







朴素贝叶斯算法
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。而朴素朴素贝叶斯分类是贝叶斯分类中最简单,也是常见的一种分类方法。

其中{
}的含义为:对于第i个样本的第j个特征,它的特征值属于特征集j,通过训练集训练出分类模型,然后对输入的实例x进行预测分类。
例:

其中为第2个样本的第1个特征=1
特征集
={1,2,3}
P(Y)-先验概率
先验概率(prior probability)是指根据以往经验和分析得到的概率,如 全概率公式 ,它往往作为"由因求果"问题中的"因"出现的概率。
计算方法
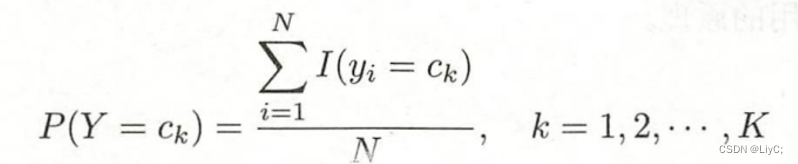
其中N为样本集的数量,表示求和这N个样本中
的数量。
P(X∣Y) -条件概率
可以理解为在发生Y的情况下,再发生X的概率
计算方法
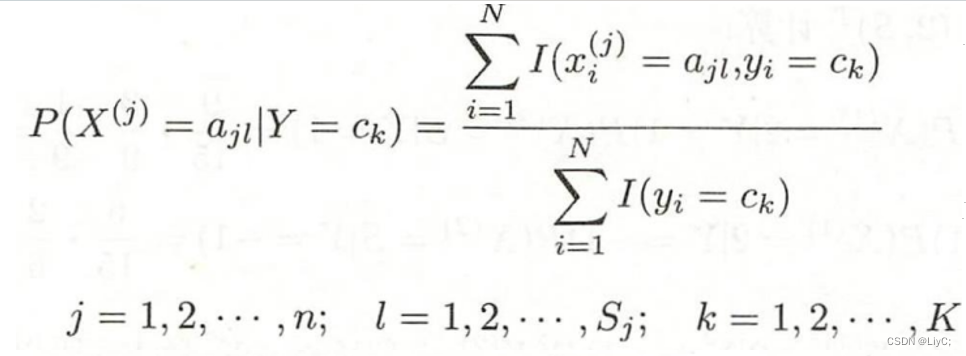
条件概率与联合概率的区别
联合概率是描述两个事件同时发生的概率,记为P(X,Y)=P(X)*P(Y)
条件概率则是在某个事件已经发生的情况下,另一个事件发生的概率,它考虑了事件之间的依赖关系
确定输入X的类
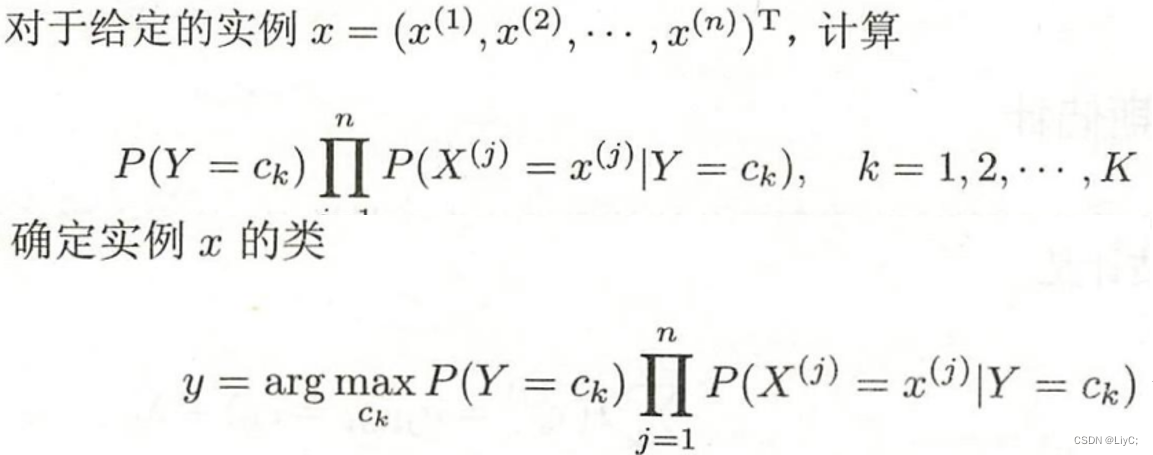
以上图表4.1为例,求x=(2,S)的分类,计算过程如下:
分别计算
argmax就是求最大值,根据上述计算得出当Y=-1的时候概率最大,所以x=(2,S)被分类为-1类
Python中五种贝叶斯算法
在Python中的scikit-learn库,根据特征数据的先验分布不同,给我们提供了5种不同的朴素贝叶斯分类算法。
分别是伯努利朴素贝叶斯(BernoulliNB),类别朴素贝叶斯(CategoricalNB),高斯朴素贝叶斯(GaussianNB)、多项式朴素贝叶斯(MultinomialNB)、补充朴素贝叶斯(ComplementNB)
本文介绍类别贝叶斯分类和高斯朴素贝叶斯分类
类别贝叶斯分类(CategoricalNB)
类别贝叶斯一般用于离散数据集。
以上图表4.1为例进行训练,因为CategoricalNB的特征集可以接受数字的字符串,但是不可以出现英文和中文,所以训练集的第二特征集用1表示S,2表示M,3表示L。
#导入模块
import numpy as np
from sklearn.naive_bayes import CategoricalNB
#定义训练集
X_train = np.array([["1", "1"], ["1", "2"], ["1", "2"], ["1", "1"], ["1", "1"],
["2", "1"], ["2", "2"], ["2", "2"], ["2", "3"], ["2", "3"],
["3", "3"], ["3", "2"], ["3", "2"], ["3", "3"], ["3", "3"]])
#定义标签集
y_train = np.array([-1,-1,1,1,-1,-1,-1,1,1,1,1,1,1,1,-1])
#创建类别贝叶斯模型实例
clf = CategoricalNB()
#使用fit函数拟合数据
clf.fit(X_train, y_train)
#返回测试向量 X 的对数概率估计值
print(clf.predict_proba(X_train))运行结果 :
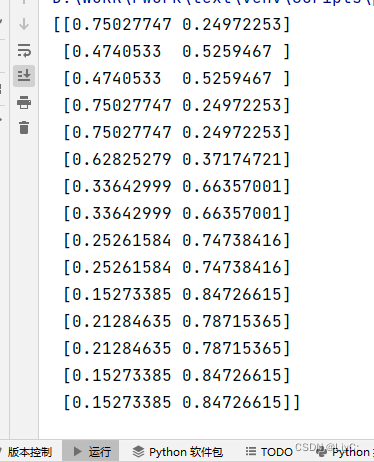
含义为:
预测x(1,S)标签为-1的概率为0.75027747,标签为1的概率为0.24972253
预测x(1,M)标签为-1的概率为0.4740533,标签为1的概率为0.5259467
.........
可以发现通过训练出来的模型还是会有误差,其中一个原因就是训练的数据量太少了
训练误差就是模型在训练集上的误差平均值,度量了模型对训练集拟合的情况。训练误差大说明对训练集特性学习得不够,训练误差太小说明过度学习了训练集特性,容易发生过拟合。
高斯贝叶斯分类(GaussianNB)
高斯贝叶斯一般用于连续数据集。
关于连续属性和离散属性的介绍
离散属性:取值可以具有有限个或无限可数个值,这个值可以用来定性描述属性
连续属性:在一定区间内可以任意取值的属性,其数值是连续不断的
举个例子:对于天气的温度和湿度它的取值是在一定的数字范围内任意取的(如1-100),所以这是连续属性。而对于天气的好坏只能取好或者取坏,这就是离散属性。
本文只是用两种不同的算法对同一数据进行计算,只是为了简单的展示两种不同的算法,在实际情况中需要对得到的信息进行分析判断哪些属于连续属性,哪些属于离散属性,然后选择相应的算法去计算。
代码测试
继续以表4.1y实现过程与上述代码类似,只是把导入类别贝叶斯改为导入高斯贝叶斯,注意GaussianNB模型要求输入的特征值是数值型的
第一种解决办法:如果特征集是通过读取文件得到的,程序中需要增加将字符串特征值转换为数值型特征值的步骤
第二种解决办法:如果特征集是自己定义的,可以在定义的时候直接定义为数值型
#导入模块
import numpy as np
from sklearn.naive_bayes import GaussianNB
from sklearn.preprocessing import LabelEncoder
#定义训练集
X_train = np.array([["1", "1"], ["1", "2"], ["1", "2"], ["1", "1"], ["1", "1"],
["2", "1"], ["2", "2"], ["2", "2"], ["2", "3"], ["2", "3"],
["3", "3"], ["3", "2"], ["3", "2"], ["3", "3"], ["3", "3"]])
#定义标签集
y_train = np.array([-1,-1,1,1,-1,-1,-1,1,1,1,1,1,1,1,-1]).T
#创建一个LabelEncoder对象
label_encoder = LabelEncoder()
#创建一个与X_train具有相同形状的空数组
X_train_encoded = np.empty(X_train.shape)
#对X_train的每一列进行循环操作,将每一列的值进行标签编码后存储到X_train_encoded中
for i in range(X_train.shape[1]):
X_train_encoded[:, i] = label_encoder.fit_transform(X_train[:, i])
#创建高斯贝叶斯模型实例
clf = GaussianNB()
#使用fit函数拟合数据
clf.fit(X_train_encoded, y_train)
#返回测试向量 X 的对数概率估计值
print(clf.predict_proba(X_train_encoded))运行结果:
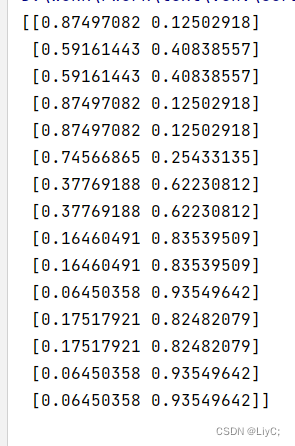
含义与之前解释的一样
predict_proba是如何确定返回标签的
通过上面两段python的测试代码,我们得到了一个predict_proba的返回集,它表示的是X属于不同标签的概率。
但是会有一些疑问,我们是如何知道返回集中的第一列是代表标签为1的概率还是代表标签为-1的概率?
在这里需要引出classes_属性,在sklearn中,对于训练好的分类模型,模型都有一个classes_属性,classes_属性中按顺序保存着训练样本的类别标记。这个属性可以让你查看分类器训练时学习到的所有类别,并且在预测时可以帮助你理解输出结果对应的类别。
查看classes_属性时候,需要在拟合数据后才可以查看,因为在拟合数据以后才相当于创建了一个模型,此时它才有对应的classes_属性。
#使用fit函数拟合数据
clf.fit(X_train, y_train)
# 查看clf的classes_属性
print("classes_属性为:",end='')
print(clf.classes_)输出结果:

分析:
输入的标签集为:[-1,-1,1,1,-1,-1,-1,1,1,1,1,1,1,1,-1],在fit拟合数据后会把标签集的属性记录到classes_属性中,并且predict_proba的返回集也是根据classes_属性进行排列的。
即返回集的第一列对应classes_的第一个属性-1,返回集的第一列对应classes_的第一个属性1。















 155
155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









