







今天完成了哨兵的部署,由于后续需要部署cluster集群,作者也不想设置太多容器,就决定先把这些操作记录下来,然后再把创建的容器删除。
对于哨兵配置完的直观感受就是:类似于从服务器的操作流程,最终能够在主服务器挂掉之后选择一个从服务器替代,并且如果先前的主服务器恢复,哨兵还能将它选择为从服务器。
流程是类似的,都是先创建配置文件,指定哨兵的工作端口、监控对象信息、日志文件位置:

最后的2表示:至少需要2台哨兵节点才能认定该主服务器失效。换句话说就是,一个哨兵可能发现主服务器挂掉了,但是这只是它发现的情况,并不一定是实实在在发生的事。所以它只是把主服务器这种情况判断为sdown,即“主观下线”。这时,这个哨兵就不再为主服务器监听了。但其他服务器要不要和它一样放弃监听呢?这就要求所有的服务器都要判断主服务器的状态。
如上面的配置,至少需要2台哨兵节点才能认定该主服务器失效。也就是说,在上面的例子中只要再出现一个哨兵发现主服务器失效,原本status=sdown、主观下线的主服务器这下子是真的可以判断下线了,变成“客观下线”状态(status=odown)。这时哨兵们就会马不停蹄地找到某个得力从服务器,将其选择为主服务器。
配置完文件,记得先设置文件夹权限,再创建启动哨兵节点的容器。


-v挂载数据卷,把/opt/server和容器的redisConfig文件绑定。

作者第一次哨兵信息检验的时候就遇到status=sdown,也就是检测到主服务器掉线。作者今天花了一些功夫才发现原因:之前作者存在重启redis-master主服务器的操作,导致主服务器的ip变化,并且主从关系并没有改变,最终结果就是主从服务器断连,并且哨兵还没开始监听主服务器,无法将从服务器转化为主服务器。
这种ip变化是一种动态变化,也就是说,在每一次docker运行过程中,重启一次就会改变一次。但是如果关闭所有容器,重启docker之后,所有容器的ip都会恢复从前,这样就能恢复主服务器和从服务器之间的连接,也能恢复哨兵的监听功能。因为主服务器的ip一旦正确,就能与所有节点(不管是从服务器还是哨兵)的配置文件的ip对应,关系也就确定下来。最终哨兵信息如下图所示。
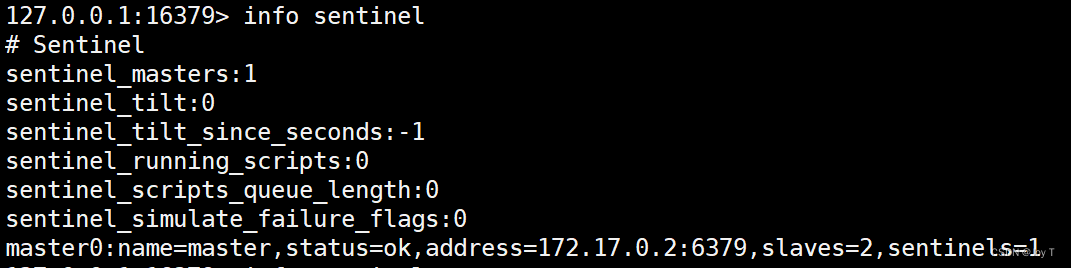
如图,最后一行哨兵的status=ok,且master有2个slaves和一个sentinel哨兵,再为主服务器配置一个哨兵,最终结果如下:
![]()
sentinels=2,这样就会有两个哨兵监听主服务器了。我们模拟主服务器掉线,即停止redis-master容器运行(注意其端口为6379),等一段时间后查看redis集群状态:

作者当时没截图,上面的截图是新的,端口不一样。重点关注新的master已经产生,并且其从服务器个数connected_slaves=1。当我们通过start原本关掉的6379服务器时,它会以从服务器的状态出现,这就体现了哨兵的作用。
















 384
384











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











