






目录
内联函数:
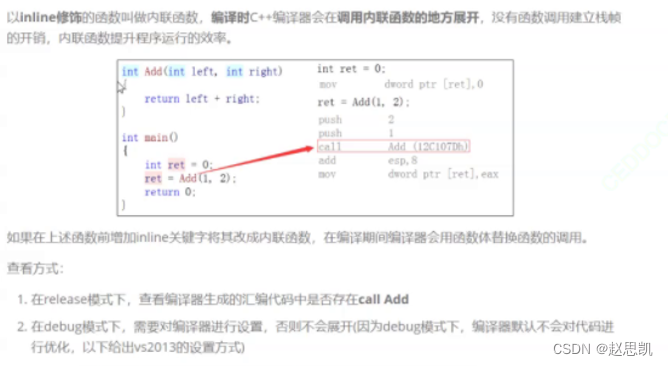
我们先写一串简单的代码:
#include<iostream>
using namespace std;
int Add(int a, int b)
{
return a + b;
}
int main()
{
int a = 5, b = 3;
int ret = Add(a,b);
return 0;
}我们调试看他们内部的汇编代码:
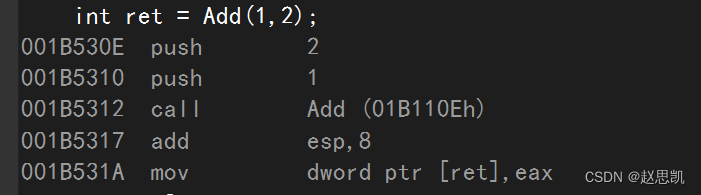
我们发现,我们调用了函数,call就是调用函数的意思。
函数调用会开辟栈帧,大量的栈帧就会影响程序的运行效率,例如:当我们使用排序函数时,可能要多次大量的调用Swap交换函数,那么就会造成程序的运行效率降低。
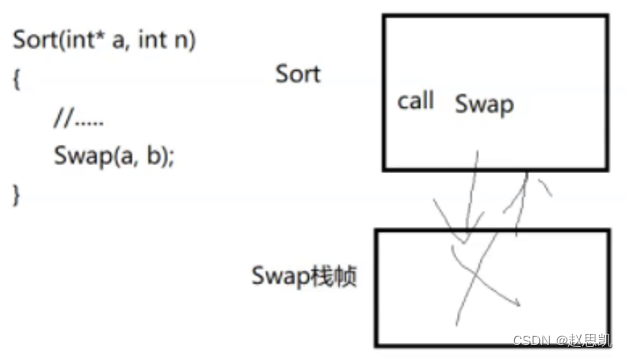
我们有没有一种方法既能够实现函数的使用,又能够不开辟栈帧来提高运行效率呢?
我们以前有过一种方法,那就是使用宏函数。
宏函数:
我们知道,宏函数和宏定义这些,都是在预处理阶段就发生了替换,所以就不需要调用函数了。
我们先写一个宏函数Add:
#define Add(a,b) ((a)+(b));宏函数相较于函数调用的确能够省去栈帧的开辟,那么宏函数的缺点又是什么呢?
缺点1:不能调试:
宏函数在调用的时候,发生的是替换,这里表示的就是把Add函数替换成((a)+(b)).所以无法进行调试:
缺点2:没有类型安全检查
例如:假如我们把Add函数写成这样也不会检查报错:
#define Add(a,b) ((3.14)+(2.56));我们进行编译:
缺点3:容易写错:
宏函数有许多不同的“版本”:
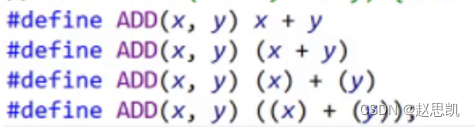
我们逐个分析他们错误的原因:
第一个:
假如我们把main函数写成这样时:
int main()
{
int ret = 2*Add(1,2);
return 0;
}我们原来计算的结果为2*3=6.
我们实际计算出来的结果是:2*1+2=4
第二个:
假如我们把main函数写成这样:
int main()
{
int ret = Add(a|b, a&b);
return 0;
}我们原来计算的结果是a按位或b再加上a按位与b
因为加号比|和&的优先级高,我们计算的结果就为:a|(b+a)&b
第三个:
int main()
{
int ret = 2*Add(1,2);
return 0;
}第三个和第一个是同理。
宏定义还有一个容易写错的点就是宏定义的尾部不能加分号。
例如:
#define Add(a,b) ((a)+(b));
int main()
{
int ret = Add(1, 2);
if (Add(1, 2))
{
return;
}
return 0;
}因为宏定义是全部替换,所以假如我们把分号也上去的话,分号也会发生替换,就会造成语法错误。
宏定义有如此多的缺点,那我们有没有别的方法进行解决:
内联函数:
对于普通的Add函数,我们用内联函数的写法可以这样写:
inline int Add(int a, int b)
{
return a + b;
}
int main()
{
int ret = Add(1, 2);
cout << ret << endl;
return 0;
}我们进行调试:
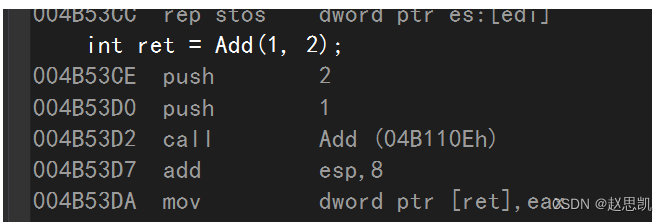
发现函数并没有展开,还是被调用了,原因是什么?
答:因为debug版本下支持调试,但是假如我们展开了函数,就没有办法进行调试了,这个是编译器的默认属性,我们可以在编译器属性中进行修改:
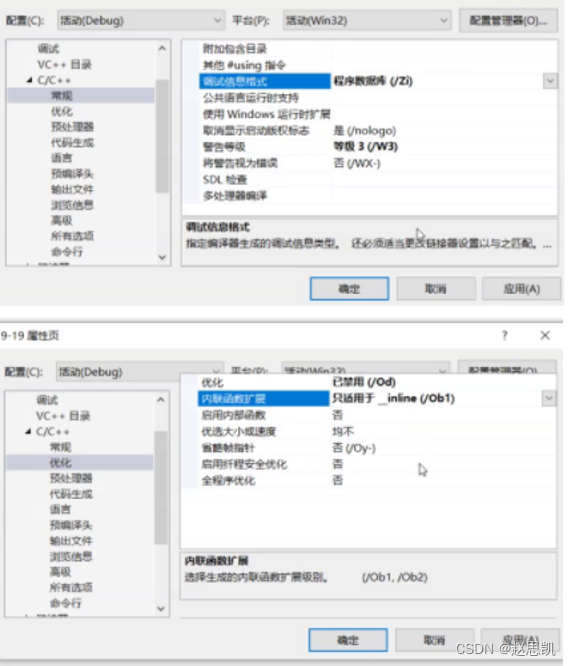
我们修改之后,再次进行调试看汇编代码:
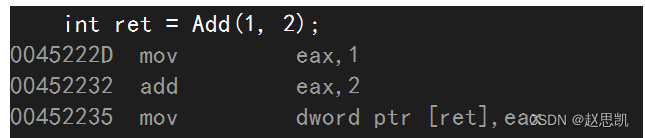
这时候,我们没有了call,证明了我们的函数已经被展开了。
大多数时候,我们可以用inline const enum来替代宏。
内联函数的特性:

我们对特性进行分析:
1: 因为我们对函数的代码进行了展开,所以就会导致代码变多,影响的是可执行程序,也就是安装包会变大。
2:使用内联函数与否不是由代码编写者决定的,是由编译器决定的,因为代码编写者并不能准确判断使用内联函数的时机。例如:当函数的代码庞大时,我们就极可能避免使用内联函数。亦或者当函数递归时,我们也要避免使用内联函数。并且内联函数的使用也要求频繁调用,否则内联函数也不大实用。
3:不建议申明和分析
我们写一个代码进行分析:
inline int Add(int x, int y)
{
return x + y;
}
inline int func(int x, int y)
{
int ret = x + y;
ret = x + y;
ret = x + y;
ret = x + y;
ret = x + y;
ret = x + y;
ret = x + y;
ret = x + y;
ret = x + y;
ret = x + y;
ret -= x + y;
ret *= x + y;
}
int main()
{
int ret = Add(1, 3);
cout << ret << endl;
ret = func(10, 20);
cout << ret << endl;
}
我们进行编译,查看他们的汇编代码:
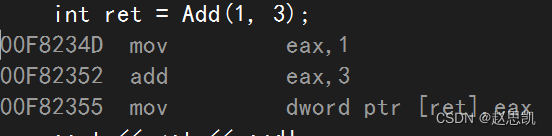
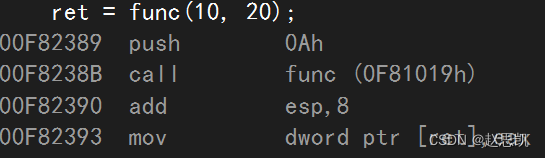
我们可以发现Add函数展开了,而func函数并没有展开。
因为Add函数的函数规模较小,而func的函数规模较大。
为什么代码长了不会展开
答:代码膨胀:
例如,假如我们有一个func函数,func的代码是30行,我们调用它10000次,当我们使用内联函数时:
我们就会产生300000行代码,浪费空间。
假如我们有一个func函数,func的代码是30行,我们调用它10000次,当我们不使用内联函数时:
我们会大约产生10000+30=10030行代码。
inline函数为什么不支持声明和定义分离?
答:我们这里就需要设计一些编译和链接部分的知识,链接部分设计符号表的合并和重定义,合并的意思就是把函数和他的地址进行合并,其中,无论是声明还是定义,都会产生函数的地址。
重定义的意思就是我们要进行筛选,把无效的地址(声明)进行删除,把定义的地址与函数的地址进行匹配。
但是,假如我们的inline函数声明和定义分离时,因为我们定义的inline函数会展开,所以并不能够产生自己的函数地址,但是我们的声明函数却能够产生对应的地址,因为我们的定义函数的地址的缺失导致我们最后重定义时,我们把声明函数的地址与函数的地址进行匹配,所以就产生了错我。
正确的写法就是我们把声明和定义放在同一块,这样就不会产生声明的地址,就不会产生错误了。
类和对象:
typeid:可以把对应的变量的类型打印出来
int main()
{
int a = 10;
auto b = a;
auto c = 'a';
auto d = 1.33;
cout << typeid(b).name() << endl;
cout << typeid(c).name() << endl;
cout << typeid(d).name() << endl;
}我们进行编译:
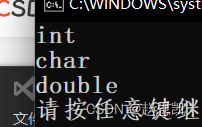
auto:取参数类型
我们再写一串代码:
int main()
{
int x = 10;
auto a = &x;
auto*b = &x;
auto&c = x;
cout << typeid(a).name() << endl;
cout << typeid(b).name() << endl;
cout << typeid(c).name() << endl;
return 0;
}打印的结果是什么?
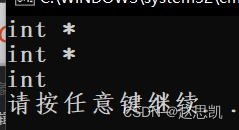
我们进行分析:
1:
auto a = &x;auto的作用是取参数类型,a的参数类型就应该和&x一样,x的类型是整型,&x的类型是int*,所以第一个打印的结果是int*。
2:
auto*b = &x;auto*首先表示b是一个指针,b的类型和x相同,所以b的类型是int*
3:
auto&c = x;auto&表示c是x的引用,所以c的类型和x一样,所以c的类型是int
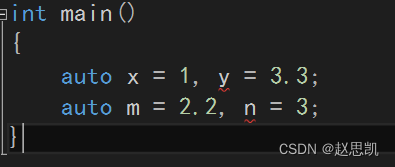
当auto在同一行定义多个变量时:
int main()
{
auto x = 1, y = 2;
auto m = 2.2, n = 3.3;
}同一行的变量类型要相同,不能这样写:
auto不能作为函数的参数:
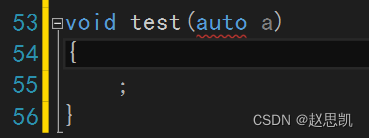
原因是在这里auto对应的类型是不明确的,我们在函数栈帧开辟之前需要对函数内部的参数的类型数量进行统计,以便我们开辟适应大小的空间。
auto不能用来声明数组:
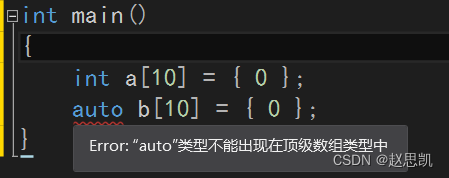
auto的for循环:
int main()
{
int a[5] = { 1, 2, 3, 4, 5 };
for (auto e : a)
{
e *= 2;
}
for (auto e : a)
{
cout << e <<" " ;
}
cout << endl;
return 0;
}这里for循环,我们可以这样思考:我们一次把数组a的元素赋给e。
所以这个循环中e*=2的结果是不会影响数组元素的,原因是我们是把数组元素赋值给e,所以e本身的改变并不会影响数组a中的元素发生改变。
我们打印的结果还是1,2,3,4,5;

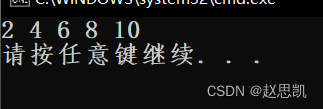
我们如果想要实现把数组的元素全部扩大二倍,我们可以采用引用的方法:
int main()
{
int a[5] = { 1, 2, 3, 4, 5 };
for (auto&e : a)
{
e *= 2;
}
for (auto e : a)
{
cout << e <<" " ;
}
cout << endl;
return 0;
}原因是:我们的e相当于就是a的别名,所以变量e和a的地址都相同,我们对变量e修改也会造成a的改变。
易错问题:
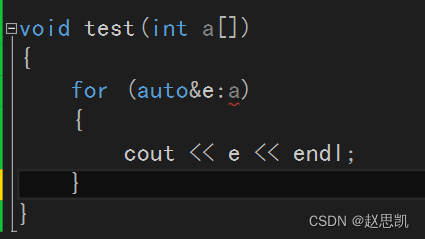
例如这个函数:注意,这里传递的a并不是a的数组,而是a的数组名,也就是数组首元素的地址,所以我们是无法通过auto的for循环实现遍历的。
c++的bug

在c++的环境中,我们把NULL替换成了1,这时候就导致一些问题,我们举一个例子
void func(int a)
{
cout << "int a" << endl;
}
void func(int*a)
{
cout << "int*a" << endl;
}
int main()
{
func(0);
func(NULL);
}两个函数函数名相同,类型不同,并且在同一个域中,构成函数重载。
我们根据他们的参数进行调用,func(0)表示调用的是第一个参数,打印出来的结果就应该是int a
func(int*a)表示调用的是第二个参数,打印出来的结果就应该是int *a。
我们进行编译:
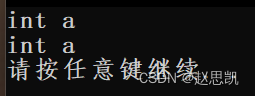
为什么打印的结果都是int a呢?
原因是这样:因为我们是c++的环境,所以我们的NULL在预处理时被替换成了0,所以我们调用的实际参数是0,所以我们都指挥调用第一个函数,所以打印的结果都是int a。
解决措施:
c++引入了nullptr来解决问题:
nullptr对应的值就是:
void*(0)表示把0强制类型转化为无类型指针。
nullptr需要注意的问题:
1:在使用nullptr作为指针空值时,我们不需要包含任何头文件,因为nullptr是c++11引入的关键字。
2:在c++11中,sizeof(nullptr)和sizeof(void*(0))所占的空间相同。
3:为了提高代码的健壮性,在后续使用指针空值,一律使用nullptr。
面向对像
c语言是面向过程的,关注的是解决问题的过程,分析出解决问题的步骤,通过函数调用逐步解决问题。
c++是面向对象的,关注的是对象,把一件事拆分成不同的对象,靠对象之间的交互完成。
struct的升级:
1:兼容c语言中struct的所有用法
2:升级成了类。
接下来,我们用c++的struct来写一个栈
typedef int DataType;
struct Stack
{
void Init(size_t capacity)
{
_array = (DataType*)malloc(sizeof(DataType)*capacity);
if (nullptr == _array)
{
perror("malloc申请空间失败");
return;
}
_capacity = capacity;
_size = 0;
}
void Push(const DataType&data)
{
_array[_size] = data;
++_size;
}
DataType*_array;
size_t _capacity;
size_t _size;
};
int main()
{
Stack s;
s.Init(10);
s.Push(1);
s.Push(2);
s.Push(3);
cout << s._size << endl;
s.Destroy();
}大体的写法就是这样,我们对比一下普通的c语言,分析出使用类定义的好处
1:在c++中,我们的栈的成员函数和成员变量的创建是在一起的。
2:在c++中,我们对栈进行了定义,假如我们要创建一个栈对象,我们直接这样写就对了:
Stack s;而在c语言,我们需要这样写:
struct Stack s;3:在c++中,我们的函数的参数不需要成员参数本身,因为成员参数本身在类中是可以被使用的。
例如,在c++中,我们写栈的初始化:
void Init(size_t capacity)在c语言中,我们写栈的初始化:
void StackInit(DataType*_array,size_t capacity)c++中,类的内部是可以相互寻找的
例如:
struct ListNode
{
ListNode*next;
};假如在c语言中,我们只能在结构体的外边定义这个指针,并且写法必须是这样:
struct ListNode*next;类的定义:
class classname
{
};class是定义类的关键字,classname是类的名字,class内部内容叫做类的成员。
类中的变量叫做类的属性或者又叫做成员变量。类中的函数叫做类的方法或者又叫做成员函数。
类的访问限定符:

1:public修饰的成员变量在类外可以直接访问,所以的成员变量都可以在类内互相访问。
2:protect和private变量在类外不能被直接访问,在类内可以被互相访问。
3:访问权限作用域就是从访问限定符出现到下一个访问限定符出现或者到达类边界。
5:class的默认访问权限是private,struct的默认访问权限是public(因为struct要兼容c,c中struct就是共用的,所以c++也默认为共有的了)。
例如:
class Stack
{
public:
void Init(int N = 4)
{
//...
}
void Push(int x)
{
//...
}
private:
int*a;
int top;
public:
int capacity;
};
int main()
{
Stack st;
st.Init();
st.top;
}由代码可知,a和top在类外面是不可以直接访问的。
我们进行编译:

我们写一个问题:
class Stack
{
public:
void Push(int x)
{
//...
}
void Init(int N=4)
{
top = 0;
capacity = 0;
}
private:
int*a;
int top;
int capacity;
};
int main()
{
Stack::a = 0;
}
为什么这里的a是不可以被访问的。
答: 因为我们的类是声明,声明是不开辟空间的,既然没有开辟空间就不能直接访问
声明和定义分离的意义:
主要的作用是方便阅读,例如假如我们要写一个栈并使用,我们可以这样排布:
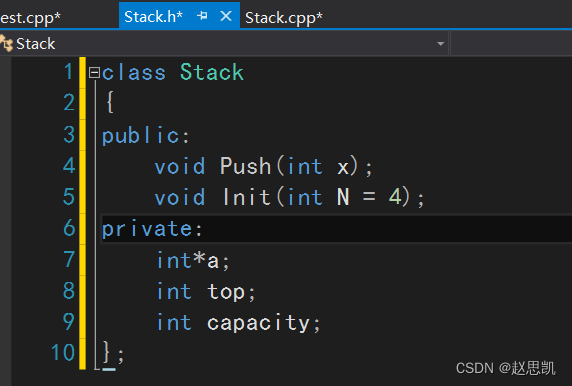
在头文件中,定义类,声明函数和对象。
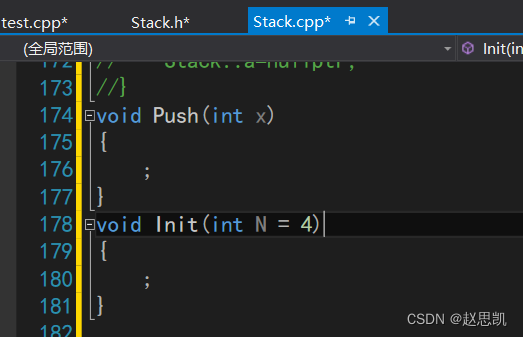
在源文件中写函数的定义
在测试代码中进行测试。
这样写非常清晰,便于读者进行阅读。
假如我们定义了两个类,第一个类是栈,第二个类是队列,并且我们在两个类中都声明了函数Push和Init,我们在定义的时候该如何区分呢?
class Stack
{
public:
void Push(int x);
void Init(int N = 4);
private:
int*a;
int top;
int capacity;
};
class Queue
{
public:
void Init();
void Push(int x);
private:
//...
};许多人这里构成了函数重载,但是并不满足函数重载的一个条件。
函数重载:两个在相同的域,函数名相同,参数不同的函数就构成函数重载。
我们可以这样区分:
#include"Stack.h"
void Stack::Push(int x)
{
;
}
void Stack::Init(int N )
{
;
}
void Queue::Init()
{
;
}
void Queue::Push(int x)
{
;
}
这样写就可以避免出现两义性的情况。
总结:类就像图纸,类本身并不会定义对象,根据类的结构来定义的对象就叫做实例化对象。
成员变量的正确写法:
我们可以发现,现在很多代码的成员变量都会前置一个"_",原因是什么呢?
例如:
class Date
{
public:
void Init(int year, int month, int day)
{
year = year;
month = month;
day = day;
}
private:
int year;
int month;
int day;
};
int main()
{
Date a;
a.Init(2001, 10, 1);
}我们定义了一个类,假如我们不加"_",我们可以发现,我们无法区分三个成员变量和三个临时参数。
所以我们可以这样写进行区分:
class Date
{
public:
void Init(int year, int month, int day)
{
_year = year;
_month = month;
_day = day;
}
private:
int _year;
int _month;
int _day;
};















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









