:', len(img_encode))
# 读取编码的文件,得到二进制编码数据字符串
img_read_code = readBinImage('huffman_bin_img_file.bin', len(img_encode))
# 解码二进制编码数据字符串,得到原始图像展开的向量
# 这是根据哈夫曼树进行解码的方式
img_src_val_array = decodeHuffman(img_read_code, huffman_root_node)
img_src_val_array2 = decodeHuffmanByDict(img_read_code, Huffman_encode_dict)
# 确保解码的数据与原始数据大小一致
assert len(img_src_val_array) == src_img_w * src_img_h * 3
# 恢复原始二维图像
img_decode = np.reshape(img_src_val_array, [src_img_w, src_img_h, 3])
# 展示图片
# 计算平均编码长度和编码效率
total_code_len = 0
total_code_num = sum(hist_dict.values())
avg_code_len = 0
I_entropy = 0
for key in hist_dict.keys():
count = hist_dict[key]
code_len = len(Huffman_encode_dict[key])
prob = count / total_code_num
avg_code_len += prob * code_len
I_entropy += -(prob * math.log2(prob))
S_eff = I_entropy / avg_code_len
print("平均编码长度为:{:.3f}".format(avg_code_len))
print("编码效率为:{:.6f}".format(S_eff))
# 压缩率
ori_size = 3 * src_img_w * src_img_h * 8 / (1024 * 8)
comp_size = len(img_encode) / (1024 * 8)
comp_rate = 1 - comp_size / ori_size
print('原图灰度图大小', ori_size, 'KB 压缩后大小', comp_size, 'KB 压缩率', comp_rate, '%')
cv2.imshow('src_img', src_img) # 显示图片
cv2.imshow('img_decode', img_decode) # 显示图片
cv2.waitKey(0)
cv2.destroyAllWindows()
界面窗口程序
main.py
import math
import sys
import cv2
import numpy as np
from PySide2.QtCore import QObject, QFile, Signal, QTimer
from PySide2.QtGui import QImage, QPixmap
from PySide2.QtWidgets import *
from PySide2.QtUiTools import QUiLoader
from PySide2 import QtCore
from PySide2 import QtGui
from hfm import createTree, walkTree_VLR, Huffman_encode_dict, encodeImage, decodeHuffman, decodeHuffmanByDict
class MainWindow(QMainWindow):
def __init__(self):
super().__init__()
self.img_encode = None
self.huffman_root_node = None
self.src_img_h = None
self.src_img_w = None
self.src_img_ravel = None
self.hist_dict = {}
qfile = QFile("ui/main.ui")
qfile.open(QFile.ReadOnly)
qfile.close()
self.ui = QUiLoader().load(qfile)
self.initBtn()
def initBtn(self):
self.ui.btn.clicked.connect(self.selectImage)
self.ui.btn1.clicked.connect(self.getFrequency)
self.ui.btn2.clicked.connect(self.getHFM)
self.ui.btn3.clicked.connect(self.getEfficiency)
self.ui.btn4.clicked.connect(self.encodeToImage)
def selectImage(self):
filePath, fileType = QFileDialog.getOpenFileName(
self, # 父窗口对象
"选择你要上传的图片", # 标题
)
fileType = filePath.split('.')[-1]
if fileType in ['jpg', 'bmp', 'png', 'webp']:
img = cv2.imread(filePath) # 读取图片文件,返回numpy数组
pixmap = QtGui.QPixmap(filePath)
pixmap = pixmap.scaled(self.ui.label.size())
self.ui.label.setPixmap(pixmap)
self.ui.label.raise_()
self.src_img_w, self.src_img_h = img.shape[:2]
self.src_img_ravel = img.ravel()
def getFrequency(self):
self.ui.textBrowser.clear()
for p in self.src_img_ravel:
if p not in self.hist_dict:
self.hist_dict[p] = 1
else:
self.hist_dict[p] += 1
# print(self.hist_dict)
self.ui.textBrowser.insertPlainText(f"一共有{len(self.hist_dict)}个像素点\n")
self.ui.textBrowser.insertPlainText(f"长:{self.src_img_h}\n")
self.ui.textBrowser.insertPlainText(f"宽:{self.src_img_w}\n")
self.ui.textBrowser.insertPlainText("像素频率如下:\n")
for k, v in self.hist_dict.items():
kk = str(k)
vv = str(v)
self.ui.textBrowser.insertPlainText(f"{kk}: {vv}\t")
self.ui.textBrowser.raise_()
def getHFM(self):
self.ui.textBrowser.clear()
self.huffman_root_node = createTree(self.hist_dict)
walkTree_VLR(self.huffman_root_node)
global Huffman_encode_dict
self.img_encode = encodeImage(self.src_img_ravel, Huffman_encode_dict)
print('哈夫曼编码长度为:', len(self.img_encode))
# print(self.img_encode)
self.ui.textBrowser.append(f'哈夫曼编码长度为:{len(self.img_encode)}')
self.ui.textBrowser.append('哈夫曼编码如下:\n')
self.ui.textBrowser.insertPlainText(self.img_encode[:10000])
self.ui.textBrowser.raise_()
def getEfficiency(self):
self.ui.textBrowser.clear()
total_code_num = sum(self.hist_dict.values())
avg_code_len = 0
I_entropy = 0
for key in self.hist_dict.keys():
count = self.hist_dict[key]
code_len = len(Huffman_encode_dict[key])
prob = count / total_code_num
avg_code_len += prob * code_len
I_entropy += -(prob * math.log2(prob))
S_eff = I_entropy / avg_code_len
self.ui.textBrowser.append("平均编码长度为:{:.3f}".format(avg_code_len))
self.ui.textBrowser.append("编码效率为:{:.6f}%".format(S_eff*100))
# 压缩率
ori_size = 3 * self.src_img_w * self.src_img_h * 8 / (1024 * 8)
comp_size = len(self.img_encode) / (1024 * 8)
comp_rate = (1 - comp_size / ori_size) * 100
self.ui.textBrowser.append(f'原图灰度图大小: {ori_size:.2f}KB')
self.ui.textBrowser.append(f'压缩后大小: {comp_size:.2f}KB')
self.ui.textBrowser.append(f'压缩率{comp_rate:.2f}%')
self.ui.textBrowser.raise_()
def encodeToImage(self):
img_src_val_array = decodeHuffmanByDict(self.img_encode, Huffman_encode_dict)
img_decode = np.reshape(img_src_val_array, [self.src_img_w, self.src_img_h, 3])
imgRGB = cv2.cvtColor(img_decode, cv2.COLOR_BGR2RGB)
image = QImage(imgRGB.data, imgRGB.shape[1], imgRGB.shape[0], QImage.Format_RGB888)
pixmap = QPixmap.fromImage(image)
pixmap = pixmap.scaled(self.ui.label.size())
self.ui.label.setPixmap(pixmap)
self.ui.label.raise_()
if __name__ == '__main__':
QtCore.QCoreApplication.setAttribute(QtCore.Qt.AA_EnableHighDpiScaling)
app = QApplication(sys.argv)
window = MainWindow()
window.ui.show()
sys.exit(app.exec_())
ui文件
ui/main.ui
<?xml version="1.0" encoding="UTF-8"?>
<ui version="4.0">
<class>MainWindow</class>
<widget class="QMainWindow" name="MainWindow">
<property name="geometry">
<rect>
<x>0</x>
<y>0</y>
<width>562</width>
<height>528</height>
</rect>
</property>
<property name="windowTitle">
<string>MainWindow</string>
</property>
<property name="styleSheet">
<string notr="true"/>
</property>
<widget class="QWidget" name="centralwidget">
<widget class="QLabel" name="label">
<property name="geometry">
<rect>
<x>210</x>
<y>90</y>
<width>321</width>
<height>321</height>
</rect>
</property>
<property name="styleSheet">
<string notr="true">background-color: rgb(255, 255, 255);</string>
</property>
<property name="text">
<string/>
</property>
<property name="alignment">
<set>Qt::AlignLeading|Qt::AlignLeft|Qt::AlignTop</set>
</property>
<property name="wordWrap">
<bool>true</bool>
</property>
</widget>
<widget class="QPushButton" name="btn">
<property name="geometry">
<rect>
<x>290</x>
<y>420</y>
<width>151</width>
<height>31</height>
</rect>
</property>
<property name="styleSheet">
<string notr="true">background-color: rgb(255, 255, 255);</string>
</property>
<property name="text">
<string>选择图片</string>
</property>
</widget>
<widget class="QLabel" name="title">
<property name="geometry">
<rect>
<x>0</x>
<y>10</y>
<width>551</width>
<height>51</height>
</rect>
</property>
<property name="styleSheet">
<string notr="true">font: 20pt "黑体";</string>
</property>
<property name="text">
<string>哈夫曼图片编码</string>
</property>
<property name="alignment">
<set>Qt::AlignCenter</set>
</property>
</widget>
<widget class="QPushButton" name="btn1">
<property name="geometry">
<rect>
<x>30</x>
<y>90</y>
<width>151</width>
<height>31</height>
</rect>
</property>
<property name="styleSheet">
<string notr="true">background-color: rgb(255, 255, 255);</string>
</property>
<property name="text">
<string>获取图片信息</string>
</property>
</widget>
<widget class="QPushButton" name="btn4">
<property name="geometry">
<rect>
<x>30</x>
<y>380</y>
<width>151</width>
<height>31</height>
</rect>
</property>
<property name="styleSheet">
<string notr="true">background-color: rgb(255, 255, 255);</string>
</property>
<property name="text">
<string>哈夫曼编码解码为图片</string>
</property>
</widget>
<widget class="QPushButton" name="btn3">
<property name="geometry">
<rect>
<x>30</x>
<y>290</y>
<width>151</width>
<height>31</height>
</rect>
</property>
<property name="styleSheet">
<string notr="true">background-color: rgb(255, 255, 255);</string>
</property>
<property name="text">
<string>查看压缩效率</string>
</property>
</widget>
<widget class="QPushButton" name="btn2">
<property name="geometry">
<rect>
<x>30</x>
<y>180</y>
<width>151</width>
<height>31</height>
</rect>
</property>
<property name="styleSheet">
<string notr="true">background-color: rgb(255, 255, 255);</string>
</property>
<property name="text">
<string>获取哈夫曼编码</string>
</property>
</widget>
<widget class="QTextBrowser" name="textBrowser">
<property name="geometry">
<rect>
<x>210</x>
<y>90</y>
<width>321</width>
<height>321</height>
</rect>
</property>
</widget>
</widget>
<widget class="QMenuBar" name="menubar">
<property name="geometry">
<rect>
<x>0</x>
<y>0</y>
<width>562</width>
<height>22</height>
</rect>
</property>
</widget>
<widget class="QStatusBar" name="statusbar"/>
</widget>
<resources/>
<connections/>
</ui>















 1246
1246

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









