






本文为🔗365天深度学习训练营 中的学习记录博客
原作者:K同学啊|接辅导、项目定制
我的环境:
1.语言:python3.7
2.编译器:pycharm
3.深度学习环境:TensorFlow2.5
我是跟着CSDN上的k同学啊学习的有关深度学习方面的知识,他也是本次活动的带头人,我们一起跟着他好好学习关于深度学习方面的知识。
我们今天要学习有关天气识别的知识,是利用深度学习来实现的,他的原篇博客地址我放在这里:
https://mtyjkh.blog.csdn.net/article/details/117186183
一.设置GPU
若使用cpu可忽略
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
gpu0 = gpus[0]
tf.config.experimental.set_memory_growth(gpu0, True)
tf.config.set_visible_devices([gpu0],"GPU")
使用cpu训练
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
2.导入数据
首先导入我们所需要用到的包
import os,PIL,pathlib
import matplotlib.pyplot as plt
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers, models
import PIL
import tensorflow as tf
from tensorflow.keras.preprocessing import image_dataset_from_directory
from tensorflow.python.data.ops.dataset_ops import AUTOTUNE
原作者提供的数据集:
之后我们来导入数据所在的位置,并计算图片数量
data_dir = "E:\TF环境\天气识别\weather_photos"
data_dir = pathlib.Path(data_dir)
image_count = len(list(data_dir.glob('*/*.jpg')))
print("图片总数为:", image_count)图片总数为:1125import PIL
roses = list(data_dir.glob('sunrise\*.jpg'))
PIL.Image.open(str(roses[1]))
ff = PIL.Image.open(str(roses[1]))
ff.show()运用PIL(python3版本安装pillow库,安装完后依旧用PIL调用)库为pycharm添加图像处理功能打开sunrise文件夹中第二张照片。

二、数据预处理
1、加载数据(这里我们将使用到image_dataset_from_directory)
Image data preprocessing原型是
tf.keras.preprocessing.image_dataset_from_directory(
directory,
labels="inferred",
label_mode="int",
class_names=None,
color_mode="rgb",
batch_size=32,
image_size=(256, 256),
shuffle=True,
seed=None,
validation_split=None,
subset=None,
interpolation="bilinear",
follow_links=False,
)它的作用是将文件夹的数据加载到tf.data.Dataset中,且加载的同时会打乱数据
如果你的目录结构是:
main_directory/
...class_a/
......a_image_1.jpg
......a_image_2.jpg
...class_b/
......b_image_1.jpg
......b_image_2.jpg然后调用 image_dataset_from_directory(main_directory, labels='inferred') 将返回一个tf.data.Dataset, 该数据集从子目录class_a和class_b生成批次图像,同时生成标签0和1(0对应class_a,1对应class_b).
支持的图像格式:jpeg, png, bmp, gif. 动图被截断到第一帧。
参数:
- directory: 数据所在目录。如果标签是“inferred”(默认),则它应该包含子目录,每个目录包含一个类的图像。否则,将忽略目录结构。
- labels: “inferred”(标签从目录结构生成),或者是整数标签的列表/元组,其大小与目录中找到的图像文件的数量相同。标签应根据图像文件路径的字母顺序排序(通过Python中的os.walk(directory)获得)。
- label_mode: 'int':表示标签被编码成整数(例如:
sparse_categorical_crossentropyloss)。‘categorical’指标签被编码为分类向量(例如:categorical_crossentropyloss)。‘binary’意味着标签(只能有2个)被编码为值为0或1的float32标量(例如:binary_crossentropy)。None(无标签)。 - class_names: 仅当“labels”为“inferred”时有效。这是类名称的明确列表(必须与子目录的名称匹配)。用于控制类的顺序(否则使用字母数字顺序)。
- color_mode: "grayscale"、"rgb"、"rgba"之一。默认值:"rgb"。图像将被转换为1、3或者4通道。
- batch_size: 数据批次的大小。默认值:32
- image_size: 从磁盘读取数据后将其重新调整大小。默认:(256,256)。由于管道处理的图像批次必须具有相同的大小,因此该参数必须提供。
- shuffle: 是否打乱数据。默认值:True。如果设置为False,则按字母数字顺序对数据进行排序。
- seed: 用于shuffle和转换的可选随机种子。
- validation_split: 0和1之间的可选浮点数,可保留一部分数据用于验证。
- subset: "training"或"validation"之一。仅在设置validation_split时使用。
- interpolation: 字符串,当调整图像大小时使用的插值方法。默认为:
bilinear。支持bilinear,nearest,bicubic,area,lanczos3,lanczos5,gaussian,mitchellcubic.。 - follow_links: 是否访问符号链接指向的子目录。默认:False。
Returns
一个tf.data.Dataset对象。
- 如果label_mode为None,它将生成float32张量,其shape为(batch_size, image_size[0], image_size(1), num_channels),并对图像进行编码(有关num_channels的规则,参见下文)。
- 否则,将生成一个元组(images, labels),其中图像的shape为(batch_size, image_size[0], image_size(1), num_channels),并且labels遵循下面描述的格式。
关于labels格式规则:
- 如果label_mode 是 int, labels是形状为(batch_size, )的int32张量
- 如果label_mode 是 binary, labels是形状为(batch_size, 1)的1和0的float32张量。
- 如果label_mode 是 categorial, labels是形状为(batch_size, num_classes)的float32张量,表示类索引的one-hot编码。
有关生成图像中通道数量的规则:
如果color_mode 是 grayscale, 图像张量有1个通道。
如果color_mode 是 rgb, 图像张量有3个通道。
如果color_mode 是 rgba, 图像张量有4个通道。
image_dataset_from_directory方法就介绍到这里,现在我们去运用它加载照片
首先定义我们要加载的照片属性:
batch_size = 32
img_height = 180
img_width = 180train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)结果:
Found 1125 files belonging to 4 classes
using 900 files for trainingval_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)结果:
Found 1125 files belonging to 4 classes.
using 225 files for validation.接下来通过class_names输出数据集的标签。标签将按字母顺序对应于目录名称。
class_names = train_ds.class_names
print(class_names)
结果:
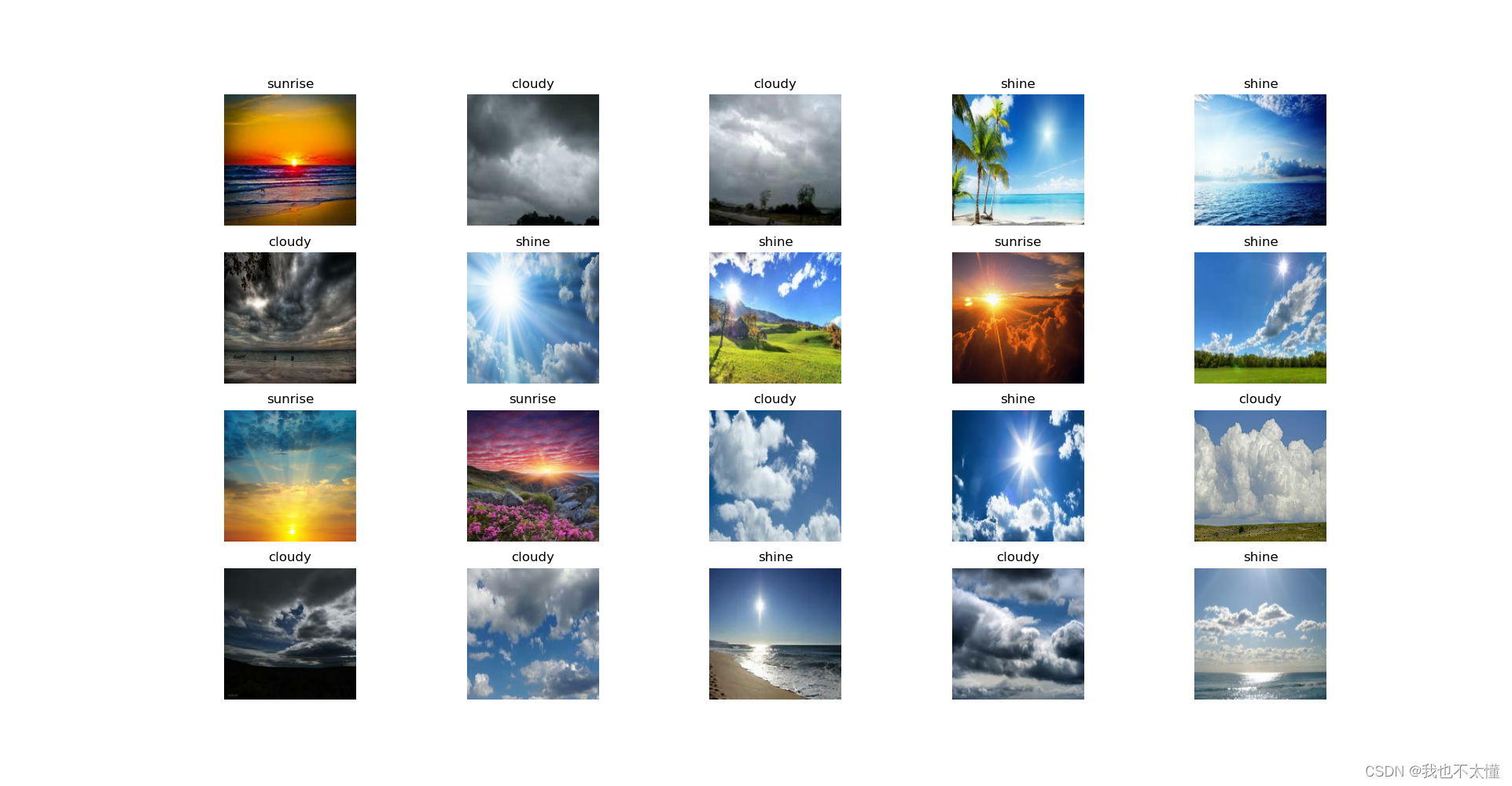
['cloudy','rain','shine','sunrise']2、可视化数据
for images, labels in train_ds.take(1):
for i in range(20):
ax = plt.subplot(5, 10, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
plt.show()(1)figure语法说明
figure(num=None, figsize=None, dpi=None, facecolor=None, edgecolor=None, frameon=True)
- num:图像编号或名称,数字为编号 ,字符串为名称
- figsize:指定figure的宽和高,单位为英寸;
- dpi参数指定绘图对象的分辨率,即每英寸多少个像素,缺省值为80 1英寸等于2.5cm,A4纸是 21*30cm的纸张
- facecolor:背景颜色
- edgecolor:边框颜色
- frameon:是否显示边框
(2)subplot语法说明:
| nrows | 行数 |
| ncols | 列数 |
| sharex | 和谁共享x轴 |
| sharey | 和谁共享y轴 |
| subplot_kw | 关键字字典 |
| **fig_kw | 其他关键字 |
3、再次检查数据
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
结果:
(32,180,180,3)
(32,)- Image_batch是形状张量(32,180,180,3)。这是一批形状180*180*3的32张图片(最后一维指的是彩色通道RGB)。
- Label_batch是形状(32,)的张量,这些标签对应32张图片。
4、配置数据集
- shuffle():打乱数据
- prefetch():预取数据,加速运行
- cache():将数据集缓存到内存当中,加速运行
from tensorflow.python.data.ops.dataset_ops import AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)三、构建CNN网络
CNN网络是卷神经网络的别名。而卷神经网络最擅长的就是图片的处理,它是受到人类视觉神经系统的启发。
卷积神经网络主要由这几类层构成:输入层、卷积层,ReLU层、池化(Pooling)层和全连接层(全连接层和常规神经网络中的一样)。通过将这些层叠加起来,就可以构建一个完整的卷积神经网络。在实际应用中往往将卷积层与ReLU层共同称之为卷积层,所以卷积层经过卷积操作也是要经过激活函数的。具体说来,卷积层和全连接层(CONV/FC)对输入执行变换操作的时候,不仅会用到激活函数,还会用到很多参数,即神经元的权值w和偏差b;而ReLU层和池化层则是进行一个固定不变的函数操作。卷积层和全连接层中的参数会随着梯度下降被训练,这样卷积神经网络计算出的分类评分就能和训练集中的每个图像的标签吻合了。
Dropout,它可以通过随机失活神经元,强制网络中的权重只取最小值,使得权重值的分布更加规则,减小样本过拟合问题,起到正则化的作用。当Dropout应用到某个层中,它会再训练过程中对所应用的层随机丢弃(你所设置的)输出数量单位。当Dropout取一个小数作为他的输入值(如:0.1、0.2、0.3......),代表了从应用的层中随机放弃10%、20%、30%的输出单位
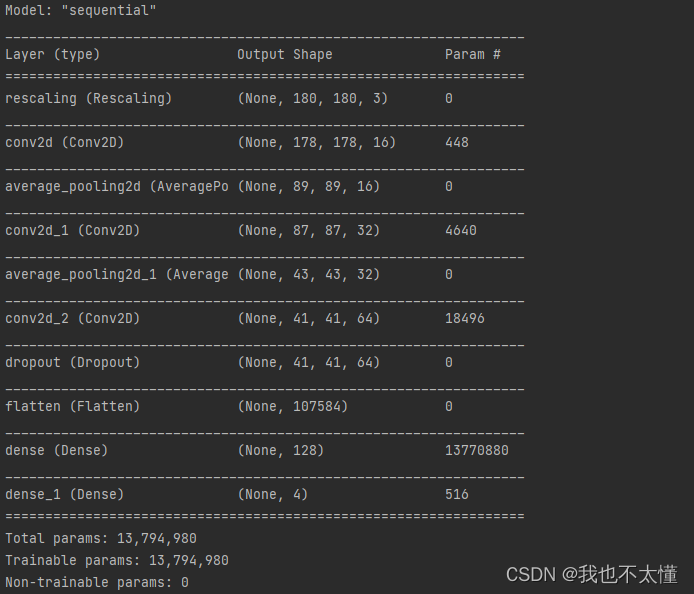
model = models.Sequential([
layers.experimental.preprocessing.Rescaling(1. / 255, input_shape=(img_height, img_width, 3)),
layers.Conv2D(16, (3, 3), activation='relu', input_shape=(img_height, img_width, 3)), # 卷积层1,卷积核3*3
layers.AveragePooling2D((2, 2)), # 池化层1,2*2采样
layers.Conv2D(32, (3, 3), activation='relu'), # 卷积层2,卷积核3*3
layers.AveragePooling2D((2, 2)), # 池化层2,2*2采样
layers.Conv2D(64, (3, 3), activation='relu'), # 卷积层3,卷积核3*3
layers.Dropout(0.3),
layers.Flatten(), # Flatten层,连接卷积层与全连接层
layers.Dense(128, activation='relu'), # 全连接层,特征进一步提取
layers.Dense(num_classes) # 输出层,输出预期结果
])
model.summary() # 打印网络结构
四、编译
在准备对模型进行训练之前,还需要设置一下优化器。优化器利用算法可以帮助模型再训练过程中更快地将参数调整好。在损失函数定义好的情况下,使用一种优化器进行求解最小损失。
Adam 算法利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。TensorFlow提供的tf.train.AdamOptimizer可控制学习速度,经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。
opt = tf.keras.optimizers.Adam(learning_rate=0.001)
model.compile(optimizer=opt,
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
optimizer(优化器):决定模型如何根据其看到的数据和自身的损失函数进行更新。
loss(损失函数):用于衡量模型在训练期间的准确率。
metrics(指标):用于监控训练和测试步骤。一上实例使用了准确率,即被正确分类的图像的比率。
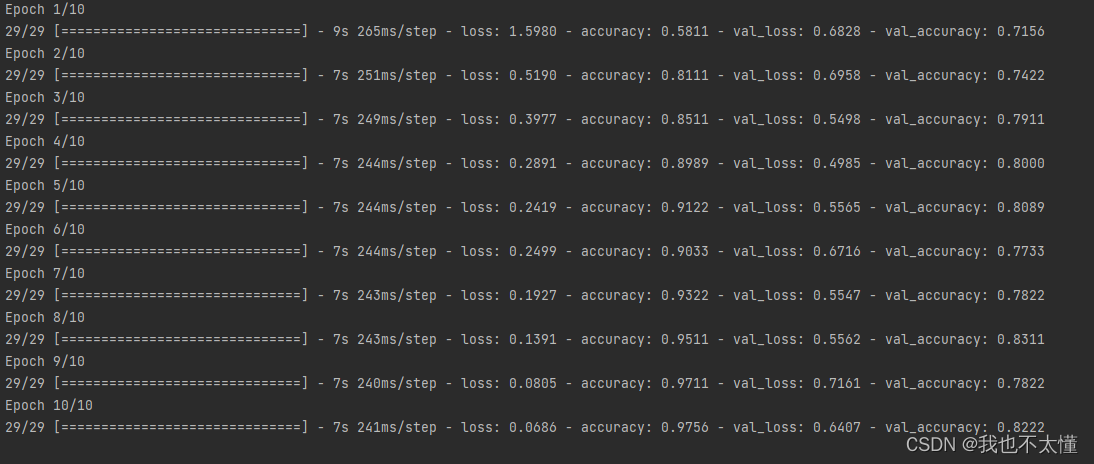
五、训练模型
epochs把所有训练数据完整执行一遍
epochs = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
model.fit()方法用于执行训练过程,使用方法如下:
model.fit( 训练集的输入特征,
训练集的标签,
batch_size, #每一个batch的大小
epochs, #迭代次数
validation_data = (测试集的输入特征,测试集的标签),
validation_split = 从测试集中划分多少比例给训练集,
validation_freq = 测试的epoch间隔数)
七、模型评估
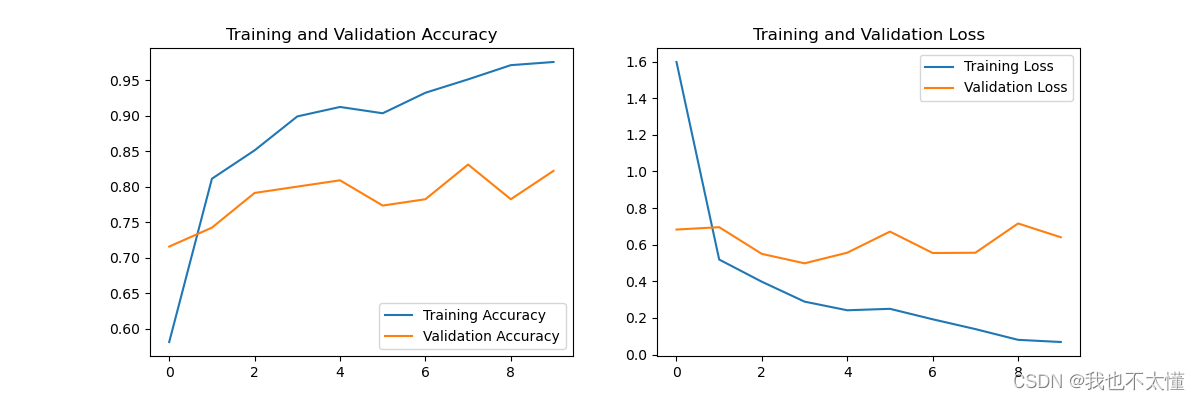
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
八、小结
在本次学习中我又巩固了一遍关于池化层、卷积层、Flatten层的相关知识。了解了Dropout处理过拟合的优点,更加深入地理解了构建CNN网络模型。在本次学习中新加入的设置优化器我还没有完全理解,同时全部代码中还有不少参数等待着我的进一步了解。















 820
820











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









