







yolov7的文件夹打开之后是这个样子啦
一、准备YOLO格式的数据集
以下是三个常见目标检测数据集
VOC 格式一张图片对应一个xml文件
COCO 目录是直接将所有图片以及对应的box信息写在了一个json文件里
YOLO 数据集会直接把每张图片标注的标签信息保存到一个txt文件中已经标注好的yolo格式数据集会按照以下格式进行存放

train.txt

val.txt
网上有很多几种格式互相转换的教程
https://zhuanlan.zhihu.com/p/461488682
二、配置深度学习环境
https://blog.csdn.net/qq_65966646/article/details/132067244?spm=1001.2014.3001.5502
三、修改data数据集
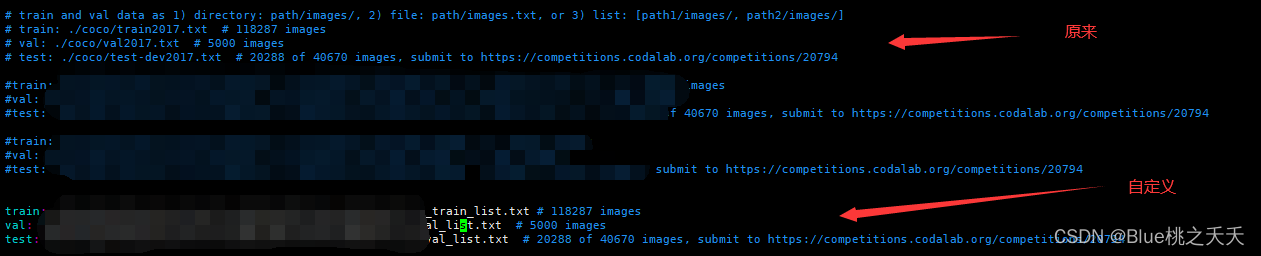
// coco.yaml 中放的是yolo的数据集【训练集、验证集和测试集】,以txt文件保存

在Linux中使用vi命令进入yaml文件进行修改
、、
vi coco.yaml
、、

改完之后这个样子

下面分别为训练集、验证集、测试集路径,将其修改为自己所存放数据的路径

修改过后
四、选择模型 (yoloV7)修改模型配置
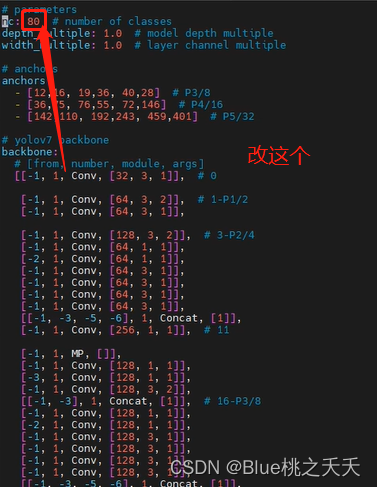
// 训练中模型的参数定义,采用yaml文件【注意是training下的yaml,不是deploy下的】,可以用于模型的选择
路径 cfg cfg/training/yolov7.yaml

最好自己cp一个yolov7.yaml文件,然后修改配置
五、用训练好的模型预测
github上检测的原指令是介个样子滴,如果不训练自己的数据集可以直接用这串命令在Linux上运行
、、
python detect.py --weights yolov7.pt --conf 0.25 --img-size 640 --source inference/images/horses.jpg
、、要使用自己的数据集的话在detect.py文件里可以看到需要改这两个地方

命令只需要在两个地方进行修改,conf和img-size想改就改,我依旧使用默认值

在runs/train/exp/weights文件夹里面保存了这次训练结束后整个网络模型的权重
![]()
自己选一个 ,将上面的命令改一改

设置好后就可以运行了,如果一切顺利的话,就可以等模型训练完成。
如果没有改代码其他设置,我们就可以在runs/train/exp文件夹下获取这次训练的结果
看看结果

















 2778
2778











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









