







Re
maybe_xor
这题考察的应该是同类型样本的通用数据提取脚本!
- 考察base64解密,异或解密
- 通过解析汇编字节码定位数据偏移位置
- 根据汇编字节码特征提取xor汇编指令的操作数
- 跟远程服务器交互脚本的编写,我这里用的pwntools
接下来就剩爆破了:
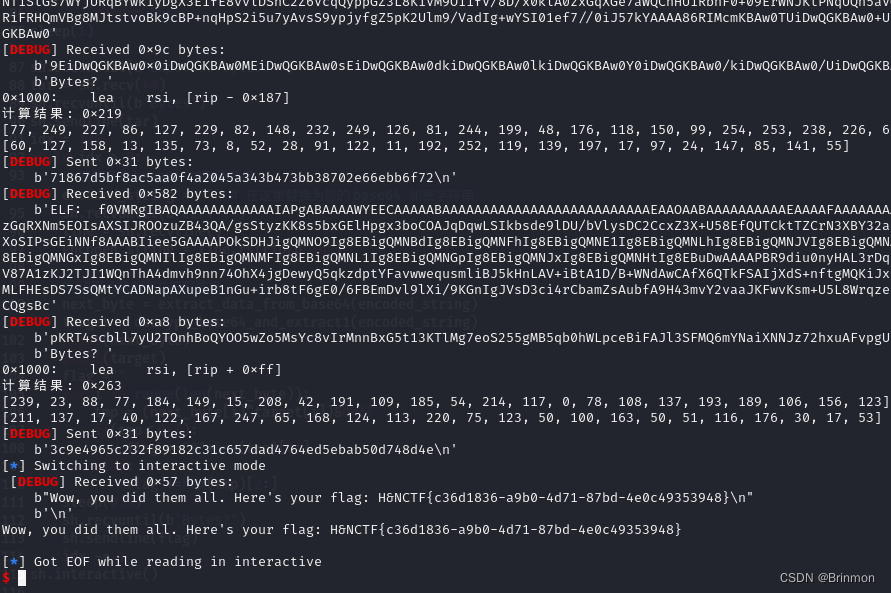
解题思路如下:
0.单个文件分析
根据提示知道发来的base64数据是一个ELF文件,写个脚本dump出文件来分析:
import base64
def decode_base64_to_file(encoded_string, output_file):
# 解码 base64 字符串
decoded_data = base64.b64decode(encoded_string)
# 将解码后的数据写入文件
with open(output_file, 'wb') as file:
file.write(decoded_data)
print("解密完成并已写入文件。")
# 要解密的 base64 加密字符串
encoded_string = "f0VMRgIBAQAAAAAAAAAAAAIAPgABAAAAi4EECAAAAABAAAAAAAAAAAAAAAAAAAAAAAAAAEAAOAABAAAAAAAAAAEAAAAFAAAAAAAAAAAAAAAAgAQIAAAAAACABAgAAAAAkAQAAAAAAACQBAAAAAAAAAAQAAAAAAAArrlN8YKXNzPs2ZPJdlSHtIHATpGVaYXjt/bYswBasGk2W8kAuUzG5HPyOFN2nAhCSiLuV5eK1agtakZGTk31sO9xB3jj/veFaxP44L9HCv8stf+dYW5dY0rPUmOdbDSRJ3MWY8LpnDsd7/+wCPa0ZeUd84dzzJgKypt6gMR3nUoe22sGmPhl70F9uCmANVWbA9Fda326m8+Uy7spyiRwNEnJswj6eCnwBeJczfKnziKl5xsIMNPCjkgsp4c0fc4qjhJ1joRMxkiuorlRoQzRQ5tlCu2f8bhheisCMrUB7UxEH+wtUjjqIQkrP5g04SIGdQm3dLZ2WJH058bdUk7gEnA9HNwot0xIdFTTc8CLiMERJvZIg+wYSI01+f7//0iJ57kYAAAA86RIMcmKBAw070iDwQGKBAw0NEiDwQGKBAw0rkiDwQGKBAw0pUiDwQGKBAw05UiDwQGKBAw0DkiDwQGKBAw0BUiDwQGKBAw0J0iDwQGKBAw0PEiDwQGKBAw04EiDwQGKBAw06UiDwQGKBAw0MEiDwQGKBAw0iEiDwQGKBAw0J0iDwQGKBAw0iEiDwQGKBAw0YUiDwQGKBAw0WUiDwQGKBAw0H0iDwQGKBAw0SEiDwQGKBAw0WEiDwQGKBAw0vkiDwQGKBAw0REiDwQGKBAw0wkiDwQGKBAw0ZUiDwQG4PAAAAA8F/vwnMFAFq/9bov2eNJ2k/wseRqP82hUpnSg4ZiKRcuGwii6wNI8yDNBRjXuHHPkDDbVvwQ0rTCifJ6RzPFBBKiPvO8NU/gQtElhBEg+ZUOal+BQk5A+YFkJcmgG9zX7mzKU3urAXlVqzELQGmo/Qi4EGv77k4nBIMNGdeLfhKTvFxZa3v7R19pg1UuOvuob+YG+n2dFf6N03sIN0gQmAkL6X8aw1WFukpYxeXAJ8Nyi44bL+04D10ZpvtblNVb9T6iVIekZJk7hKJJ2+nAdG3Fi0DK6iJHqs5vtKOo2/D78z+NmtQ54ME3xbR6jSapk4N7fpY8fkL7OsEevXtsDJQYONI6J/NBO72pXSxtRK3w2BKlfP38GIyx96KFVHFrQcj50PVgmN4Qg1lfEMx+QQLyc04NbTHXd39wvvD1/jeKyQP2oAM4JSpikgRxDD/XSZBPZlEnU/MZYbSp/RAITpclspQNh/A/dH5BDW9GNtYNX79rYTkiT9weTQhAUQ3Z7sJlzL+3maCxMDEU/9OlRsG+iY6lEyJVBC7XVtEKJ9Uswt2xzMxt0I+0trGCPdMhI/f2/5K0m1VJ4Lp0ep7OGobAtsBxnjW9CncgPMfhur/Ybi2R/hHbrYPOC8HiCh43YAeejDzeK2aMFi+0/AFt4nsAVXEQWzH9kdH4TilJ62dnkt5xeUM/p8zCI/oQmGOg=="
output_file = "output" # 输出文件的名称
# 调用函数解码并写入文件
decode_base64_to_file(encoded_string, output_file)
将文件放入IDA进行分析:
根据提示知道是异或运算所以提取出所有的Xor的操作数
发现byte_804808F是另一组异或数据
LOAD:000000000804818B sub rsp, 18h
LOAD:000000000804818F lea rsi, byte_804808F
LOAD:0000000008048196 mov rdi, rsp
LOAD:0000000008048199 mov ecx, 18h
LOAD:000000000804819E rep movsb
LOAD:00000000080481A0 xor rcx, rcx
LOAD:00000000080481A3 mov al, [rsp+rcx]
LOAD:00000000080481A6 xor al, 0EFh
LOAD:00000000080481A8 add rcx, 1
LOAD:00000000080481AC mov al, [rsp+rcx]
LOAD:00000000080481AF xor al, 52
LOAD:00000000080481B1 add rcx, 1
LOAD:00000000080481B5 mov al, [rsp+rcx]
...
LOAD:000000000804826C xor al, 0C2h
LOAD:000000000804826E add rcx, 1
LOAD:0000000008048272 mov al, [rsp+rcx]
LOAD:0000000008048275 xor al, 65h
LOAD:0000000008048277 add rcx, 1
LOAD:000000000804827B mov eax, 3Ch ; '<'
LOAD:0000000008048280 syscall ; LINUX - sys_exit
用idapython提取出Xor的数据:
import idc
import idautils
def parse_hex_string(value):
if value.endswith("h"):
value = value[:-1] # 去除"h"后缀
return int(value, 16)
# 设置开始和结束地址
start_addr = 0x8048398
end_addr = 0x804846D
hex_value = []
# 从开始地址逐个遍历到结束地址
current_addr = start_addr
while current_addr < end_addr:
# 获取当前地址的汇编指令
disasm = idc.GetDisasm(current_addr)
# 如果指令是 XOR 指令
if "xor" in disasm:
# 获取操作数
operands = disasm.split(",")
print(operands)
op1 = operands[0].strip()
op2 = operands[1].strip()
print("操作数2: {}".format(op2))
hex_value.append(parse_hex_string(op2) )
# 移动到下一个指令
current_addr = idc.next_head(current_addr)
print(hex_value)
提取出的Xor操作数:
[239, 82, 174, 165, 229, 14, 5, 39, 60, 224, 233, 48, 136, 39, 136, 97, 89, 31, 72, 88, 190, 68, 194, 101]
ida手动提取出byte_804808F:
[0xE3, 0xB7, 0xF6, 0xD8, 0xB3, 0x00, 0x5A, 0xB0, 0x69, 0x36, 0x5B, 0xC9, 0x00, 0xB9, 0x4C, 0xC6, 0xE4, 0x73, 0xF2, 0x38, 0x53, 0x76, 0x9C, 0x08]
上脚本:
next_byte = [239, 82, 174, 165, 229, 14, 5, 39, 60, 224, 233, 48, 136, 39, 136, 97, 89, 31, 72, 88, 190, 68, 194, 101]
target = [0xE3, 0xB7, 0xF6, 0xD8, 0xB3, 0x00, 0x5A, 0xB0, 0x69, 0x36, 0x5B, 0xC9, 0x00, 0xB9, 0x4C, 0xC6, 0xE4, 0x73, 0xF2, 0x38, 0x53, 0x76, 0x9C, 0x08]
flag = ""
for i in range(len(next_byte)):
tmp = (next_byte[i]^target[i])&0xff
if(tmp<=0xf):
flag +="0"+hex(tmp)[2:]
else:
flag +=hex(tmp)[2:]
print(flag)
#0ce5587d560e5f9755d6b2f9889ec4a7bd6cba60ed325e6d
进行异或运算后发现:数据正确
1.多个文件分析
对比多个数据样本发现区别!
- 每个样本的xor操作数都不一样
- 目标数据的地址偏移也是不断变化的
所以目标:找到方法能够提取不同样本的目标数据!
样本1,发现代码段位于文件最后,数据段在文件上部分
LOAD:0000000008048457 add rcx, 1
LOAD:000000000804845B mov al, [rsp+rcx+18h+var_18]
LOAD:000000000804845E xor al, 0F3h
LOAD:0000000008048460 add rcx, 1
LOAD:0000000008048464 mov al, [rsp+rcx+18h+var_18]
LOAD:0000000008048467 xor al, 6Fh
LOAD:0000000008048469 add rcx, 1
LOAD:000000000804846D mov eax, 3Ch ; '<'
LOAD:0000000008048472 syscall ; LINUX - sys_exit
LOAD:0000000008048472 start endp
LOAD:0000000008048472
LOAD:0000000008048472 LOAD ends
LOAD:0000000008048472
LOAD:0000000008048472
LOAD:0000000008048472 end start
样本2,发现代码段位于文件中间,数据段在文件最后
LOAD:0000000008048265 add rcx, 1
LOAD:0000000008048269 mov al, [rsp+rcx]
LOAD:000000000804826C xor al, 0C2h
LOAD:000000000804826E add rcx, 1
LOAD:0000000008048272 mov al, [rsp+rcx]
LOAD:0000000008048275 xor al, 65h
LOAD:0000000008048277 add rcx, 1
LOAD:000000000804827B mov eax, 3Ch ; '<'
LOAD:0000000008048280 syscall ; LINUX - sys_exit
LOAD:0000000008048280 ; ---------------------------------------------------------------------------
LOAD:0000000008048282 dw 0FCFEh, 3027h, 550h
LOAD:0000000008048288 dq 9D349EFDA25BFFABh, 0DAFCA3461E0BFFA4h, 91226638289D2915h
LOAD:00000000080482A0 dq 8F34B02E8AB0E172h, 1C877B8D51D0
…
2.通过解析汇编字节码定位数据偏移位置
先看ida里的伪代码:
LOAD:000000000804818B sub rsp, 18h
LOAD:000000000804818F lea rsi, byte_804808F
LOAD:0000000008048196 mov rdi, rsp
我要提取的是byte_804808F的地址,但是他是动态变化的!!
提取出汇编码:48 8D 35 F9 FE FF FF
48 8D 35是lea rsi的硬编码,F9 FE FF FF便是要跳转的偏移了!
可以通过Capstone来解析x86汇编代码来定位到byte_804808F的数据偏移位置!
找到偏移位置后提取0x18个数据就可以了!
def decrypt_base64_and_extract1(encoded_string):
# 解密 base64 字符串
decoded_data = base64.b64decode(encoded_string)
# 寻找匹配的字节序列
match_index = decoded_data.find(b'\x48\x89\xe7')
# 如果找到匹配的字节序列
if match_index != -1:
# 寻找等于0x34的数据的下一个数据
extracted_data = []
index = match_index # 匹配字节序列之后的索引
# 提取匹配到的字节序列前面的指定字节数
extracted_data = decoded_data[index - 7: index]
# 初始化Capstone
md = Cs(CS_ARCH_X86, CS_MODE_64)
md.detail = True
offest1 = 0
# 反汇编二进制数据
for i in md.disasm(extracted_data, 0x1000):
print("0x%x:\t%s\t%s" % (i.address, i.mnemonic, i.op_str))
# 汇编指令字符串
assembly_instruction = i.op_str
# 提取方括号中的算式
start_index = assembly_instruction.find("[")
end_index = assembly_instruction.find("]")
expression = assembly_instruction[start_index + 1:end_index]
# 检查字符串中是否包含加号或减号
if "+" in expression:
operator = "+"
elif "-" in expression:
operator = "-"
else:
print("无法识别的操作符。")
exit()
# 提取操作数和偏移量
tokens = expression.split(operator)
rip = match_index
offset = int(tokens[1].strip(), 16)
# 根据操作符执行加法或减法
if operator == "+":
result = rip + offset
else:
result = rip - offset
offest1 = result
print("计算结果:", hex(result))
extracted_data = []
while len(extracted_data) < 0x18: # 提取0x18个元素
extracted_data.append(decoded_data[offest1]) # 提取下一个数据
offest1 += 1
return extracted_data
else:
return None
3.根据汇编字节码特征提取xor汇编指令的操作数
先定位到:mov al, [rsp+rcx]的偏移位置在开始找xor的操作数
mov al, [rsp+rcx]的硬编码:b'\x8A\x04\x0C'
由于xor的编码是0x34,而且每个xor的距离都是9个字节,所以提取起来比较简单!
def extract_data_from_base64(encoded_string):
# 解密 base64 字符串
decoded_data = base64.b64decode(encoded_string)
# 寻找匹配的字节序列
match_index = decoded_data.find(b'\x8A\x04\x0C')
# 如果找到匹配的字节序列
if match_index != -1:
# 寻找等于0x34的数据的下一个数据
extracted_data = []
index = match_index + 3 # 匹配字节序列之后的索引
while len(extracted_data) < 0x18: # 提取0x18个元素
if decoded_data[index] == 0x34: # 如果当前数据等于0x34
extracted_data.append(decoded_data[index + 1]) # 提取下一个数据
index += 9
return extracted_data
else:
return None
4.最后的解题脚本
一共要交互128次的样子,flag就被输出了!
import base64
from pwn import *
from capstone import *
sh=remote('hnctf.imxbt.cn',53833)
context(log_level='debug',arch='amd64',os='linux')
def extract_data_from_base64(encoded_string):
# 解密 base64 字符串
decoded_data = base64.b64decode(encoded_string)
# 寻找匹配的字节序列
match_index = decoded_data.find(b'\x8A\x04\x0C')
# 如果找到匹配的字节序列
if match_index != -1:
# 寻找等于0x34的数据的下一个数据
extracted_data = []
index = match_index + 3 # 匹配字节序列之后的索引
while len(extracted_data) < 0x18: # 提取0x18个元素
if decoded_data[index] == 0x34: # 如果当前数据等于0x34
extracted_data.append(decoded_data[index + 1]) # 提取下一个数据
index += 9
return extracted_data
else:
return None
def decrypt_base64_and_extract1(encoded_string):
# 解密 base64 字符串
decoded_data = base64.b64decode(encoded_string)
# 寻找匹配的字节序列
match_index = decoded_data.find(b'\x48\x89\xe7')
# 如果找到匹配的字节序列
if match_index != -1:
# 寻找等于0x34的数据的下一个数据
extracted_data = []
index = match_index # 匹配字节序列之后的索引
# 提取匹配到的字节序列前面的指定字节数
extracted_data = decoded_data[index - 7: index]
# 初始化Capstone
md = Cs(CS_ARCH_X86, CS_MODE_64)
md.detail = True
offest1 = 0
# 反汇编二进制数据
for i in md.disasm(extracted_data, 0x1000):
print("0x%x:\t%s\t%s" % (i.address, i.mnemonic, i.op_str))
# 汇编指令字符串
assembly_instruction = i.op_str
# 提取方括号中的算式
start_index = assembly_instruction.find("[")
end_index = assembly_instruction.find("]")
expression = assembly_instruction[start_index + 1:end_index]
# 检查字符串中是否包含加号或减号
if "+" in expression:
operator = "+"
elif "-" in expression:
operator = "-"
else:
print("无法识别的操作符。")
exit()
# 提取操作数和偏移量
tokens = expression.split(operator)
rip = match_index
offset = int(tokens[1].strip(), 16)
# 根据操作符执行加法或减法
if operator == "+":
result = rip + offset
else:
result = rip - offset
offest1 = result
print("计算结果:", hex(result))
extracted_data = []
while len(extracted_data) < 0x18: # 提取0x18个元素
extracted_data.append(decoded_data[offest1]) # 提取下一个数据
offest1 += 1
return extracted_data
else:
return None
sleep(1)
sh.recvuntil(b'Expected bytes: ')
tar = sh.recv(48)
sh.recvuntil(b'Bytes')
sh.sendline(tar)
idx = 128
while idx > 0:
# 要解密的 base64 加密字符串
encoded_string = "" # 在这里替换为您的 base64 加密字符串
sh.recvuntil(b'ELF: ')
line = sh.recvline()
encoded_string = line.rstrip(b"\n")
# 调用函数解密并提取数据
next_byte = extract_data_from_base64(encoded_string)
target = decrypt_base64_and_extract1(encoded_string)
print(next_byte)
print(target)
flag =""
for i in range(len(next_byte)):
tmp = (next_byte[i]^target[i])&0xff
if(tmp<=0xf):
flag +="0"+hex(tmp)[2:]
else:
flag +=hex(tmp)[2:]
sleep(0.5)
sh.recvuntil(b'Bytes?')
sh.sendline(flag)
idx -= 1
sh.interactive()
最喜欢的逆向题
flag是明文写的主要是要找:
看伪代码:
if ( Buffer[5] == 105 && Buffer[7] == Buffer[10] && Buffer[15] == Buffer[22] )
所以符合条件的flag是:H&NCTF{Do_Y0u_like_F5_1n_Rev}
case 105:
printf("H&NCTF{Do_Y0u_like_F5_1n_Rev}");
childmaze
表面是迷宫逆向,其实只要找到关键字符串发现就是个异或加密!
考察的主要是眼力
flag:H&NCTF{Ch411enG3_0f_M4z3}
发现是简单的异或加密:
target = "H'L@PC}Ci625`hG2]3bZK4{1~"
for i in range(len(target)):
print(chr( ord(target[i]) ^ (i%7)),end="")
#输出:H&NCTF{Ch411enG3_0f_M4z3}
代码审计的时候发现了关键代码:
qmemcpy(KeyStr, "H'L@PC}Ci625`hG2]3bZK4{1~", 25);
copyKeystr = KeyStr;
...
for ( i = 0i64; i < 0x19; ++i ) // 关键位置
{
LODWORD(v306) = *(copyKeystr + i) ^ (i % 7u);
*&v308 = &v306;
*(&v308 + 1) = _$LT$char$u20$as$u20$core..fmt..Display$GT$::fmt::h4b602de30937fa88;
*&Tmp = &off_7FF738153868;
*(&Tmp + 1) = 1i64;
v312 = &v308;
v313 = 1ui64;
std::io::stdio::_print::h6e1d82d125fe1319(&Tmp);
}
DO YOU KNOW SWDD?
发现是smc,动调调试找到主要加密逻辑!发现scanf只能输入一个字符
找到逻辑就可以直接搓脚本了!
flag:H&NCTF{I_LOVE_SWDD_WHAT_ABOUT_YOU}
target = "S_VYFO_CGNN_GRKD_KLYED_IYE"
tag = 0
print("H&NCTF{",end="")
for cha in target:
tag = 0
for i in range(65,91):
if((i + 10 - 65) % 26 + 65 == ord(cha)):
print(chr(i),end="")
tag = 1
break
if(tag==0):
print(cha,end="")
print("}",end="")
# H&NCTF{I_LOVE_SWDD_WHAT_ABOUT_YOU}
解题路径:动态调试找到加密逻辑:
找到加密逻辑:
// positive sp value has been detected, the output may be wrong!
void __cdecl __noreturn sub_417000(char *Str1)
{
char v1; // [esp-FCh] [ebp-208h]
char Str2[36]; // [esp+D0h] [ebp-3Ch] BYREF
int i; // [esp+F4h] [ebp-18h]
int v4; // [esp+100h] [ebp-Ch]
__CheckForDebuggerJustMyCode(&unk_41E015);
v4 = 10;
for ( i = 0; Str1[i]; ++i )
{
if ( Str1[i] >= 65 && Str1[i] <= 90 )
Str1[i] = (Str1[i] + v4 - 65) % 26 + 65;
}
strcpy(Str2, "S_VYFO_CGNN_GRKD_KLYED_IYE");
if ( !j_strcmp(Str1, Str2) )
{
printf("yes, you are right\n", v1);
exit(0);
}
printf("Try Again!", v1);
exit(0);
}
hnwanna
flag:H&NCTF{ozxyfjfxdzsnydlfrj}
思路:找到Assembly-CSarp.dll里的LoadLevel()和a(),加密逻辑就出来了
逻辑出来了脚本也就出来了!
def a(input_str, shift):
text = ""
for c in input_str:
if c.isalpha():
text += chr((ord(c.lower()) - ord('a') + shift) % 26 + ord('a'))
else:
text += c
return text
print("H&NCTF{"+a("justaeasyunitygame",5)+"}")
#H&NCTF{ozxyfjfxdzsnydlfrj}
解题路程:
找到核心逻辑dll文件,Assembly-CSarp.dll
Dnspy进行C#反编译
找到LoadLevel()和a()就可以获得flag了!
// GameWindow
// Token: 0x0600001B RID: 27 RVA: 0x0000265C File Offset: 0x0000085C
public void LoadLevel()
{
GameObject gameObject = Object.Instantiate<GameObject>(this.levelArr[this.levelCount]);
gameObject.name = "Level" + this.levelCount.ToString();
gameObject.transform.SetParent(base.transform, false);
this.player.transform.localPosition = gameObject.transform.Find("StartPoint").localPosition;
if (this.levelCount == 5)
{
this.FlagText = GameObject.Find("Tip").GetComponent<Text>();
string input = "justaeasyunitygame";
string str = this.a(input, this.levelCount);
this.FlagText.text = "H&NCTF{" + str + "}";
}
}
// Token: 0x0600001A RID: 26 RVA: 0x000025F8 File Offset: 0x000007F8
public string a(string input, int shift)
{
string text = "";
foreach (char c in input)
{
if (char.IsLetter(c))
{
text += ((char)(((int)(c - 'a') + shift) % 26 + 97)).ToString();
}
else
{
text += c.ToString();
}
}
return text;
}
Misc
ManCraft - 娱乐题
击杀牢大就可获得key,获得flag
H&CTF{d4ea9253161048e7a129d337bd4e383f}

















 1014
1014











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









