






1.用于目标检测的数据集划分
目标检测数据集文件结构如下所示:
而yolo数据集标注完后往往如下图所示
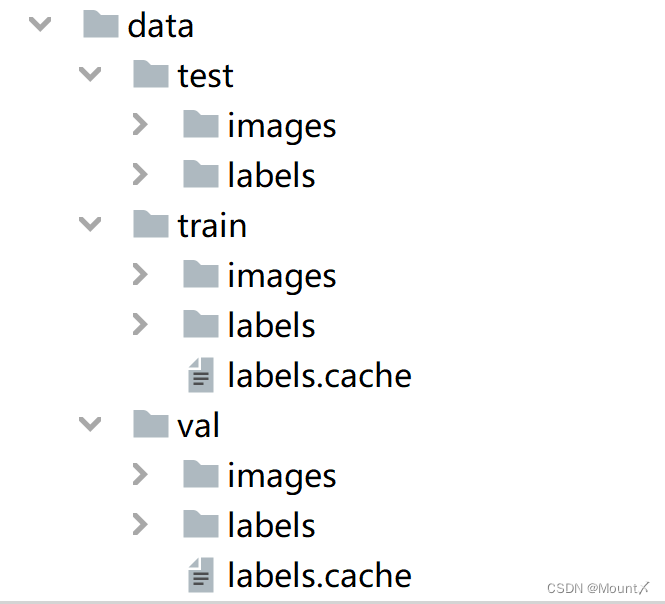

所以现在 需要进行数据划分,将数据集里的图片和标签按照比例进行划分,代码如下所示:
import os
import random
from shutil import copy2
# 判断是否存在目标文件夹,不存在则创建---->创建train\val\test文件夹
def create_folder(new_file_path, split_names):
if os.path.isdir(new_file_path):
pass
else:
os.makedirs(new_file_path)
for split_name in split_names:
split_path = new_file_path + "/" + split_name
if os.path.isdir(split_path):
pass
else:
os.makedirs(split_path)
split_images_path = split_path + "/images"
split_labels_path = split_path + "/labels"
os.makedirs(split_images_path)
os.makedirs(split_labels_path)
print(split_path + "创建成功")
print("文件夹创建成功")
def data_split(old_path, new_file_path, labels_path, split_rate):
current_data_path = old_path
current_all_data = os.listdir(current_data_path)
current_data_length = len(current_all_data)
current_data_index_list = list(range(current_data_length))
random.shuffle(current_data_index_list)
train_images_path = os.path.join(new_file_path, 'train/images/')
val_images_path = os.path.join(new_file_path, 'val/images/')
test_images_path = os.path.join(new_file_path, 'test/images/')
train_labels_path = os.path.join(new_file_path, 'train/labels/')
val_labels_path = os.path.join(new_file_path, 'val/labels/')
test_labels_path = os.path.join(new_file_path, 'test/labels/')
train_stop_flag = current_data_length * split_rate[0]
val_stop_flag = current_data_length * (split_rate[0] + split_rate[1])
current_idx = 0
train_num = 0
val_num = 0
test_num = 0
# 图片复制到文件夹中
for i in current_data_index_list:
src_img_path = os.path.join(current_data_path, current_all_data[i])
txt_name = current_all_data[i].split(".")[0]+'.txt'
src_label_path =os.path.join(labels_path, txt_name)
if current_idx < train_stop_flag:
copy2(src_img_path, train_images_path)
copy2(src_label_path, train_labels_path)
train_num += 1
elif current_idx < val_stop_flag:
copy2(src_img_path, val_images_path)
copy2(src_label_path, val_labels_path)
val_num += 1
else:
copy2(src_img_path, test_images_path)
copy2(src_label_path, test_labels_path)
test_num += 1
current_idx += 1
print(f'第{current_idx}条数据划分完成')
print("=======================划分完成======================")
print("数据集:", current_idx)
print("训练集:", train_num)
print("验证集:", val_num)
print("测试集:", test_num)
if __name__ == '__main__':
# 图片文件夹路径
file_path = "./images"
# yolo标签路径
labels_path = "./labels"
# 新文件路径
new_file_path = "./data"
# 划分数据比例7:2:1
split_rate = [0.7, 0.2, 0.1]
# 目标文件夹下创建文件夹
split_names = ['train', 'val', 'test']
# 创建文件夹
create_folder(new_file_path, split_names)
# 数据划分
data_split(file_path, new_file_path, labels_path, split_rate)
代码运行结果如图所示:

2.用于分类模型的数据集划分
运行前
运行后
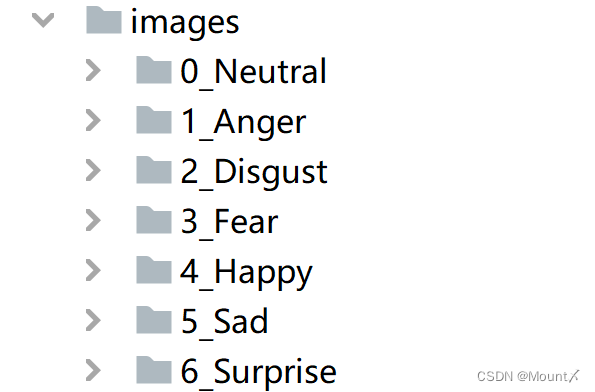
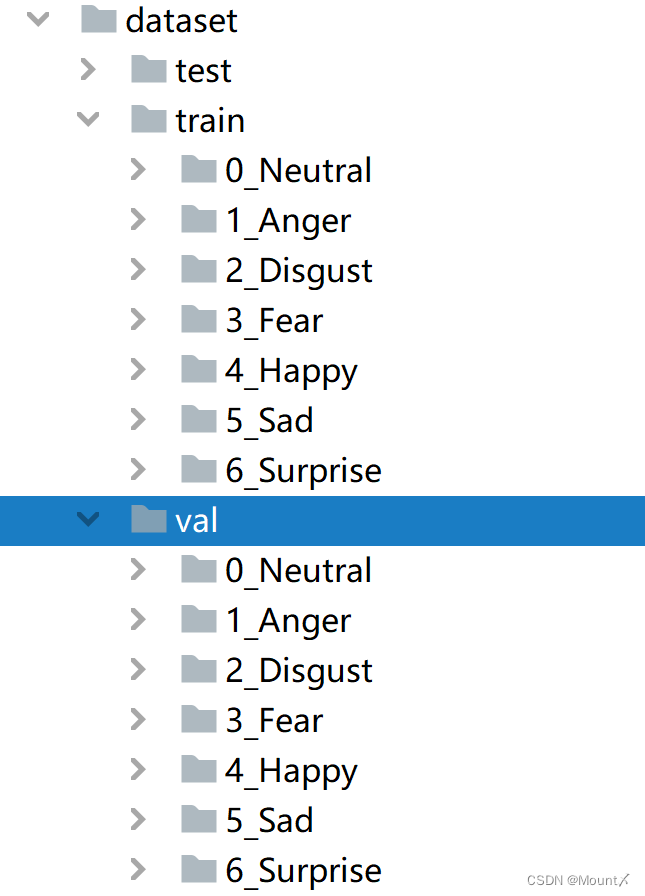
# 工具类
import os
import random
from shutil import copy2
def data_set_split(src_data_folder, target_data_folder, split_rate):
train_scale = split_rate[0]
val_scale = split_rate[1]
test_scale = split_rate[2]
print("开始数据集划分")
class_names = os.listdir(src_data_folder)
# 在目标目录下创建文件夹
split_names = ['train', 'val', 'test']
for split_name in split_names:
split_path = os.path.join(target_data_folder, split_name)
if os.path.isdir(split_path):
pass
else:
os.makedirs(split_path)
# 然后在split_path的目录下创建类别文件夹
for class_name in class_names:
class_split_path = os.path.join(split_path, class_name)
if os.path.isdir(class_split_path):
pass
else:
os.makedirs(class_split_path)
# 按照比例划分数据集,并进行数据图片的复制
# 首先进行分类遍历
for class_name in class_names:
current_class_data_path = os.path.join(src_data_folder, class_name)
current_all_data = os.listdir(current_class_data_path)
current_data_length = len(current_all_data)
current_data_index_list = list(range(current_data_length))
random.shuffle(current_data_index_list)
train_folder = os.path.join(os.path.join(target_data_folder, 'train'), class_name)
val_folder = os.path.join(os.path.join(target_data_folder, 'val'), class_name)
test_folder = os.path.join(os.path.join(target_data_folder, 'test'), class_name)
train_stop_flag = current_data_length * train_scale
val_stop_flag = current_data_length * val_scale + train_stop_flag
current_idx = 0
train_num = 0
val_num = 0
test_num = 0
for i in current_data_index_list:
src_img_path = os.path.join(current_class_data_path, current_all_data[i])
if current_idx < train_stop_flag:
copy2(src_img_path, train_folder)
train_num = train_num + 1
elif current_idx < val_stop_flag:
copy2(src_img_path, val_folder)
val_num = val_num + 1
else:
copy2(src_img_path, test_folder)
test_num = test_num + 1
current_idx = current_idx + 1
print("*********************************{}*************************************".format(class_name))
print(
"{}类按照{}:{}:{}的比例划分完成,一共{}张图片".format(class_name, train_scale, val_scale, test_scale, current_data_length))
print("训练集{}:{}张".format(train_folder, train_num))
print("验证集{}:{}张".format(val_folder, val_num))
print("测试集{}:{}张".format(test_folder, test_num))
if __name__ == '__main__':
src_data_folder = "images"
target_data_folder = "dataset"
split_rate = [0.7, 0.2, 0.1]
data_set_split(src_data_folder, target_data_folder, split_rate)
运行结果
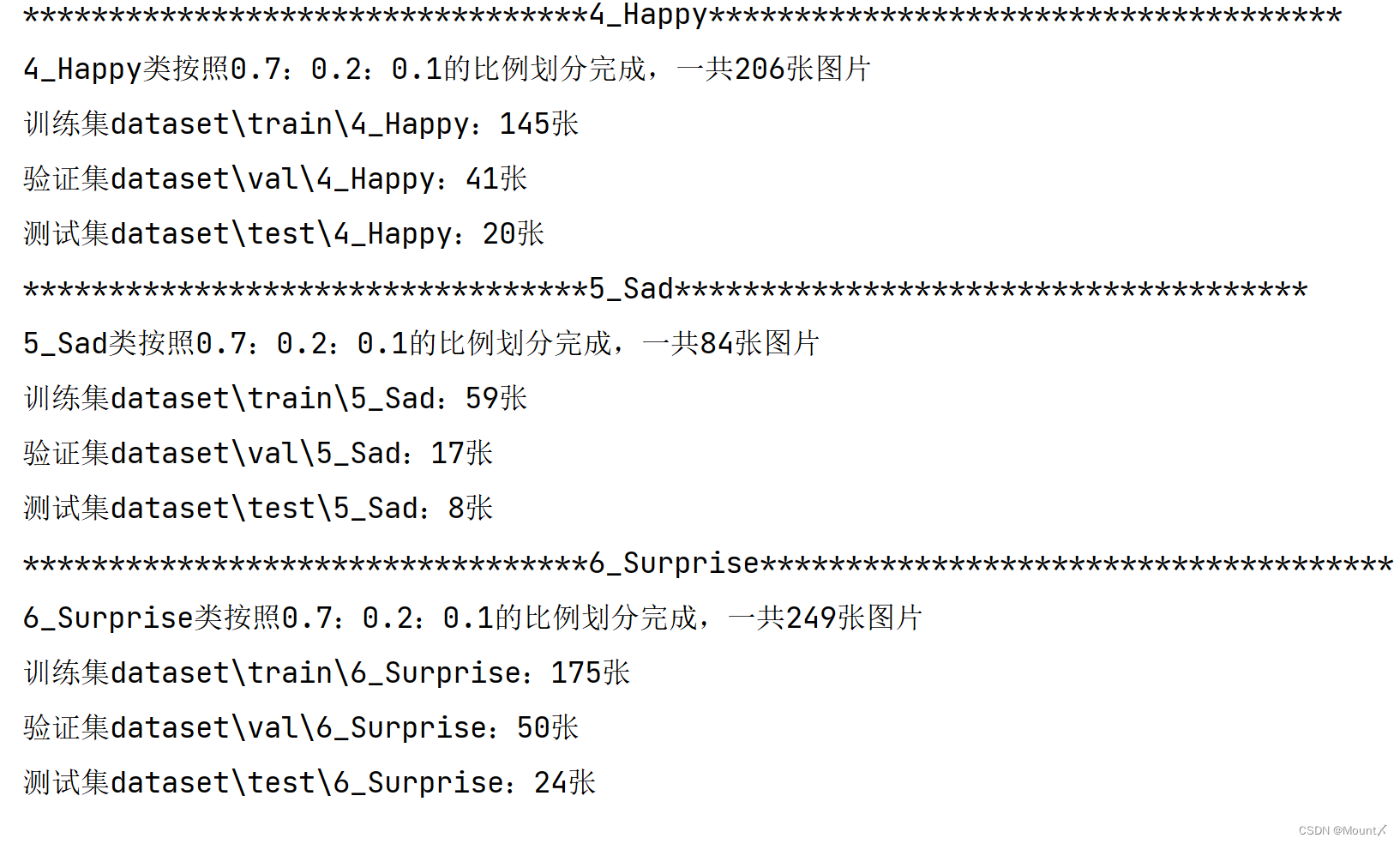















 1120
1120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









