







1.LSTM模型
关于这个模型的基本概念长短时记忆网络(LSTM)(超详细 |附训练代码)_lstm代码-CSDN博客可以查看这篇文章,写得很详细,我觉得能大概看明白反向传递各个部分的推导就行了。
2.pytorch的安装
我使用的是conda环境,在参照网上的安装过程后,运行出现了报错OSError: [WinError 126] 找不到指定的模块。 Error loading "D:\WORK\anaconda\lib\site-packages\torch\lib\c10_cuda.dll" or one of its dependencies.
重新创建了一个python3.9的conda环境后,再次安装torch就可以了。具体过程可以参考这篇文章安装PyTorch详细过程_pytorch安装-CSDN博客
3.LSTM训练(下载链接)
本文只是简略的一个训练和预测过程,适合感兴趣的人初步学习。所有代码都已经写有详细的注释,希望对读者的阅读能有帮助。整个项目的流程包括爬虫,数据处理,还有数据集等等我已经放在GitHub上,感兴趣的小伙伴可以拿去学习或者修改出更好的训练代码,github链接(最新版)。
3.1 LSTMModel.py
编写一个简单的LSTM模块,pytroch已经内置了LSTM,我们只需要编写调用就行了,不用实现LSTM的内部功能。
import torch
import torch.nn as nn
# input_size输入特征的维度
# hidden_size隐藏层的维度,即每个LSTM单元的隐藏状态向量的维度。
# output_size:输出的维度。
# num_layers:LSTM层的数量,默认为1。
class LSTMModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=1):
super(LSTMModel, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
# 定义lsmt层
# batch_first=True表示输入数据的形状是(batch_size, sequence_length, input_size)
# 而不是默认的(sequence_length, batch_size, input_size)。
# batch_size是指每个训练批次中包含的样本数量
# sequence_length是指输入序列的长度
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
# 定义全连接层,将LSTM层的输出映射到最终的输出空间。
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
# 初始化了隐藏状态h0和细胞状态c0,并将其设为零向量。
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
# LSTM层前向传播
# 将输入数据x以及初始化的隐藏状态和细胞状态传入LSTM层
# 得到输出out和更新后的状态。
# out的形状为(batch_size, sequence_length, hidden_size)。
out, _ = self.lstm(x, (h0, c0))
# 全连接层前向传播
# 使用LSTM层的最后一个时间步的输出out[:, -1, :](形状为(batch_size, hidden_size))作为全连接层的输入,得到最终的输出。
out = self.fc(out[:, -1, :])
return out3.2 load_data.py
加载数据集模块,读取本地的CSV数据集,对数据集提取目标变量和特征变量。
# 加载数据集并划分数据集和测试集
import torch
from torch.utils.data import Dataset, DataLoader, random_split
import pandas as pd
from sklearn.preprocessing import StandardScaler
# 自定义一个数据集类
class CustomDataset(Dataset):
def __init__(self, csv_file, transform=None):
self.data = pd.read_csv(csv_file, encoding='GBK')
self.transform = transform
# 三次指数平滑
# self.X = self.X.apply(self.triple_exponential_smoothing, axis=0)
# 提取特征和目标变量
self.X = self.data.drop(columns=['当日票房(万)']) # 除了目标剩下的都是特征
self.Y = self.data['当日票房(万)'] # 目标
# 使用StandardScaler对数据进行标准化处理,以确保训练过程中的数值稳定性(可选)
# pd.DataFrame()函数,可以将数据从不同的数据源(如列表、字典、NumPy数组等)转换成数据帧
self.scaler = StandardScaler()
self.X = pd.DataFrame(self.scaler.fit_transform(self.X), columns=self.X.columns)
def triple_exponential_smoothing(self, series, alpha=0.2):
"""
三次指数平滑
series: 时间序列数据
alpha: 平滑系数,取值范围为 [0, 1]
"""
model = ExponentialSmoothing(series, trend='add', seasonal='add', seasonal_periods=12)
model_fit = model.fit(smoothing_level=alpha, smoothing_trend=alpha, smoothing_seasonal=alpha)
return model_fit.fittedvalues
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
# 从self.X中选择索引为idx的行,并将其赋值给X_sample
X_sample = self.X.iloc[idx]
Y_sample = self.Y.iloc[idx]
# 特征数据和标签数据都被转换为float32类型的PyTorch张量。
sample = {'X': torch.tensor(X_sample.values, dtype=torch.float32),
'Y': torch.tensor(Y_sample, dtype=torch.float32)}
# 在这里进行数据预处理,如果需要的话
if self.transform:
sample = self.transform(sample)
return sample
def load_data():
# 读取CSV文件
csv_file = 'D:/WORK/all.movie.new.csv'
# 创建数据集实例
custom_dataset = CustomDataset(csv_file)
# 划分训练集和测试集
train_size = int(0.9 * len(custom_dataset)) # 训练集占比90%
test_size = len(custom_dataset) - train_size # 测试集占比10%
train_dataset, test_dataset = random_split(custom_dataset, [train_size, test_size]) # 按照比例随机划分
# 创建数据加载器
# batch_size参数用于指定每个批次(batch)中包含的样本数量。
# 通常情况下,较大的batch_size可以加快训练速度,但可能会占用更多的内存资源。
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
# 检查数据加载器
for batch in train_loader:
print(batch['X'].shape, batch['Y'].shape)
break
return train_loader, test_loader, custom_dataset
在加载数据的时候可选是否使用三次指数平滑(代码中已经注释掉了) ,使用三次指数平滑可以使数据对时间的变化效果更好一些。
# 三次指数平滑
# self.X = self.X.apply(self.triple_exponential_smoothing, axis=0)下图是只使用归一化的效果
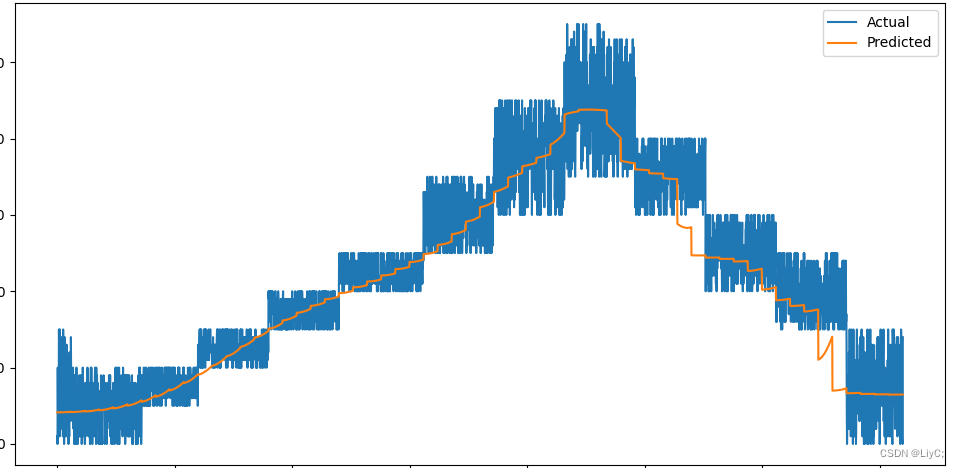
下图是先使用了三次指数平滑,再使用归一化的效果
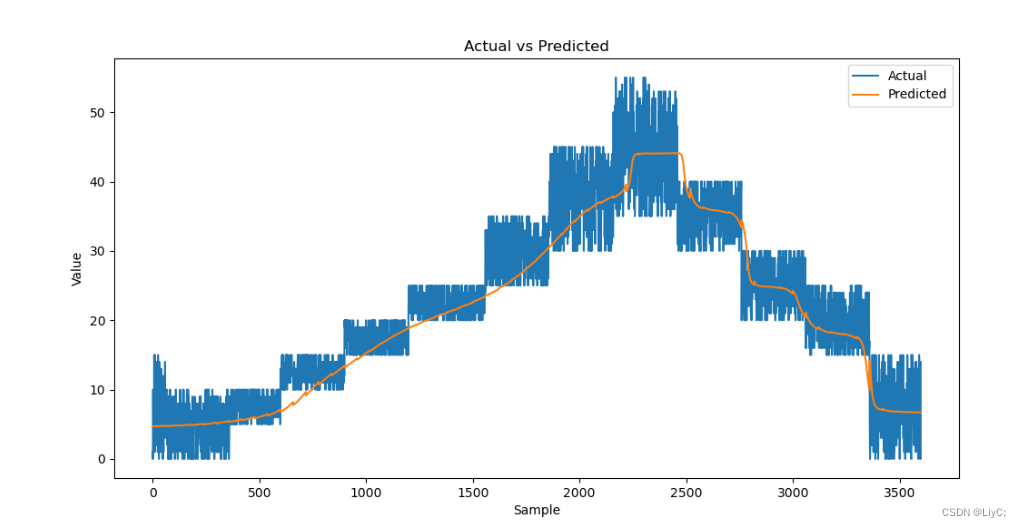
可以看到我们的预测曲线明显平滑了许多
3.3 train.py
训练模块,通过调用LSTMModel和load_data,来实例化模型和加载数据。然后进行前向传播和反向传递的无限循序训练。
import torch
from torch import nn
import load_data
import LSTMmodel as lstm
import torch.optim as optim
def evaluate_model(model, data_loader, criterion):
# 评估模块
model.eval()
total_loss = 0
with torch.no_grad():
for batch in data_loader:
X_batch = batch['X'].unsqueeze(1).to('cuda')
Y_batch = batch['Y'].unsqueeze(1).to('cuda')
outputs = model(X_batch)
loss = criterion(outputs, Y_batch)
total_loss += loss.item()
return total_loss / len(data_loader)
def main():
# 加载训练集和测试集和对应的数据加载器
train_loader, test_loader, custom_dataset = load_data.load_data()
# 设置超参数
input_size = len(custom_dataset.X.columns) # 特征数量
hidden_size = 32 # 隐藏层大小
# 隐藏层大小是指每个LSTM单元中的隐藏状态向量的维度,它在很大程度上影响了模型的表示能力和性能
# 如果隐藏层太大,模型可能会过拟合训练数据,对测试数据表现不佳。
# 如果隐藏层太小,模型可能无法捕捉到足够的信息,导致欠拟合。
output_size = 1 # 输出大小(预测当日票房)
num_layers = 4 # LSTM层数
# 单层LSTM:适用于简单的序列建模任务,结构简单,计算效率高。
# 多层LSTM:适用于复杂的序列建模任务,能够捕捉更复杂的模式和长距离依赖,但需要更多的计算资源。
# 层数选择:需要通过实验来确定,考虑任务复杂度、数据量和计算资源。
learning_rate = 0.01 # 学习率
# 对于较小的网络或简单任务,较大的学习率(如 0.01)可能是合适的。
# 对于较深的网络或复杂任务,较小的学习率(如 0.0001)可能是必要的。
# 实例化模型、损失函数和优化器
model = lstm.LSTMModel(input_size, hidden_size, output_size, num_layers).to('cuda') # 在GPU上训练
criterion = nn.SmoothL1Loss() # 均方误差损失函数
# 回归损失函数
# torch.nn.MSELoss 用于回归任务,计算预测值与目标值之间的均方误差。
# torch.nn.L1Loss 用于回归任务,计算预测值与目标值之间的平均绝对误差。
# torch.nn.SmoothL1Loss 结合了 L1Loss 和 MSELoss 的优点,对于回归任务更为稳健。
optimizer = optim.RMSprop(model.parameters(), lr=learning_rate)
# model.parameters(),获取模型中所有需要训练的参数(权重和偏置)
# SGD:适合大规模数据和需要较好泛化性能的任务,可以通过调节学习率和添加动量(Momentum)来改进。
# RMSprop:适合处理非平稳目标,可以自动调整学习率。
# Adam:适用于大多数情况,特别是有噪声的梯度和稀疏梯度的情形。
# 训练模型
try:
epoch = 0
model.train()
while True:
for batch in train_loader:
X_batch = batch['X'].unsqueeze(1).to('cuda') # 增加序列维度
Y_batch = batch['Y'].unsqueeze(1).to('cuda')
# 前向传播
outputs = model(X_batch) # 经过LSTM层,全连接层,生成输出
loss = criterion(outputs, Y_batch) # 计算模型输出与目标值之间的损失
# 反向传播及优化
optimizer.zero_grad() # 梯度清零,防止堆积
# 反向传播PyTorch会自动计算损失相对于模型参数的梯度
# 在这一步中,PyTorch会执行以下操作:
# 从损失开始,沿计算图的反向方向计算梯度。
# 对于LSTM层,这意味着计算损失相对于LSTM权重和偏置的梯度。LSTM层的反向传播包括计算输入门、遗忘门、输出门和候选记忆细胞的梯度。
# 对于全连接层(Linear layer),计算损失相对于线性层权重和偏置的梯度。
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0) # 添加梯度裁剪,防止梯度爆炸
# 调用优化器的step函数,使用计算得到的梯度来更新模型参数
# 优化器会使用学习率来缩放梯度。
# 对于每个参数,优化器会减去相应的梯度乘以学习率,从而更新参数。
optimizer.step()
if (epoch + 1) % 20 == 0:
# 每20epoch使用测试集计算一次损失,并保存模型
test_loss = evaluate_model(model, test_loader, criterion)
print(f'Epoch [{epoch + 1}], Train Loss: {loss.item():.4f}, Test Loss: {test_loss:.4f}')
# 保存模型
torch.save(model.state_dict(), f'D:/WORK/lstm_model_{epoch+1}.pth')
print(f"训练完成并保存模型(lstm_model_{epoch+1}.pth)。")
model.train()
else:
print(f'Epoch [{epoch + 1}], Train Loss: {loss.item():.4f}')
epoch += 1
except KeyboardInterrupt:
# ctrl+c中止训练
print("训练已中止。")
if __name__ == "__main__":
main()
3.4 train_and_display.py
通过调用windows的命令提示窗口来执行训练过程
import subprocess
# 在新的命令提示符窗口中启动另一个Python脚本执行训练,并将信息显示在窗口中
subprocess.Popen(["start", "cmd", "/k", "python", "train.py"], shell=True, creationflags=subprocess.CREATE_NEW_CONSOLE)3.5 模型训练与调参
训练
运行train_and_display.py后开始训练,训练过中程序每20个epoch就会输出一次测试损失并保存模型。想要结束训练按ctrl+c。
理论上,当训练达到一定的epoch后,loss损失会趋向于一个值,或者会在这个值附件浮动。如果想要继续降低损失,就需要进行调参。当训练过多以后,测试集的loss值可能会不降反而增加,这可能是模型过拟合导致的。
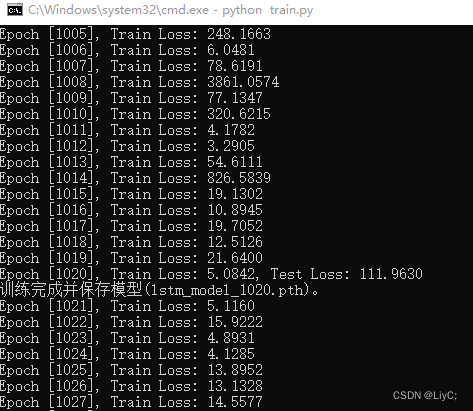
调参
在训练的过程中,通过Loss损失的反馈,我们需要对程序内的参数进行调整来训练出更好的模型好的模型(loss更小)。
已下参数都我根据自己需求设置的。具体每一个参数的作用,代码中对应部分都有详细的注解。
- hidden_size(隐藏层大小):32
- output_size(输出大小):1
- num_layers(LSTM层数):4
- learning_rate(学习率):0.01
- optimizer(优化器):RMSprop
- criterion(损失函数):SmoothL1Loss
- batch_size(指定每个批次中包含的样本数量):32
在调参过程中,建议每次调整只对一个参数进行。
经过不断调参后得到的训练损失:
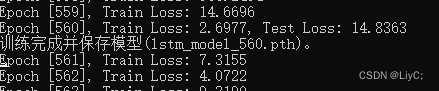
4.模型预测
新补充:predict.py的代码已经换成最新的了,添加了对预测数据的归一化操作。因为训练的时候是对归一化的数据进行的了训练,所以预测的时候要把预测数据归一化了再进行预测,不然输出结果可能是一条直线(即无论输入什么数据,输出结果都一样)
predict.py
这是一个简单的预测模块,通过手动输入预测数据,然后调用模型对这些数据进行分析最后得出预测结果。
import torch
import LSTMmodel as lstm
import load_data
def predict(model, input_data, scaler):
model.eval() # 将模型设置为评估模式
with torch.no_grad(): # 使用torch.no_grad()上下文管理器来关闭梯度计算,以便在推断过程中不计算梯度。
input_data = scaler.transform([input_data])
# 将输入数据转换为torch张量(tensor),并进行一些维度调整,最后将其移动到GPU上
input_tensor = torch.tensor(input_data, dtype=torch.float32).unsqueeze(0).to('cuda')
output = model(input_tensor) # 将输入数据传递给模型,获取输出结果
return output.item()
def main():
# 加载数据
_, _, custom_dataset = load_data.load_data()
# 构建模型,参数需要与训练的时候相同
input_size = len(custom_dataset.X.columns)
hidden_size = 32
output_size = 1
num_layers = 4
model = lstm.LSTMModel(input_size, hidden_size, output_size, num_layers).to('cuda')
# 加载模型
model.load_state_dict(torch.load('D:/WORK/lstm_model_560.pth'))
# 输入预测数据
# 上座率(%) 场均人次 票房占比(%) 已上映天数
# 排片场次 排片占比(%) 当日总出票 当日总场次
# 出品国家 电影类别1 电影类别2 电影类别3
# 电影评分 男性占比(%) 女性占比(%) 节假日
input_data = [0.015, 2.0, 0.188, 6,
79039, 0.190, 74.0, 37.2,
1, 1, 22, 0,
9.4, 0.314, 0.686, 13] # 示例输入数据
# 进行预测
prediction = predict(model, input_data, custom_dataset.scaler)
print(f'模型预测今日票房结果: {prediction:.1f}万')
if __name__ == "__main__":
main()
预测结果
测试一
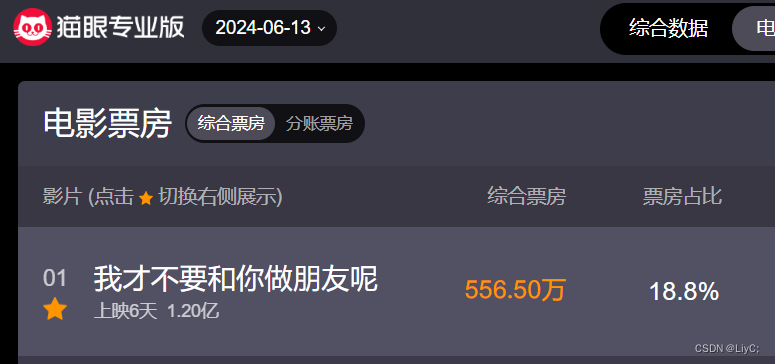
预测6月13日《我才不要和你做朋友呢》电影的票房信息

现在是6月14号,在猫眼专业版的网站上,我们可以查询到昨日的总票房
测试二
预测13号《神偷奶爸4》的票房


测试三
继续预测14号的票房


5.总结
准确率计算公式: ,带入计算后可以得知准确率还是可以的。
因为精力有限,并没有对每一个样例进行详细预测。训练模型的时候训练集的特征数量也选得比较简单。要想提高模型的准确率,可以对训练集的特征进行特征工程,这又涉及到了很多其它知识,感兴趣的话大家可以去学习学习。

















 9159
9159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









