





1.ABSTRACT
1.1 背景
准确可靠的PM2.5和PM10浓度预测对公众合理避免空气污染和政府的政策反应非常重要。
1.2 挑战
由于大气流动的动态性,PM2.5和PM10浓度的预测具有很大的不确定性和不稳定性,单个模式难以有效提取时空依赖性。
1.3 提出的方法
本文报道了一个可靠的预报系统,可以实现对PM2.5和PM10浓度的精确多步提前预报。
1.采用相关分析方法筛选目标城市污染和气象的空间信息,便于对浓度进行预测。
2.利用时空注意机制从空间和时间两个维度为原始输入分配权重,增强基本信息。
3.利用残差卷积神经网络对改进后的输入进行特征提取。
4.采用5个精度指标和2个附加的统计检验对所提出的预测系统的性能进行了综合评价
1.4 实验结果
对长三角城市群区域3个主要城市的实验研究表明:
1.该预测系统在准确性和稳定性方面都优于目前流行的各种基线模型。
2.在定量上,与基线模型相比,本文提出的STA-ResCNN模型在3个主要城市的PM2.5和PM10平均提前1-4小时预测的均方根误差分别降低了5.595% ~ 15.247%和6.827% ~ 16.906%。
3.通过在全区其他23个城市的推广应用,进一步验证了该预测系统的适用性和泛化性。
结果表明,该预报系统在大气污染预警和区域防治中具有较好的应用前景。
2. Introduction
背景:随着世界经济的快速发展,空气污染引起了广泛关注,最主要的是PM10和PM2.5直径分别小于10和2.5µm。这些会对人的身体造成严重的损害。空气污染预测可以为公众和政府机构应对严重污染事件提供有效的预警和决策支持。因此,准确可靠地预测PM10和PM2.5的环境浓度是改善空气质量和保护公众健康的迫切需要。
2.1 Literature review
1.现有的工作
现有的空气污染物浓度预测方法大致可分为三类,即数值、统计和人工智能(AI)模型。
1.1 数值模型
数值模型本质上是通过构造和求解复杂的微分方程来模拟大气中污染物的物理和化学变化和运移过程。最新的代表性数值模型包括社区多尺度空气质量(CMAQ)和天气研究与预报耦合化学(WRF-Chem)。
不足;这些模型的准确性高度依赖于详细的污染源排放数据,而这些数据通常是不确定或不可用的.复杂的建模过程需要更多的时间和更多的计算能力.
1.2 统计模型
统计模型不涉及复杂的物理变化、化学反应和传输过程。它们仅基于对历史数据内部关系的数据驱动挖掘。因此,计算成本明显低于数值模型。经典统计模型,如自回归综合移动平均(ARIMA) (Kulkarni等人,2018)和自回归移动平均(ARMA) (Saffarinia和Odat, 2008)易于实现。
不足;这种模型主要适用于小数据集和单变量时间序列建模。而且这些模型都是基于线性假设,对数据的平稳性有严格的要求。因此,很难捕捉数据中的非线性关系。这些限制极大地限制了经典统计模型在大气污染预测中的性能和适用性。
1.3人工智能算法的模型
1.3.1机器学习
机器学习算法如支持向量回归(SVR) 、随机森林(RF)、极端梯度增强(XGB) 和人工神经网络(ANN) 已经开发用于空气污染预测。例如,Li等人提出了一种改进的最小二乘支持向量机(LSSVM)与多目标优化算法相结合的空气质量指数(AQI)预测算法。通过8个城市的数据验证了该模型的有效性和适用性。采用带有敏感性分析的ANN模型进行NO2浓度预测。灵敏度分析确定了输入参数的贡献。与传统的统计模型相比,这些机器学习模型可以充分逼近复杂的非线性关系,并且往往具有更强的鲁棒性和容错性。
机器学习的不足:机器学习模型通常需要研究人员手动构建特征,这在很大程度上依赖于个人经验。当处理越来越大的数据集时,它们表现出减少冗余数据的能力不足,这反过来影响了它们的学习和泛化能力。
1.3.2深度学习
深度学习算法在计算机视觉、情感识别、机器翻译、目标检测等多个领域取得了重大突破。作为最新的人工智能成果,深度学习算法因其出色的自学习能力和强大的非线性映射能力,也成为空气污染预测领域的热点。
单一RNN:其中,递归神经网络(RNN)及其变体,包括长短期记忆(LSTM)和门控递归单元(GRU),用于序列预测。这些模型不仅基于在当前时间点获得的信息,而且还考虑了之前时刻的先验信息。这一特性非常适合于时间序列空气污染预测,使得这些基于rnn的模型成为现有研究的主流。Chang等人提出了一种结合三个LSTM的聚合LSTM (ALSTM)模型用于PM2.5浓度预测。ALSTM的预测性能优于传统的机器学习算法,包括SVR和梯度增强树回归(GBTR)。Jiang et al . 开发了一种使用集合GRU预测PM2.5短期浓度的混合模型。集成策略结合了多个gru的输出,提高了模型的精度和稳定性。该模型的预测性能优于人工神经网络和单一GRU。考虑到基于rnn的模型能够捕获序列数据的时间依赖性,在大多数情况下,它们比统计和机器学习模型更有效。
不足之处:空气污染预测需要模拟各种复杂和非平稳的空气污染物数据与气象数据之间的时空关系。单一的基于Rnn的模型在处理时空相关性数据集时可能仍然不足。
克服单一RNN的不足:研究人员采用了其他深度学习算法来增强时空建模。卷积神经网络(cnn)提供了出色的特征提取能力,因为卷积操作的权重共享和局部感知为了克服单一基于单一RNN的模型的缺点,研究人员采用了其他深度学习算法来增强时空建模。
卷积神经网络(CNNs)由于具有权重共享和卷积操作的局部意识,因此提供了出色的特征提取能力,已成为一种提取时空特征以预测空气污染的有效方法。采用CNN模型预测提前24小时的O3 浓度。模型输入同时包含空气污染和气象数据。此外,对21个站点的预测结果显示,CNN模型优于GRU、Ridge和Lasso回归。Ding等人还开发了一种基于时空相关性的CNN-LSTM PM2.5浓度预测混合模型。利用CNN和LSTM分别提取输入数据的空间特征和时间依赖性。CNN-LSTM模型超过了多层感知器(MLP)和单个LSTM模型。而时空相关性的加入提高了所提出的CNN-LSTM模型的预测精度。Faraji等人提出了一个3D CNN-GRU混合模型来预测每小时和每天的PM2.5浓度。与LSTM、GRU、ANN、SVR和ARIMA相比,该模型的效果也最好。Sharma等人在他们的PM10预测研究中也验证了类似的结果。这些研究启发我们对基于cnn的模型进行调查,以充分探索PM2.5和PM10浓度与其他污染物浓度和气象特征之间的时空关系。
注意机制也被广泛地用来提高深度学习模型的预测精度。注意机制是近年来在自然语言处理(NLP)和图像分析中最普遍的概念之一。它的主要原理是帮助模型关注于更重要的特征信息。它们还被广泛应用于洪水、风力和交通等时间序列预测任务。例如,Ding等人提出了一种混合可解释的时空注意LSTM(STA-LSTM)来预测洪水事件。时空注意对输入数据的时空分布分配权重。STA-LSTM的表现优于个体LSTM和CNN模型。
不足之处;据我们所知,时空注意机制还没有被探索或用于空气污染的预测。Zhang等人提出了一种整合注意的双向GRU机制。实验结果表明,该模型比同类模型能更好地捕捉到历史信息中最重要的部分。与流行的LSTM、GRU、CNN-LSTM和RF模型相比,预测性能有了显著提高。然而,他们在研究空间特征的工作中并没有考虑到空间注意机制。因此,值得进一步研究这一有前途的时空关注机制,以加强空气污染的预测。
2.2. Contributions and novelties
根据以上文献综述,可以有效地挖掘数据的时空特征,是提高空气污染预测性能的关键。为了解决这一挑战,实现更准确和稳定的预测,我们提出了一种基于卷积神经网络的混合预测系统,结合时空注意和残差学习(STAResCNN),用于PM2.5和PM10浓度的多步预测。本工作的新颖性和贡献总结如下:
1.建立了一种先进的多变量空气污染物预测系统,为区域联合防治提供多步骤、准确、可靠的预警。该系统包括时空特征构建、模型预测和综合评价,共同提高了空气污染物预测的有效性。
2.我们介绍并改进了空气污染预测的时空注意机制。利用时间注意机制和空间注意机制分别从时间维度和空间维度中提取特征。因此,可以根据注意权重的分布,有效地挖掘时滞和空间依赖性等重要信息,提高了空气污染物浓度的可预测性。
3.我们通过将CNN与残差学习相结合,获得了准确的预测结果。考虑到该模型的时空矩阵输入的高维性,我们采用了一个具有较强的特征提取能力的CNN作为核心预测模块。此外,在CNN中引入了残差学习,以防止模型性能下降。
3. Study area and dataset analysis
3.1. Study area
选择长三角城市群作为研究区,如图1所示显示了整个研究区域的地理分布情况。上海、南京和杭州是整个研究区域中最发达的政治和经济中心,人口密集。因此,他们被选择为主要的研究对象。然后,我们对其他23个城市实施了验证后的模型。它位于长江下游,属亚热带季风气候,季节分明,雨量适中。然而,与先进的国际标准相比,空气质量仍有很大的改进空间。PM2.5和PM10是主要污染物的天数占每年污染总天数的近一半(中华人民共和国生态环境部。中国的生态与环境状况,2021年)。因此,准确预测这一领域的PM2.5和PM10是非常重要的。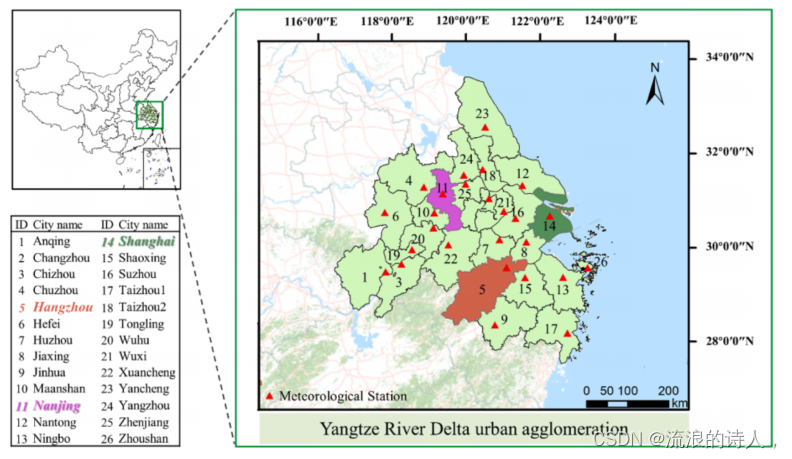
图1:长三角城市群的地理分布情况。
3.2. Data description and preprocessing
PM2.5和PM10与其他主要污染物之间的关系是复杂的。例如,PM2.5和O3具有共同的前体(如NOx),并且它们在大气中也以各种方式相互作用。因此,我们预先选择了所有六种主要污染物(PM2.5、PM10、O3、二氧化氮、CO和SO2)和AQI作为预测PM2.5和PM10浓度的模型输入。请注意,这些变量使用每个城市多个监测站对应的平均值来降低模型输入的复杂性。此外,风速、湿度、温度等气象数据会影响空气污染物的扩散。因此,我们收集了中华人民共和国生态环境部(https://air.cnemc.cn:18007/)2018年1月1日至2019年12月31日期间六种主要污染物和AQI的每小时浓度数据,每个城市共有17520条记录。同期的每小时气象数据来自开放天气系统(https://openweathermap.org/。
对收集到的数据进行如下预处理。首先,通过序列号编码,将非数值数据,即天气条件的参数(见补充文件中的表S1)转换为数字数据。然后用简单的线性插值填充收集数据集中约1.651 %的缺失值。为了加速模型的收敛速度和消除该幅度 不同维度的差异,所有数据使用min-max标准化从0到1进行归一化。最后,三个主要城市的统计信息如表1所示,以更直接地呈现数据。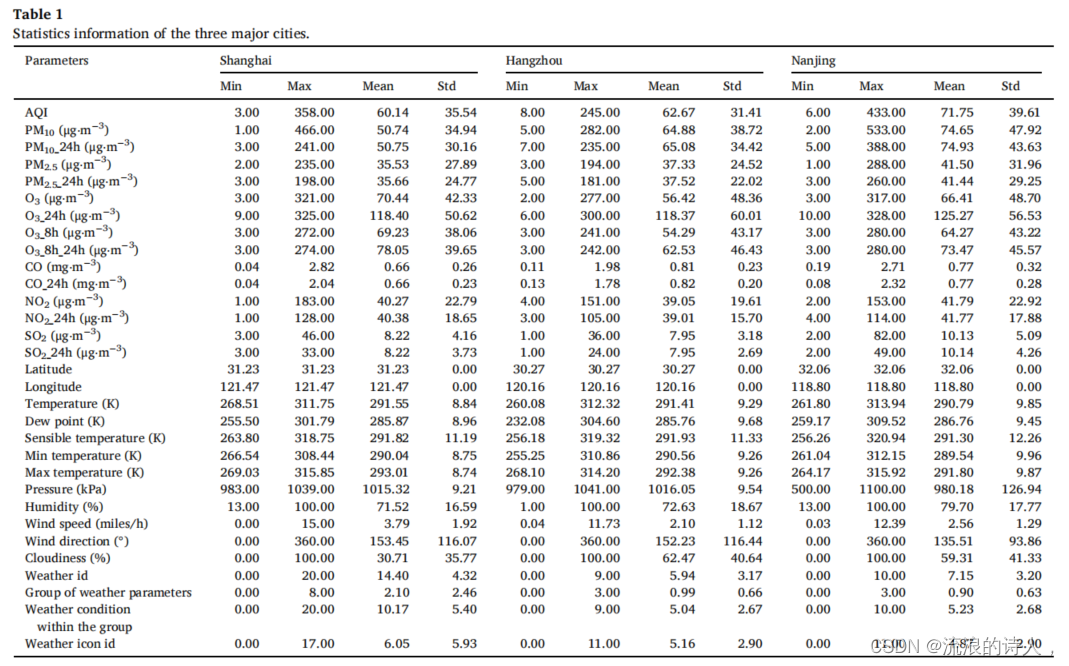
4. Methodology
4.1. The framework of the proposed forecasting system
图2显示了所提出的预测系统的框架。整体结构主要包括以下三个步骤:
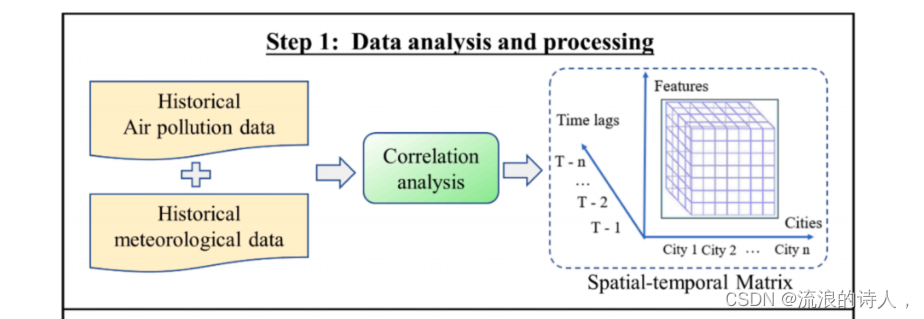
首先,在数据分析和处理阶段使用 ,确定目标城市与研究区域其他城市之间的空气污染物PM2.5或PM10的相关度。这是因为目标城市与其他城市之间的PM2.5或PM10浓度的皮尔逊相关系数与城市之间的距离呈负相关,可用于空间分析。以往的研究也表明,其他城市的信息与目标城市中相应的信息高度相关,提高了模型的准确性。然而,添加来自更多城市的信息并不一定会提高模型的准确性,因为添加无用的低相关信息可能会使建模复杂化,并降低建模的准确性。因此,建议逐步筛选有助于改进基于相关阈值排序的预测的有用空间信息。PM2.5和PM10浓度的皮尔逊相关结果如图所示。处理后的数据被构造为时空矩阵,随时准备进行模型输入。
第二步是整个系统的核心,即使用我们提出的STA-ResCNN模型进行时空预测建模。在这一步中,利用时空注意机制来探索原始模型输入的时空信息分布。具体来说,构建的模型输入时空矩阵形成三维张量;三维张量的三维维度、通道、高度和宽度分别是回顾步长(即考虑的历史时刻的数量)、城市(目标城市和其他筛选城市)和特征(空气污染物和气象信息)。相应地,时间注意机制从通道维度中提取时间权重分布,空间注意机制从高度和宽度维度中提取空间权重分布。然后,将时空注意机制的权值分配后得到的细化输入输入到下一个模块中。本文采用带有残差学习的深度CNN模型来充分提取细化输入的时空特征。最后,全连接(FC)层将特征提取结果映射到最终的多步提前输出。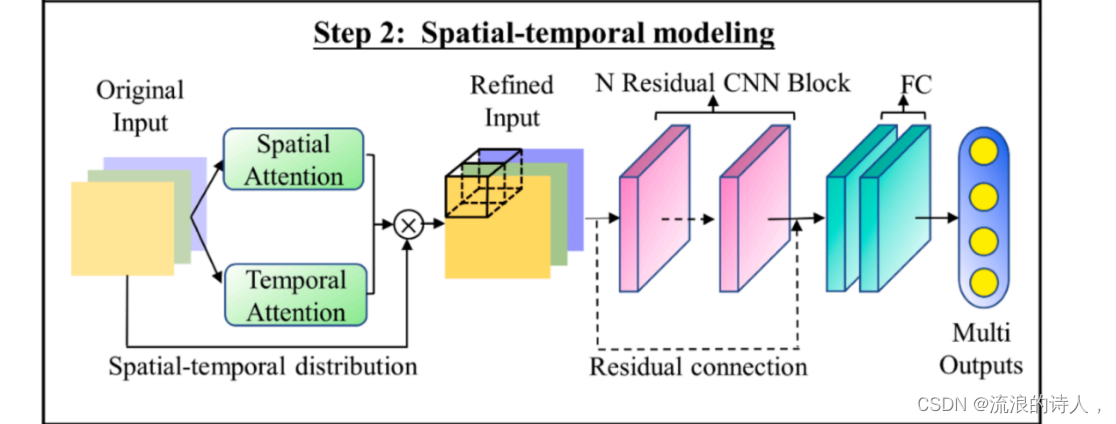
该框架的最后一个阶段是模型评估。首先,将该模型的预测值和最先进的基线模型的预测值与实际值进行比较,计算出各种指标,并进行交叉比较,以验证该模型在预测PM2.5和PM10浓度方面的优越性。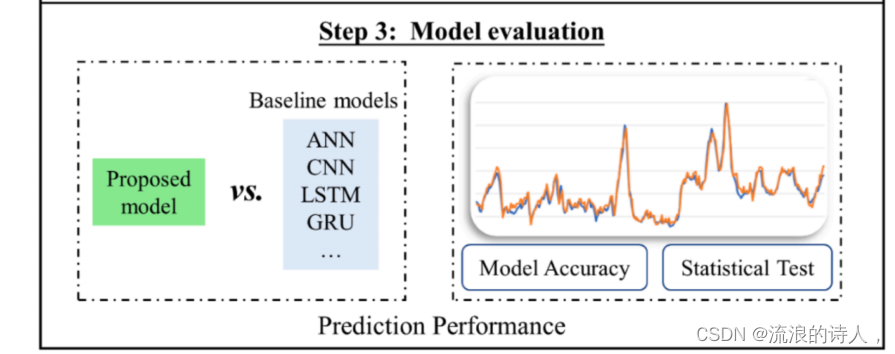
4.2. Spatial-temporal attention
4.2.1. Spatial attention (SA) module
空间注意(SA)机制强调内部空间目标城市与周边城市之间的空气污染与气象特征的关系。图3为SA模块的示意图。首先,沿着信道维度进行最大池(MaxPool)和平均池(AvgPool)操作,以生成两条独特且有价值的信道信息。随后,将分别获得的MaxPool和AvgPool结果,FS Max∈R1×××W和FS Ave∈R1×××W连接起来,生成有效的特征图。然后通过标准卷积层和s型激活函数进行处理,生成空间注意分布的二维分布图[MS (F)∈R1×H×W]。计算过程如图等式所示 (1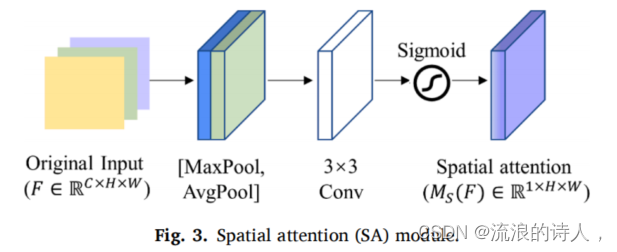
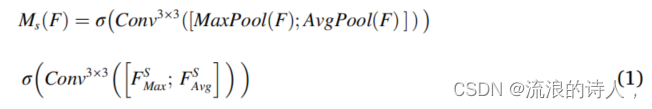
其中Conv3×3称为滤波器大小为3的滤波器3的卷积层,σ,由等式定义(2),表示映射在0到1之间的结果的Sigmoid函数。
4.2.2. Temporal attention (CA) module
与空间注意机制不同,时间注意机制更侧重关注不同历史时刻的输入对当前和未来时刻的影响。自从通道原始输入的维数表示历史时间滞后信息,CA模块自适应用于提取原始输入之间的内部时间关系。通过学习每个通道的权重,可以分别加强和抑制有意义的和无用的历史信息。CA模块的结构如图4所示。它首先应用全局MaxPool和AvgPool操作来聚合空间特征信息。这个过程产生两个空间特征向量,包含独立和有意义的空间特征,即FC Max∈RC×1×1和FC Avg∈RC×1×1。然后,这两个向量被输入一个共享的神经网络,以进一步生成通道注意图。共享神经网络由两个卷积层组成,其效果与Ref中采用的MLP相同.也就是说,要捕获非线性的跨通道权值。然后,将生成的两个输出向量进行元素求和。最后,通过激活函数可以产生时间注意权重分布(MC (F)∈RC×1×1)。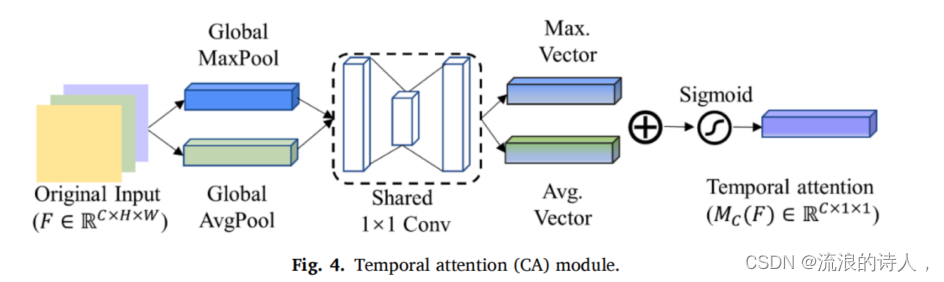
因此,前面的过程可以计算为 其中,W0和W1表示滤波器大小为1×1的卷积层。R被称为还原比。默认为6。这个降维过程的目的是控制模型的复杂性。和SA模块一样,σ也表示sg函数。
其中,W0和W1表示滤波器大小为1×1的卷积层。R被称为还原比。默认为6。这个降维过程的目的是控制模型的复杂性。和SA模块一样,σ也表示sg函数。
4.2.3. Spatial-temporal attention module
SA模块和CA模块分别专注于提取原始输入的时空权值分布。因此,它们会相互补充。这两个模块的融合过程如图5所示。将时空注意分布的元素级乘法结果转发到一个激活函数中,生成时空注意分布(MST (F) ∈ RC×H×W).最终的细化输入(F*∈RC×H×W)可以通过元素明智地将时空注意分布与原始输入相乘得到。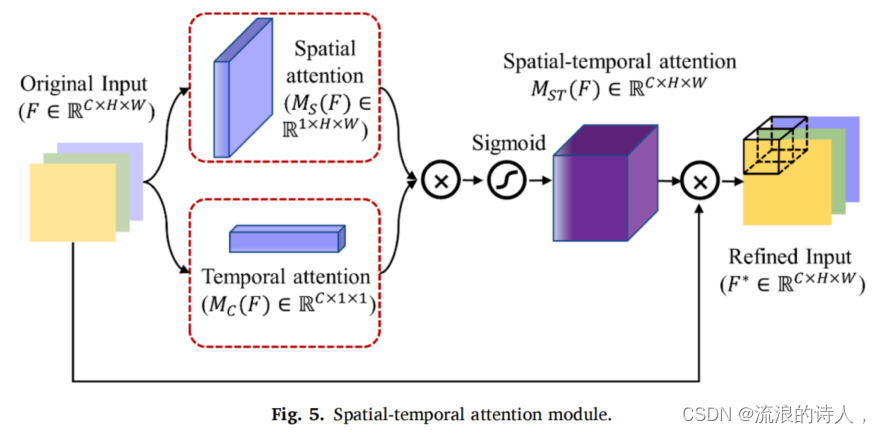
![]() 其中⊗和σ分别表示元素乘法和Sigmoid函数。
其中⊗和σ分别表示元素乘法和Sigmoid函数。
4.3. Convolutional neural network with residual learning
4.3.1. Convolutional neural network
由于CNN强大的特征提取和表示能力,越来越多的研究报道使用CNN来处理时空数据。传统的CNN主要由卷积层和池化层组成,其中卷积层是CNN的核心。通过定期滑动滤波器的卷积操作,可以从原始数据中提取出不同层次的特征。当每个过滤器遍历输入特性时,过滤器参数是固定的。这种权重共享方法大大减少了参数的数量,防止了参数过多导致的过拟合。与普通的神经网络不同,卷积层仅通过设置比输入值小得多的核大小而与相邻层部分连接。这种连接被称为稀疏连接;它加强了相邻层之间的本地交互,并减少了存储需求。每个位置的输出可以通过卷积运算来计算.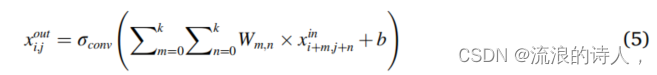 其其中,xouti、j和xini+m、j+n分别为特征映射的第i行和第j列的输出值和输入值。Wm,n表示卷积核的第m行和第n列的权值;b是卷积核的偏差;σconv表示激活函数,以保证模型的非线性映射能力。对于CNN模型,经过反复试验,我们选择了双曲切线(Tanh)函数。池化层主要对卷积层的输出进行降维,从而降低了计算成本。然而,空气污染预测受到不稳定和不确定性的影响(例如,极端天气可能导致污染物浓度的突然变化)。因此,池化层可能会消除可能对预测有用的敏感特性。此外与图像和视频特征相比,该任务中的空气污染物的数量和计量特征可以忽略不计。因此,正如Ref和我们的验证结果所建议的那样,在我们的CNN模型中没有使用池化层,以确保所有信息都是完整的。
其其中,xouti、j和xini+m、j+n分别为特征映射的第i行和第j列的输出值和输入值。Wm,n表示卷积核的第m行和第n列的权值;b是卷积核的偏差;σconv表示激活函数,以保证模型的非线性映射能力。对于CNN模型,经过反复试验,我们选择了双曲切线(Tanh)函数。池化层主要对卷积层的输出进行降维,从而降低了计算成本。然而,空气污染预测受到不稳定和不确定性的影响(例如,极端天气可能导致污染物浓度的突然变化)。因此,池化层可能会消除可能对预测有用的敏感特性。此外与图像和视频特征相比,该任务中的空气污染物的数量和计量特征可以忽略不计。因此,正如Ref和我们的验证结果所建议的那样,在我们的CNN模型中没有使用池化层,以确保所有信息都是完整的。
4.3.2. Residual learning
一般认为CNN层越深,提取的高级特征越丰富,从而提高模型性能。然而,过深的网络可能过拟合,难以训练,这可能导致网络退化。因此,我们提出了残差学习的概念来解决这个问题。图6为本工作中采用的残余块。该块由两个分支或映射组成,即残差映射和标识映射。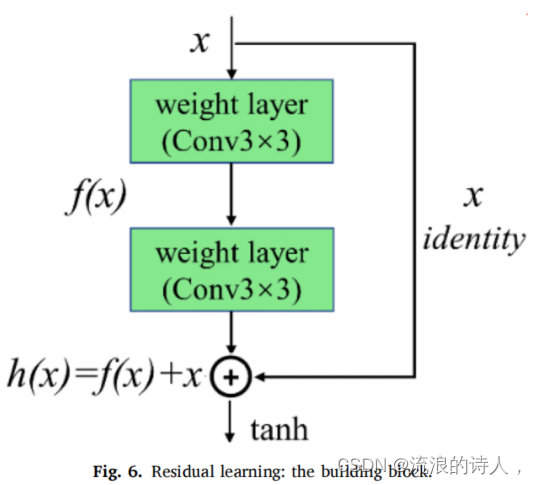
它可被定义为:![]() 其中,x和y分别为多层膜的输入和输出。f(x,Wi)表示需要学习的残差映射,可以进一步表示为:
其中,x和y分别为多层膜的输入和输出。f(x,Wi)表示需要学习的残差映射,可以进一步表示为:![]()
其中,W和b分别为两个权重层的权重向量和偏差向量。要实现身份映射,x和f(x,Wi)的维数必须相同。否则,等式(8)可以实现以匹配这些维度。![]() 其中Ws表示x上的线性项目。
其中Ws表示x上的线性项目。
根据图6中的块结构,当残差映射接近于零时,该块将只执行标识映射。身份映射通过在输入和输出之间的快捷连接来保护原始信息的完整性。这样,网络性能的退化就可以被最小化。在实践中,残差映射通常是非零的,这允许块学习残差映射。在形式上,原始映射可以定义为:![]()
其中,h (x)表示原始的底层映射,f (x)是残差函数,x是输入。原始映射可以重新重铸为f (x) + x。这种快捷方式连接允许功能从一个残差块直接连接到另一个残差块。这种操作使残差学习简化了模型的学习目标和困难。受这一特性的启发,在我们所提出的模型中引入了图6中所示的两个残差学习块。其中,h (x)表示原始的底层映射,f (x)是残差函数,x是输入。原始映射可以重新重铸为f (x) + x。这种快捷方式连接允许功能从一个残差块直接连接到另一个残差块。这种操作使残差学习简化了模型的学习目标和困难。受这一特性的启发,在我们所提出的模型中引入了图6中所示的两个残差学习块(见图2中的步骤2)。
4.4. Model evaluation
4.4.1. Baseline models
4.4.2. Evaluation metrics
模型间预测性能的定量交叉比较对于评估所提模型的优势和有效性至关重要。因此,为此目的,我们开发了一个综合评估,包括表2中总结的各种指标。
注:N为预测样本的总数。yobs和ypre分别为第i个观测值和预测值。yi obs表示观测值的平均值
具体来说,RMSE、MAE和MAPE反映了观测值和预测值之间的差异和预测误差。IA和TIC描述了观测值和预测值之间的相关性和准确性分析RMSE和MAE的值由因变量的尺度决定,而IA和TIC的范围通常为0~1。一般来说,RMSE、MAE、MAPE、TIC越小,IA越大,说明模型的精度越高。
除了这五个指标外,我们还引入了另外两个额外的统计测试,即迪堡-马里亚诺(DM)和稳定性测试,以进一步巩固绩效评估。
DM检验常用于比较两个时间序列模型的预测结果,并确定哪个模型具有较好的预测能力。它的零假设(H0)假设这两个模型具有相同的预测效果,而备择假设(H1)是相反的。假设检验可以表示为:

其中e pro i和ebase i代表提出的预测误差基准模型
各自地g表示一个损失函数,如MSE(均方误差)和MAE。E表示期望计算。然后,DM的统计数据可以表述如下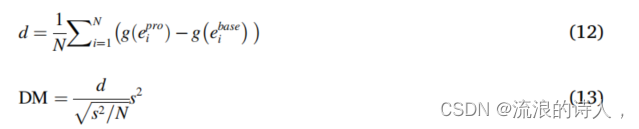
其中,N为预测样本的总数。s2表示g(e pro i)−g(ebase i)的渐近方差的一致估计。在原假设下,DM检验的统计量符合渐近标准正态分布。因此,对于给定的显著性水平,如果统计值在区间[−Z(α/2),Z(α/2)]内,则不应拒绝α,H0。否则,H0将被拒绝,这意味着在显著性水平α下,所提出的预测系统和基线模型之间存在显著的性能差异。
模型稳定性是现实应用中另一个必要的指标。稳定性高的预测模型具有较强的抵抗异常输入条件的能力,保证了预测的可靠性。在本研究中,我们采用预测误差的方差来进行稳定性检验。它可以表示为等式

其中,ei和ei为周期i的绝对预测误差和N个绝对预测误差的平均值。
5. Experimental design
将第2.2节中的数据按顺序分为训练集、验证集和测试集,比例为80 %: 10 %: 10 %。相关性分析如图所示。我们使用补充文档中的S1和S2来粗略地去除不相关的空间信息,以降低模型的复杂性。然后,将筛选出的变量构造为适合于模型输入的时空矩阵。不同预测任务的空间因素的最优组合由试错法确定(见补充文件表S2)。
模型的超参数设置和结构设计严重影响着其预测性能。为了保证模型性能比较的公平性,我们进行了大量的随机搜索测试,以探索模型的最优超参数设置和结构设计。表3总结了这些模型的常见超参数设置。具体来说,我们利用过去12小时的时空空气污染物和气象信息来预测未来4小时的PM2.5和PM10浓度。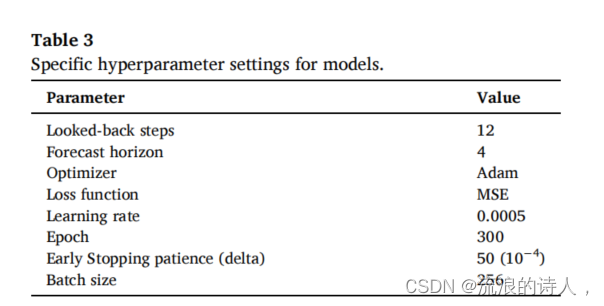
损失函数确定为MSE,相应的学习率为0.0005,使模型尽可能收敛。迭代为300,采用早期停止法防止模型过拟合。如果在验证集上连续50个周期内每两个周期的损失函数下降小于10−4,则认为模型的计算是收敛的。在模型结构上,所提出的STA-ResCNN模型从第3.2节中描述的时空注意模块开始,以分配原始输入的权重。然后,通过实验确定两个残差CNN块,从细化的输入中实现特征提取。然后,采用三个全连通层将二维特征映射转换为一维向量,以实现最终的回归输出。基线模型的结构见第3.4.1节。
6. Results and discussion
本节主要通过洞察性的讨论来详细阐述我们的实验结果。首先,在第5.1节和第5.2节中讨论了三个主要城市的两个实验的精度结果,即PM2.5和PM10的预测。随后,进行了DM测试和稳定性测试,以进一步验证第5.3节中的模型性能。最后,在第5.6节中,将验证后的预测系统扩展到长三角城市群内的其他23个城市,分析其适用性。
6.1. Experiment I: PM2.5 forecasting of three major cities
实验一比较了所提模型与基线模型在PM2.5浓度预测方面的性能。三个主要城市的预测结果见表4,其中不同预测范围下的最优结果以粗体突出显示。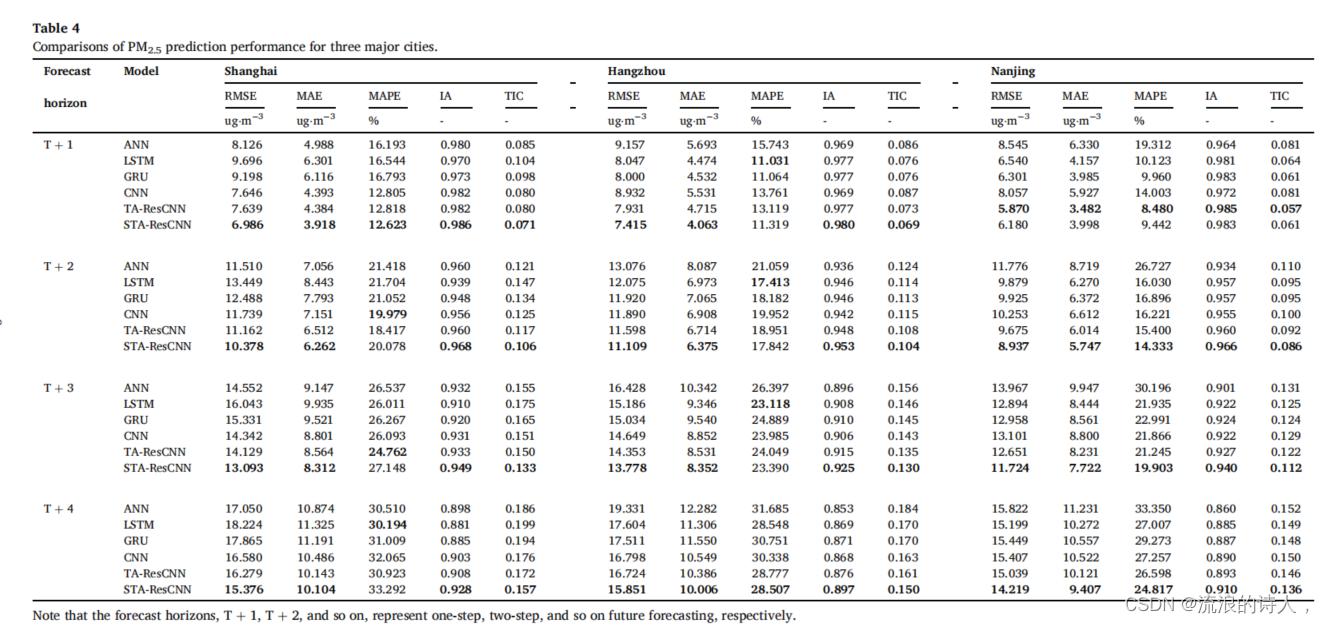
首先,与基线模型相比,我们提出的STA-ResCNN模型在几乎所有预测场景中产生最小的RMSE、MAE、MAPE和TIC值和最高的IA值(南京city预测提前一步除外)。这些初步结果表明,所提出的STA-ResCNN在精度指标方面优于其他基线模型。
其次,所采用的人工神经网络模型是传统的机器学习的代表,在大多数情况下,其预测精度低于其他深度学习模型。这表明,深度学习算法在处理大数据时,可以比机器学习算法更具有鲁棒性和适应性.
第三,LSTM模型、网格学习模型和CNN模型这三种流行的深度学习模型的性能取决于特定的预测任务。这反映了一个单一的深度学习模型在遇到复杂的预测任务时,不能保证恒定的鲁棒性;这一发现与以前的研究是一致的
第四,在大多数情况下,TA-ResCNN模型仅次于所提出的STA-ResCNN模型。这一发现表明,引入时间注意机制可以有效地从历史输入中获取重要信息,有利于预测的准确性。此外,时间注意和空间注意的结合,通过进一步挖掘城市间的时空信息,提高了STA-ResCNN模型的预测能力,从而提高了模型的性能。因此,强烈建议考虑目标城市周围的空间依赖性,以提高预测精度。
为了量化所提出的STA-ResCNN模型相对于基线模型的改进程度,图7 a)根据表4给出了每个模型在所有预测场景下的计算平均度量。然后将各度量IRRMSE、IRMAE、IRMAPE、IRIA、IRTIC的平均改进率统一计算为
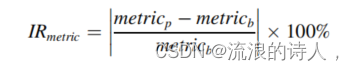
其中,度量p和度量b分别表示所提出的STAResCNN模型和基线模型的度量。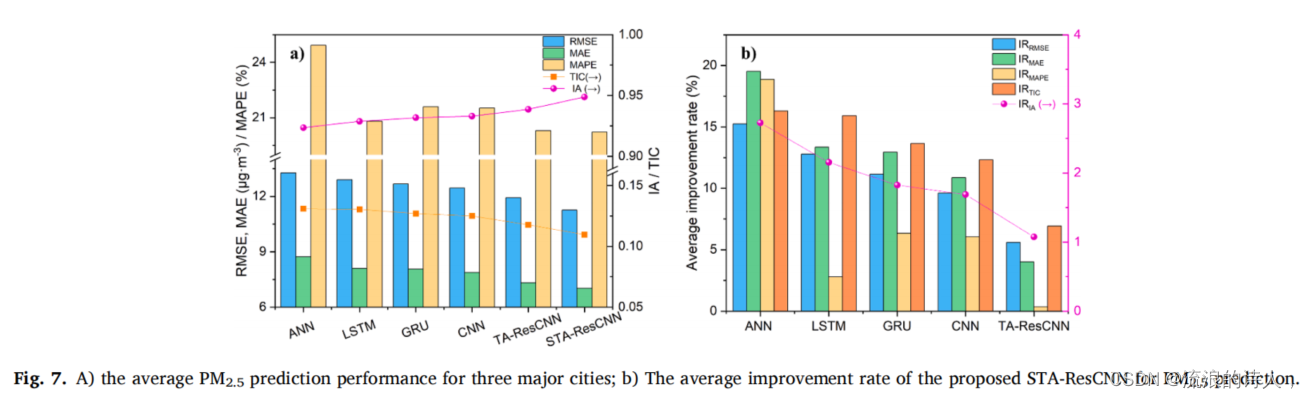
根据图7中的结果,可以进一步总结以下几点:
(1)从图7 a)可以看出,模型的总体性能按ANN、LSTM、GRU、CNN、TAResCNN和STA-ResCNN的升序排列。这再次证实了所提出的模型相对于基线模型的优势。
(2)图7 b)显示了所提出的STA-ResCNN模型相对于其他基线模型的IRRMSE、IRMAE、IRMAPE、IRIA和IRTIC的一致趋势。以RMSE度量为例,与ANN相比,STA-ResCNN模型、LSTM、GRU、CNN和TA-ResCNN模型的平均改进率分别为15.247 %、12.781 %、11.142 %、9.604 %和5.595 %。根据先前的研究,这些平均改善率是相当大的。这证明了时空注意机制对提高模型性能的有效性。
6.2. Experiment II: PM10 forecasting of three major cities
实验二建立了三个主要城市的PM10浓度预测结果。为了避免实验一中所解释的主题的重复,本节直接展示了最终的预测结果。从表5可以看出,PM10的估计与实验i中PM2.5的估计相似。所提出的STA-ResCNN模型在RMSE、MAE、MAPE、TIC最低但IA最高的大多数情况下再次表现出最佳的预测性能。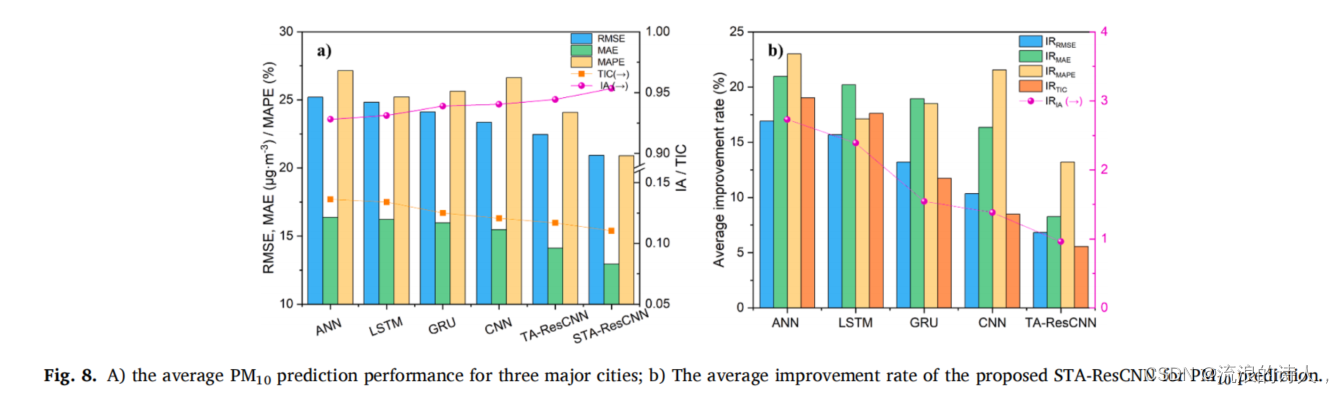
同样,图8 a)显示了模型的整体性能三个主要城市的PM10浓度预测也按ANN、LSTM、GRU、CNN、TA-ResCNN和STAResCNN的升序排列。图8 b)的平均改善率趋势与实验一的趋势一致:IRRMSE、IRMAE、IRTIC按ANN、LSTM、GRU、CNN和TA-ResCNN的降序排列。这进一步证实了该模型在我们的预测任务中是对以前的深度学习算法的改进。此外,所提出的结合了时空注意机制和残差学习的STA-ResCNN模型相比,大大提高了预测精度。
6.3. Additional DM test and stability test of the proposed model
本节通过另外两个统计检验,进一步评估了所提出的STA-ResCNN模型和基线模型在准确性和稳定性方面的显著差异。
6.3.1. DM test for significant difference in accuracy evaluation
表6总结了不同预测任务的DM测试结果,以评估所提出的准确性之间的显著差异,STA-ResCNN和其他模型。大部分检验统计量均大于1.96,说明在5%的显著性水平上拒绝了原假设。换句话说,在95 %的置信区间内,我们提出的模型的准确性在大多数预测场景中优于其他基线模型。因此,可以得出结论,与其他基线模型相比,所提出的STA-ResCNN模型的总体精度显著提高,这与第5.1和5.2节的结果一致。
6.3.2. Stability test of the proposed model
PM2.5和PM10的浓度受到复杂因素的影响;它们通常是动态的和无序的。因此,高度稳定的模型可以提供更准确和可靠的预测。我们在等式中使用预测误差(Svar)的方差(14)评价各模型的稳定性。Svar值越小,模型的稳定性越高。
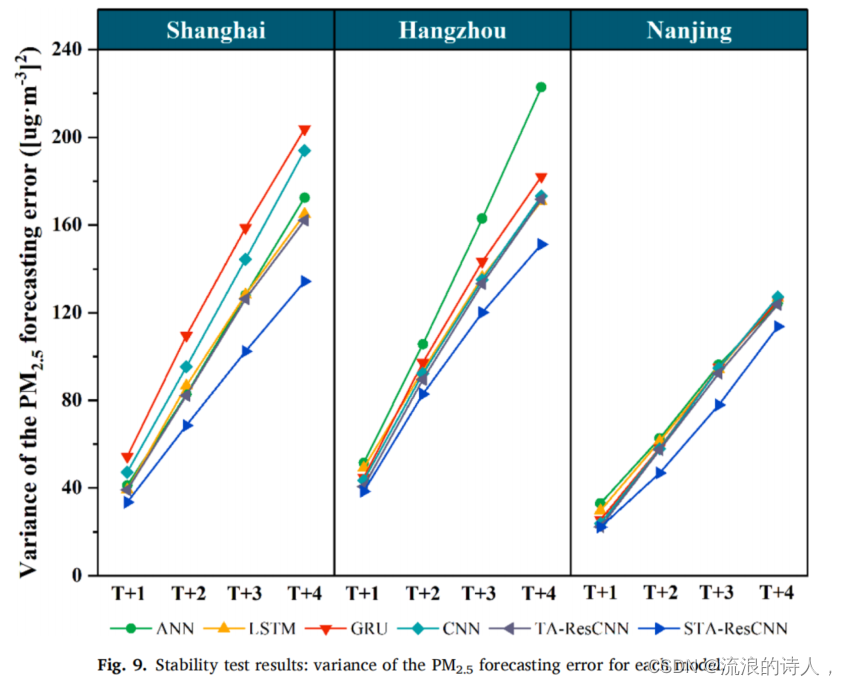
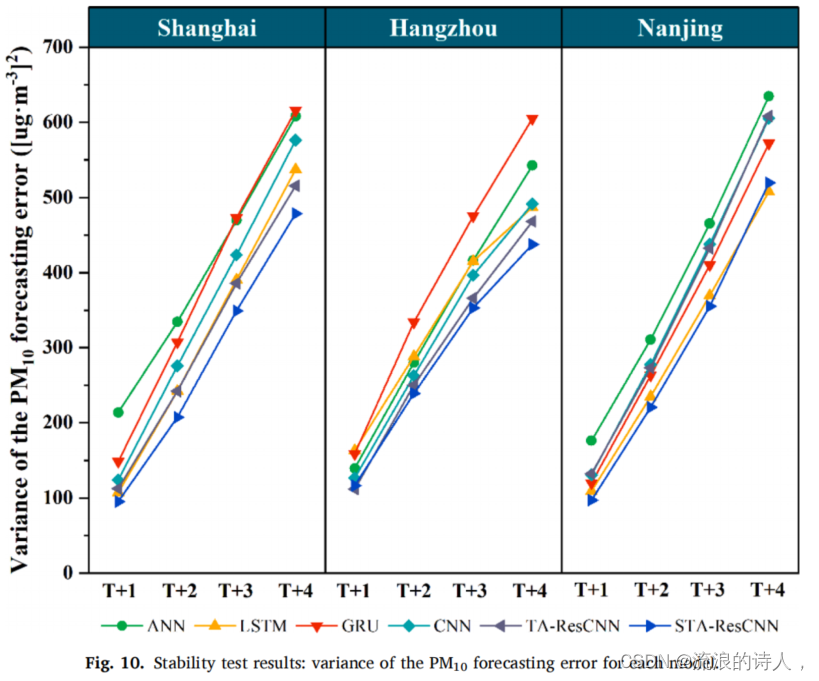 图9和图10分别显示了PM2.5和PM10浓度预测的稳定性试验结果。所提出的STA-ResCNN模型在几乎所有的预测场景中都达到了最低的Svar值。这意味着所提出的STA-ResCNN模型比其他基线模型更稳定。总之,广泛的交叉比较的预测精度。
图9和图10分别显示了PM2.5和PM10浓度预测的稳定性试验结果。所提出的STA-ResCNN模型在几乎所有的预测场景中都达到了最低的Svar值。这意味着所提出的STA-ResCNN模型比其他基线模型更稳定。总之,广泛的交叉比较的预测精度。
在实验I和实验II的模型之间,DM检验和稳定性测试表明,所提出的STA-ResCNN模型优于其他基线模型,显著提高了精度和稳定性。研究结果表明,该预测系统有可能实现对长三角城市群城市进行可靠的多步PM2.5和PM10集中预测。
6.4. Sensitivity analysis of model input
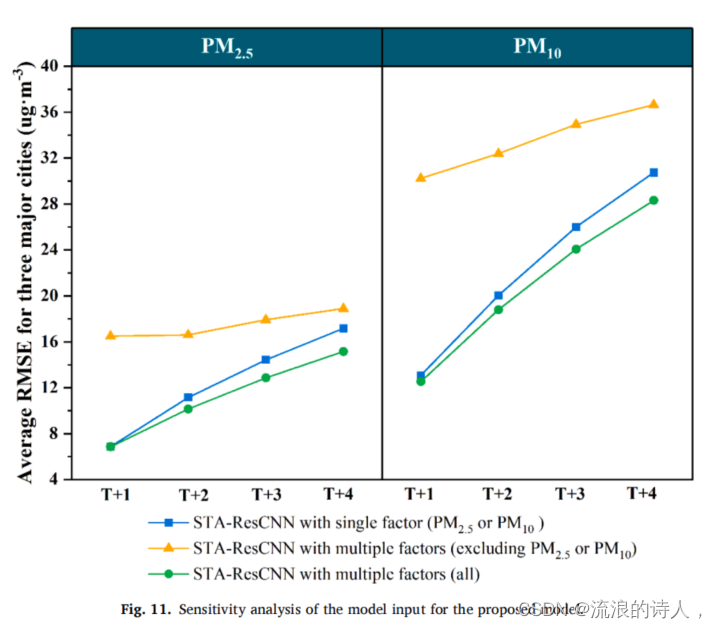 图11为所提出的STA-ResCNN算法的模型输入的灵敏度分析。对于具有单因子(PM2.5或PM10)的STA-ResCNN,只有时间PM2.5或PM10本身被视为模型输入。对于具有多种因素(不包括PM2.5或PM10)、各种时空空气污染和气象因素的STA-ResCNN,不包括PM2.5或PM10浓度本身,被用作模型输入。对于具有多因素(全部)的STA-ResCNN,采用所有时空因素作为模型输入。其中,具有多因素的STA-ResCNN(全部)的RMSE表现最好,其次是具有单因素(PM2.5或PM10)的STA-ResCNN,而具有多因素的STA-ResCNN(不包括PM2.5或PM10)的预测最差。单因素(PM2.5或PM10)的STA-ResCNN和多因素(不包括PM2.5或PM10)的STA-ResCNN的比较表明,时间序列预测任务不同于正常回归建模,目的是利用历史信息预测未来的状态。因此,预测目标本身,即本工作中的PM2.5或PM10浓度,对模型比其他变量更敏感。此外,STA-ResCNN在多因素(全部)下获得的最低RMSE再次证实了时空空气污染和气象因素的引入提高了模型的准确性。
图11为所提出的STA-ResCNN算法的模型输入的灵敏度分析。对于具有单因子(PM2.5或PM10)的STA-ResCNN,只有时间PM2.5或PM10本身被视为模型输入。对于具有多种因素(不包括PM2.5或PM10)、各种时空空气污染和气象因素的STA-ResCNN,不包括PM2.5或PM10浓度本身,被用作模型输入。对于具有多因素(全部)的STA-ResCNN,采用所有时空因素作为模型输入。其中,具有多因素的STA-ResCNN(全部)的RMSE表现最好,其次是具有单因素(PM2.5或PM10)的STA-ResCNN,而具有多因素的STA-ResCNN(不包括PM2.5或PM10)的预测最差。单因素(PM2.5或PM10)的STA-ResCNN和多因素(不包括PM2.5或PM10)的STA-ResCNN的比较表明,时间序列预测任务不同于正常回归建模,目的是利用历史信息预测未来的状态。因此,预测目标本身,即本工作中的PM2.5或PM10浓度,对模型比其他变量更敏感。此外,STA-ResCNN在多因素(全部)下获得的最低RMSE再次证实了时空空气污染和气象因素的引入提高了模型的准确性。
6.5. Computation time
为了进一步评价模型的效率,各模型在不同预测任务下的计算时间如表7所示。诚然,所提出的STA-ResCNN模型的计算时间比基线模型略长。然而,所提出的STA-ResCNN模型预测的改进足以平衡稍长的计算时间。此外,应用更先进的硬件可以进一步减少每个模型的计算时间,以加速预测,最大限度地降低增强的成本对计算的负面影响。
6.6. Application of the proposed forecasting system to the overall study area
在本节中,我们将我们提出的预测系统扩展到整个长三角城市群区域,以进一步验证其适用性和通用性。因此,我们进一步使用我们的STA-ResCNN模型对研究区域内的其余23个城市进行了独立的预测建模。随后,我们使用克里格法进行空间插值,以探索实际PM2.5和PM10浓度的分布以及它们在整个研究区域的预测误差分布。
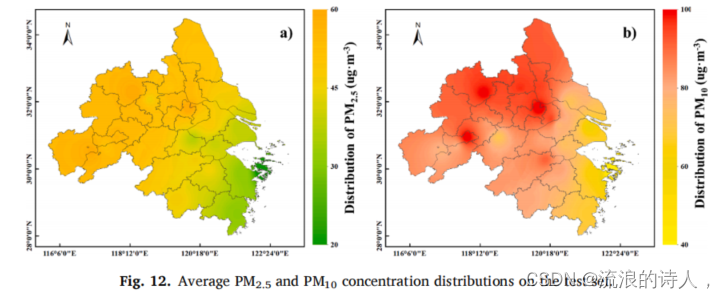 图12为测试集上PM2.5和PM10的平均浓度分布。研究区PM2.5和PM10浓度在西北部较高,在东南部较低。
图12为测试集上PM2.5和PM10的平均浓度分布。研究区PM2.5和PM10浓度在西北部较高,在东南部较低。
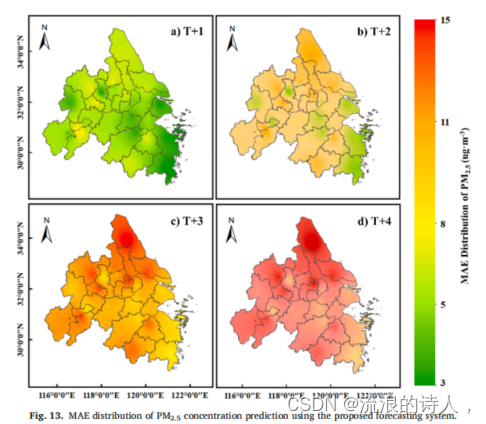
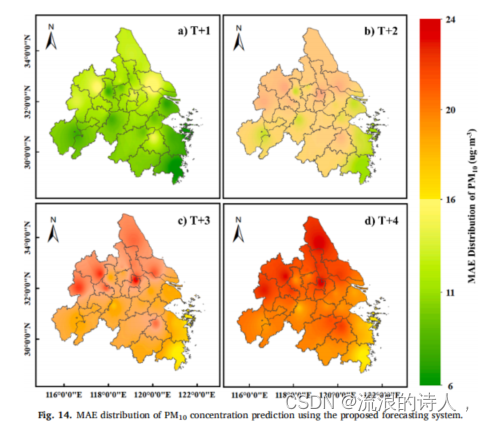 图13和图14所示的PM2.5和PM10的MAE分布是一致的,即西北偏高,西南偏低。这表明,对于盐城和南通等城市,相对较高的MAE值是由于其固有的较高的PM2.5和PM10浓度。而在东南部的舟山和宁波等城市的情况则相反,MAE结果相对较低。此外,与上述三个主要城市中PM2.5和PM10浓度的主要城市相似的城市(如嘉兴和苏州)与三个主要城市一样具有良好的预测性能。上述分析表明,该预测系统在整个区域内具有令人满意的性能。这进一步证明了该模型具有较强的适用性和可转移性;它是一个实用而有效的PM2.5和PM10浓度预测的稳健框架。
图13和图14所示的PM2.5和PM10的MAE分布是一致的,即西北偏高,西南偏低。这表明,对于盐城和南通等城市,相对较高的MAE值是由于其固有的较高的PM2.5和PM10浓度。而在东南部的舟山和宁波等城市的情况则相反,MAE结果相对较低。此外,与上述三个主要城市中PM2.5和PM10浓度的主要城市相似的城市(如嘉兴和苏州)与三个主要城市一样具有良好的预测性能。上述分析表明,该预测系统在整个区域内具有令人满意的性能。这进一步证明了该模型具有较强的适用性和可转移性;它是一个实用而有效的PM2.5和PM10浓度预测的稳健框架。
7. Conclusions
本文报道了一种基于深度学习算法的预测系统,用于PM2.5和PM10浓度预测。首先,应用城市间污染物的相关性分析,指导模型的时空输入的构建。然后,采用将时间和空间注意机制和卷积神经网络与残差学习相结合的混合STA-ResCNN模型作为核心预测系统,挖掘历史信息的时空依赖性。在长三角城市群的三个主要城市(即上海、南京和杭州)的实验结果表明,所提出的预测系统在准确性和统计检验方面都优于几种最先进的基线模型。与以往的深度学习模型,如LSTM和CNN相比,时间注意机制和空间注意机制允许模型捕获更重要的时空依赖信息,而残差学习则保证了模型不会退化。然后,该模型进一步成功地扩展到其他23个城市
尽管所开发的预测系统的优越性已得到充分验证,但进一步改进仍然不足。一种很有前途的方法是将来自不同城市或站点的数据划分为网格,以更有效地提取空间信息。更多的监测站和更长的空气质量和气象信息是可取的,因为更多的数据有望提高模型的精度。此外,我们计划将相关的政策信息数字化并整合到模型中,这可能是有益的。

















 899
899

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









