







 本文介绍了倒排表在信息检索中的应用,包括分词、停用词移除、倒排索引构建、压缩以及查询处理的过程,展示了如何通过这种结构快速定位包含特定词项的文档。
本文介绍了倒排表在信息检索中的应用,包括分词、停用词移除、倒排索引构建、压缩以及查询处理的过程,展示了如何通过这种结构快速定位包含特定词项的文档。
倒排表(Inverted Index)是信息检索领域中常用的一种数据结构,用于快速查找包含特定词项的文档或文本片段。它将文档中的每个词项(或者单词)与包含该词项的文档列表关联起来。
通常,倒排表包含两部分:
- 词项(Term): 文档中的单词或短语,如“apple”、“banana”等。
- 文档列表(Document List): 包含特定词项的文档的列表或索引,每个文档可以用唯一标识符表示,比如文档ID。
倒排表的构建过程通常分为以下几个步骤:
- 文档分词(Tokenization): 将文档拆分成词项或单词。
- 去除停用词(Stopword Removal): 去除常见的停用词,如“and”、“the”等,以减少索引的大小。
- 构建倒排索引(Inverted Index Construction): 遍历文档集合,为每个词项构建对应的倒排表,记录包含该词项的文档列表。
- 索引压缩(Index Compression): 可以采用一些压缩技术来减少倒排表的存储空间。
- 查询处理(Query Processing): 当用户查询某个词项时,通过倒排表快速定位包含该词项的文档列表,从而加速搜索过程。
例子
假设我们有以下三个简短的文档:
- 文档1: “Apple is sweet”
- 文档2: “Banana is yellow and sweet”
- 文档3: “Apple and banana are fruits”
我们需要建立一个倒排索引,首先进行分词和去除停用词(如"is"、“and”、“are”),然后将剩余的词项用来构建倒排索引。
分词后的结果:
- 文档1: [“Apple”, “sweet”]
- 文档2: [“Banana”, “yellow”, “sweet”]
- 文档3: [“Apple”, “banana”, “fruits”]
倒排索引表:
- Apple: [1, 3]
- Banana: [2, 3]
- sweet: [1, 2]
- yellow: [2]
- fruits: [3]
解释:
- Apple:出现在文档1和文档3中。
- Banana:出现在文档2和文档3中。
- sweet:出现在文档1和文档2中。
- yellow:只出现在文档2中。
- fruits:只出现在文档3中。
当用户查询“Apple”时,系统会查找倒排索引,发现“Apple”在文档1和文档3中出现。如果查询是“sweet”,则系统找到文档1和文档2,因为这两个文档都包含词“sweet”。
这种索引结构使得检索效率非常高,因为它允许系统直接通过查找关键词来定位到包含该词的所有文档,而不需要逐个文档检查。
示例1代码演示
首先,我们需要准备一些文档,并对其进行分词和去除停用词。然后,我们将构建倒排索引,并展示如何使用这个索引来响应查询。
# 导入必要的库
import re
from collections import defaultdict
# 准备文档
documents = {
1: "Apple is sweet",
2: "Banana is yellow and sweet",
3: "Apple and banana are fruits"
}
# 定义停用词
stopwords = set(["is", "and", "are", "the"])
# 函数:分词并去除停用词
def tokenize(text):
# 使用正则表达式去除非字母字符,并转换为小写
words = re.findall(r'\b\w+\b', text.lower())
# 去除停用词
return [word for word in words if word not in stopwords]
# 建立倒排索引
inverted_index = defaultdict(list)
for doc_id, text in documents.items():
words = tokenize(text)
for word in words:
if doc_id not in inverted_index[word]:
inverted_index[word].append(doc_id)
# 打印倒排索引
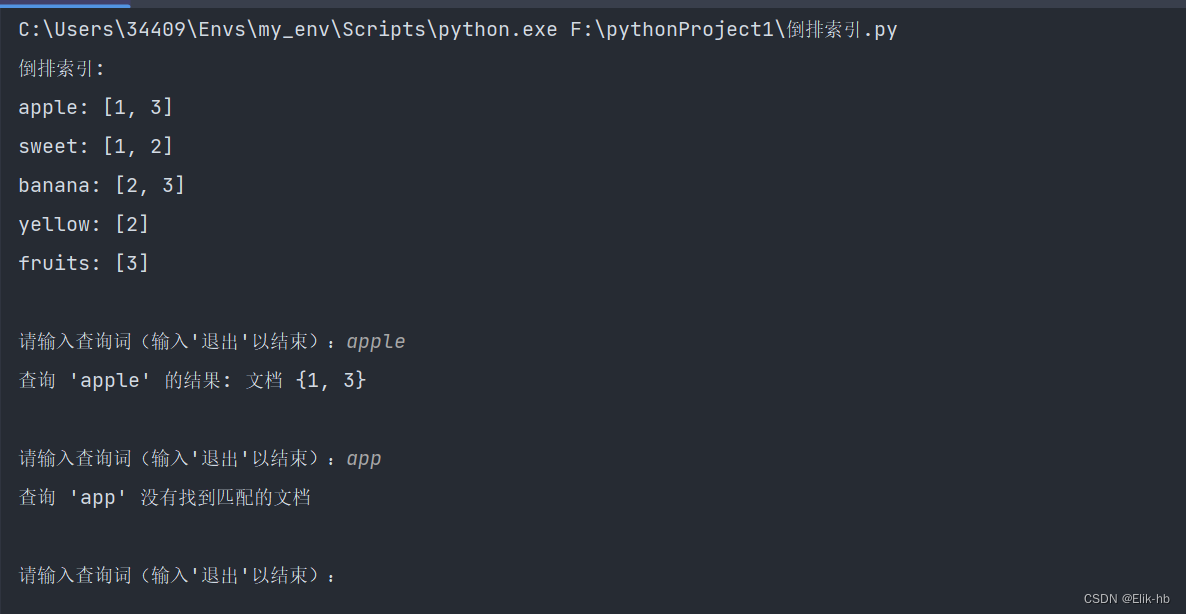
print("倒排索引:")
for word, doc_ids in inverted_index.items():
print(f"{word}: {doc_ids}")
# 查询函数
def search(query):
query_words = tokenize(query)
matched_documents = set()
for word in query_words:
if word in inverted_index:
matched_documents.update(inverted_index[word])
return matched_documents
# 示例查询
query = "Apple"
result = search(query)
print(f"\n查询 '{query}' 的结果: 文档 {result}")
代码解释:
- 导入库:使用
re进行正则表达式操作,defaultdict用于方便地构建倒排索引。 - 文档和停用词:定义了三个简单的文档和一些常见的停用词。
- 分词函数:将文本转换为小写,并通过正则表达式匹配单词,最后移除停用词。
- 构建倒排索引:对每个文档进行分词,然后将每个词与出现该词的文档ID关联起来。
- 查询函数:接收一个查询字符串,分词后在倒排索引中查找匹配的文档。
演示结果
示例2代码演示
实现支持模糊查询
模糊查询方法包括前缀匹配、子串匹配和编辑距离匹配
我们更改代码支持前缀匹配和子串匹配和精准匹配查询
解释意思
子串
在计算机科学和编程中,子串(substring)是一个字符串的一部分。具体来说,一个字符串的子串是从这个字符串中取出的一段连续的字符序列。子串可以是从字符串的任何位置开始,长度可以是任意的,但必须是连续的字符序列。
举个例子,考虑字符串 “banana”:
- “ban” 是 “banana” 的子串。
- “ana” 是 “banana” 的子串。
- “na” 是 “banana” 的子串。
- “banana” 是 “banana” 自己的子串。
- “bana” 也是 “banana” 的子串。
但像 “bnn” 这样不连续的字符序列就不是 “banana” 的子串。
在搜索查询中,子串匹配意味着查询词可以匹配到包含该查询词的部分或全部字符序列的任何文档。例如,在子串匹配模式下,查询词 “ana” 可以匹配到包含 “banana” 的文档,因为 “ana” 是 “banana” 的子串。
前缀
前缀是指一个字符串的开头部分。具体来说,如果字符串 B 是字符串 A 的前缀,那么字符串 A 的开头部分与字符串 B 完全相同,且字符串 B 的长度不超过字符串 A 的长度。
举个例子,考虑字符串 “banana”:
- “b” 是 “banana” 的前缀。
- “ban” 是 “banana” 的前缀。
- “banana” 是 “banana” 自己的前缀。
但 “nan” 不是 “banana” 的前缀,因为它不是从字符串开头开始的。
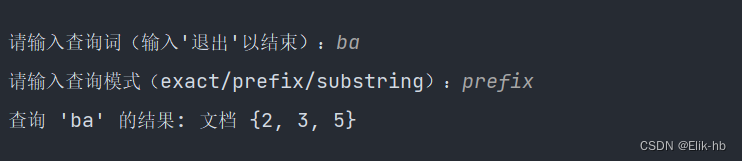
在搜索查询中,前缀匹配意味着查询词可以匹配到以该查询词开头的任何词。例如,在前缀匹配模式下,查询词 “ban” 可以匹配到 “banana”,因为 “banana” 以 “ban” 开头。
import re
from collections import defaultdict
# 准备文档
documents = {
1: "Apple is sweet",
2: "Banana is yellow and sweet",
3: "Apple and banana are fruits",
4: "Apple is a fruit",
5: "Ba is a fruit",
6: "pp is a fruit"
}
# 定义停用词
stopwords = set(["is", "and", "are", "the"])
# 函数:分词并去除停用词
def tokenize(text):
words = re.findall(r'\b\w+\b', text.lower())
return [word for word in words if word not in stopwords]
# 建立倒排索引
inverted_index = defaultdict(list)
for doc_id, text in documents.items():
words = tokenize(text)
for word in words:
if doc_id not in inverted_index[word]:
inverted_index[word].append(doc_id)
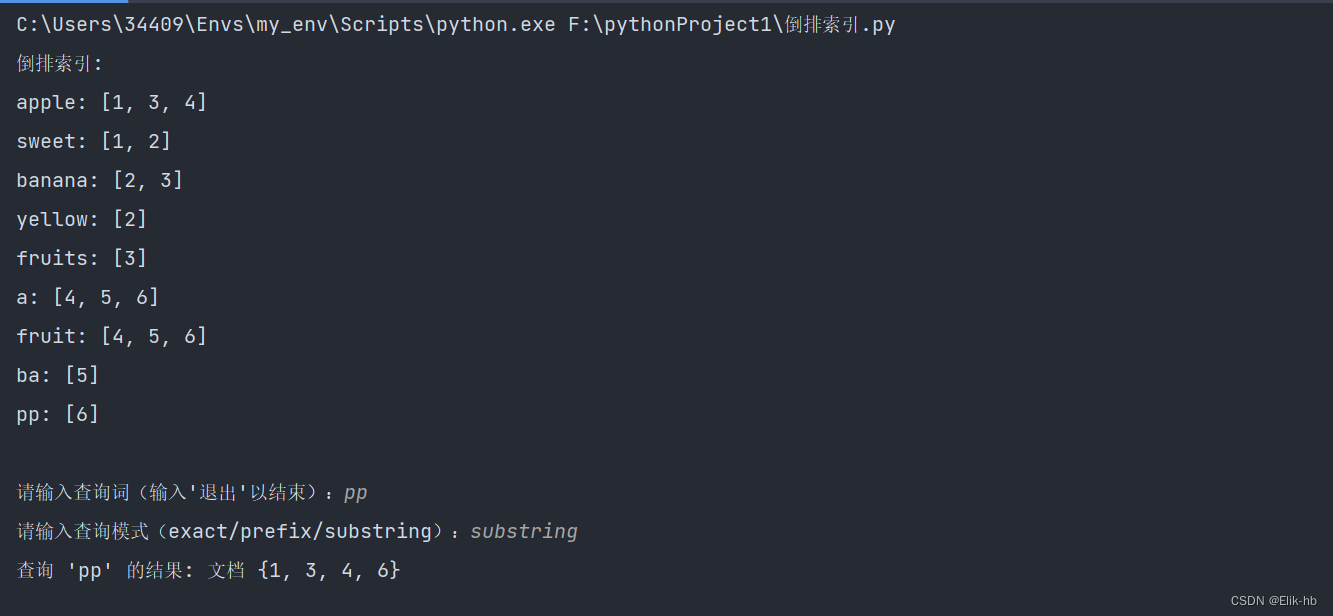
print("倒排索引:")
for word, doc_ids in inverted_index.items():
print(f"{word}: {doc_ids}")
# 查询函数
def search(query, mode="exact"):
query_words = tokenize(query)
matched_documents = set()
if mode == "exact":
for word in query_words:
if word in inverted_index:
matched_documents.update(inverted_index[word])
elif mode == "prefix":
for word in query_words:
for key in inverted_index:
if key.startswith(word):
matched_documents.update(inverted_index[key])
elif mode == "substring":
for word in query_words:
for key in inverted_index:
if word in key:
matched_documents.update(inverted_index[key])
return matched_documents
# 持续接收用户查询
while True:
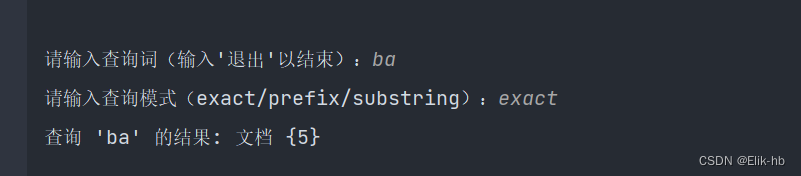
query = input("\n请输入查询词(输入'退出'以结束):")
if query.lower() == "退出":
break
mode = input("请输入查询模式(exact/prefix/substring):")
if mode not in ["exact", "prefix", "substring"]:
print("无效的查询模式,使用默认模式 'exact'")
mode = "exact"
result = search(query, mode)
if result:
print(f"查询 '{query}' 的结果: 文档 {result}")
else:
print(f"查询 '{query}' 没有找到匹配的文档")
代码解释:
- 查询模式:增加了三种查询模式:
exact:精确匹配,查询词必须与词项完全匹配。prefix:前缀匹配,查询词是词项的前缀。substring:子串匹配,查询词是词项的子串。
- 查询函数:在
search函数中,根据用户选择的模式进行不同的匹配逻辑。 - 用户交互:在接收查询词后,要求用户输入查询模式,默认为
exact。
运行



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











