






目录
引用:

#include<iostream>
using namespace std;
int main()
{
int a = 10;
int&ra = a;
printf("%p\n", a);
printf("%p\n", ra);
return 0;
}
所以:引用并不会创建额外空间,本质上是对所修饰变量的别名,相当于:
引用特性

特性1:
int main()
{
int a = 10;
int &ra;
a = ra;
return 0;
}
特性2:
int main()
{
int a = 10;
int &ra = a;
int&rb = a;
return 0;
}引用的价值
void Swap(int&a, int&b)
{
int tmp = a;
a = b;
b = tmp;
}引用可以作为输出型参数,和指针的作用类似。
引用还可以作为返回值来使用:
int&Count()
{
static int n = 0;
n++;
return n;
}这样理解:相当于把n的别名传引用返回。
理解传引用返回:
要理解传引用返回,先理解传值返回。
int Count()
{
static int n = 0;
n++;
return n;
}
int main()
{
int ret=Count();
return 0;
}用一个简图来解释:
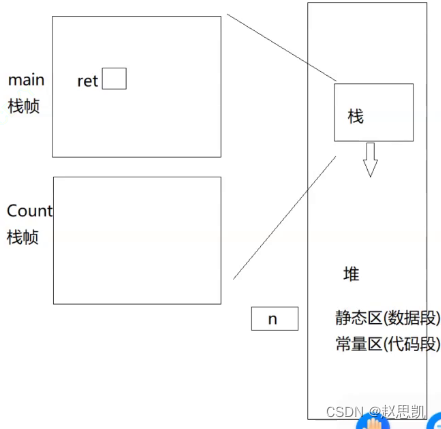
首先调用main函数,形成main函数的栈帧,栈帧中有一个变量ret。
接下来调用Count 函数,Count函数形成栈帧,参数n虽然在Count函数内部,但是有static修饰,所以n是静态变量,不会随函数调用结束而销毁。
Count函数返回的过程是一个传值返回,把n的值进行拷贝,存储在寄存器或者上一个函数栈帧(main函数)中,这个变量就叫做临时变量,再把临时变量赋给ret。
为什么必须要用传值返回:
int Count()
{
int n = 0;
n++;
return n;
}
int main()
{
int ret = Count();
return 0;
}假设我们没有传值返回:调用Count函数,用ret接受返回值n,这时候Count函数已经调用完毕,参数n值被释放,释放之后我们再对对应位置访问就是越界访问。
假设我们有传值返回:在调用Count函数进行返回时,首先用一个临时变量拷贝n的值,然后栈帧释放,n值销毁,我们再把临时变量赋给ret,就不会产生越界访问了。
传引用返回:
int& Count()
{
int n = 0;
n++;
return n;
}
int main()
{
int ret = Count();
cout << ret << endl;
cout << ret << endl;
cout << ret << endl;
return 0;
}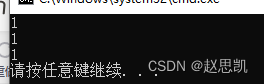
并没有报错,ret的值也没有问题,分析具体的步骤:
因为我们在Count函数中传引用返回,在返回时,我们用一个临时变量接受n,这里的临时变量就等于n的别名了,然后Count函数调用结束,n值销毁,我们再访问n就是越界了,这里没有越界的原因:我们用ret接收Count的返回值,这个过程也是传值,所以我们的ret和Count函数中的n指向的并不是同一块空间。
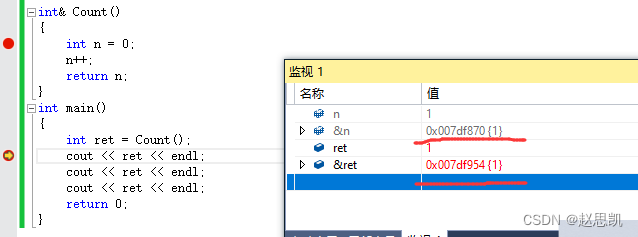
传引用返回的第二种情况:
int& Count()
{
int n = 0;
n++;
return n;
}
int main()
{
int& ret = Count();
cout << ret << endl;
cout << ret << endl;
cout << ret << endl;
return 0;
}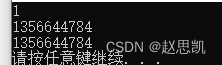
这里和上一段代码的不同点在于我们使用了两个引用,首先在Count函数中用引用接收到了n的别名,又传引用给了ret,那么ret现在就是Count函数中的n,我们进行访问就会越界。
为什么这里会出现1?
答: 虽然对应的n的空间已经销毁,我们调用cout函数,因为cout函数也是只有一个参数,ret就和原来属于n的空间重合了,我们打印就是n值。
总结:
出了函数作用域,返回变量不存在了,就不能用传引用返回,因为传引用返回的结果是未定义的。
除了函数作用域,返回变量还存在,就可以用传引用返回。
争取的写法:
int Count1()
{
int a = 0;
a++;
return a;
}
int&Count2()
{
static int a = 0;
a++;
return a;
}
int main()
{
int ret1 = Count1();
int ret2 = Count2();
cout << ret1 << "," << ret2 << endl;
return 0;
}对于静态变量作为返回值,我们可以用传引用返回,因为静态变量不随函数的调用结束而销毁。
引用的作用:
传引用返回:
作用:可以提高效率,减少拷贝。
#include<time.h>
struct A{
int a[10000];
};
A a;
A TestFunc1()
{
return a;
}
A& TestFunc2()
{
return a;
}
void TestReturnByRefOrValue()
{
size_t begin1 = clock();
for (size_t i = 0; i < 100000; i++)
{
TestFunc1();
}
size_t end1 = clock();
size_t begin2 = clock();
for (size_t i = 0; i < 100000; i++)
{
TestFunc2();
}
size_t end2 = clock();
cout << "TestFunc1 time:" << end1 - begin1 << endl;
cout << "TestFunc2 time:" << end2 - begin2 << endl;
}
int main()
{
TestReturnByRefOrValue();
return 0;
}我们写了一个结构体,一个这样的结构体所占的空间是40000个字节。
函数1和函数2的返回值都是该结构体类型,函数1会发生拷贝,函数2因为是传引用返回,我们分别调用两个函数100000次,看他们花费的时间。

可以看到,传值返回和传引用返回的效率差了70倍,所以传引用返回可以减少拷贝,提高效率。
引用做参数的作用:
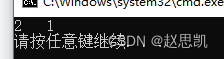
作用1:输出型参数,在函数中修改形参,实参也跟着改变:
void Swap1(int& left, int& right)
{
int temp = left;
left = right;
right = temp;
}
//void Swap2(int left, int right)
//{
// int temp = left;
// left = right;
// right = temp;
//}
int main()
{
int a = 1, b = 2;
/*Swap2(a, b);
cout << a << " " << b << endl;*/
Swap1(a, b);
cout << a << " " << b << endl;
return 0;
}
作用2:减少拷贝,提高效率:
指针和引用的权限大小问题:
int main()
{
int a = 0;
int&ra = a;
const int b = 1;
int&rb = b;
return 0;
}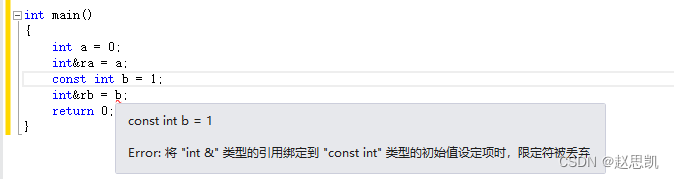
因为我们的b是只读类型,rb是可读可写的,从只读变成可读可写的是权限的放大,权限的放大是不允许的。
int main()
{
int a = 0;
int&ra = a;
/*const int b = 1;
int&rb = b;*/
int b = 1;
const int&rb = b;
return 0;
}而权限的缩小或者权限的平移是允许的。
注意:这里的权限放大缩小平移针对的只是指针或者引用。
int main()
{
const int a = 10;
int b = 20;
b = a;
return 0;
}这里虽然是权限的放大,但是这里并没有指针或者引用,这种问题就不会出现错误。
常见的易错点
void Func(int&x)
{
;
}
int main()
{
int a = 10;
int&ra = a;
const int&rra = a;
const int b = 1;
Func(a);
Func(rra);
Func(b);
return 0;
}
报错原因:我们传递的实参rra,b都是只读的,而我们的形参是可读可写的,从只读到可读可写是权限的放大。
所以一般用引用作为参数调用函数一般要用const修饰:
void Func(const int&x)
{
;
}
int main()
{
int a = 10;
int&ra = a;
const int&rra = a;
const int b = 1;
Func(a);
Func(rra);
Func(b);
return 0;
}这时候就不可能出现权限的放大。
但是这种问题并不会大量出现,因为如果我们不需要在函数中对被引用对象进行修改的话,我们可以在引用前加上const,假如我们要对被引用对象进行修改时,我们传递的实参也一定是可修改的,不能用const修饰。
const引用可以接收常量
int main()
{
int&a = 10;
return 0;
}int main()
{
const int&a = 10;
return 0;
}下面这种写法对吗?
int main()
{
const int&a = 10;
double d = 12.34;
int&ri = d;
return 0;
}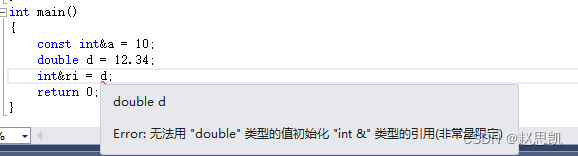
错误,因为d是double类型的,而ri是int类型的,是这样吗?
int main()
{
const int&a = 10;
double d = 12.34;
/*int&ri = d;*/
int ri = d;
return 0;
}那么为什么以下这种写法是正确的呢?
我们再举一个例子:
int main()
{
const int&a = 10;
double d = 12.34;
/*int&ri = d;*/
int ri = d;
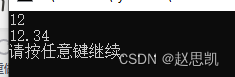
cout << (int)d << endl;
cout << d << endl;
return 0;
}这里的强制类型转化是把d转化成了整型12吗?
不对:本质上是有一个临时变量当作桥梁。

临时变量是整型,先把d传递给临时变量,再把临时变量赋给i,所以这里的d并没有发生改变。
而临时变量具有常性,我们又知道,const引用可以接收常量,所以以下的写法就正确了:
const int&ri = d;这里并不是把d赋给ri,而是先把d传递给临时变量,const引用可以接收临时变量,所以没问题。
我们再举一个新的例子:
int Count()
{
int n = 0;
n++;
return n;
}
int main()
{
int&ret = Count();
return 0;
}
Count函数的返回是传值返回,中间产生临时变量,临时变量具有常性,所有我们要用const来修饰。
int Count()
{
int n = 0;
n++;
return n;
}
int main()
{
const int&ret = Count();
return 0;
}
引用在底层
{
int a = 10;
int&ra = a;
ra += 10;
int*pa = &a;
*pa = 30;
}引用在语法上就是别名,不开空间。
而引用在底层呢?
const引用可以修饰常量(临时变量或者常数等)
我们转到反汇编

可以发现,引用在底层和指针的情况很相同。
所以引用在底层也是使用指针实现的。
引用和指针的不同点:

auto关键字
int main()
{
int a = 10;
auto b = a;
return 0;
}auto关键字的作用是根据a的类型自动推导b的类型。
范围for
int main()
{
int arr[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 0 };
for (auto e : arr)
{
cout << e;
}
cout << endl;
}![]()
范围for的作用:依次取arr数组中的每一个元素赋值给e,自动判断结束,自动迭代。















 194
194











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









