







目录
理解源IP地址和目的IP地址
理解源IP地址和目的IP地址可以通过类比日常通信的方式来解释。想象一下寄信的场景,这里有两个参与者:寄件人(源)和收件人(目的)。
源IP地址: 寄件人的地址就好比网络通信中的源IP地址。这个地址标识了数据包的出发地,即发送数据包的设备。就像在寄信时写明寄件人地址,网络数据包中的源IP地址用于标识数据的来源。
目的IP地址: 收件人的地址就好比网络通信中的目的IP地址。这个地址标识了数据包的目的地,即接收数据包的设备。就像在寄信时写明收件人地址,网络数据包中的目的IP地址用于指示数据的最终目标。
通信过程的类比:
- 寄信过程: 假设你要寄一封信给朋友。你写上你自己的地址作为寄件人(源),然后写上朋友的地址作为收件人(目的)。
- 网络通信过程: 类比到网络通信,设备A要发送数据给设备B。设备A的IP地址作为源IP地址,设备B的IP地址作为目的IP地址。
- 邮递员的角色: 在邮寄中,邮递员会根据信封上的地址,将信件从寄件人送到收件人的地址。在网络中,这个功能由路由器扮演,它根据源和目的IP地址,将数据包从一个网络传递到另一个网络。
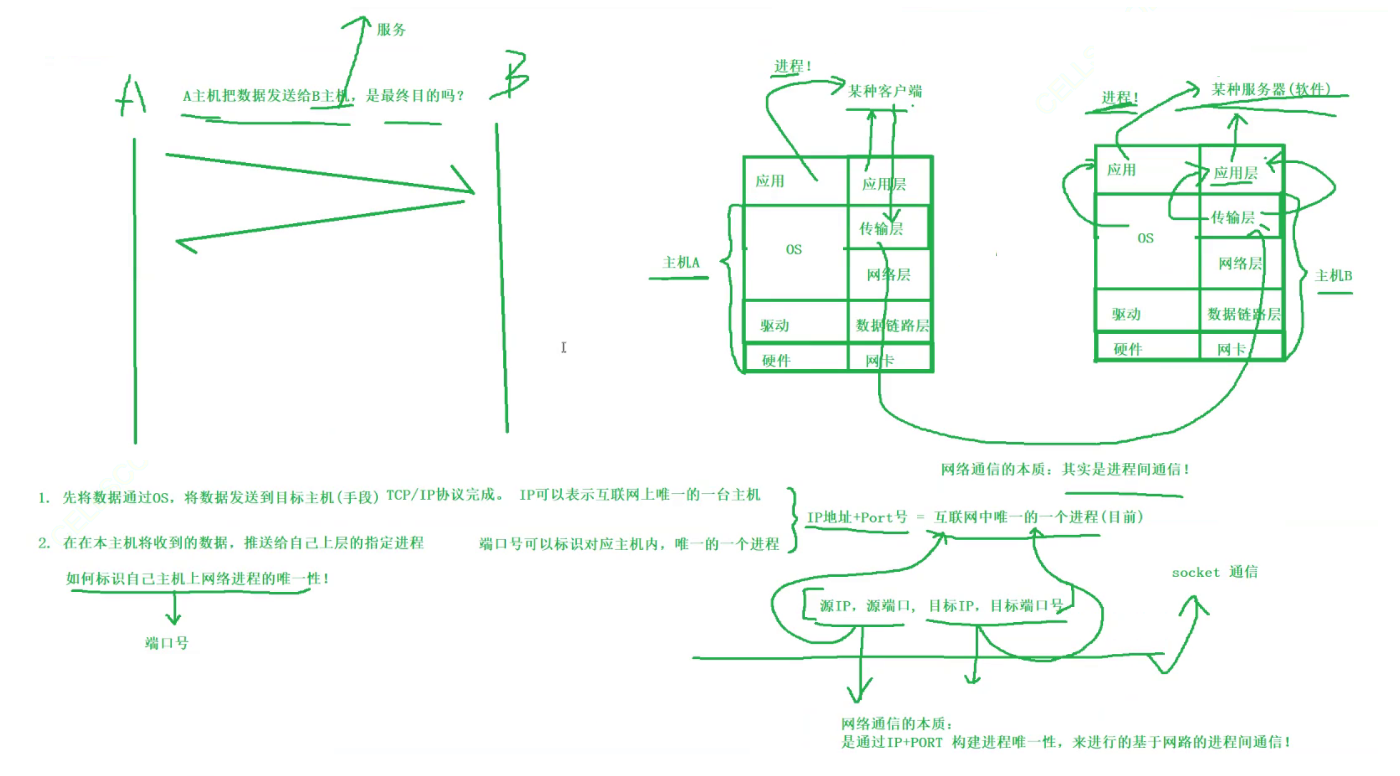
认识端口号
- 端口号是传输层协议的内容: 端口号属于传输层协议的范畴,主要用于在主机之间的进程之间建立通信。常见的传输层协议有TCP(Transmission Control Protocol)和UDP(User Datagram Protocol),它们都使用端口号来区分不同的应用程序或服务。
- 端口号是一个2字节16位的整数:端口号是一个16位的整数,范围从0到65535。这样的范围允许大量的端口号,使得在一个主机上可以同时运行多个应用程序,每个应用程序使用不同的端口号。
- 端口号用来标识一个网络进程:端口号的主要作用之一是标识正在运行的应用程序或服务的进程。这样,当数据到达主机时,操作系统能够根据端口号将数据传递给正确的进程。
- IP地址 + 端口号能够标识网络上的某一台主机的某一个进程:组合使用IP地址和端口号能够唯一地标识网络上的主机上的一个进程。这种组合提供了端到端的通信标识。
- 一个端口号只能被一个进程占用:通常情况下,一个端口号只能被一个进程占用。如果一个进程已经绑定到某个端口号,其他进程就不能再使用相同的端口号。这确保了端口的唯一性,避免了端口冲突。
综上所述,端口号在网络通信中扮演着重要的角色,通过它们,不同的应用程序能够在同一主机上并发运行,并通过网络进行通信。
理解源端口号和目的端口号
源端口号和目的端口号是在网络通信中用于标识发送和接收进程的端口。这是在传输层(通常是TCP或UDP协议)中使用的概念。
- 源端口号(Source Port):
-
- 源端口号是指发送数据的进程所使用的端口号。
- 当一个主机通过网络发送数据时,它的操作系统为此数据分配一个源端口号。这个源端口号有助于确定哪个应用或进程发送了这些数据。
- 目的端口号(Destination Port):
-
- 目的端口号是指接收数据的进程所使用的端口号。
- 在网络通信中,接收方的操作系统会检查到达的数据包的目的端口号,以确定应该将这些数据传递给哪个应用或进程。
为什么需要端口号? 在一个主机上可能同时运行多个应用程序,每个应用程序都需要独立地发送和接收数据。端口号使得数据包能够被正确地路由到相应的应用程序,实现多个应用程序之间的并发通信。
认识TCP协议
传输控制协议(TCP,Transmission Control Protocol)是一种面向连接的、可靠的网络传输协议,位于OSI模型的传输层。TCP确保数据的可靠性和顺序传输,它通过将数据划分为小的数据段,并使用序号和确认号来跟踪数据的传输和接收。
以下是TCP协议的一些关键特点:
- 面向连接: 在进行数据传输之前,TCP会在发送和接收方之间建立一个连接。连接的建立是通过三次握手(three-way handshake)来完成的,包括客户端向服务器发送连接请求,服务器回应连接请求,最后客户端再次回应确认连接。
- 可靠性: TCP通过使用序号和确认号来确保数据的可靠传输。每个数据段都有一个唯一的序号,接收方通过确认号来指示下一个期望接收的数据段。如果发送方未收到接收方的确认,它会重新发送数据。
- 流控制: TCP使用滑动窗口机制来实现流控制。滑动窗口定义了发送方可以发送但尚未收到确认的数据量。接收方可以通过调整窗口大小来控制发送方的发送速率,以防止数据溢出或过载。
- 拥塞控制: TCP通过拥塞窗口和拥塞避免算法来处理网络拥塞。当网络出现拥塞时,TCP会调整发送速率以减轻网络负载,从而保证网络的稳定性。
- 面向字节流: TCP是面向字节流的,而不是面向消息的。它将数据视为一个连续的字节流,没有固定的消息边界,因此需要上层应用来解释和分割消息。
- 全双工通信: TCP连接是全双工的,允许数据在两个方向上同时传输。这使得双方可以独立地发送和接收数据,提高了通信效率。
- 复杂性: 相对于用户数据报协议(UDP),TCP协议的实现较为复杂。它需要维护连接状态、序号、确认号等信息,以确保可靠性和顺序性。
TCP广泛用于各种应用,特别是对于需要可靠数据传输和顺序传输的应用,如网页浏览、文件传输、电子邮件等
认识UDP协议
UDP(User Datagram Protocol)是一种无连接的、简单的面向数据报的传输协议,位于OSI模型的传输层。相对于TCP,UDP更注重传输效率而不是可靠性和顺序传输。
以下是UDP协议的一些关键特点:
- 无连接性: UDP是无连接的,不需要在发送数据前建立连接。每个UDP数据包(数据报)独立存在,发送端和接收端之间没有预先建立的连接。这使得它在速度上比TCP更快,但也意味着它不提供像TCP那样的错误检查和纠正机制。
- 面向数据报: UDP以数据报的形式发送数据,每个数据报都是一个独立的实体。这意味着它不会像TCP那样将数据流分割成小的数据段,而是将数据完整地打包成数据报发送。
- 不可靠性: UDP不提供可靠性保证,它不会对数据传输进行确认或重传丢失的数据包。因此,数据包可能会因网络拥塞、丢包或错误而丢失,接收顺序也不受保证。
- 高效性: 由于UDP不需要像TCP那样维护连接状态、序号和确认号等信息,因此它更加简单和高效。这使得它在实时应用中很受欢迎,如音频/视频流传输、在线游戏等,因为它可以提供更低的延迟。
- 不支持拥塞控制: UDP不具备TCP中的拥塞控制机制。这意味着当网络出现拥塞时,UDP不会调整发送速率或做出其他响应来缓解拥塞情况。
- 应用场景: UDP适用于一些对实时性要求较高、对数据传输延迟要求较低的应用场景,如音频/视频传输、实时游戏、DNS查询等。在这些情况下,速度和即时性可能比数据完整性和可靠性更为重要。
总体而言,UDP和TCP是两种不同的传输协议,各自适用于不同的应用场景。UDP强调快速传输和实时性,而牺牲了可靠性和顺序性;而TCP则更注重数据传输的可靠性、顺序性和错误处理。选择使用UDP还是TCP取决于具体的应用需求。
网络字节序
我们已经知道,内存中的多字节数据相对于内存地址有大端和小端之分, 磁盘文件中的多字节数据相对于文件中的偏移地址也有大端小端之分, 网络数据流同样有大端小端之分. 那么如何定义网络数据流的地址呢?
发送主机通常将发送缓冲区中的数据按内存地址从低到高的顺序发出;
接收主机把从网络上接到的字节依次保存在接收缓冲区中,也是按内存地址从低到高的顺序保存;
因此,网络数据流的地址应这样规定:先发出的数据是低地址,后发出的数据是高地址.
TCP/IP协议规定,网络数据流应采用大端字节序,即低地址高字节数。
不管这台主机是大端机还是小端机, 都会按照这个TCP/IP规定的网络字节序来发送/接收数据;
如果当前发送主机是小端, 就需要先将数据转成大端; 否则就忽略, 直接发送即可
- 网络字节序: 也称为大端字节序,是一种规定,要求在网络数据传输中使用固定的字节序。在网络字节序中,数据的高位字节存储在低地址,而低位字节存储在高地址。这确保了不同架构的计算机在进行网络通信时能够正确解释数据。
- 发送主机和接收主机: 在网络通信中,存在发送方和接收方。发送主机将数据从内存发送到网络,而接收主机将从网络接收的数据存储到内存。这两个过程都需要按照网络字节序进行操作,以确保数据的正确传输和解释。
- 内存中的字节序: 计算机的内存中存储数据的方式可能是大端(高位字节存储在低地址)或小端(低位字节存储在低地址)。这与网络字节序有关,因为在进行网络通信时,必须按照网络字节序的规定来发送和接收数据,以免导致字节序混淆。
- TCP/IP协议规定: TCP/IP协议族规定了网络字节序应采用大端字节序。这是为了保持在不同计算机体系结构上的一致性。即使在小端机器上,发送和接收的数据也必须按照大端字节序进行处理,以确保与其他系统的兼容性。
- 主机的端序转换: 如果当前发送主机的体系结构是小端,而网络字节序要求大端字节序,那么在发送数据之前,主机必须将数据进行字节序的转换。这确保了数据在网络上传输时采用了正确的字节序。
总体而言,网络字节序的规范是为了在不同体系结构的计算机之间实现可靠的数据通信,而TCP/IP协议族对网络字节序采用大端字节序的规定是为了提供一致性和互操作性。
什么是主机字节序?什么是网络字节序?
主机字节序和网络字节序是两种不同的字节序(即字节的存储顺序)规定,用于确保在不同计算机体系结构之间进行数据交换时的一致性。
- 主机字节序(序列)(Host Byte Order):
-
- 主机字节序是指在特定计算机体系结构(主机)中,多字节数据在内存中的存储顺序。
- 对于一个多字节数据类型(如整数或浮点数),主机字节序规定了这些字节在内存中的排列顺序。具体而言,是高位字节(Most Significant Byte,MSB)在低地址,低位字节(Least Significant Byte,LSB)在高地址(大端字节序)还是高位字节在高地址,低位字节在低地址(小端字节序)。
- 不同的计算机体系结构可能采用不同的主机字节序。这与你自己的电脑有关,因为不同的计算机体系结构可能有不同的主机字节序。例如,x86 架构的计算机通常采用小端字节序,而某些其他体系结构可能采用大端字节序。
- 网络字节序(序列)(Network Byte Order):
-
- 网络字节序是一种规定,用于在不同计算机之间进行网络通信时,确保数据传输的一致性。
- 标准的网络字节序是大端字节序(Big-Endian),即高位字节在低地址,低位字节在高地址。
- TCP/IP协议族规定了网络字节序应该采用大端字节序,以确保在网络上传输的数据能够被正确解释。
- 在进行网络通信时,发送方需要按照网络字节序将数据打包,而接收方需要按照网络字节序将数据解包。
在进行网络通信时,如果发送方和接收方的主机字节序不同,就需要进行字节序的转换,以确保数据在传输过程中被正确解释。这种转换通常是由网络库或操作系统提供的函数完成的。所以主机字节序指的是自己电脑对数据存储的方式,网络字节序指的是对接受或者发送的数据的存储方式。
为使网络程序具有可移植性,使同样的C代码在大端和小端计算机上编译后都能正常运行,可以调用以下库函数做网络字节序和主机字节序的转换

这些函数名很好记,h开头的表示host(主机),n开头的表示network(网络),l表示32位长整数,s表示16位短整数。
例如htonl表示将32位的长整数从主机字节序转换为网络字节序,例如将IP地址转换后准备发送。
如果主机是小端字节序,这些函数将参数做相应的大小端转换然后返回 ;
如果主机是大端字节序,这些 函数不做转换,将参数原封不动地返回。
socket(套接字)编程接口
socket 常见API
// 创建 socket 文件描述符 (TCP/UDP, 客户端 + 服务器)
int socket(int domain, int type, int protocol);
// 绑定端口号 (TCP/UDP, 服务器)
int bind(int socket, const struct sockaddr *address,
socklen_t address_len);
// 开始监听socket (TCP, 服务器)
int listen(int socket, int backlog);
// 接收请求 (TCP, 服务器)
int accept(int socket, struct sockaddr* address,
socklen_t* address_len);
// 建立连接 (TCP, 客户端)
int connect(int sockfd, const struct sockaddr *addr,
socklen_t addrlen);在"socket API"中,"API"是指"Application Programming Interface",即应用程序编程接口。它表示一组定义了函数、协议、数据结构和常量等编程接口的规范,用于在应用程序和操作系统之间进行通信和交互。
Socket API 是一种提供套接字编程接口的 API,这些接口定义了在程序中如何创建、配置、连接、发送和接收数据等网络操作。Socket API允许开发者使用编程语言中的函数、类或方法来执行与网络相关的任务,而无需深入了解底层网络协议的细节。
sockaddr结构
Socket API 是一个抽象的网络编程接口,允许开发人员使用统一的编程接口来处理各种网络通信,包括 IPv4、IPv6 以及 Unix 域套接字(UNIX Domain Socket)等。
不同的网络协议有着各自不同的地址格式。这些地址格式对应着不同的套接字地址结构体,例如:
- IPv4 地址格式:在IPv4通信中,使用 sockaddr_in 结构体表示地址信息。
- IPv6 地址格式:IPv6则使用 sockaddr_in6 结构体来表示地址信息。
- Unix 域套接字地址格式:在Unix域套接字通信中,使用 sockaddr_un 结构体来表示地址信息。
这些不同的地址结构体都允许在程序中使用统一的 sockaddr 结构体进行通用性的传递(也就是说sockaddr_in 和sockaddr_un 都可以通过 sockaddr 结构体和类型转换,用来传递给sockaddr)。sockaddr 结构体是一个通用的套接字地址结构体,用于在各种情况下传递套接字地址信息。为了实现这种通用性,Socket API 提供了类型转换功能,允许开发者在不同的地址结构体之间进行转换。
这样,通过 sockaddr 结构体和类型转换,开发人员可以编写更加通用、可移植的网络应用程序,而无需在不同的网络协议之间切换时修改大量的代码。Socket API 提供了一种抽象层,使得程序员能够更加方便地处理不同协议的网络通信,提高了代码的可移植性和复用性。
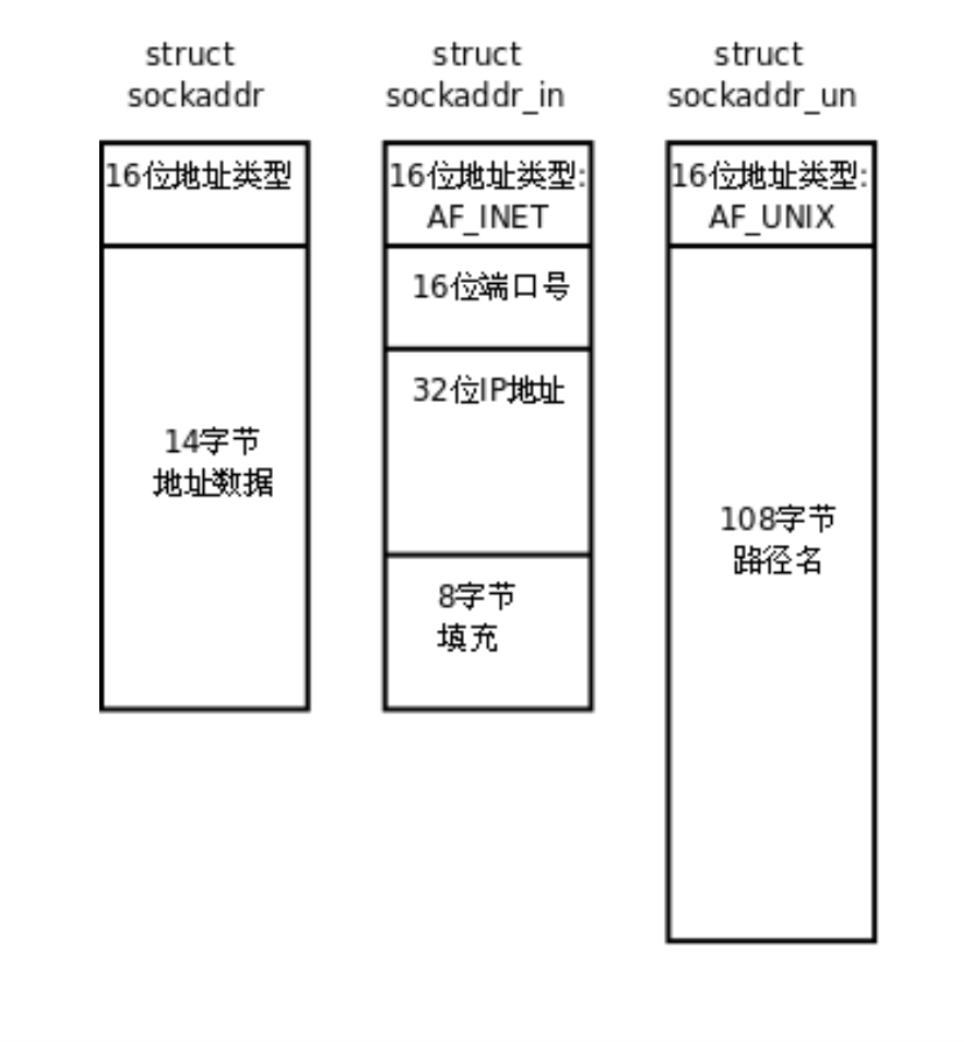
注:sockaddr_in 和 sockaddr_un 是在网络编程中常用的两个结构体,用于表示套接字地址。它们分别用于处理基于网络通信的套接字(如IPv4套接字)和基于本地通信的套接字(Unix域套接字)。
sockaddr_in 结构体主要设计用于表示 IPv4 地址信息,因此在通常情况下,它主要用于网络通信而不是本地通信。然而,如果你愿意,你可以在本地环境中使用 sockaddr_in 进行通信,但这并不是通常的做法。
在 C 语言中,struct sockaddr 是一个通用的套接字地址结构体,它被用来表示各种类型的套接字地址,包括 IPv4、IPv6 以及 Unix 域套接字。这个结构体的定义如下:
struct sockaddr {
unsigned short sa_family; // address family, AF_xxx
char sa_data[14]; // 14 bytes of protocol address
};其中,sa_family 字段表示地址的类型,可以是 AF_INET 表示 IPv4,AF_INET6 表示 IPv6,而对于 Unix 域套接字,则会使用不同的地址家族。sa_data 则是用来存储具体的地址信息。
IPv4和IPv6的地址格式定义在netinet/in.h中,IPv4地址用sockaddr_in结构体表示,包括16位地址类型, 16
位端口号和32位IP地址。
IPv4、IPv6地址类型分别定义为常数AF_INET、AF_INET6. 这样,只要取得某种sockaddr结构体的首地址,
不需要知道具体是哪种类型的sockaddr结构体,就可以根据地址类型字段确定结构体中的内容。
socket API可以都用struct sockaddr *类型表示, 在使用的时候需要强制转化成sockaddr_in; 这样的好
处是程序的通用性, 可以接收IPv4, IPv6, 以及UNIX Domain Socket各种类型的sockaddr结构体指针做为
参数;
例如,如果你有一个 struct sockaddr * 指针,你可以这样检查地址类型并转换为对应的结构体:
struct sockaddr *addr; // 指向套接字地址的指针
// 检查地址类型
if (addr->sa_family == AF_INET) {
// IPv4 地址
struct sockaddr_in *ipv4_addr = (struct sockaddr_in *)addr;
// 在这里可以使用 ipv4_addr 来访问 IPv4 地址的具体信息
} else if (addr->sa_family == AF_INET6) {
// IPv6 地址
struct sockaddr_in6 *ipv6_addr = (struct sockaddr_in6 *)addr;
// 在这里可以使用 ipv6_addr 来访问 IPv6 地址的具体信息
} else {
// 其他类型的地址处理
}这种通用性使得你的程序更加灵活,可以适应不同类型的网络地址而无需修改大量代码。这也是 Socket API 设计的一个重要特点,提高了代码的可移植性和通用性。
以下是 sockaddr_in 的原型定义:
struct sockaddr_in {
sa_family_t sin_family; // 地址族,一般为 AF_INET
in_port_t sin_port; // 端口号,使用网络字节序表示
struct in_addr sin_addr; // IPv4 地址
char sin_zero[8]; // 填充字段,通常设置为 0
};在该结构体中,包含了以下几个成员:
- sin_family:表示地址族,是一个 sa_family_t 类型的值,一般设置为 AF_INET,表示 IPv4 地址族。
- sin_port:表示端口号,是一个 in_port_t 类型的值,用于表示端口号,一般使用网络字节序(大端序)表示,需要使用 htons() 函数将主机字节序转换为网络字节序。
- sin_addr:表示 IPv4 地址,是一个 struct in_addr 类型的结构体,用于表示 IPv4 地址。
- sin_zero:用于填充,一般设置为 0。在 IPv4 中,sockaddr_in 结构体的大小为 16 字节,为了兼容性,添加了这个填充字段。
需要注意的是,sockaddr_in 结构体是用于描述 IPv4 地址和端口号的,而不是实际的 IP 地址和端口号。
例:
因为使用的 bzero 进行了初始化为0,所以sin_zero一并被设置为0了。
注:sockaddr_in 是 Socket(套接字) Address(地址) INternet(互联网) 的缩写。
sockaddr_un是用于表示UNIX域套接字地址的结构体。以下是sockaddr_un的原型定义:
#include <sys/un.h>
struct sockaddr_un {
sa_family_t sun_family; // 地址族,一般为 AF_UNIX
char sun_path[108]; // 路径名
};在该结构体中,包含了以下两个成员:
- sun_family:表示地址族,是一个 sa_family_t 类型的值,一般设置为 AF_UNIX,表示UNIX域套接字。
- sun_path:表示路径名,是一个字符数组,用于存放UNIX套接字的路径名。路径名的最大长度通常为108个字符。
需要注意的是,UNIX域套接字不需要端口号,而是使用文件系统中的路径名来进行通信。因此,在使用sockaddr_un结构体表示UNIX域套接字地址时,需要指定sun_family为AF_UNIX,并将路径名存放在sun_path成员中。
socket() 函数
socket() 函数是一个系统调用,在Socket编程中用于创建新的套接字的函数。这个函数通常由操作系统提供,并且在不同的编程语言中可能有一些细微的差异。以下是通常情况下,在类Unix系统上(包括Linux和macOS)使用C语言进行Socket编程时的基本形式:
#include <sys/types.h>
#include <sys/socket.h>
int socket(int domain, int type, int protocol);其中:
- domain 参数指定套接字的地址家族(Address Family),常见的有 AF_INET(IPv4)和 AF_INET6(IPv6)。
- type 参数指定套接字的类型,常见的有 SOCK_STREAM(流套接字,用于TCP)和 SOCK_DGRAM(数据报套接字,用于UDP)。
- protocol 参数通常设置为0,表示根据 domain 和 type 的取值选择默认的协议。对于 AF_INET 和 AF_INET6,SOCK_STREAM,通常是 IPPROTO_TCP;对于 SOCK_DGRAM,通常是 IPPROTO_UDP。
例如,在创建一个基于IPv4和UDP的套接字时,可以使用以下代码:
#include <sys/types.h>
#include <sys/socket.h>
int main() {
int sockfd;
sockfd = socket(AF_INET, SOCK_DGRAM, 0);
if (sockfd == -1) {
// 处理套接字创建失败的情况
}
// 其他操作,如绑定、监听、连接等
return 0;
}需要注意的是,socket() 函数只是创建了一个套接字,还需要后续的操作(如绑定、监听、连接等)才能进行实际的网络通信。这个函数返回一个整数类型的套接字 文件描述符,用于后续对该套接字的引用。如果发生错误,它返回 -1,此时应该根据具体情况处理错误。
注:尽管套接字在某种程度上它的本质被视为文件,但它们与普通文件还是有很大的区别。普通文件通常存储在磁盘上,但套接字提供了一种用于网络通信的机制。套接字提供了客户端和服务器之间的连接点,使得数据可以通过网络传输到另一个套接字,而不是被存储在磁盘上。
bind() 函数
bind函数是一个系统调用,在网络编程中,bind() 函数用于将一个套接字(Socket)绑定到一个特定的地址和端口上。它是 Socket API 提供的函数之一,通过它可以设置套接字的本地地址和端口号,从而使套接字能够与特定的网络地址进行关联。
注:在网络编程中,"网络地址"指的是用于标识网络上主机(计算机)或者网络设备的唯一标识。网络地址由 IP 地址和端口号组成。
IP 地址是一个由数字和点分隔符组成的标识符,用于标识网络上的主机。IP 地址分为 IPv4 地址(例如:"192.0.2.1")。IP 地址用于在网络中唯一标识一个主机,类似于现实生活中的街道地址。
换句话说,网络地址是用于标识网络上的主机或设备的唯一标识,它由 IP 地址和端口号组成。通过使用 bind() 函数,我们可以将套接字与指定的网络地址关联起来,使得套接字可以与特定的主机(通过 IP 地址)和应用程序(通过端口号)进行通信。
bind() 函数的原型如下所示:
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);参数说明:
- sockfd:要绑定的套接字的文件描述符(socket descriptor)。
- addr:指向要绑定的本地地址信息的指针,通常是 struct sockaddr 类型的指针(可以转换为 struct sockaddr_in 或 struct sockaddr_in6 或 sockaddr_un)。
- addrlen:本地地址信息结构体的大小。
bind() 函数在成功时返回 0,它主要完成以下两个任务:
- 将套接字与一个特定的本地地址进行绑定,在网络编程中通常是将服务端的套接字与一个固定的 IP 地址和端口号绑定。
- 使得系统内核能够通过这个套接字与指定的地址和端口进行网络通信。
下面是 bind() 函数的返回值含义:
- 如果绑定操作成功,bind() 函数返回 0。这意味着套接字成功地与指定的地址和端口进行了绑定。
- 如果绑定操作失败,bind() 函数返回 -1,并设置适当的错误码(通过全局变量 errno 获取)。这意味着绑定操作未能成功完成。
当 bind() 函数失败时,常见的错误码可能包括以下一些:
- EACCES:权限不足。执行绑定操作的进程没有足够的权限来绑定指定的地址和端口。
- EADDRINUSE:地址或端口已经被占用。指定的地址和端口已被其他套接字或进程占用,无法再次绑定。
- EINVAL:无效的参数。绑定传递了一个无效的参数,如无效的套接字描述符或无效的地址长度。
- EFAULT:无效的指针。传递给 bind() 的地址参数是一个无效的指针。
在调用 bind() 函数之前,通常需要初始化地址结构体,并将要绑定的本地地址和端口信息填充到结构体中。然后,通过 bind() 函数将套接字与该地址进行绑定。
示例代码(C语言):
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
int main() {
// 创建套接字
int sockfd = socket(AF_INET, SOCK_STREAM, 0);
// 初始化服务器地址
struct sockaddr_in server_addr;
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(1234);
server_addr.sin_addr.s_addr = INADDR_ANY;
// 绑定套接字与地址
int bind_result = bind(sockfd, (struct sockaddr *)&server_addr, sizeof(server_addr));
if(bind_result < 0) {
perror("bind failed");
return -1;
}
// ...
// 其他处理逻辑
// ...
return 0;
}上述示例代码中,通过 socket() 创建了一个套接字,然后初始化了一个 sockaddr_in 结构体描述了服务器的地址信息,最后通过 bind() 函数将套接字与该地址绑定在一起。
这样,服务器套接字就绑定了指定的本地地址和端口,它可以使用这个地址和端口在网络上监听并接收客户端的连接请求。
主机序列转换成为网络序列函数
端口转换函数
htons() 函数是一个用于主机字节序(host byte order)和网络字节序(network byte order)之间进行转换的函数,其中网络字节序是大端字节序(big-endian)。
在计算机网络编程中,经常需要将数据从主机字节序转换为网络字节序,或者反之,以便正确地在网络上传输数据。这种字节序转换是因为不同的计算机体系结构使用不同的字节序,而网络协议通常要求使用一种特定的字节序。
函数原型如下:
#include <arpa/inet.h>
uint16_t htons(uint16_t hostshort);- hostshort:主机字节序的16位整数。
返回值:返回网络字节序的16位整数。
示例:
#include <stdio.h>
#include <arpa/inet.h>
int main() {
uint16_t host_short = 0x1234; // 4660 in decimal
// Convert from host to network byte order
uint16_t net_short = htons(host_short);
printf("Host short: 0x%x\n", host_short);
printf("Network short: 0x%x\n", net_short);
return 0;
}在这个例子中,htons 函数将主机字节序的 16 位整数转换为网络字节序,然后打印出两者的值。需要注意的是,这样的字节序转换通常在网络编程中处理套接字时用到,以确保正确的数据传输。
地址转换函数
这里只介绍基于IPv4的socket网络编程,sockaddr_in中的成员struct in_addr sin_addr表示32位 的IP 地址但是我们通常用点分十进制的字符串表示IP 地址,以下函数可以在字符串表示 和in_addr表示之间转换。
注:简单来说地址转换函数指的是把字符串风格的IP地址转换成4字节整形的IP地址 或者 把4字节整形的IP地址转换成字符串风格的IP地址
字符串转in_addr类型的函数:

in_addr类型转字符串的函数:

其中inet_pton和inet_ntop不仅可以转换IPv4的in_addr,还可以转换IPv6的in6_addr,因此函数接口是void *addrptr。
代码示例:
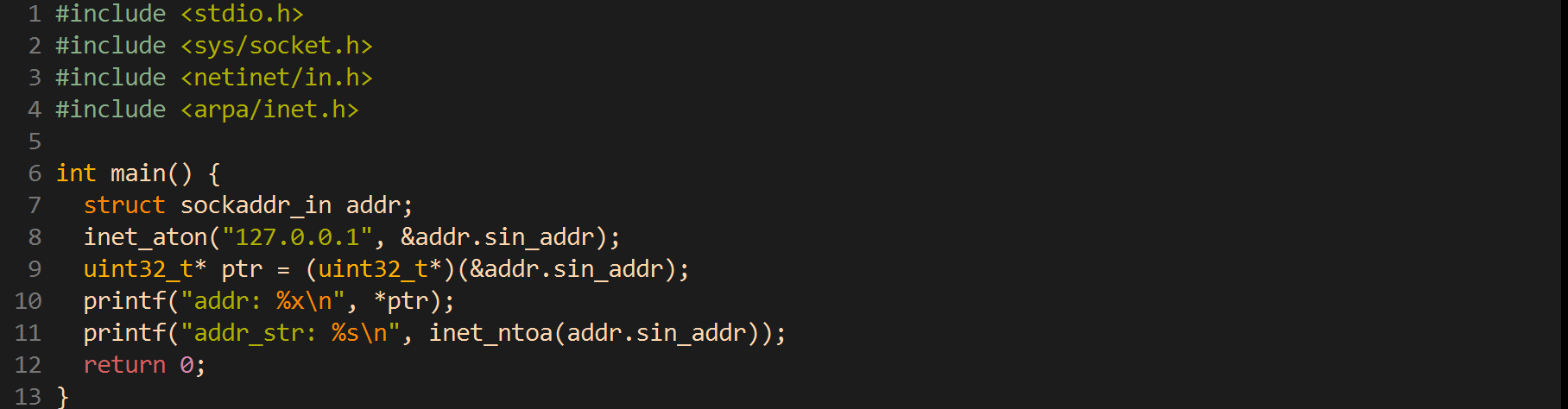
关于inet_ntoa
inet_ntoa这个函数返回了一个char*, 很显然是这个函数自己在内部为我们申请了一块内存来保存ip的结果. 那么是否需要调用者手动释放呢?

man手册上说, inet_ntoa函数, 是把这个返回结果放到了静态存储区. 这个时候不需要我们手动进行释放,那么问题来了, 如果我们调用多次这个函数, 会有什么样的效果呢? 参见如下代码:
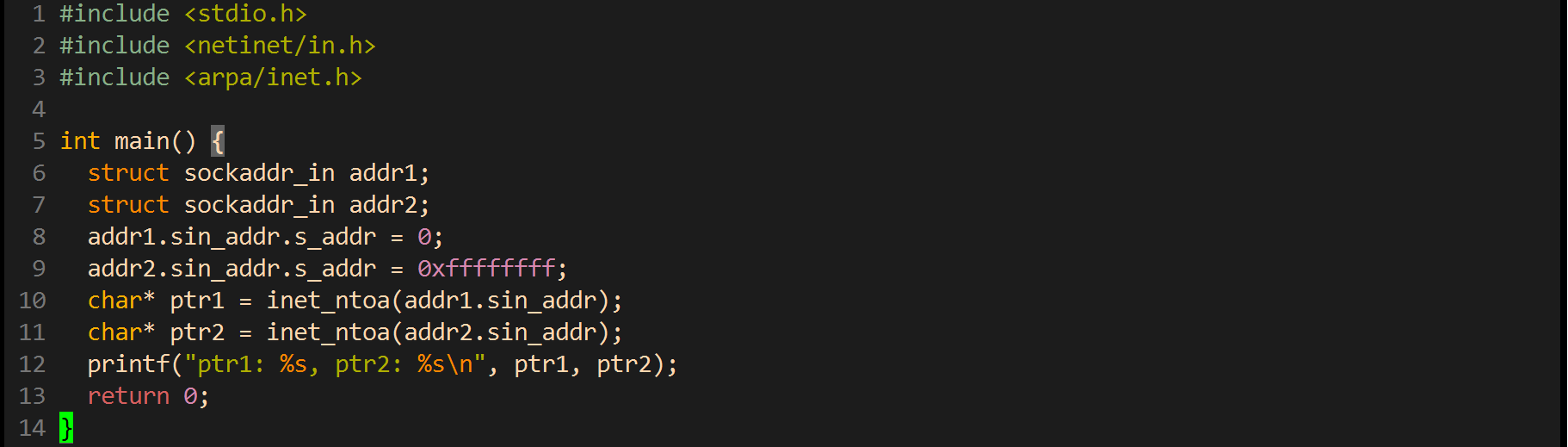
运行结果如下:

因为inet_ntoa把结果放到自己内部的一个静态存储区, 这样第二次调用时的结果会覆盖掉上一次的结果。
思考: 如果有多个线程调用 inet_ntoa, 是否会出现异常情况呢? 在APUE中, 明确提出inet_ntoa不是线程安全的函数; 但是在centos7上测试, 并没有出现问题, 可能内部的实现加了互斥锁; 可以自己写程序验证一下在自己的机器上inet_ntoa是否会出现多线程的问题; 在多线程环境下, 推荐使用inet_ntop, 这个函数由调用者提供一个缓冲区保存结果, 可以规避线程安全问题。
inet_ntoa 函数在早期的实现中通常不是线程安全的,因为它使用了一个静态缓冲区来保存转换后的字符串,而该缓冲区是被所有调用线程共享的。因此,在多线程环境下,多个线程同时调用 inet_ntoa 可能会导致数据混乱或覆盖,因为它们会共享相同的静态缓冲区。
在实际使用中,一些系统的库实现可能对 inet_ntoa 进行了改进,引入了一些线程安全的机制,例如使用互斥锁(mutex)来保护静态缓冲区。因此,你在某些系统上的测试中可能没有观察到问题。
然而,这种依赖于实现的行为是不可靠的,因为不同的系统和库版本可能有不同的实现方式。为了确保在多线程环境下安全使用IP地址转换,推荐使用更现代的函数 inet_ntop,该函数不使用静态缓冲区,而是由调用者提供一个缓冲区来保存结果,从而避免了线程安全问题。这种做法更加可靠,并且符合现代编程的最佳实践。
示例使用 inet_ntop 的代码如下:
#include <stdio.h>
#include <arpa/inet.h>
int main() {
struct in_addr addr;
inet_aton("192.168.1.1", &addr);
char buffer[INET_ADDRSTRLEN]; // Assuming INET_ADDRSTRLEN is large enough
const char *result = inet_ntop(AF_INET, &addr, buffer, INET_ADDRSTRLEN);
if (result != NULL) {
printf("IP address: %s\n", buffer);
} else {
perror("inet_ntop");
}
return 0;
}这里使用了 inet_ntop 函数,它更安全,因为它不使用静态缓冲区,而是使用由调用者提供的缓冲区。
recvfrom() 函数
recvfrom()函数通常用于UDP套接字。recvfrom() 函数是一个系统调用,用于从指定的套接字 sockfd 接收数据。它的函数原型如下:
ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags,
struct sockaddr *src_addr, socklen_t *addrlen);参数说明:
- sockfd:要接收数据的套接字文件描述符。
- buf:一个指向接收数据缓冲区的指针,用于存储接收到的数据。
- len:指定接收缓冲区的大小,即能够接收的最大字节数。
- flags:是接收操作的标志,通常设置为0。可选参数,用于指定接收操作的特殊选项,如下:
-
- MSG_DONTWAIT:非阻塞接收,如果没有数据可接收,则立即返回。
- MSG_WAITALL:等待直到接收到指定大小的数据。
- 其他标志根据具体需求而定,可参考相关文档。
- src_addr: 是一个指向 struct sockaddr 结构体的指针,用于存储发送端的地址信息(ip + port)。
- addrlen:一个指向存储着 src_addr 结构体大小的指针。
返回值:
- 如果成功接收数据,则返回接收到的字节数。
- 如果出现错误,返回值为 -1,并设置相应的错误代码。
注意事项:
- recvfrom() 函数是一个阻塞调用,即在没有数据可接收时会一直等待,直到有数据到达才返回,除非使用 MSG_DONTWAIT 标志进行非阻塞接收。
- 在使用 recvfrom() 函数之前,需要先创建套接字并进行绑定操作,以便能够接收到远程主机发送过来的数据。
- 在 UDP 套接字中使用 recvfrom() 可以获取发送方的网络地址信息,以便进行回复或其他操作。
请注意,以上是基于 C 语言的函数原型和参数说明,具体的使用方式还需要根据具体的编程语言和套接字库来确定。
使用 recvfrom() 的一个简单例子如下:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <arpa/inet.h>
int main() {
int sockfd;
struct sockaddr_in server_addr, client_addr;
socklen_t client_len = sizeof(client_addr);
char buffer[1024];
// 创建UDP套接字
if ((sockfd = socket(AF_INET, SOCK_DGRAM, 0)) == -1) {
perror("socket");
exit(EXIT_FAILURE);
}
// 设置服务器地址
memset(&server_addr, 0, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_addr.s_addr = INADDR_ANY;
server_addr.sin_port = htons(8080);
// 绑定套接字到地址和端口
if (bind(sockfd, (struct sockaddr *)&server_addr, sizeof(server_addr)) == -1) {
perror("bind");
exit(EXIT_FAILURE);
}
// 接收数据
ssize_t recv_bytes = recvfrom(sockfd, buffer, sizeof(buffer), 0,
(struct sockaddr *)&client_addr, &client_len);
if (recv_bytes == -1) {
perror("recvfrom");
exit(EXIT_FAILURE);
}
// 打印接收到的数据
printf("Received data from %s:%d\n", inet_ntoa(client_addr.sin_addr), ntohs(client_addr.sin_port));
printf("Data: %.*s\n", (int)recv_bytes, buffer);
// 关闭套接字
close(sockfd);
return 0;
}这个例子创建了一个UDP服务器,绑定到本地地址和端口,然后使用 recvfrom() 接收从客户端发送过来的数据。
sendto() 函数
sendto() 函数是用于通过一个已连接或未连接的套接字发送数据的函数,通常用于UDP(无连接)套接字。
sendto() 函数常用于UDP套接字,而UDP是无连接的协议。所谓“无连接”是指在发送数据之前不需要先建立连接。相比之下,TCP是一种有连接的协议,它要求在数据传输之前先建立一个连接。
在使用UDP时,通信的两端并不需要在彼此之间建立持久的连接。相反,UDP是面向数据报的,每个数据包都是一个独立的实体,不依赖于之前或之后的数据包。因此,sendto() 函数用于发送UDP数据包,而不需要提前建立连接。
总的来说,UDP是一种无连接的协议,因此在使用UDP套接字时,发送数据的过程中不需要事先建立连接。
其原型为:
ssize_t sendto(int sockfd, const void *buf, size_t len, int flags,
const struct sockaddr *dest_addr, socklen_t addrlen);参数说明:
- sockfd:要接收数据的套接字文件描述符。
- buf:一个指向接收数据缓冲区的指针,用于存储接收到的数据。
- len:指定接收缓冲区的大小,即能够接收的最大字节数。
- flags:是接收操作的标志,通常设置为0。可选参数,用于指定接收操作的特殊选项,如下:
-
- MSG_DONTWAIT:非阻塞接收,如果没有数据可接收,则立即返回。
- 其他标志根据具体需求而定,可参考相关文档。
- src_addr: 是一个指向 struct sockaddr 结构体的指针,用于存储发送端的地址信息(ip + port)。
- addrlen:一个指向存储着 src_addr 结构体大小的指针。
该函数返回已发送的字节数,如果出现错误则返回 -1。
注意事项:
- sendto() 函数是一个阻塞调用,即在无法立即发送数据时会一直等待,直到数据被完全发送或出现错误才返回,除非使用 MSG_DONTWAIT 标志进行非阻塞发送。
- 在使用 sendto() 函数之前,需要先创建套接字并进行绑定操作(对于 UDP),或者建立连接(对于 TCP),以便将数据发送到正确的目标地址。
- 在 UDP 套接字中使用 sendto() 可以指定数据的目标地址,而在 TCP 套接字中,可以使用 send() 函数发送数据,而无需每次都指定目标地址。
请注意,以上是基于 C 语言的函数原型和参数说明,具体的使用方式还需要根据具体的编程语言和套接字库来确定。
使用 sendto() 的一个简单例子如下:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <arpa/inet.h>
int main() {
int sockfd;
struct sockaddr_in server_addr;
char buffer[] = "Hello, UDP Server!";
// 创建UDP套接字
if ((sockfd = socket(AF_INET, SOCK_DGRAM, 0)) == -1) {
perror("socket");
exit(EXIT_FAILURE);
}
// 设置服务器地址
memset(&server_addr, 0, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_addr.s_addr = inet_addr("127.0.0.1");
server_addr.sin_port = htons(8080);
// 发送数据
ssize_t send_bytes = sendto(sockfd, buffer, sizeof(buffer), 0,
(struct sockaddr *)&server_addr, sizeof(server_addr));
if (send_bytes == -1) {
perror("sendto");
exit(EXIT_FAILURE);
}
printf("Sent %d bytes to the server.\n", (int)send_bytes);
// 关闭套接字
close(sockfd);
return 0;
}这个例子创建了一个UDP客户端,通过 sendto() 函数向指定的服务器地址发送数据。
popen函数
popen 函数是一个在Linux和Unix系统中提供的标准C库函数,用于创建一个管道并启动一个子进程。该函数提供了一个方便的接口,允许从父进程向子进程发送数据或从子进程接收数据。
函数原型如下:
FILE *popen(const char *command, const char *mode);- command 参数是要执行的命令字符串。
- mode 参数是一个字符串,指定了管道的读写模式。可以是 "r"(读)或 "w"(写)。
popen 函数返回一个文件指针,可以用于读取或写入与子进程的标准输入或输出相关联的管道。
使用示例:
#include <stdio.h>
int main() {
FILE *fp;
char buffer[1024];
// 执行一个命令并从子进程读取输出
fp = popen("ls -l", "r");
if (fp == NULL) {
perror("popen");
return 1;
}
// 读取子进程的输出
while (fgets(buffer, sizeof(buffer), fp) != NULL) {
printf("%s", buffer);
}
// 关闭文件指针
pclose(fp);
return 0;
}在上面的示例中,popen 执行了一个 ls -l 命令,并通过管道读取了子进程的输出。然后,父进程使用 fgets 函数从管道中读取输出,并将其打印到标准输出。最后,使用 pclose 关闭文件指针,等待子进程的结束。
需要注意的是,popen 函数在使用时应当小心防范潜在的安全风险,避免因为用户提供的命令而导致安全漏洞。例如,应该避免直接将用户输入的字符串作为 command 参数传递给 popen,以防止命令注入攻击。
UDP通用客户端
//udp_client.cpp
#pragma once
#include <iostream>
#include <cstring>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <pthread.h>
#include "err.hpp"
//#include "udp_client.hpp"//因为把功能写在了一起,所以没有.hpp文件
using namespace std;
//127.0.0.1:表示本地环回,就表示的就是当前主机,通常用来进行本地通信或者测试,它就是你自己主机默认的IP地址,如何一台机器都有
//它就是用来进行走我们的网络协议栈,但不是把数据发送到网络,只是在网络当中把我的数据转发一下,也就是转发给自己,它实际上就是在
//与自己通信,通常是用来在本地进行测试我们写的客户端和服务器
//启动服务器和客户端,在服务器输入 ./udp_server [port] 进行启动,在客户端输入 ./client 127.0.0.1 [port]进行启动,即可开始测试
//如果想让其他人也给你的服务器进行通信,只需要把 client 发送给别人,让他启动后 把 127.0.0.1 改为你主机的公网IP即可连接上你的服务器进行通信,前提是你的服务器要先启动。
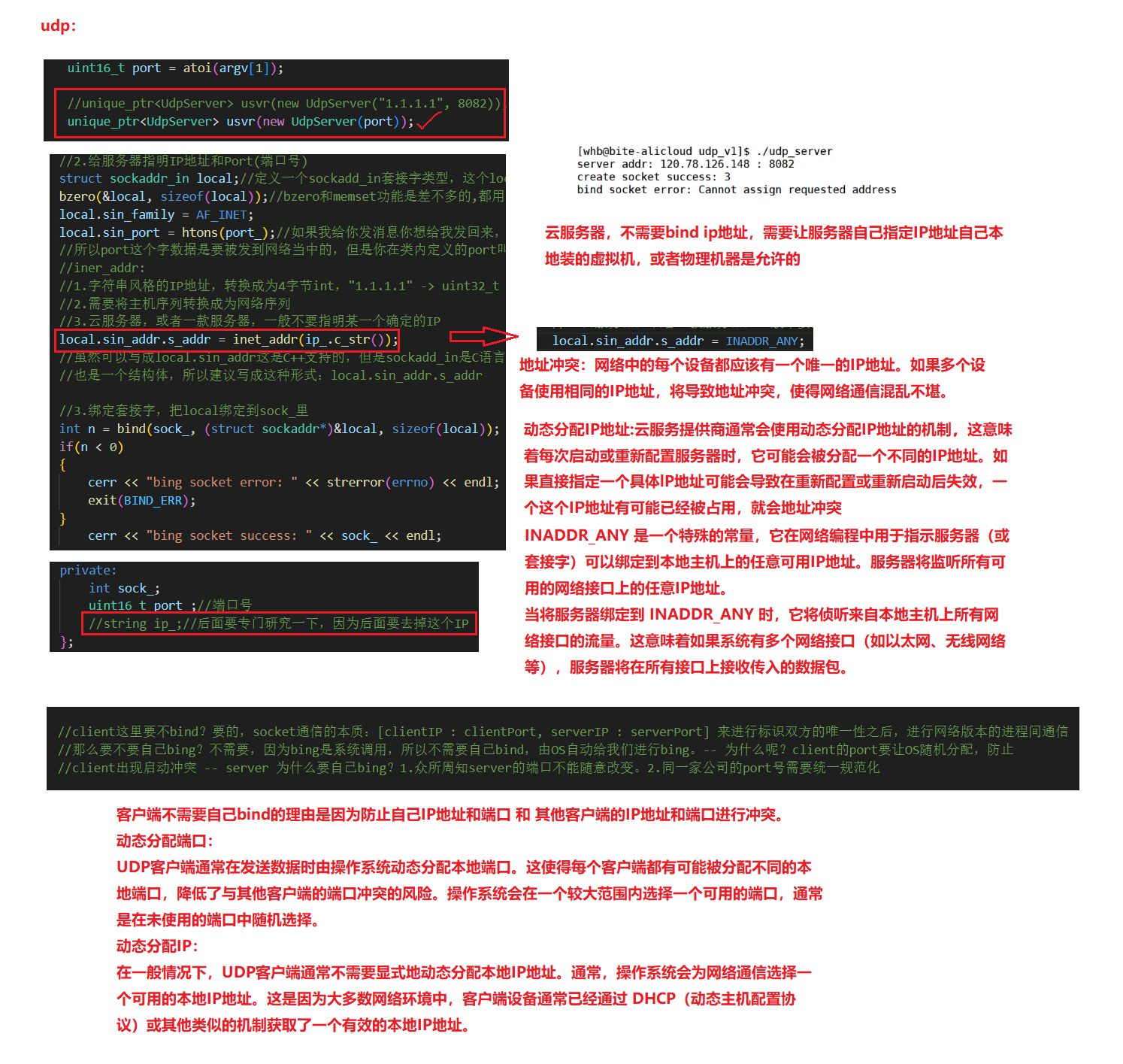
//这就是为什么我们在写服务器的时候 local.sin_addr.s_addr = INADDR_ANY;//让我们的udp_server在启动的时候,自动bind本主机上的任意IP的原因,服务器将监听所有可用的
//网络接口上的任意lP地址。当将服务器绑定到INADDR_ANY时,它将侦听来自本地主机上所有网络接口的数据
static void usage(std::string proc)//使用手册
{
cout << "Usage:\n\t" << proc << " serverip serverport\n" << endl;
}
void *recver(void *args)
{
//接受
int sock = *(static_cast<int *>(args));
while (true)
{
// 接受
char buffer[2048];
struct sockaddr_in temp;
socklen_t len = sizeof(temp);
int n = recvfrom(sock, buffer, sizeof(buffer) - 1, 0, (struct sockaddr *)&temp, &len);
if (n > 0)
{
buffer[n] = 0;
cout << buffer << endl; //1
}
}
}
int main(int argc, char* argv[])
{
if (argc != 3)
{
usage(argv[0]);
exit(USAGE_ERR);
}
string serverip = argv[1];
uint16_t serverport = atoi(argv[2]);
//1.创建socket(套接字)接口,本质就是打开网络文件
int sock = socket(AF_INET, SOCK_DGRAM, 0);//#define AF_INET PF_INET,所以这里使用PF_INET和AF_INET是一样的
if(sock < 0)
{
cout << "create socket error: " << strerror(errno) << endl;
exit(SOCKET_ERR);
}
//cout << "create socket success: " << sock << endl;//输出文件描述符
//client这里要不bind?要的,socket通信的本质:[clientIP : clientPort, serverIP : serverPort] 来进行标识双方的唯一性之后,进行网络版本的进程间通信
//那么要不要自己bing?不需要,也不要自己bind,由OS自动给我们进行bing。-- 为什么呢?client的port要让OS随机分配,防止client出现启动冲突,
//在我们的系统中有许多不同的进程,为了防止不同的应用进程使用同一个端口号,所以要让OS随机分配,防止client出现启动冲突。
//server 为什么要自己bing?1.众所周知server的端口不能随意改变。2.同一家公司的port号需要统一规范化
//什么时候自动bing的?
// 明确server是谁
struct sockaddr_in server;
memset(&server, 0, sizeof(server));
server.sin_family = AF_INET;
server.sin_port = htons(serverport);
server.sin_addr.s_addr = inet_addr(serverip.c_str());//为什么服务器不需要指定IP地址,而客户端需要?
//在服务器端,将套接字的 local.sin_addr.s_addr 设置为 INADDR_ANY 可以使服务器监听在本机的所有可用 IP 地址上。这样服务器就能够接收到发送到任何一个 IP 地址的连接请求。
//然而,在客户端连接到服务器时,需要明确指定要连接的目标服务器的 IP 地址。这是因为客户端需要知道目标服务器的 IP 地址才能建立与服务器的连接。
//客户端通过将 server.sin_addr.s_addr 设置为目标服务器的 IP 地址来指定要连接的服务器。这样客户端就能够将连接请求发送到目标服务器指定的 IP 地址上,与服务器建立连接。
//总结起来,服务器端通过将套接字绑定到 INADDR_ANY 来监听本机的任意 IP 地址上的连接请求。而客户端需要明确指定要连接的目标服务器的 IP 地址。这样服务器端和客户端才能正确地建立连接并进行通信。
pthread_t tid;
pthread_create(&tid, nullptr, recver, &sock);
while(true)
{
// 用户输入
string message;
cerr << "please Enter Your Message# ";//2
//cin >> message;
getline(cin, message);
//什么时候自动bing的?在我们首次系统调用发送数据的时候,OS会在底层随机选择clientport+自己的IP。1.bind 2.构建发送的数据报文
//发送
sendto(sock, message.c_str(), message.size(), 0, (struct sockaddr*)&server, sizeof(server));
}
return 0;
}UDP通用服务器
//udp_server.cpp
#include "udp_server.hpp"
#include <memory>
#include <cstdio>
using namespace ns_server;
static void usage(string proc)//使用手册
{
cout << "Usage:\n\t" << proc << " port\n" << endl;
}
// 上层的业务处理,不关心网络发送,只负责信息处理即可
std::string transactionString(std::string request)
{
std::string result;
char c;
for (auto &r : request)
{
if (islower(r))
{
c = toupper(r);//用于将字符转换为大写形式
result.push_back(c);
}
else
{
result.push_back(r);
}
}
return result;
}
static bool isPass(const string &command)
{
bool pass = true;
auto pos = command.find("rm");
if(pos != string::npos) pass=false;
pos = command.find("mv");
if(pos != string::npos) pass=false;
pos = command.find("while");
if(pos != string::npos) pass=false;
pos = command.find("kill");
if(pos != string::npos) pass=false;
return pass;
}
// 在你的本地把命令给我,server再把结果给你!
// ls -a -l
std::string excuteCommand(string command) // command就是一个命名
{
// 1. 安全检查
if(!isPass(command)) return "you are bad man!";
// 2. 业务逻辑处理
FILE *fp = popen(command.c_str(), "r");
if(fp == nullptr) return "None";
// 3. 获取结果了
char line[1024];
std::string result;
while(fgets(line, sizeof(line), fp) != NULL)
{
result += line;
}
pclose(fp);
return result;
}
int main(int argc, char* argv[])
{
if (argc != 2)
{
usage(argv[0]);
exit(USAGE_ERR);
}
uint16_t port = atoi(argv[1]);
//unique_ptr<UdpServer> usvr(new UdpServer("1.1.1.1", 8082));//服务器不能指定需要bing的IP地址
//unique_ptr<UdpServer> usvr(new UdpServer(transactionString, port));
//unique_ptr<UdpServer> usvr(new UdpServer(excuteCommand, port));
unique_ptr<UdpServer> usvr(new UdpServer(port));
// usvr->InitServer();//服务器的初始化
usvr->start();
return 0;
}//udp_server.hpp
#pragma once
#include <iostream>
#include <cerrno>
#include <cstring>
#include <cstdlib>
#include <functional>
#include <strings.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <pthread.h>
#include <arpa/inet.h>
#include <unordered_map>
#include "err.hpp"
#include "RingQueue.hpp"
#include "lockGuard.hpp"
#include "Thread.hpp"
using namespace std;
namespace ns_server
{
const static uint16_t default_port = 8080;//内置端口号
using func_t = function<string (string)>;//定义一个函数,返回值和参数都是string
class UdpServer
{
public:
UdpServer(uint16_t port = default_port): port_(port)
{
std::cout << "server addr: " << port_ << std::endl;
pthread_mutex_init(&lock, nullptr);
p = new Thread(1, bind(&UdpServer::Recv, this));
c = new Thread(1, bind(&UdpServer::Broadcast, this));
}
void start()
{
//1.创建socket(套接字)接口,本质就是打开网络文件,也就是一个文件描述符(套接字)
sock_ = socket(AF_INET, SOCK_DGRAM, 0);//#define AF_INET PF_INET,所以这里使用PF_INET和AF_INET是一样的,SOCK_DGRAM:创建数据报套接字
if(sock_ < 0)
{
cout << "create socket error: " << strerror(errno) << endl;
exit(SOCKET_ERR);
}
cout << "create socket success: " << sock_ << endl;//输出文件描述符 -- 3,因为0,1,2被占用
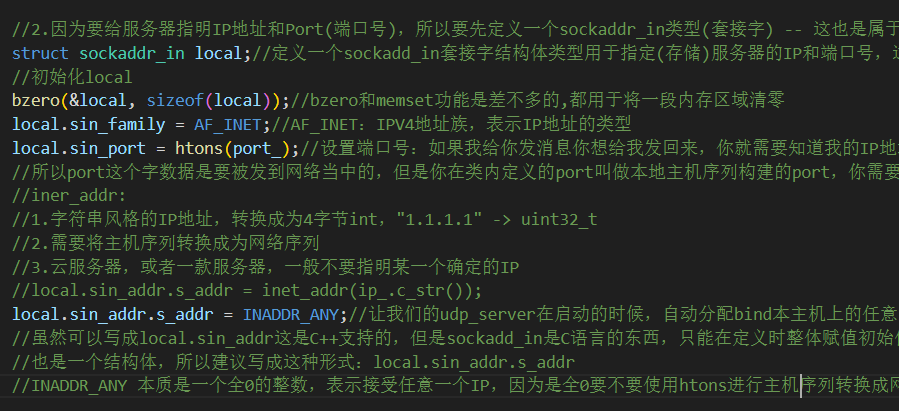
//2.因为要给服务器指明IP地址和Port(端口号),所以要先定义一个sockaddr_in类型(套接字段) -- 这也是属于bing操作的一部分
struct sockaddr_in local;//定义一个sockadd_in套接字结构体类型用于指定(存储)服务器的IP和端口号,这个local在定义哪里?用户空间的特定函数的栈帧上,不在内核中,所以下面的操作只是在对local进行初始化
//初始化local
bzero(&local, sizeof(local));//bzero和memset功能是差不多的,都用于将一段内存区域清零
local.sin_family = AF_INET;//AF_INET:IPV4地址族,表示IP地址的类型
local.sin_port = htons(port_);//设置端口号:如果我给你发消息你想给我发回来,你就需要知道我的IP地址和端口号,换句话说端口号这个两字节的数据必须出现在网络当中
//所以port这个字数据是要被发到网络当中的,但是你在类内定义的port叫做本地主机序列构建的port,你需要把这个port从主机序列转换成网络序列。
//iner_addr:
//1.字符串风格的IP地址,转换成为4字节int,"1.1.1.1" -> uint32_t
//2.需要将主机序列转换成为网络序列 -- iner_addr函数替我们完成了这两件事
//local.sin_addr.s_addr = inet_addr(ip_.c_str());
//3.云服务器,或者一款服务器,一般不要指明某一个确定的IP
local.sin_addr.s_addr = INADDR_ANY;//让我们的udp_server在启动的时候,自动分配bind本主机上的任意IP
//虽然可以写成local.sin_addr这是C++支持的,但是sockadd_in是C语言的东西,只能在定义时整体赋值初始化,不允许第二次整体赋值,因为local.sin_addr
//也是一个结构体,所以建议写成这种形式:local.sin_addr.s_addr
//INADDR_ANY 本质是一个全0的整数,表示接受任意一个IP,因为是全0要不要使用htons进行主机序列转换成网络序列都无所谓。
//3.bind(绑定)套接字,把定义的local绑定到 sock_ 里
int n = bind(sock_, (struct sockaddr*)&local, sizeof(local));
if(n < 0)
{
cerr << "bing socket error: " << strerror(errno) << endl;
exit(BIND_ERR);
}
cout << "bing socket success: " << sock_ << endl;
p->run();
c->run();
}
void addUser(const std::string &name, const struct sockaddr_in &peer)
{
// onlineuserp[name] = peer;
LockGuard lockguard(&lock);
auto iter = onlineuser.find(name);
if (iter != onlineuser.end())
return;
// onlineuser.insert(std::make_pair<const std::string, const struct sockaddr_in>(name, peer));
onlineuser.insert(std::pair<const std::string, const struct sockaddr_in>(name, peer));
}
//注:为什么收和发信息时不需要从主机序列转换成网络序列?因为 recvfrom 和 sendto 会自动帮我们在底层做大小端的转化,以及后面的TCP的读写方法(收和发),也是自动帮我们做大小端的转化
//只有在bind阶段,也就是启动服务器阶段,有些属性是需要我们去把它进行大小端的转化的。如上面的:struct sockaddr_in local 的属性就是如此,而下面的 struct sockaddr_in peer
//和 user 就会自动进行大小端的转换
void Recv()
{
char buffer[1024];//接收/发送 存储数据的缓冲区
while(true)//服务器本质就是死循环
{
// 收
struct sockaddr_in peer;//定义一个用于存储客户端的 IP 地址和端口号的套接字结构体,所以不需要和上面一样进行初始化,因为是用来接收的。
socklen_t len = sizeof(peer); // 这里一定要写清楚,未来你传入的缓冲区大小,也就是sockaddr_in结构体的大小
int n = recvfrom(sock_, buffer, sizeof(buffer) - 1, 0, (struct sockaddr *)&peer, &len);//sizeof(buffer) - 1保留一个位置添加 \0
if (n > 0)
buffer[n] = '\0';
else
continue;
// 提取client信息 -- debug
string clientip = inet_ntoa(peer.sin_addr);
uint16_t clientport = ntohs(peer.sin_port);
cout << clientip << "-" << clientport << "# " << buffer << endl;
// 构建一个用户,并检查
std::string name = clientip;
name += "-";
name += std::to_string(clientport);
// 如果不存在,就插入,如果存在,什么都不做
addUser(name, peer);
rq.push(buffer);
// // 做业务处理
// std::string message = service_(buffer);
// 发 -- 把接受到的数据经过业务处理之后发回给客户端
// sendto(sock_, message.c_str(), message.size(), 0, (struct sockaddr*)&peer, sizeof(peer));
// sendto(sock_, buffer, strlen(buffer), 0, (struct sockaddr*)&peer, sizeof(peer));
}
}
//发
void Broadcast()
{
while (true)
{
string sendstring;
rq.pop(&sendstring);
vector<struct sockaddr_in> v;
{
LockGuard lockguard(&lock);
for (auto user : onlineuser)
{
v.push_back(user.second);
}
}
for (auto user : v)
{
// cout << "Broadcast message to " << user.first << sendstring << endl;
sendto(sock_, sendstring.c_str(), sendstring.size(), 0, (struct sockaddr *)&(user), sizeof(user));
cout << "send done ..." << sendstring << endl;
}
}
}
~UdpServer()
{
pthread_mutex_destroy(&lock);
c->join();
p->join();
delete c;
delete p;
}
private:
int sock_;
uint16_t port_;//端口号
//func_t service_;//测试完解决网络的IO问题之后,开始进行业务处理 -- 回调函数
unordered_map<string, struct sockaddr_in> onlineuser;//在线用户
pthread_mutex_t lock;
RingQueue<string> rq;
Thread* c;
Thread* p;
//string ip_;//后面要专门研究一下,因为后面要去掉这个IP
};
}
其他相关头文件
//Makefile
.PHONY:all
all: udp_client udp_server
udp_client:udp_client.cc
g++ -o $@ $^ -std=c++11 -lpthread
udp_server:udp_server.cc
g++ -o $@ $^ -std=c++11 -lpthread
.PHONY:clean
clean:
rm -f udp_client udp_server//RingQueue.hpp
#pragma once
#include <iostream>
#include <vector>
#include <semaphore.h>
#include <pthread.h>
using namespace std;
static const int N = 5;
template<class T>
class RingQueue
{
private:
void P(sem_t &s)
{
sem_wait(&s);//P操作 --
}
void V(sem_t &s)
{
sem_post(&s);//V操作 ++
}
void Lock(pthread_mutex_t &m)
{
pthread_mutex_lock(&m);
}
void UnlocK(pthread_mutex_t &m)
{
pthread_mutex_unlock(&m);
}
public:
RingQueue(int num = N) :_ring(num), _cap(num)
{
sem_init(&_data_sem, 0, 0);
sem_init(&_space_sem, 0, num);
_c_step = _p_step = 0;
pthread_mutex_init(&_c_mutex, nullptr);
pthread_mutex_init(&_p_mutex, nullptr);
}
void push(const T &in)//生产
{
//先申请锁,还是先申请信号量?答案是推荐先申请信号量
//如果我们先申请锁,那么也就意味着生产线程只要持有锁了,其他线程就没有机会进入后续的代码逻辑了
//更加意味着其他线程在当前线程持有锁期间,其他线程也就只能在外部等待,但是如果先申请信号量,我们
//就可以先把资源分配好,就好比一间教室你是让一个一个的人进来找好坐位,还是直接让一批人进来找好坐位,那个
//速度更快?当然是让一批人进来找坐位速度更快,效率更好,所以下面的消费者也是如此。
//所以先申请信号量,在进行加锁。
P(_space_sem);//P操作 --
Lock(_p_mutex);
_ring[_p_step++] = in;
_p_step %= _cap;
UnlocK(_p_mutex);
V(_data_sem);//V操作 ++
}
void pop(T* out)//消费
{
//信号量存在的意义
//1.可以不用在临界区内部对资源做判断,就可以知道临界资源的使用情况
//2.什么时候用锁?什么时候用sem(信号量)?取决于你对应的临界资源,是否被整体使用!
P(_data_sem);
Lock(_c_mutex);
*out = _ring[_c_step++];
_c_step %= _cap;
UnlocK(_c_mutex);
V(_space_sem);
}
~RingQueue()
{
sem_destroy(&_data_sem);
sem_destroy(&_space_sem);
pthread_mutex_destroy(&_c_mutex);
pthread_mutex_destroy(&_p_mutex);
}
private:
vector<T> _ring;
int _cap;//环形队列容器大小
sem_t _data_sem;//数据 -- 只有消费者关心
sem_t _space_sem;//空间 -- 只有生产者关心
int _c_step;//消费位置
int _p_step;//生产位置
//因为消费者和生产者是并行的所以需要两把锁,防止消费者内部的竞争和生产者内部的竞争
//因为信号量的原因并不用担心死锁问题,因为消费者和生产者指向同一个位置时,只有其中一个可以运行
pthread_mutex_t _c_mutex;//消费者之间的锁
pthread_mutex_t _p_mutex;//生产者之间的锁
};//Thread.hpp
#pragma once
#include <iostream>
#include <string>
#include <cstdlib>
#include <pthread.h>
#include <unistd.h>
#include <functional>
using namespace std;
class Thread
{
public:
typedef enum
{
NEW = 0,
RUNNING,
EXITED
} ThreadStatus;
//typedef void (*func_t)(void*);
using func_t = function<void ()>;
public:
Thread(int num, func_t func) : _tid(0), _status(NEW), _func(func)
{
char name[128];
snprintf(name, sizeof(name), "thread-%d", num);
_name = name;
}
int status() { return _status; }//获取线程状态
std::string threadname() { return _name; }//获取线程名字
pthread_t threadid()//获取线程ID
{
if (_status == RUNNING)
return _tid;
else
{
return 0;
}
}
// runHelper是不是类的成员函数,而类的成员函数,具有默认参数this,需要static
// 但是会有新的问题:static成员函数,无法直接访问类属性和其他成员函数
static void* runHelper(void *args)
{
Thread *ts = (Thread*)args; // 就拿到了当前对象
// _func(_args);
(*ts)();
return nullptr;
}
void operator ()() //仿函数
{
if(_func != nullptr)
_func();
}
void run()
{
int n = pthread_create(&_tid, nullptr, runHelper, this);
if(n != 0) exit(1);
_status = RUNNING;
}
void join()
{
int n = pthread_join(_tid, nullptr);
if( n != 0)
{
std::cerr << "main thread join thread " << _name << " error" << std::endl;
return;
}
_status = EXITED;
}
~Thread()
{}
private:
pthread_t _tid;
std::string _name;
func_t _func; // 线程未来要执行的回调
ThreadStatus _status;
};//err.hpp
#pragma once
enum
{
USAGE_ERR = 1,
SOCKET_ERR,
BIND_ERR,
};//lockGuard.hpp
#pragma once
#include <iostream>
#include <pthread.h>
class Mutex // 自己不维护锁,有外部传入
{
public:
Mutex(pthread_mutex_t *mutex):_pmutex(mutex)
{}
void lock()
{
pthread_mutex_lock(_pmutex);//加锁
}
void unlock()
{
pthread_mutex_unlock(_pmutex);//解锁
}
~Mutex()
{}
private:
pthread_mutex_t *_pmutex;
};
class LockGuard // 自己不维护锁,有外部传入
{
public:
LockGuard(pthread_mutex_t *mutex):_mutex(mutex)
{
_mutex.lock();//通过构造函数自动加锁,防止忘记加锁
}
~LockGuard()
{
_mutex.unlock();//通过析构函数自动解锁,防止忘记解锁
}
private:
Mutex _mutex;
};listen函数
listen 函数是在套接字编程中用于监听客户端连接请求的函数。它被用于服务器端,用于标识一个套接字以侦听客户端的连接请求。
函数原型如下:
#include <sys/types.h>
#include <sys/socket.h>
int listen(int sockfd, int backlog);- sockfd:是一个已创建并绑定到地址的套接字的文件描述符,通常是通过 socket 和 bind 函数创建并初始化的。
- backlog:是一个整数,表示在等待队列中允许的未处理连接的最大数量。这是指已经连接但还没有被服务器 accept 函数接受的客户端连接请求的队列长度。如果队列已满,新的连接请求将被拒绝。
返回值:
- 成功: 如果 listen 函数成功执行,则返回 0。这表示当前套接字现在处于监听状态,可以接受连接请求。
- 失败: 如果 listen 函数执行失败,则返回 -1,并且设置全局变量 errno 表示具体的错误原因。
listen 函数通常用于TCP套接字,在调用 listen 之前,通常需要通过 socket 创建套接字并使用 bind 绑定到一个地址。一旦调用 listen,套接字就处于监听状态,可以通过 accept 函数接受来自客户端的连接请求。
示例:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <arpa/inet.h>
#include <sys/types.h>
#include <sys/socket.h>
int main() {
int server_fd, client_fd;
struct sockaddr_in server_addr, client_addr;
int backlog = 5;
// 创建 socket
server_fd = socket(AF_INET, SOCK_STREAM, 0);
if (server_fd == -1) {
perror("Socket creation failed");
exit(EXIT_FAILURE);
}
// 绑定地址
server_addr.sin_family = AF_INET;
server_addr.sin_addr.s_addr = INADDR_ANY;
server_addr.sin_port = htons(8080);
if (bind(server_fd, (struct sockaddr*)&server_addr, sizeof(server_addr)) == -1) {
perror("Bind failed");
exit(EXIT_FAILURE);
}
// 监听连接
if (listen(server_fd, backlog) == -1) {
perror("Listen failed");
exit(EXIT_FAILURE);
}
printf("Server listening on port 8080...\n");
// 其他处理...
close(server_fd);
return 0;
}在这个例子中,listen 函数用于监听客户端连接请求,指定了最大等待队列的长度。接下来,服务器可以使用 accept 函数接受连接请求,处理客户端连接。
netstat指令
netstat 是一个用于显示网络状态信息的命令行工具,在 Linux 系统中广泛使用。它可以显示各种网络相关信息,比如网络连接、路由表、接口统计等。netstat 可以用于查看活动连接、监听端口、路由表等网络相关信息,帮助诊断网络问题和监视网络活动。
在使用 netstat 时,常见的一些选项包括:
- -a:显示所有选项(连接和监听的端口),默认不显示LISTEN相关。
- -n:以数字形式显示地址和端口号,不进行反向域名解析。
- -t:仅显示 TCP 相关选项连接。
- -p:显示正在使用套接字的进程标识符(PID)和程序名称。
- -u:仅显示 UDP 相关选项连接。
- -r:显示路由表信息。
- -s:显示各个协议的统计信息。
- -l:仅显示监听状态的套接字。
- -e:显示更详细的信息,如用户和 Inode。
例如,要显示所有的网络连接和监听的端口,可以使用以下命令:
netstat -a如果只想显示 TCP 连接,可以使用以下命令:
netstat -tnetstat 在最新的 Linux 发行版中可能已被标记为过时,建议使用 ss 命令或 ip 工具来代替。例如,ss 命令可以用来显示套接字统计信息。
ss -t -a无论是 netstat 还是 ss,它们都是很有用的网络工具,可以帮助了解系统中的网络连接情况、诊断网络问题并监控网络活动。
accept 函数
accept 函数用于从监听套接字接受连接,并返回一个新的套接字描述符,该文件描述符(套接字)用于与客户端进行通信。这个新的套接字是专门为与新连接的客户端通信而创建的。accept 函数通常在服务器程序中使用,用于接受客户端的连接请求。
函数原型如下:
#include <sys/types.h>
#include <sys/socket.h>
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);- sockfd:是一个已经通过 socket 创建并经过 bind 和 listen 设置为监听状态的套接字的文件描述符。
- addr:是一个指向 struct sockaddr 结构体的指针,用于存储与连接相关的客户端地址信息。
- addrlen:是一个指向 socklen_t 类型的指针,用于指定 addr 缓冲区的大小。在调用 accept 之前,应该将 *addrlen 设置为 sizeof(struct sockaddr)。
accept 函数的返回值是一个新的套接字描述符,用于与客户端进行通信。如果出现错误,accept 返回 -1,并设置 errno 表示错误的类型。
下面是一些可能的错误情况:
- errno 为 EAGAIN 或 EWOULDBLOCK:
-
- 表示非阻塞套接字上没有连接请求等待接受。
- 这在非阻塞模式下是一个可能的错误返回,表示当前没有连接请求处于等待状态。
- errno 为 EINTR:
-
- 表示 accept 被信号中断。
- 这可能是由于接收到中断信号而导致 accept 函数返回。
- EBADF:无效的文件描述符,即 sockfd 不是一个有效的套接字描述符。
- EFAULT:addr 指针指向的内存空间无法访问。
- EINVAL:sockfd 不是一个监听套接字。
- ENOTSOCK:sockfd 不是一个套接字。
注:accept 函数是一个阻塞调用。在TCP服务器编程中,accept 用于接受客户端的连接请求,并创建一个新的套接字用于与客户端通信。当没有连接请求到来时,accept 会一直阻塞等待,直到有新的连接请求到达为止。
以下是一个简单的使用 accept 的示例:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <arpa/inet.h>
int main() {
int server_fd, client_fd;
struct sockaddr_in server_addr, client_addr;
socklen_t client_len = sizeof(client_addr);
// 创建 socket
server_fd = socket(AF_INET, SOCK_STREAM, 0);
if (server_fd == -1) {
perror("Socket creation failed");
exit(EXIT_FAILURE);
}
// 绑定地址
server_addr.sin_family = AF_INET;
server_addr.sin_addr.s_addr = INADDR_ANY;
server_addr.sin_port = htons(8080);
if (bind(server_fd, (struct sockaddr*)&server_addr, sizeof(server_addr)) == -1) {
perror("Bind failed");
exit(EXIT_FAILURE);
}
// 监听连接
if (listen(server_fd, 5) == -1) {
perror("Listen failed");
exit(EXIT_FAILURE);
}
printf("Server listening on port 8080...\n");
// 接受连接
client_fd = accept(server_fd, (struct sockaddr*)&client_addr, &client_len);
if (client_fd == -1) {
perror("Accept failed");
exit(EXIT_FAILURE);
}
printf("Connection accepted from %s:%d\n", inet_ntoa(client_addr.sin_addr), ntohs(client_addr.sin_port));
// 在新的 client_fd 上进行通信
close(server_fd);
close(client_fd);
return 0;
}在这个例子中,accept 函数用于接受来自客户端的连接请求,返回一个新的套接字描述符 client_fd,通过这个描述符可以进行与客户端的通信。
注:socket函数和accept 函数的返回值都是返回一个套接字,他们两个的返回值之间的区别:
socket 的返回值:
socket 函数用于创建一个新的套接字,它返回一个套接字描述符(socket descriptor)。
套接字描述符是一个整数值,代表着操作系统内核中关联的套接字资源。这个描述符是后续进行套接字通信的标识符。简单来说socket 函数创建的套接字是用来标识IP地址类型和端口号(端口号通过bing函数写入)以及通信类型方式的。
地址类型:
通常使用 AF_INET (IPv4)地址类型 或者 AF_INET6(IPv6)地址类型。
通信类型:
通过指定 SOCK_STREAM,创建的是一个面向连接的套接字,即TCP套接字。TCP提供可靠的、有序的、双向的字节流通信。
通过指定 SOCK_DGRAM 用于套接字类型,那么创建的将是一个用于UDP通信的套接字,UDP是无连接的、不可靠的通信协议。
accept 的返回值:
accept 函数用于在服务器端接受客户端的连接请求,并创建一个新的套接字用于与该客户端通信。accept 函数返回一个新的套接字描述符(返回值),用于实际的数据传输,与客户端进行通信。通过IO函数可以对该 描述符 进行 读写 操作。
简单举一个例子描述 socket 和 accept 创建的套接字的区别:
假设有一家餐厅,有一个专门负责揽客的店员叫做张三和一堆服务员李四、王五等,张三负责在店外招揽客人进餐厅吃饭,李四、王五负责给客人进行点菜和上菜等服务。
- Socket创建的套接字(返回值):
- 当使用 socket 函数创建套接字时,它返回一个文件描述符,这个文件描述符实际上代表了一个套接字。这个过程就好比张三站在餐厅外,负责招揽客人进入餐厅。这个套接字在服务器端用于监听客户端的连接请求。
- 通常,这个套接字被命名为 listensocket 或 serverSocket,因为它专门用于监听客户端的连接请求,类似于张三专门负责招揽客人。
- accept创建的套接字(返回值):
- 当使用 accept 函数处理客户端的连接请求时,它会创建一个新的套接字,用于在服务器端和客户端之间进行通信。这个新的套接字就好比餐厅的服务员(李四、王五),负责与特定客户端进行交流和提供服务。
- 这个新创建的套接字通常被命名为 clientSocket 或类似的名称,因为它用于处理与特定客户端的通信。
所以,可以将整个过程类比为张三(listensocket)在餐厅外招揽客人,当有客人进来时,由服务员(accept 创建的新套接字)负责与客人进行具体的点菜和上菜服务。这样的比喻可以帮助理解服务器端套接字和客户端套接字之间的区别及其各自的角色。
总结两者之间的区别:
socket创建的套接字是用来接受其他主机发送过来的通信连接,当然也可以用于服务器和客户端的通信,而accept创建的套接字是用来服务器和客户端的通信的。
在服务器端,调用socket函数创建一个监听套接字,用于监听等待客户端的连接请求。然后,通过调用accept函数,创建一个新的套接字,用于与具体的客户端进行通信(accept:用于个客户端发送请求连接的时候)。socket函数创建的套接字也可以用于服务器和客户端之间的通信(socket:用于一个客户端发送请求连接的时候),所以socket创建的套接字在一对一的情况下是用来作为通信套接字,一对多的情况下是用来作为监听套接字。
在客户端,调用socket函数创建一个套接字,用于与服务器建立通信连接。通过这个套接字,客户端可以向服务器发送请求并接收服务器的响应。
总结来说,socket是通用的用于通信的数据结构,而accept创建的套接字是服务器与客户端之间的通信套接字。
connect函数
connect函数是用于建立TCP连接的系统调用(或函数),通常在TCP客户端中使用。在C语言中,connect函数的原型如下:
#include <sys/types.h>
#include <sys/socket.h>
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);在使用connect函数时,需要提供以下参数:
- sockfd:一个已经创建并绑定(如果需要)的套接字文件描述符,通常通过socket创建。
- addr:一个指向目标服务器地址结构的指针,通常是struct sockaddr类型。这个结构包含目标服务器的IP地址和端口号。
- addrlen:addr结构的大小,以字节为单位。
connect函数的作用是尝试与指定的目标服务器建立连接。它完成了以下主要步骤:
- 与服务器建立TCP连接:connect函数尝试与指定的目标服务器建立TCP连接。
- 三次握手: 在TCP连接的建立过程中,connect函数将执行三次握手协议,确保客户端和服务器都同意建立连接。
- 阻塞或非阻塞: 如果connect函数成功建立连接,它将返回0。如果连接建立失败,它可能会阻塞(默认情况下)或根据套接字的设置而返回适当的错误码。在非阻塞模式下,connect可能会返回EINPROGRESS,表示连接正在进行中。
在使用connect函数之前,通常需要先创建套接字并使用bind函数绑定本地地址(如果需要)。connect函数通常在TCP客户端的初始化过程中调用,以建立与服务器的连接,然后客户端可以使用send和recv等函数进行数据交换。
send 函数
send 函数通常用于在面向连接的套接字(如TCP套接字)上发送数据。它是一种可靠的、有序的数据传输方式。
#include <sys/socket.h>
ssize_t send(int sockfd, const void *buf, size_t len, int flags);- sockfd: 套接字文件描述符。
- buf: 包含要发送数据的缓冲区的指针。
- len: 要发送的数据的字节数。
- flags: 发送操作的标志,通常可以设置为0。
返回值:
- 成功发送数据: 返回值是发送的字节数。这表示成功将数据发送到连接的另一端。
- 连接关闭: 返回值为 0。这表示连接的远程一方已经关闭了连接。在TCP套接字中,发送0字节通常意味着对方已经关闭了连接。
- 出现错误: 返回值为 -1,并且设置了 errno 来指示错误类型。可能的错误类型包括:
-
- EAGAIN 或 EWOULDBLOCK:套接字处于非阻塞模式,并且发送缓冲区已满,需要等待下次可写。
- EINTR:发送操作被信号中断。
- 其他错误类型,如 EPIPE(连接已经被对方关闭), EFAULT(缓冲区指针无效), EINVAL(参数无效)等。
需要注意的是,send 函数是在面向连接的套接字上使用的,通常用于 TCP 协议。在使用 send 函数之前,通常需要先使用 connect 函数建立连接。
在某些情况下,你可以使用 write 函数替代 send 函数,特别是在使用面向连接的套接字(如 TCP 套接字)时。然而,需要注意的是,它们有一些细微的区别。
- 套接字 vs. 通用文件描述符:
-
- write 函数是一个通用的文件写入函数,可用于写入任何文件描述符,包括套接字。
- send 函数更专门用于在套接字上发送数据。
- 面向连接 vs. 无连接:
-
- 如果你的套接字是面向连接的(如 TCP 套接字),那么 write 可以替代 send。
- 对于无连接的套接字(如 UDP 套接字),最好使用 sendto。
- 可移植性:
-
- write 函数是 POSIX 标准的一部分,具有更广泛的可移植性。
- send 函数在 POSIX 中也是标准的,但它提供了一些用于网络编程的扩展选项(如 MSG_NOSIGNAL)。
- 错误处理:
-
- 错误处理可能略有不同,因为 send 的错误处理通常涉及到更多的网络相关的错误。
recv函数
通常recv函数用于TCP套接字。recv 函数用于从已连接的套接字接收数据。它的原型如下:
#include <sys/types.h>
#include <sys/socket.h>
ssize_t recv(int sockfd, void *buf, size_t len, int flags);其中:
- sockfd 是套接字描述符,标识要接收数据的套接字。
- buf 是用于存放接收数据的缓冲区的指针。
- len 是缓冲区的长度,即可接收的最大字节数。
- flags 是一组标志,通常为0。可以用来指定一些接收操作的选项,例如设置 MSG_WAITALL 标志以确保接收到指定长度的数据。
recv 函数的返回值表示实际接收到的字节数,可能的情况包括:
- 成功接收数据: 返回值是实际接收到的字节数。应用程序可以使用这个返回值来处理接收到的数据。
- 连接关闭: 返回值为 0。这表示连接的远程一方已经关闭了连接。在TCP套接字中,收到0字节通常意味着对方已经关闭了连接。
- 出现错误: 返回值为 -1,并且设置了 errno 来指示错误类型。可能的错误类型包括:
-
- EAGAIN 或 EWOULDBLOCK:套接字处于非阻塞模式,并且在接收缓冲区中没有可用数据。
- EINTR:接收操作被信号中断。
- 其他错误类型,如 ECONNRESET(连接被对方重置)、EFAULT(缓冲区指针无效)、EINVAL(参数无效)等。
在调用 recv 函数后,应用程序通常会检查返回值并根据返回值的不同情况来处理接收到的数据或处理错误。
注:
send函数是真的把我们定义的缓冲区里面的数据直接发送到对方的主机吗?显然不是,在Linux内核中存在两个缓冲区,一个是发送缓冲区,另一个是接受缓冲区,在发送数据时,TCP协议要先把send发送的数据拷贝到内核的发送缓冲区,然后再把数据发送到对方主机内核的接受缓冲区,而recv函数也不是直接把数据读取上来,要等接受缓冲区把数据拷贝到recv函数提供的缓冲区内才可以进行读取数据。
这个过程涉及几个关键步骤:
- 用户空间到内核空间的复制:当应用调用 send 函数时,数据从用户空间的内存复制到内核空间的 TCP 发送缓冲区。
- TCP 分段:内核中的 TCP/IP 协议栈处理数据包的分段、头部信息的添加(包括序列号、校验和等)以及可能的流量控制和拥塞控制机制。
- 网络传输:经过处理的 IP 数据包通过网络发送到对方主机。
- 对方内核的处理:对方主机接收到数据包后,将其放入 TCP 接收缓冲区,等待应用程序读取。
- 内核空间到用户空间的复制:当应用程序调用 recv 函数时,数据从内核的接收缓冲区复制回用户空间的内存中,此时应用程序才能处理这些数据。
inet_aton函数
inet_aton函数是用于将点分十进制(IPv4地址的一种表示形式)转换为网络地址的函数(也是主机序列转换网络序列)。该函数在C语言中常常用于网络编程中,特别是在套接字编程中。
inet_aton函数的原型如下:
#include <arpa/inet.h>
int inet_aton(const char *cp, struct in_addr *inp);函数的参数解释如下:
- cp:是一个指向包含点分十进制IPv4地址的字符串的指针。
- inp:是一个指向struct in_addr的指针,用于存储转换后的二进制网络字节序的IPv4地址。
inet_aton函数的返回值是一个整数,如果转换成功,返回1,如果失败,返回0。在失败的情况下,可以使用errno变量来获取错误的具体原因。
jobs指令
在 Unix 和 Unix-like 操作系统中(如 Linux),jobs 命令用于显示当前 shell 中的作业列表。作业(进程/任务)是由 shell 管理的进程或命令的集合。(从现在开始,以后启动的进程我们都叫做进程组或者任务)以下是 jobs 命令的基本用法:
jobs [-lnprs] [jobspec ...] or jobs -x command [args]- 选项:
-
- -l: 显示详细信息,包括作业号、状态、进程ID等。
- -n: 只显示状态非运行中 (stopped 或 completed) 的作业。
- -p: 只显示进程组ID。
- -r: 只显示运行中的作业。
- -s: 只显示已停止的作业。
- jobspec: 可选参数,指定作业的标识符。可以是作业号(以 '%' 开头)、进程组ID、或者是 %+(当前作业)或 %-(前一个作业)。
- -x command [args]: 将指定的命令作为作业运行,但不等待其完成。
示例:
- 显示当前 shell 中的所有作业:
jobs- 显示详细信息,包括作业号、状态、进程ID等:
jobs -l- 显示所有已停止的作业:
jobs -s- 将 sleep 命令放入后台运行,然后使用 jobs 查看:
sleep 100 &
jobsjobs 命令对于在后台运行的作业的管理非常有用,特别是在使用交互式 shell 时。通过 jobs,用户可以查看当前 shell 中正在运行或已停止的作业,以及它们的状态和标识符。
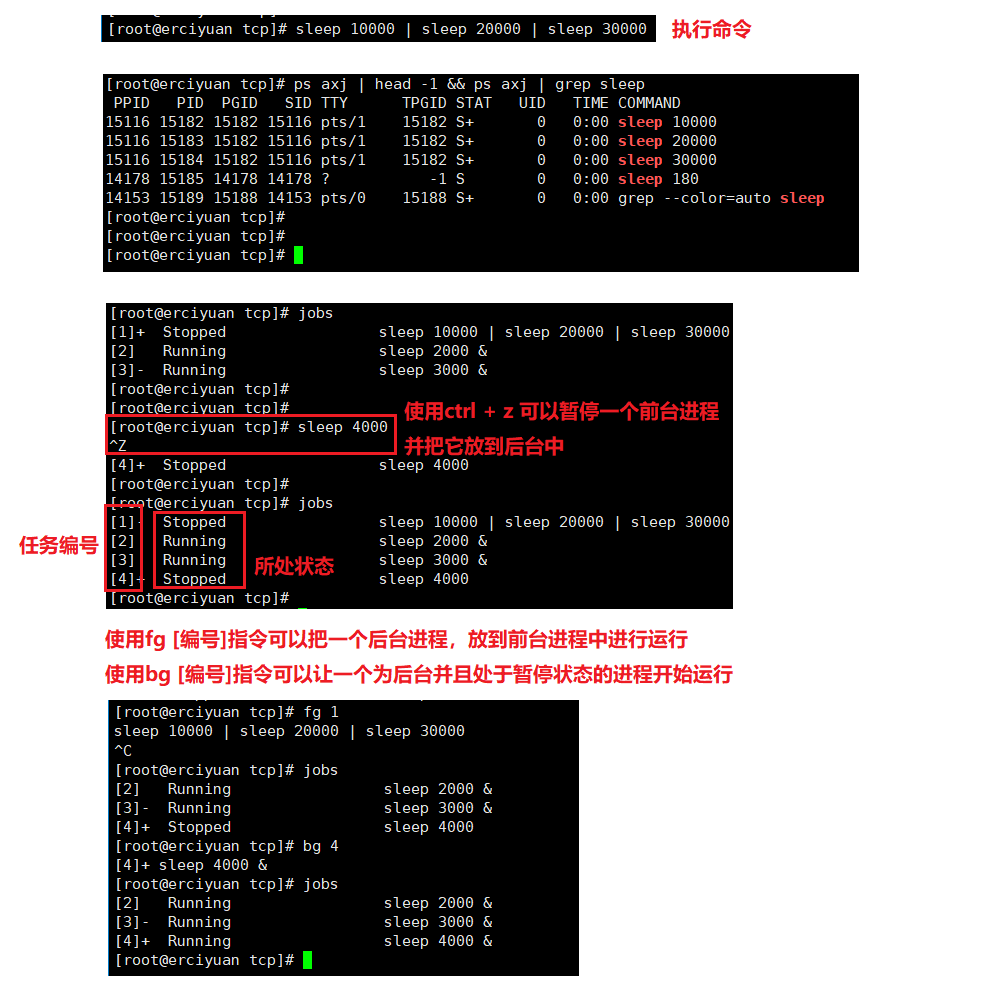
- PGID(Process Group ID):
-
- 每个进程都属于一个进程组,进程组有一个唯一的ID,称为进程组ID(PGID)。进程组允许将多个进程组合在一起,以便可以向整个进程组发送信号。通常情况下,一个进程的 PGID 与其所在会话的 ID(SID)相同,但可以使用 setpgid() 等系统调用来更改进程的进程组ID。
- SID(Session ID):
-
- 会话是一个或多个进程组的集合。会话ID(SID)是一个整数,用于唯一标识一个会话。当用户登录时,通常会创建一个新会话,并将该会话中的第一个进程作为会话的领头进程(Session Leader),其进程ID(PID)就是会话ID(SID)。会话ID在整个会话期间保持不变,即使进程组成员发生变化。
注:每个进程组(Process Group)都有一个进程组组长(Process Group Leader)。进程组组长是该进程组中第一个创建的进程。一旦创建了进程组,它的进程组组长就不能改变。
进程组组长的主要职责是接收来自终端的信号,例如中断信号(Ctrl+C)。当用户在终端上按下中断键时,中断信号会被发送给整个进程组的每个成员,然后由进程组组长接收并处理。这是为了确保用户能够方便地中断整个作业或进程组。
在创建新的进程组时,通常第一个进程会成为该进程组的组长。如果你在终端上启动一个新的命令,该命令就会成为一个新的进程组,而该命令的第一个进程将成为进程组组长。
- TTY(Teletypewriter):
-
- TTY是指终端设备,它提供了用户与计算机交互的界面。在 UNIX 或 Linux 中,TTY 通常是用户登录系统时分配给用户的终端。TTY也可以是虚拟终端(如终端仿真器或通过SSH远程连接的终端)。每个进程都可以与一个TTY相关联,以便通过该TTY与用户交互。(如果显示的是 "?" 表示该进程没有与终端产生关联)。
1.在会话中只能有一个前台任务在运行!我们在命令行启动一个进程的时候,bash无法运行了!
2.如果登录就是创建一个会话,bash任务(启动的进程),就是在当前会话中创建新的前台任务,那么如果我们退出呢?就是销毁会话,可能会影响会话内部的所有任务!所以为了不受到用户的登录和注销的影响,一般网络服务器,都是以守护进程的方式进行运行!(只要我们的电脑(云服务器)没有关闭,服务器依然可以在运行)
举个例子:
一个公司只有一个上级领导,而这个领导手下有一堆人,划分几个人为一组,而每个小组都要有自己的组长。
- 公司代表着会话窗口(SID):
-
- 在计算机操作系统中,会话窗口是一个抽象概念,表示一次用户与系统进行交互的会话。一个公司在这个比喻中可以被看作是一个会话窗口(Session Identifier,SID),每个公司代表了一个独立的会话。
- 上级领导代表 shell:
-
- Shell是用户与操作系统内核进行交互的界面。在这个比喻中,上级领导就好比是shell。每个会话只有一个会话领导进程,就像每个公司只有一个上级领导。这个领导进程负责接收用户输入,并将其传递给内核执行。
- 进程组长指的是第一个创建小组的人:
-
- 在Unix/Linux系统中,进程组是一组相关进程的集合,而进程组长是该组的第一个进程。在你的比喻中,每个小组都有自己的组长,就像在一个会话中,第一个创建小组的人会成为这个小组的组长。这个组长负责管理小组内的进程。
setsid函数(创建守护进程)
在 Linux 中,setsid 函数用于创建一个新的会话(session)并设置调用进程为该会话的领头进程(session leader)。这样,调用进程就成为一个新会话中的唯一进程组的领头进程,并且脱离了原来的控制终端。
具体的函数原型如下:
#include <unistd.h>
pid_t setsid(void);setsid()函数在调用进程中创建一个新的会话,并使其成为进程组的组长。该函数返回新会话的ID。
使用setsid()函数时,有以下几个注意点:
- 如果调用setsid()函数的进程是一个进程组的组长,该函数将失败返回-1。
- 如果调用setsid()函数的进程不是会话的首进程(session leader),则创建一个新的会话,并将该进程设置为会话的首进程(进程组的组长)。
- 创建新会话后,调用进程将成为新会话的首进程,新会话中只有一个进程组,该进程组的组ID和会话ID相同。
- 新会话中的进程不再拥有终端控制。
常见用途:
- 用于创建守护进程(daemon):通过调用fork()复制一个进程,然后在子进程中调用setsid()函数创建新会话,使得守护进程摆脱终端控制。
- 防止进程终止信号的传递:可以在一个子进程中调用setsid()函数来创建新会话,使得该进程不再受到终止信号SIGHUP的影响。
示例用法
#include <unistd.h>
#include <stdio.h>
int main() {
pid_t pid;
pid = fork();
if (pid < 0) {
perror("fork");
return -1;
} else if (pid > 0) {
// 父进程退出
return 0;
}
// 子进程调用setsid()函数创建新会话
pid_t sid = setsid();
if (sid < 0) {
perror("setsid");
return -1;
}
// 在新会话中进行其他操作
printf("New session ID: %d\n", sid);
// ...
return 0;
}在上述示例中,首先调用fork()创建子进程,然后在子进程中调用setsid()函数创建新会话。随后,在新会话中,可以进行需要的操作,如设置工作目录、关闭标准输入输出等。
注:守护进程:a. 要忽略异常信号 b. 0,1,2,要做特殊处理 c. 进程的工作路径可能要更改。
/dev/null 文件的作用
/dev/null 是一个特殊的设备文件,用于丢弃数据。在 Unix 和类 Unix 系统中,/dev/null 被称为空设备,任何写入它的数据都会被丢弃,而读取它则会立即得到文件结束符。
这个设备在很多情况下用于丢弃输出或者创建空输入。以下是一些常见用途:
- 丢弃输出: 如果你运行一个命令,但不希望看到其输出,你可以将输出重定向到 /dev/null,这样输出就会被完全丢弃。
some_command > /dev/null- 创建空输入: 如果某个程序需要输入,但你没有实际数据要提供,你可以将 /dev/null 作为输入源。
some_command < /dev/null- 禁止输出: 有时,一些命令或脚本可能会产生不必要的输出,而你可能只关心命令的执行结果。在这种情况下,你可以将输出定向到 /dev/null。
some_command > /dev/null 2>&1这个例子中,2>&1 将标准错误(stderr)重定向到与标准输出(stdout)相同的位置,然后将标准输出重定向到 /dev/null。
总的来说,/dev/null 提供了一种方便的方法来处理输入或输出,使其对系统的影响最小。
TCP通用客户端
//tcpClient.cpp
#include <iostream>
#include <string>
#include <cstring>
#include <sys/types.h> /* See NOTES */
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
#include "err.hpp"
//因为没有进行模块分离所以没有tcpClient.hpp的头文件
using namespace std;
static void usage(std::string proc)
{
std::cout << "Usage:\n\t" << proc << " serverip serverport\n"
<< std::endl;
}
// ./tpc_client serverip serverport
int main(int argc, char *argv[])
{
// 准备工作
if(argc != 3)
{
usage(argv[0]);
exit(USAGE_ERR);
}
string serverip = argv[1];
uint16_t serverport = atoi(argv[2]);
// 1. create socket
int sock = socket(AF_INET, SOCK_STREAM, 0);
if(sock < 0)
{
cerr << "socket error : " << strerror(errno) << endl;
exit(SOCKET_ERR);
}
// 客户端要不要bind? 要
// 客户端要不要自己bind? 不要,因为client要让OS自动给用户进行bind,这里和udp一样
// 客户端要不要listen?不要 要不要accept?不需要,因为客户端永远都是连别人的
// 明确server是谁
struct sockaddr_in server;
memset(&server, 0, sizeof(server));
server.sin_family = AF_INET;
server.sin_port = htons(serverport);
inet_aton(serverip.c_str(), &(server.sin_addr));
// 2. connect -- 把客户端和服务器建立连接
int cnt = 5;
while(connect(sock, (struct sockaddr*)&server, sizeof(server)) != 0)
{
sleep(1);
cout << "正在给你尝试重连,重连次数还有: " << cnt-- << endl;
if(cnt <= 0) break;
}
if(cnt <= 0)
{
cerr << "连接失败..." << endl;
exit(CONNECT_ERR);
}
char buffer[1024];
// 3. 连接成功
while(true)
{
string line;
cout << "Enter>>> ";
getline(cin, line);
write(sock, line.c_str(), line.size());
ssize_t s = read(sock, buffer, sizeof(buffer)-1);
if(s > 0)
{
buffer[s] = 0;
cout << "server echo >>>" << buffer << endl;
}
else if(s == 0)
{
cerr << "server quit" << endl;
break;
}
else {
cerr << "read error: " << strerror(errno) << endl;
break;
}
}
close(sock);
return 0;
}TCP通用服务器
//tcpServer.cpp
#include "tcpServer.hpp"
#include "daemon.hpp"
#include <memory>
using namespace std;
using namespace ns_server;
static void usage(string proc)
{
std::cout << "Usage:\n\t" << proc << " port\n"
<< std::endl;
}
std::string echo(const std::string& message)
{
return message;
}
// ./tcp_server port
int main(int argc, char *argv[])
{
if(argc != 2)
{
usage(argv[0]);
exit(USAGE_ERR);
}
uint16_t port = atoi(argv[1]);
unique_ptr<TcpServer> tsvr(new TcpServer(echo, port));
tsvr->initServer();
//将服务器守护进程化
Daemon();
tsvr->start();
return 0;
}//tcpServer.hpp
#pragma once
#include <iostream>
#include <cstdlib>
#include <cstring>
#include <functional>
#include <sys/types.h> /* See NOTES */
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <signal.h>
#include <pthread.h>
#include "err.hpp"
#include "Thread.hpp"
#include "Task.hpp"
#include "ThreadPool.hpp"
#include "log.hpp"
namespace ns_server
{
static const uint16_t defaultport = 8081;
static const int backlog = 32; //? TODO
using func_t = std::function<std::string(const std::string &)>;
class TcpServer;//声明
class ThreadData
{
public:
ThreadData(int fd, const std::string &ip, const uint16_t &port, TcpServer *ts)
: sock(fd), clientip(ip), clientport(port), current(ts)
{}
public:
int sock;
std::string clientip;
uint16_t clientport;
TcpServer *current;
};
class TcpServer
{
public:
TcpServer(func_t func, uint16_t port = defaultport) : func_(func), port_(port), quit_(true)
{
}
void initServer()
{
// 1. 创建socket, 文件
listensock_ = socket(AF_INET, SOCK_STREAM, 0);//SOCK_STREAM:创建流套接字
if (listensock_ < 0)
{
// std::cerr << "create socket error" << std::endl;
logMessage(Fatal, "create socket error, code: %d, error string: %s", errno, strerror(errno));
exit(SOCKET_ERR);
}
// 2. bind
struct sockaddr_in local;
memset(&local, 0, sizeof(local));
local.sin_family = AF_INET;
local.sin_port = htons(port_);
local.sin_addr.s_addr = htonl(INADDR_ANY);
if (bind(listensock_, (struct sockaddr *)&local, sizeof(local)) < 0)
{
//std::cerr << "bind socket error" << std::endl;
logMessage(Fatal, "bind socket error, code: %d, error string: %s", errno, strerror(errno));
exit(BIND_ERR);
}
// 3. 监听
if (listen(listensock_, backlog) < 0)
{
//std::cerr << "listen socket error" << std::endl;
logMessage(Fatal, "listen socket error, code: %d, error string: %s", errno, strerror(errno));
exit(LISTEN_ERR);
}
}
void start()
{
//signal(SIGCHLD, SIG_IGN); //方法2:ok, 推荐的
// signal(SIGCHLD, handler); //方法3:还行,不太推荐
quit_ = false;
while (!quit_)
{
struct sockaddr_in client;
socklen_t len = sizeof(client);
// 4. 获取连接,accept
int sock = accept(listensock_, (struct sockaddr *)&client, &len);
if (sock < 0)
{
// std::cerr << "accept error" << std::endl;
logMessage(Warning, "accept error, code: %d, error string: %s", errno, strerror(errno));
continue;
}
// 提取client信息 -- debug
std::string clientip = inet_ntoa(client.sin_addr);
uint16_t clientport = ntohs(client.sin_port);
// 5. 获取新连接成功, 开始进行业务处理
logMessage(Info, "获取新连接成功: %d from %d, who: %s - %d",
sock, listensock_, clientip.c_str(), clientport);
// std::cout << "获取新连接成功: " << sock << " from " << listensock_ << ", "
// << clientip << "-" << clientport << std::endl;
// v1
//service(sock, clientip, clientport);//如果让服务器主进程和客户端进行通信,则无法和其他客户端建立连接,一次只能和一个客户端通信,所以有了以下其他版本
// //v2: 多进程版本
// pid_t id = fork();
// if (id < 0)
// {
// close(sock);
// continue;
// }
// else if (id == 0) // child, 父进程的fd,会被child继承吗?会。 父子会用同一张文件描述符表吗?不会,但是子进程拷贝继承父进程的fd table(表);
// {
// // 建议关闭掉不需要的fd
// close(listensock_);
// if(fork() > 0) exit(0); //方法4:就这一行代码,不太推荐,因为调用的fork太多了对系统有一定的要求,但是具有一定的设计意义,所以还是推荐方法2
// // child已经退了,孙子进程在运行。虽然方法父进程一样会被阻塞,但是不会被阻塞太久,因为子进程调用fork之后就开始退出了,没有进行其他的操作,剩下事前交给孙子进程
// //孙子进程的父进程先退出了,就变成了孤儿进程,所以孙子进程会被系统领养,由系统承担子进程的回收工作。
// service(sock, clientip, clientport);
// exit(0);
// }
// // 父, 一定关闭掉不需要的fd, 不关闭,会导致fd泄漏
// close(sock);
// pid_t ret = waitpid(id, nullptr, 0); //阻塞的! waitpid(id, nullptr, WNOHANG);//方法1:不推荐,因为 accept 是阻塞式调用!都没有新客户端的请求连接时就会进行阻塞导致
// //父进程就无法继续向后执行,当有子进程退出时就无法执行waitpid进行回收子进程
// if(ret == id) std::cout << "wait child " << id << " success" << std::endl;
// v3: 多线程 -- 原生多线程
// 1. 要不要关闭不要的socket??不能
// 2. 要不要回收线程?如何回收?会不会阻塞??
pthread_t tid;
ThreadData *td = new ThreadData(sock, clientip, clientport, this);
pthread_create(&tid, nullptr, threadRoutine, td);
// v4: v3版一旦用户来了,你才创建线程,这样效率是不是有点低?可以使用线程池来解决问题
// 使用线程池的时候,一定是有线的线程个数,一定是要处理短任务
Task t(sock, clientip, clientport, std::bind(&TcpServer::service, this, std::placeholders::_1, std::placeholders::_2, std::placeholders::_3));
ThreadPool<Task>::getinstance()->pushTask(t);
}
}
static void *threadRoutine(void *args)//类内线程的回调函数要设置为static,防止第一个参数被this指针占用
{
pthread_detach(pthread_self());//分离
ThreadData *td = static_cast<ThreadData *>(args);
td->current->service(td->sock, td->clientip, td->clientport);
delete td;
return nullptr;
}
void service(int sock, const std::string &clientip, const uint16_t &clientport)
{
std::string who = clientip + "-" + std::to_string(clientport);
char buffer[1024];
//v2
ssize_t s = read(sock, buffer, sizeof(buffer)-1);
if(s > 0)
{
buffer[s] = 0;
std::string res = func_(buffer);
std::cout << who << ">>>" << res << std::endl;
logMessage(Debug, "%s# %s", who.c_str(), res.c_str());
write(sock, res.c_str(), res.size());
}
else if(s == 0)
{
// 对方将连接关闭了
// std::cout << who << " quit, me too" << std::endl;
logMessage(Info, "%s quit,me too", who.c_str());
}
else
{
// std::cerr << "read error: " << strerror(errno) << std::endl;
logMessage(Error, "read error, %d:%s", errno, strerror(errno));
}
close(sock);
//v1
// while(true)
// {
// ssize_t s = read(sock, buffer, sizeof(buffer)-1);
// if(s > 0)
// {
// buffer[s] = 0;
// std::string res = func_(buffer);
// std::cout << who << ">>>" << res << std::endl;
// }
// else if(s == 0)
// {
// //对方将连接关闭了
// close(sock);
// std::cout << who << " quit, me too" << std::endl;
// break;
// }
// else
// {
// close(sock);
// std::cerr << "read error: " << strerror(errno) << std::endl;
// break;
// }
// }
}
~TcpServer()
{
}
private:
uint16_t port_;
int listensock_; // TODO
bool quit_;
func_t func_;
};
}其他相关头文件
//Makefile
.PHONY:all
all: tcp_client tcp_server
tcp_client:tcpClient.cc
g++ -o $@ $^ -std=c++11 -lpthread
tcp_server:tcpServer.cc
g++ -o $@ $^ -std=c++11 -lpthread
.PHONY:clean
clean:
rm -f tcp_client tcp_server//Task.hpp
#pragma once
#include <iostream>
#include <string>
#include <unistd.h>
#include <functional>
using cb_t = std::function<void(int , const std::string &, const uint16_t &)>;
class Task
{
public:
Task()
{
}
Task(int sock, const std::string &ip, const uint16_t &port, cb_t cb)
: _sock(sock), _ip(ip), _port(port), _cb(cb)
{}
void operator()()
{
_cb(_sock, _ip, _port);
}
~Task()
{
}
private:
int _sock;
std::string _ip;
uint16_t _port;
cb_t _cb;
};//Thread.hpp
#pragma once
#include <iostream>
#include <string>
#include <cstdlib>
#include <pthread.h>
#include <unistd.h>
using namespace std;
class Thread
{
public:
typedef enum
{
NEW = 0,
RUNNING,
EXITED
} ThreadStatus;
typedef void (*func_t)(void*);
public:
Thread(int num, func_t func, void *args) : _tid(0), _status(NEW), _func(func), _args(args)
{
char name[128];
snprintf(name, sizeof(name), "thread-%d", num);
_name = name;
}
int status() { return _status; }//获取线程状态
std::string threadname() { return _name; }//获取线程名字
pthread_t threadid()//获取线程ID
{
if (_status == RUNNING)
return _tid;
else
{
return 0;
}
}
// runHelper是不是类的成员函数,而类的成员函数,具有默认参数this,需要static
// 但是会有新的问题:static成员函数,无法直接访问类属性和其他成员函数
static void *runHelper(void *args)
{
Thread *ts = (Thread*)args; // 就拿到了当前对象
// _func(_args);
(*ts)();
return nullptr;
}
void operator ()() //仿函数
{
if(_func != nullptr)
_func(_args);
}
void run()
{
int n = pthread_create(&_tid, nullptr, runHelper, this);
if(n != 0) exit(1);
_status = RUNNING;
}
void join()
{
int n = pthread_join(_tid, nullptr);
if( n != 0)
{
std::cerr << "main thread join thread " << _name << " error" << std::endl;
return;
}
_status = EXITED;
}
~Thread()
{}
private:
pthread_t _tid;
std::string _name;
func_t _func; // 线程未来要执行的回调
void* _args;
ThreadStatus _status;
};//ThreadPool.hpp
#pragma once
#include <iostream>
#include <string>
#include <vector>
#include <queue>
#include <unistd.h>
#include "Thread.hpp"
#include "Task.hpp"
#include "lockGuard.hpp"
#include "log.hpp"
const static int N = 5;
//单例版的线程池
template <class T>
class ThreadPool
{
private:
ThreadPool(int num = N) : _num(num)
{
pthread_mutex_init(&_lock, nullptr);
pthread_cond_init(&_cond, nullptr);
}
ThreadPool(const ThreadPool<T> &tp) = delete;
void operator=(const ThreadPool<T> &tp) = delete;
public:
static ThreadPool<T> *getinstance()
{
if(nullptr == instance) // 为什么要这样?提高效率,减少加锁的次数!
{
LockGuard lockguard(&instance_lock);
if (nullptr == instance)
{
logMessage(Debug, "线程池单例形成");
instance = new ThreadPool<T>();
instance->init();
instance->start();
}
}
return instance;
}
pthread_mutex_t *getlock()
{
return &_lock;
}
void threadWait()
{
pthread_cond_wait(&_cond, &_lock);
}
void threadWakeup()
{
pthread_cond_signal(&_cond);
}
bool isEmpty()
{
return _tasks.empty();
}
T popTask()
{
T t = _tasks.front();
_tasks.pop();
return t;
}
static void threadRoutine(void *args)
{
// pthread_detach(pthread_self());
ThreadPool<T> *tp = static_cast<ThreadPool<T> *>(args);
while (true)
{
// 1. 检测有没有任务
// 2. 有:处理
// 3. 无:等待
// 细节:必定加锁
T t;
{
LockGuard lockguard(tp->getlock());
while (tp->isEmpty())
{
tp->threadWait();
}
t = tp->popTask(); // 从公共区域拿到私有区域
}
// for test
t();
}
}
void init()
{
for (int i = 0; i < _num; i++)
{
_threads.push_back(Thread(i, threadRoutine, this));
logMessage(Debug, "%d thread running", i);
}
}
void start()
{
for (auto &t : _threads)
{
t.run();
}
}
void check()
{
for (auto &t : _threads)
{
std::cout << t.threadname() << " running..." << std::endl;
}
}
void pushTask(const T &t)
{
LockGuard lockgrard(&_lock);
_tasks.push(t);
threadWakeup();
}
~ThreadPool()
{
for (auto &t : _threads)
{
t.join();
}
pthread_mutex_destroy(&_lock);
pthread_cond_destroy(&_cond);
}
private:
std::vector<Thread> _threads;
int _num;
std::queue<T> _tasks; // 使用stl的自动扩容的特性
pthread_mutex_t _lock;
pthread_cond_t _cond;
static ThreadPool<T> *instance;
static pthread_mutex_t instance_lock;
};
template <class T>
ThreadPool<T> *ThreadPool<T>::instance = nullptr;
template <class T>
pthread_mutex_t ThreadPool<T>::instance_lock = PTHREAD_MUTEX_INITIALIZER;//daemon.hpp
#pragma once
// 1. setsid();
// 2. setsid(), 调用进程,不能是组长!我们怎么保证自己不是组长呢?
// 3. 守护进程a. 忽略异常信号 b. 0,1,2要做特殊处理 c. 进程的工作路径可能要更改 /
#include <cstdlib>
#include <unistd.h>
#include <signal.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include "log.hpp"
#include "err.hpp"
//守护进程的本质:是孤儿进程的一种!也就是父进程先退出,子进程被领养 -- 创建守护进程
void Daemon()//自己实现一个Daemon函数,不调用库里的daemon函数来创建守护进程
{
// 1. 忽略信号
signal(SIGPIPE, SIG_IGN);
signal(SIGCHLD, SIG_IGN);
// 2. 让自己不要成为组长
if (fork() > 0)
exit(0);
// 3. 新建会话,自己成为会话的话首进程
pid_t ret = setsid();
if ((int)ret == -1)
{
logMessage(Fatal, "deamon error, code: %d, string: %s", errno, strerror(errno));
exit(SETSID_ERR);
}
// 4. 可选:可以更改守护进程的工作路径
// chdir("/")
// 5. 处理后续的对于0,1,2的问题
int fd = open("/dev/null", O_RDWR);
if (fd < 0)
{
logMessage(Fatal, "open error, code: %d, string: %s", errno, strerror(errno));
exit(OPEN_ERR);
}
dup2(fd, 0);
dup2(fd, 1);
dup2(fd, 2);
close(fd);
}//err.hpp
#pragma once
enum
{
USAGE_ERR = 1,
SOCKET_ERR,
BIND_ERR,
LISTEN_ERR,
CONNECT_ERR,
SETSID_ERR,
OPEN_ERR
};//lockGuard.hpp
#pragma once
#include <iostream>
#include <pthread.h>
class Mutex // 自己不维护锁,有外部传入
{
public:
Mutex(pthread_mutex_t *mutex):_pmutex(mutex)
{}
void lock()
{
pthread_mutex_lock(_pmutex);//加锁
}
void unlock()
{
pthread_mutex_unlock(_pmutex);//解锁
}
~Mutex()
{}
private:
pthread_mutex_t *_pmutex;
};
class LockGuard // 自己不维护锁,有外部传入
{
public:
LockGuard(pthread_mutex_t *mutex):_mutex(mutex)
{
_mutex.lock();//通过构造函数自动加锁,防止忘记加锁
}
~LockGuard()
{
_mutex.unlock();//通过析构函数自动解锁,防止忘记解锁
}
private:
Mutex _mutex;
};//log.hpp
#pragma once
#include <iostream>
#include <string>
#include <cstdio>
#include <cstring>
#include <ctime>
#include <cstdarg>
#include <sys/types.h>
#include <unistd.h>
//日志的实现本质就是把输出的错误描述,输出到指定的文件里,方便日后查看
// 日志是有日志等级的
const std::string filename = "log/tcpserver.log";
enum
{
Debug = 0,
Info,
Warning,
Error,
Fatal,
Uknown
};
static std::string toLevelString(int level)
{
switch (level)
{
case Debug:
return "Debug";
case Info:
return "Info";
case Warning:
return "Warning";
case Error:
return "Error";
case Fatal:
return "Fatal";
default:
return "Uknown";
}
}
static std::string getTime()
{
time_t curr = time(nullptr);
struct tm *tmp = localtime(&curr);
char buffer[128];
snprintf(buffer, sizeof(buffer), "%d-%d-%d %d:%d:%d", tmp->tm_year + 1900, tmp->tm_mon+1, tmp->tm_mday,
tmp->tm_hour, tmp->tm_min, tmp->tm_sec);
return buffer;
}
// 日志格式: 日志等级 时间 pid 消息体
// logMessage(DEBUG, "hello: %d, %s", 12, s.c_str()); // DEBUG hello:12, world
void logMessage(int level, const char *format, ...)
{
char logLeft[1024];
std::string level_string = toLevelString(level);
std::string curr_time = getTime();
snprintf(logLeft, sizeof(logLeft), "[%s] [%s] [%d] ", level_string.c_str(), curr_time.c_str(), getpid());
char logRight[1024];
va_list p;
va_start(p, format);
vsnprintf(logRight, sizeof(logRight), format, p);
va_end(p);
// 打印
// printf("%s%s\n", logLeft, logRight);
// 保存到文件中
FILE *fp = fopen(filename.c_str(), "a");//a:追加
if(fp == nullptr)return;
fprintf(fp,"%s%s\n", logLeft, logRight);
fflush(fp); //可写也可以不写
fclose(fp);
// 预备 -- 可变参数列表原理
// va_list p; // char *
// int a = va_arg(p, int); // 根据类型提取参数
// va_start(p, format); //p指向可变参数部分的起始地址
// va_end(p); // p = NULL;
}TCP协议通讯流程
下图是基于TCP协议的客户端/服务器程序的一般流程:
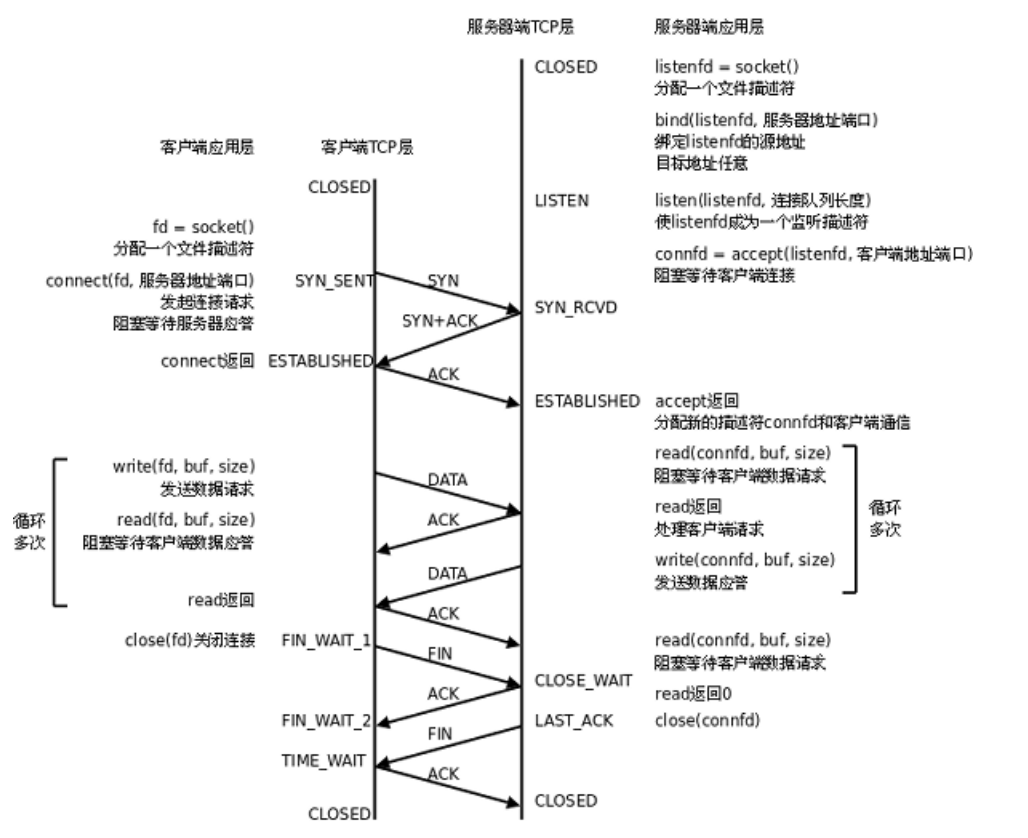
服务器初始化:
调用socket, 创建文件描述符;
调用bind, 将当前的文件描述符和ip/port绑定在一起; 如果这个端口已经被其他进程占用了, 就会bind失败;
调用listen, 声明当前这个文件描述符作为一个服务器的文件描述符, 为后面的accept做好准备;
调用accecpt, 并阻塞, 等待客户端连接过来;
建立连接的过程:
调用socket, 创建文件描述符;
调用connect, 向服务器发起连接请求;
connect会发出SYN段并阻塞等待服务器应答; (第一次)
服务器收到客户端的SYN, 会应答一个SYN-ACK段表示"同意建立连接"; (第二次)
客户端收到SYN-ACK后会从connect()返回, 同时应答一个ACK段; (第三次)
这个建立连接的过程, 通常称为 三次握手;
数据传输的过程:
建立连接后,TCP协议提供全双工的通信服务; 所谓全双工的意思是, 在同一条连接中, 同一时刻, 通信双方可以同时写数据; 相对的概念叫做半双工, 同一条连接在同一时刻, 只能由一方来写数据;
服务器从accept()返回后立刻调 用read(), 读socket就像读管道一样, 如果没有数据到达就阻塞待;
这时客户端调用write()发送请求给服务器, 服务器收到后从read()返回,对客户端的请求进行处理, 在此期间客户端调用read()阻塞等待服务器的应答;
服务器调用write()将处理结果发回给客户端, 再次调用read()阻塞等待下一条请求;
客户端收到后从read()返回, 发送下一条请求,如此循环下去;
断开连接的过程:
如果客户端没有更多的请求了, 就调用close()关闭连接, 客户端会向服务器发送FIN段(第一次);
此时服务器收到FIN后, 会回应一个ACK, 同时read会返回0 (第二次);
read返回之后, 服务器就知道客户端关闭了连接, 也调用close关闭连接, 这个时候服务器会向客户端发送一个FIN; (第三次)
客户端收到FIN, 再返回一个ACK给服务器; (第四次)
这个断开连接的过程, 通常称为 四次挥手
在学习socket API时要注意应用程序和TCP协议层是如何交互的:
应用程序调用某个socket函数时TCP协议层完成什么动作,比如调用connect()会发出SYN段
应用程序如何知道TCP协议层的状态变化,比如从某个阻塞的socket函数返回就表明TCP协议收到了某些段,再比如read()返回0就表明收到了FIN段。
1. connect() 调用:
- 当应用程序调用 connect() 时,TCP协议层会完成以下动作:
-
- 发送一个 SYN(同步)段给服务器,表示建立连接的请求。
- 进入连接建立的过程,等待服务器的响应。
2. 阻塞的 socket 函数:
- 在阻塞的 socket 函数中,如 connect() 或 recv(),应用程序在调用这些函数时可能会阻塞(暂停执行)等待某些条件的发生。
- 对于 connect(),阻塞表示等待三次握手完成,即等待连接建立成功或失败。
- 对于 recv(),阻塞可能表示等待数据的到达,直到有数据可读或发生了错误。
3. read() 返回 0:
- 当 read() 函数返回 0 时,这通常表示接收到了一个 FIN(结束)段,表明对端关闭了连接。
- 这也可能是在非阻塞套接字上,没有可用的数据时返回的,表示当前没有数据可读。
4. 应用程序如何知道 TCP 协议层的状态变化:
- 对于连接建立,应用程序可以使用 select()、poll() 或非阻塞的 connect() 来检测套接字的可写性,以知道连接建立成功。
- 对于数据的到达,应用程序可以使用 select()、poll() 或阻塞的 recv() 来等待数据的可读性。
- 应用程序可以通过检查套接字的状态或使用异步 I/O 操作来感知状态变化,这有赖于所采用的编程模型(同步、异步、阻塞、非阻塞等)。
TCP 和 UDP 对比:
可靠传输 vs 不可靠传输
有连接 vs 无连接
字节流 vs 数据报















 1724
1724











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









