









详细代码和介绍可以在笔者资源里获取
搭建一个房屋推荐系统使用到的技术栈
前端技术栈
- HTML/CSS:用于构建网页的结构和样式。
- JavaScript:用于实现交互功能。
- UI框架:
- Bootstrap:用于快速开发响应式布局的CSS框架。
后端技术栈
- 编程语言:
- JavaScript (Node.js):用于构建高性能的服务器端应用。
- Java:用于企业级应用开发。
- Web框架:
- Express.js:用于Node.js的轻量级Web框架。
- 数据库:
- MongoDB:常用的NoSQL数据库,适合存储文档型数据。
- Redis:用于缓存,提高数据访问速度。
数据处理与机器学习
- 推荐系统:
- 协同过滤:基于用户行为进行推荐。
- 内容过滤:基于内容属性进行推荐。
- 混合推荐:结合多种推荐方法提高推荐质量。
部署与运维
- 服务器:
- Nginx:高性能的Web服务器。
1. 创建项目结构

模块说明
Dataloader模块为导入house与data数据到mongodb中,还有生成mongodb用户登录数据
OffineRecommender模块为使用als算法作为离线推荐,基于评分数据的LFM,生成相似矩阵为后面流数据推荐提供参考
StaticRecommender模块为传统的统计推荐,使用查询数据库热门数据进行推荐
StreamingRecommender模块为实时推荐,通过kafka用户实时评分数据做出快速响应,传回推荐列表
Hosue_recommendation为总项目,他的pom管理整个模块的版本
2. pom文件,版本
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.fosu</groupId>
<artifactId>HouseRecommendSystem</artifactId>
<packaging>pom</packaging>
<version>1.0-SNAPSHOT</version>
<modules>
<module>DataLoader</module>
<module>StatisticsRecommender</module>
<module>OfflineRecommender</module>
<module>StreamingRecommender</module>
</modules>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spark.version>3.4.0</spark.version>
<scala.version>2.12</scala.version>
<kafka.version>2.6.0</kafka.version>
<redis.version>3.7.0</redis.version>
<mongodb-driver.version>4.3.1</mongodb-driver.version>
<jblas.version>1.2.1</jblas.version>
<log4j.version>1.2.17</log4j.version>
<slf4j.version>1.7.32</slf4j.version>
<mongodb-spark.version>3.0.1</mongodb-spark.version>
<casbah.version>3.1.1</casbah.version>
</properties>
</project>
3. 服务准备
一,离线推荐服务
主要分为统计性算法、基于 ALS 的协同过滤推荐算法
- 统计性算法:
历史热门房屋统计:根据所有历史评分数据,计算历史评分次数最多的房屋。
最近热门房屋统计:根据评分,按月为单位计算最近时间的月份里面评分数最多的房屋集合。
房屋平均得分统计:根据历史数据中所有用户对房屋的评分,周期性的计算每个房屋的平均得分。 - 基于隐语义模型的协同过滤推荐
采用 ALS 作为协同过滤算法,分别根据 MongoDB 中的用户评分表和房屋
数据集计算用户房屋推荐矩阵以及房屋相似度矩阵。
二,实时推荐服务
实时推荐算法设计
- 使用历史数据计算出来的房屋相似度矩阵:
从 MongoDB 中加载房屋相似度矩阵数据,并将其广播到所有节点,以便在后续计算中快速查找相似房屋。 - 实时评分数据处理:
从 Kafka 中获取用户实时评分数据,并将其转换为评分流,便于后续处理。 - 用户最近评分的获取:
从 Redis 中获取用户最近的 K 次评分数据,作为推荐计算的基础。 - 相似房屋的筛选:
从房屋相似度矩阵中提取与当前房屋相似的 N 个房屋,作为推荐候选列表。5. 推荐优先级计算:
对每个候选房屋,基于用户最近评分数据和房屋相似度,计算其推荐优先级。
推荐优先级的计算公式:

- 推荐结果的保存:
将计算得到的推荐结果保存到 MongoDB 中,便于后续查询和展示。 - Redis 数据更新:
更新用户在 Redis 中的评分记录,确保评分记录的实时性和有效性。
4. 启动准备
1. 启动mongo
sudo /usr/local/mongodb/bin/mongod -config /usr/local/mongodb/data/mongodb.conf
ps -ef | grep mongo
mongosh
使用mongo是因为字段可以随时扩展,符合大数据
2. 启动redis
cd /usr/local/redis
./src/redis-server ./redis.conf
使用redis存储用户最近评分数据,可以快速响应,使用算法推荐
3. 启动kafka,创建topic,监控topic
cd /usr/local/hadoop
./sbin/start-dfs.sh
cd /usr/local/kafka
./bin/zookeeper-server-start.sh config/zookeeper.properties
cd /usr/local/kafka
./bin/kafka-server-start.sh config/server.properties
cd /usr/local/kafka
./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic recommender
cd /usr/local/kafka
bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic recommender
cd /usr/local/kafka
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic recommender --from-beginning
测试
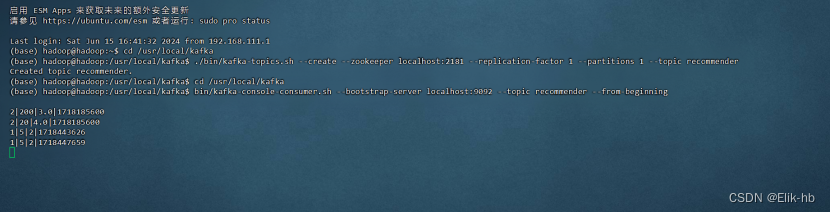
数据传入数据示例:2|20|4.0|1718185600
StreamRec是推荐列表,使用als算法
4. 启动后端express 使用命令npm start
5. 启动写好的nignx进行前端访问
5. 使用评分测试数据
ps 这里使用的是测试数据,具体有真实数据测试就更好了,笔者为了少点数据量就使用了测试数据
选取前1000个房屋进行评分,
创建一个用户ID列表,从 “1” 到 “2000”,代表总共2000个用户。
定义生成随机日期的函数 random_date:生成随机的评论日期。
根据三种概率情况来决定生成日期:
有30%的概率在上市后的前90天内生成日期,模拟上市初期的高关注度。
有10%的概率在每年的夏季(6月1日至8月31日)生成日期,反映夏季可能的高活动量。
其余时间(60%的概率)则在整个时间段内随机选择日期。
生成评分数据:
对每个房屋循环,为每个房屋随机选择评论的用户数量(介于100到1000之间,部分热门房屋可能多达2000个评论)。
每个选中的用户为该房屋生成一个1到5的随机评分。
对于少数房屋(10%的概率),将普遍生成较高的评分(4或5分)
import pandas as pd
import numpy as np
from datetime import datetime, timedelta
import random
# Constants
NUM_USERS = 2000
NUM_HOUSES = 1000
START_DATE = datetime(2020, 1, 1)
END_DATE = datetime(2024, 1, 1)
# Load the dataset
file_path = './final2.csv'
df = pd.read_csv(file_path)
# Select the first 1000 houses
houses_df = df.iloc[:NUM_HOUSES]
# Generate random user IDs
user_ids = [f"{i+1}" for i in range(NUM_USERS)]
# Generate random review dates function, now with periods of increased reviews
def random_date(start, end):
period = random.random()
# 30% of the time, choose a date close to the start date (high interest after listing)
if period < 0.3:
return start + timedelta(days=random.randint(0, 90))
# 10% chance for a date in a typical high activity summer period
elif period < 0.4:
year = random.choice([2020, 2021, 2022, 2023])
start_summer = datetime(year, 6, 1)
end_summer = datetime(year, 8, 31)
return start_summer + timedelta(days=random.randint(0, (end_summer - start_summer).days))
# 60% chance for any time
else:
days = (end - start).days
return start + timedelta(days=random.randint(0, days))
# Initialize empty lists to hold the DataFrame columns
all_user_ids = []
all_house_ids = []
all_ratings = []
all_review_dates = []
# Iterate over each house and assign random ratings by a random subset of users
for house_id in houses_df['house_id']:
num_reviews = random.randint(100, NUM_USERS // 2) # Random number of users reviewing each house
if random.random() < 0.05: # 5% of houses get a lot of attention
num_reviews += NUM_USERS // 2
reviewers = random.sample(user_ids, num_reviews) # Select random users
high_rating = random.random() < 0.1 # 10% chance that house has generally high ratings
for user_id in reviewers:
all_user_ids.append(user_id)
all_house_ids.append(house_id)
rating = random.randint(4, 5) if high_rating else random.randint(1, 5)
all_ratings.append(rating)
all_review_dates.append(random_date(START_DATE, END_DATE))
# Create a DataFrame for the ratings and review dates
ratings_df = pd.DataFrame({
"user_id": all_user_ids,
"house_id": all_house_ids,
"rating": all_ratings,
"review_date": [int(date.timestamp()) for date in all_review_dates]
})
# Display the first few rows to confirm the changes
print(ratings_df.head())
# Save the ratings DataFrame to a CSV file
ratings_df.to_csv('ratings3.csv', index=False)
6. 历史评分数据和房屋数据和用户数据导入到mongodb
启动服务
导入结果
House
rating
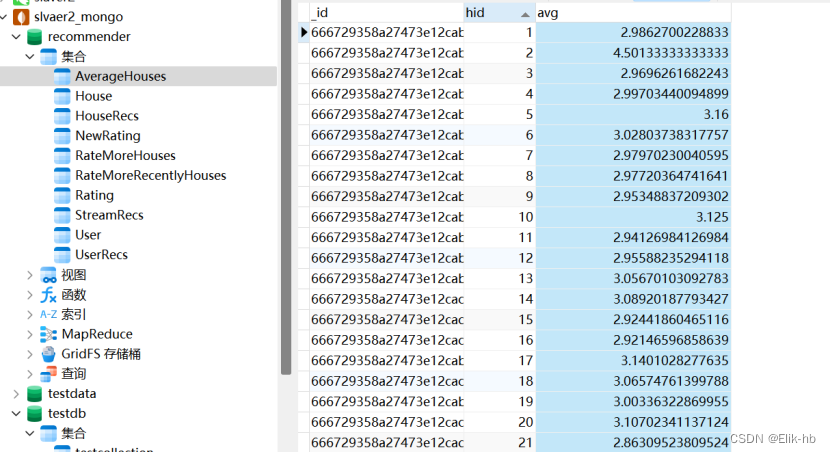
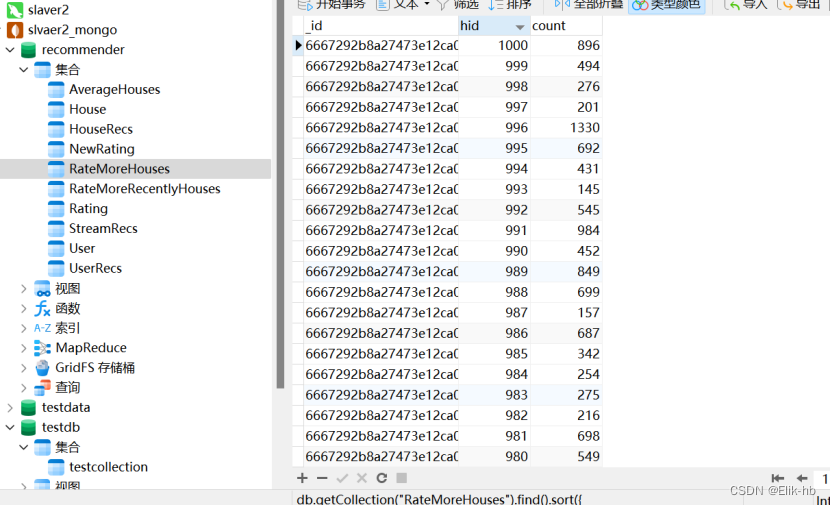
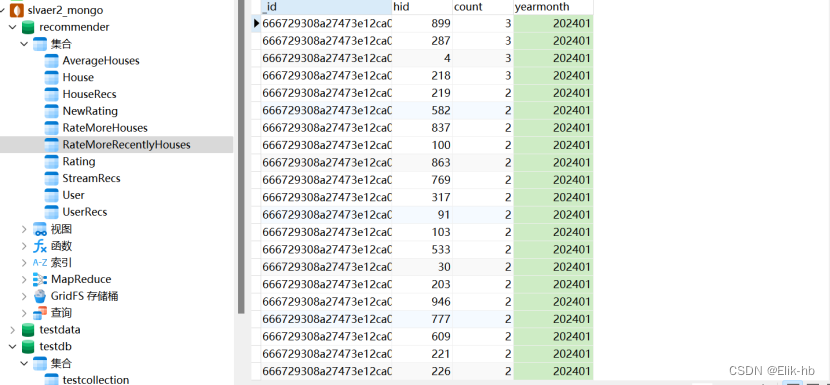
7. 统计分析保存数据到数据库mongodb
val RATE_MORE_HOUSES = “RateMoreHouses”
val RATE_MORE_RECENTLY_HOUSES = “RateMoreRecentlyHouses”
val AVERAGE_HOUSES = “AverageHouses”
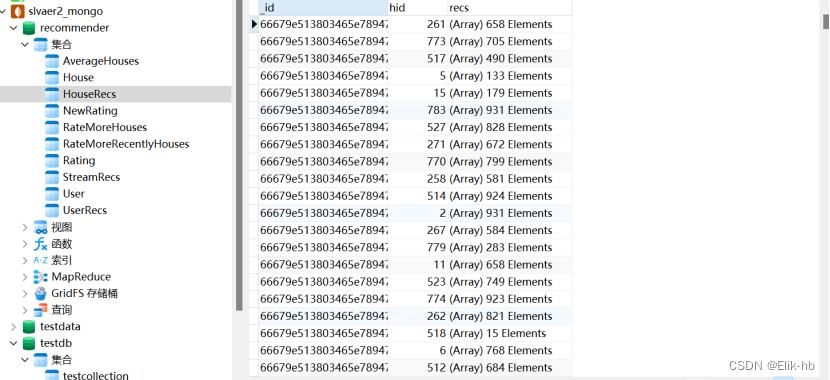
8. ALS基于历史数据进行模型预测推荐
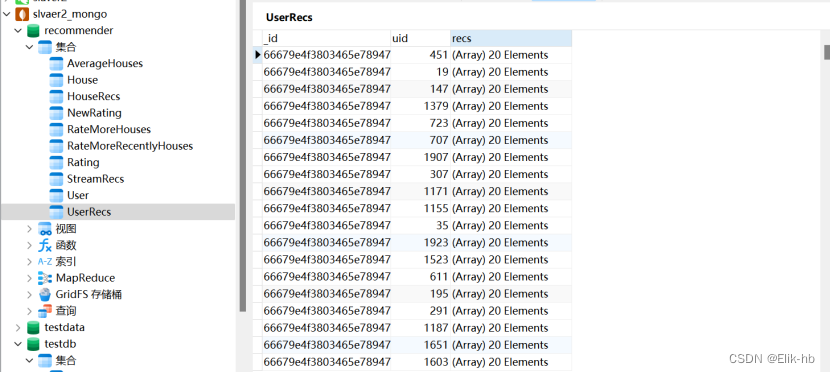
9. 保存用户最近时间段评分数据到redis中
评分数据会随着用户时间来进行实时更新的,而不是一直使用历史数据
启动redis
cd /usr/local/redis
./src/redis-server ./redis.conf
使用可视化界面操作查看导入后的数据
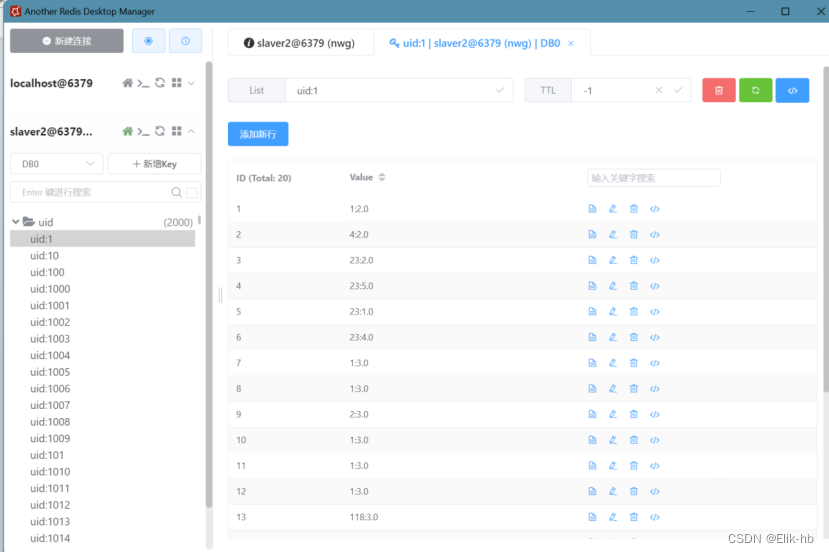
可以看到每一个用户id,都会查看到他最近的20次评分,后面我们就是通过算法来通过房屋相似矩阵来进行运行分析,增加增强因子和减弱因子来判断哪个房屋更加适合推荐给用户。
10. 启动kafka服务
创建主题为recommender,并且启动监听用户传来的数据
cd /usr/local/hadoop
./sbin/start-dfs.sh
cd /usr/local/kafka
./bin/zookeeper-server-start.sh config/zookeeper.properties
cd /usr/local/kafka
./bin/kafka-server-start.sh config/server.properties
cd /usr/local/kafka
./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic recommender
cd /usr/local/kafka
bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic recommender
cd /usr/local/kafka
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic recommender --from-beginning

11. 编写实时处理代码流程,结果会保存到mongo中
保存逻辑是,保存用户新数据到newRating表中,然后推荐列表在StreamRecs中
启动流处理
打开终端,传入测试数据
2|200|3.0|1718185600
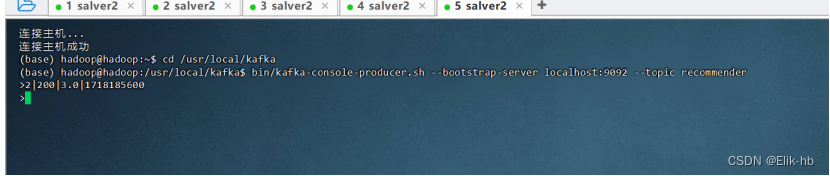
查看是否数据库已经处理成功
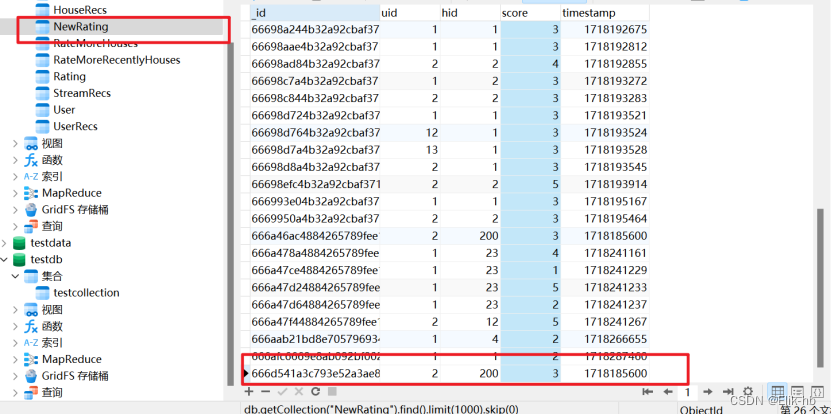
可以看到数据是导入成功了
我们来看一下这个用户的推荐列表

增加新数据来看是否是实时推荐

来查看推荐列表

可以看到推荐列表已经发生了更新,实现了这个功能
12. 设计接口文档
---
## 接口文档
### 1. 提交评分
- **描述**: 提交用户对房屋的评分
- **请求方法**: POST
- **路径**: `/submit_rating`
- **请求体**:
```json
{
"user_id": "string",
"item_id": "string",
"rating": "number",
"timestamp": "number"
}
- 响应:
- 成功:
{ "status": "success" } - 失败:
{ "status": "error", "message": "string" }
- 成功:
2. 获取用户实时的推荐房屋
- 描述: 根据用户ID获取推荐房屋
- 请求方法: GET
- 路径:
/recommendations/:user_id - URL参数:
user_id(number): 用户ID
- 响应:
- 成功:
{ "recommendations": [ { "hid": "number", "score": "number" }, ... ] } - 失败:
{ "status": "error", "message": "string" }
- 成功:
3. 获取历史热门房屋
- 描述: 获取历史评分最多的前6个房屋
- 请求方法: GET
- 路径:
/historical_popular_houses - 响应:
- 成功:
[ { "hid": "number", "count": "number" }, ... ] - 失败:
{ "status": "error", "message": "string" }
- 成功:
4. 获取近期热门房屋
- 描述: 获取最近评分最多的前5个房屋
- 请求方法: GET
- 路径:
/recent_popular_houses - 响应:
- 成功:
[ { "hid": "number", "count": "number", "yearmonth": "number" }, ... ] - 失败:
{ "status": "error", "message": "string" }
- 成功:
5. 获取高质量房屋
- 描述: 获取平均评分最高的前6个房屋
- 请求方法: GET
- 路径:
/high_quality_houses - 响应:
- 成功:
[ { "hid": "number", "avg": "number" }, ... ] - 失败:
{ "status": "error", "message": "string" }
- 成功:
6. 获取房屋相似推荐
- 描述: 根据房屋ID获取相似房屋
- 请求方法: GET
- 路径:
/house_similarity/:house_id - URL参数:
house_id(number): 房屋ID
- 响应:
- 成功:
[ { "hid": "number", "score": "number" }, ... ] - 失败:
{ "status": "error", "message": "string" }
- 成功:
7. 获取房屋详情
- 描述: 根据房屋ID获取房屋详情
- 请求方法: GET
- 路径:
/house_details/:house_id - URL参数:
house_id(number): 房屋ID
- 响应:
- 成功:
{ "hid": "number", "house_region": "string", "url_id": "number", "total_price": "number", "house_rental_area": "number", "house_structure": "string", "house_building_type": "string", "house_building_structure": "string", "house_decoration": "string", "house_listing_time": "string", "house_usage": "string", "house_property": "string", "floor_level": "string", "total_floors": "number", "rooms": "number", "halls": "number", "kitchens": "number", "bathrooms": "number", "standard_orientation": "string", "elevator_ratio": "number", "elevator_status": "string", "mortgage_status": "string" } - 失败:
{ "status": "error", "message": "string" }
- 成功:
8. 获取用户最近评分的房屋
- 描述: 根据用户ID获取最近评分的6个房屋
- 请求方法: GET
- 路径:
/recently_rated_houses/:user_id - URL参数:
user_id(number): 用户ID
- 响应:
- 成功:
[ { "hid": "number", "score": "number", "timestamp": "number" }, ... ] - 失败:
{ "status": "error", "message": "string" }
- 成功:
9. 获取用户评分统计信息
- 描述: 根据用户ID获取评分统计信息,包括用户评分过多少个房屋、用户平均打分、用户最近评分时间以及重复评分最多的房屋
- 请求方法: GET
- 路径:
/user_rating_stats/:user_id - URL参数:
user_id(number): 用户ID
- 响应:
- 成功:
{ "total_houses_rated": "number", "average_score": "number", "latest_rating_time": "string", "most_rated_house": "number" } - 失败:
{ "status": "error", "message": "string" }
- 成功:
10. 获取用户als推荐房屋数据
- 描述: 根据用户ID获取als预测评分的6个房屋
- 请求方法: GET
- 路径:
/user_recommendations/:user_id - URL参数:
user_id(number): 用户ID
- 响应:
- 成功:
[ { "hid": "number", "score": "number", }, ] - 失败:
{ "status": "error", "message": "string" }
- 成功:
13. 设计前端页面
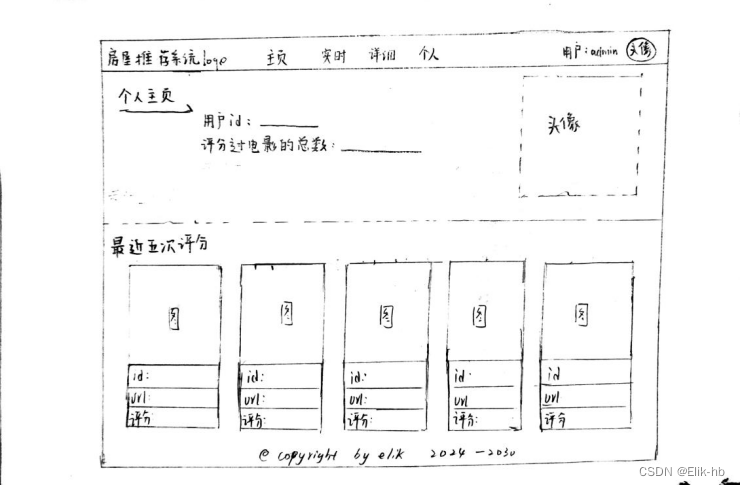
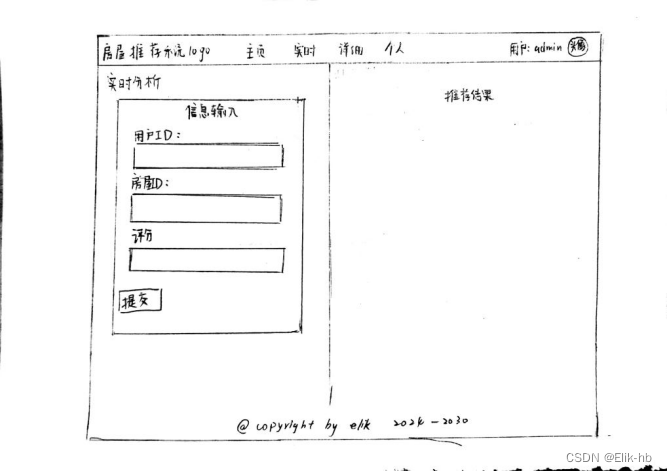
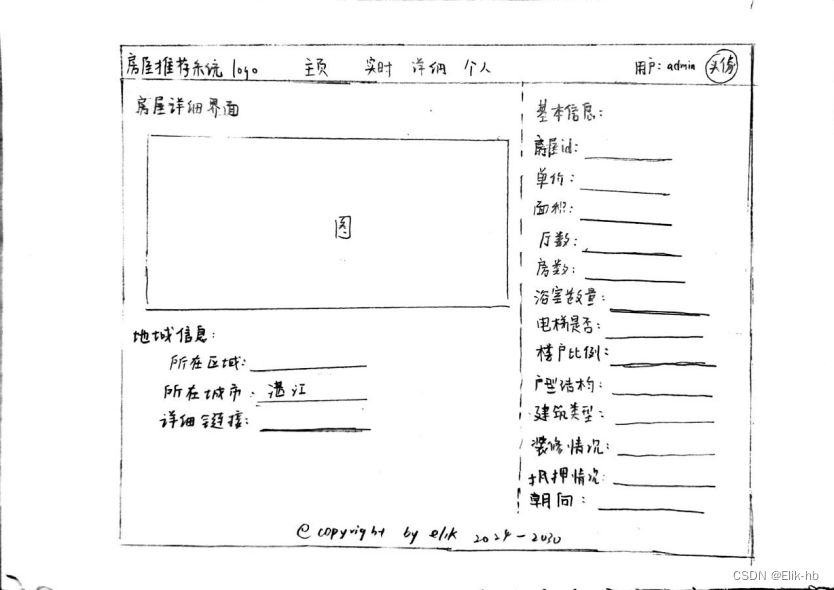
14. 创建node项目
mkdir realtime-recommendation-system
cd realtime-recommendation-system
npm init -y
npm install body-parser@^1.19.0 cookie-parser@^1.4.6 cors@^2.8.5 express@^4.17.1 kafka-node@^5.0.0 mongodb@^3.6.3
echo > index.js
notepad index.js
写入代码
项目目录结构
realtime-recommendation-system/
├── node_modules/
├── package.json
├── package-lock.json
└── index.js
15. 创建nignx项目
访问 Nginx官方下载页面 并下载适用于Windows的最新稳定版本。
然后把写好的前端代码放在html中
如图
16. 联桥测试
1. 启动node服务
2. 启动nignx
17. 网页操作
1. 首先进入登录界面
2. 输入用户登录信息,会根据用户数据库查询,并且更新为用户使用的头像
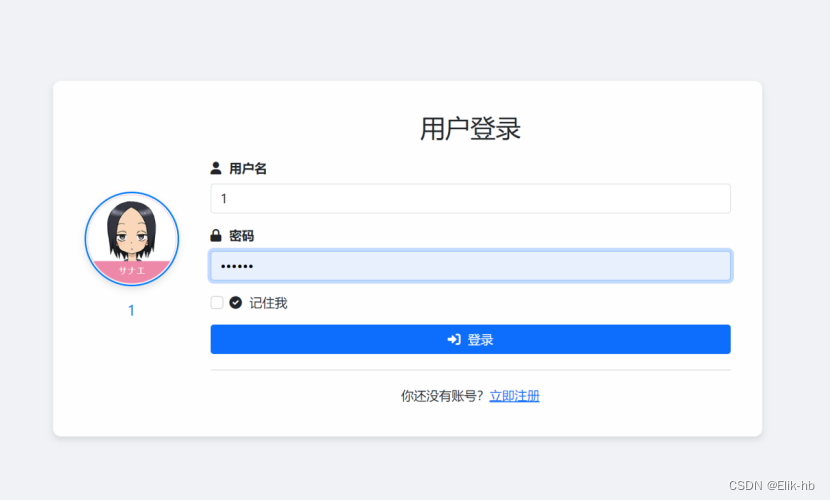
3.登录跳转到个人信息界面
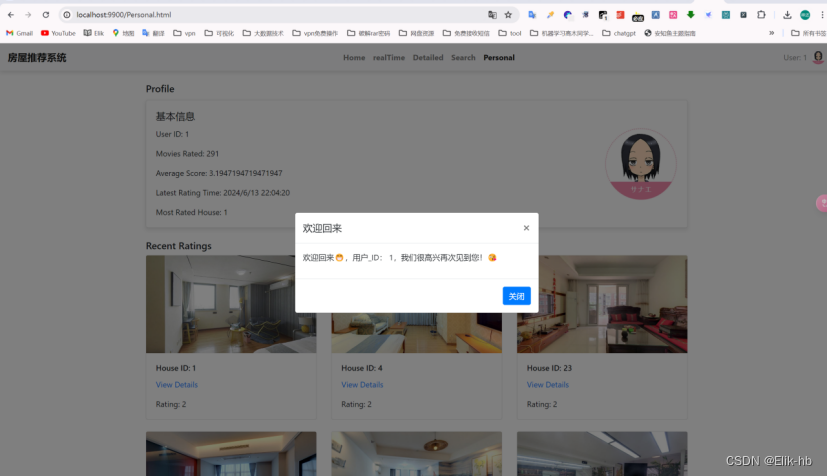
可以看到自己的基本信息和之前评论过的房屋数据
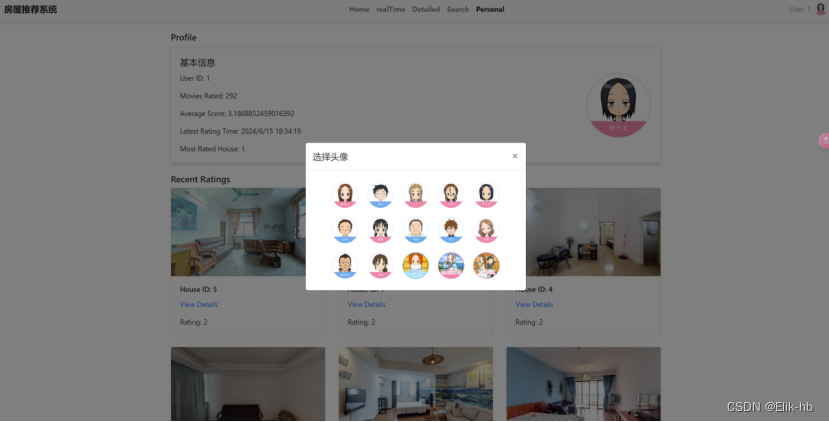
4. 点击头像可以更新
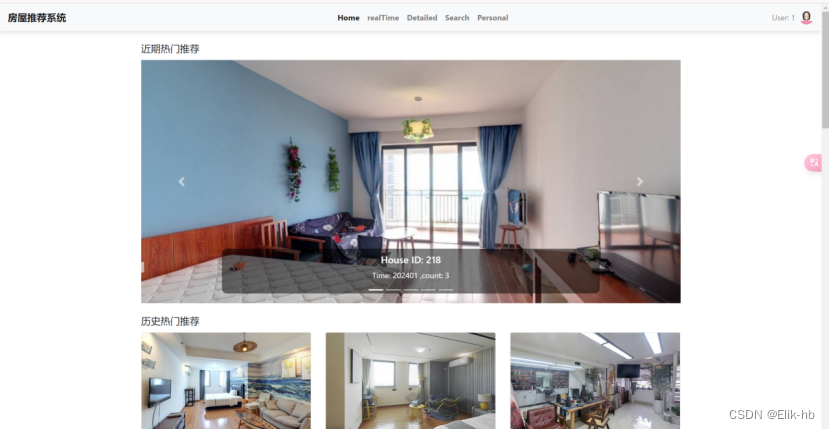
5. 查看主界面
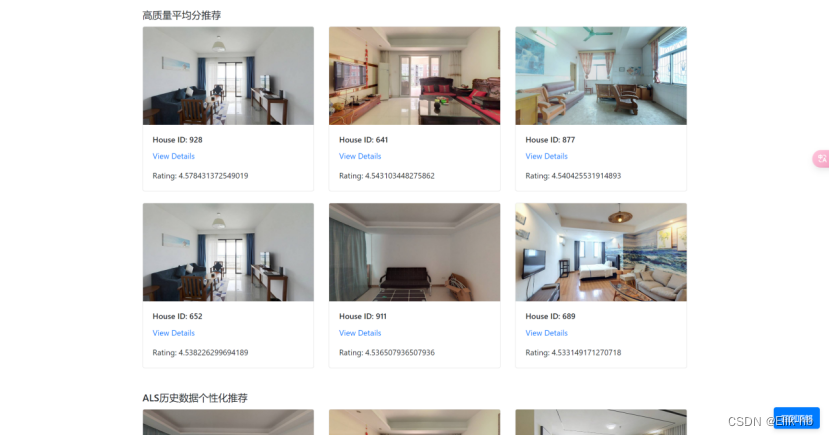
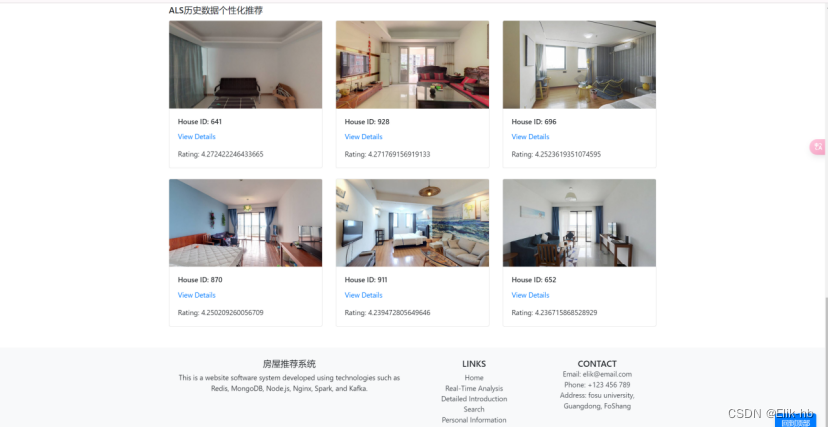
6. 点击view detail可以查看房屋详细介绍
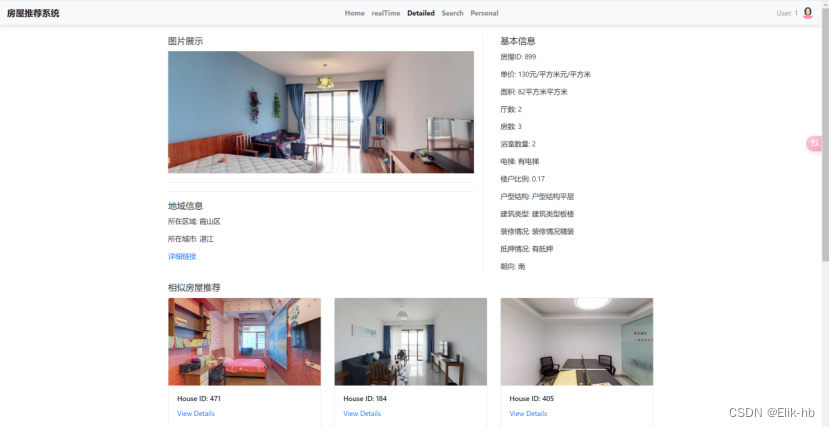
下面可以查看到相似房屋
7. 进入查询界面
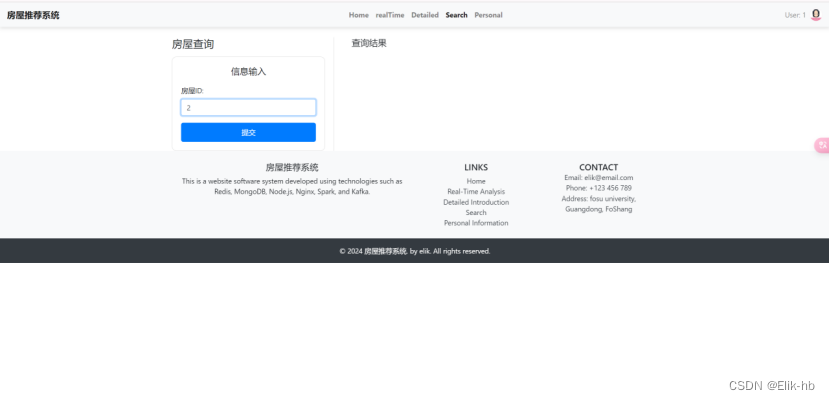
8. 输入id即可查询到相关信息
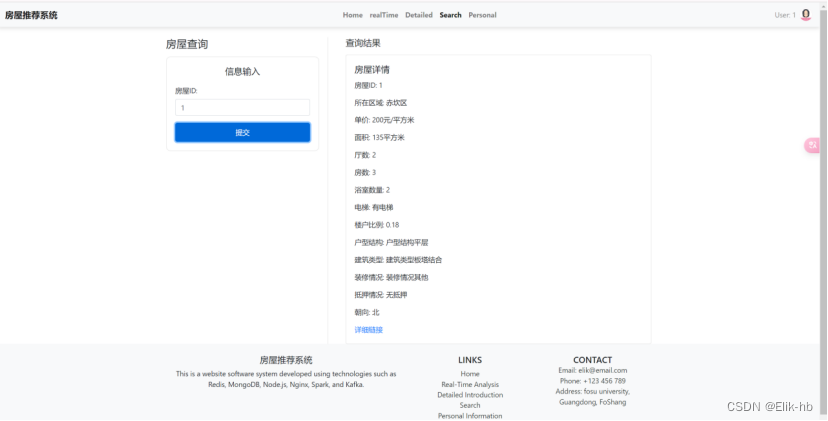
9. 进入实时推荐界面
用户对房屋进行评分
点击提交可以查看到推荐数据
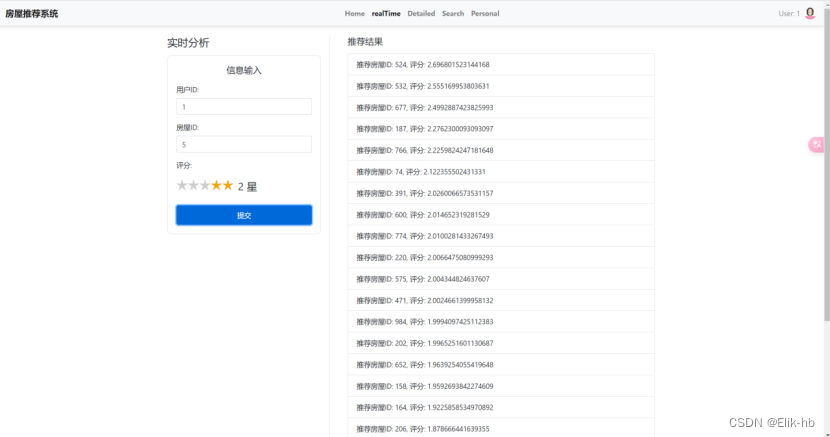
进入数据库,可以看到是对应的

18. 终端监控用户输入
















 1180
1180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











