






近年来,随着深度学习的发展,Transformer模型作为一种革命性的神经网络架构,在自然语言处理领域取得了巨大的成功。其中,Transformer在序列到序列(Seq2Seq)任务中的应用尤为突出,尤其是在机器翻译方面。本文将介绍如何使用PyTorch实现基于Transformer的Seq2Seq模型,并将其应用于机器翻译任务。
Transformer模型概述
Transformer模型由Vaswani等人在2017年提出,其核心思想是完全基于注意力机制(self-attention)来捕捉输入序列的全局依赖关系,避免了传统循环神经网络(RNN)的顺序计算。Transformer由编码器(Encoder)和解码器(Decoder)组成,它们通过多层堆叠的注意力层和前馈全连接层实现序列的编码和解码。
例子:语言模型中的长依赖问题
假设我们有一个语言模型的任务,要预测下一个单词是什么。传统的基于RNN的语言模型会按顺序处理输入序列中的每个单词,依次更新隐藏状态,如下所示:
- RNN处理方式:
- 输入序列:
"我 爱 中国" - RNN依次处理每个单词,更新隐藏状态:
- 处理
"我",更新隐藏状态h1 - 处理
"爱",更新隐藏状态h2 - 处理
"中国",更新隐藏状态h3
- 处理
- 在预测时,RNN需要依赖前面的隐藏状态
h1, h2来预测下一个单词"中国"。
- 输入序列:
传统的RNN模型在处理长序列时,可能会遇到梯度消失或梯度爆炸的问题,因为它们必须依赖于顺序计算和前一个时间步的隐藏状态。
-
Transformer处理方式:
- 输入序列同样是
"我 爱 中国" - Transformer模型可以同时处理整个序列,并利用注意力机制捕捉每个位置之间的依赖关系。
在Transformer中,每个位置的处理方式如下:
- 自注意力机制(Self-Attention):每个输入序列位置都能与其他位置进行交互,计算出该位置的注意力权重,以及其他位置对该位置的影响。
- 并行计算:Transformer可以并行地计算每个位置的特征表示,而不需要按顺序更新隐藏状态。这使得它能够更高效地捕捉长距离依赖关系。
- 输入序列同样是
例如,在处理输入序列 "我 爱 中国" 时,Transformer可以同时计算出:
"我"位置的特征表示,考虑到"爱"和"中国"的语境;"爱"位置的特征表示,考虑到"我"和"中国"的语境;"中国"位置的特征表示,考虑到"我"和"爱"的语境。
这种并行计算和全局注意力机制使得Transformer模型能够更有效地理解和建模整个序列的语义和结构,而不会受到传统RNN顺序计算的限制。
下面是代码实现
实现Seq2SeqTransformer模型
数据预处理与词汇表构建
在实现之前,我们首先需要进行数据预处理和构建词汇表。这里我们假设已经有了训练数据 trainja 和 trainen,以及相应的分词器 ja_tokenizer 和 en_tokenizer。
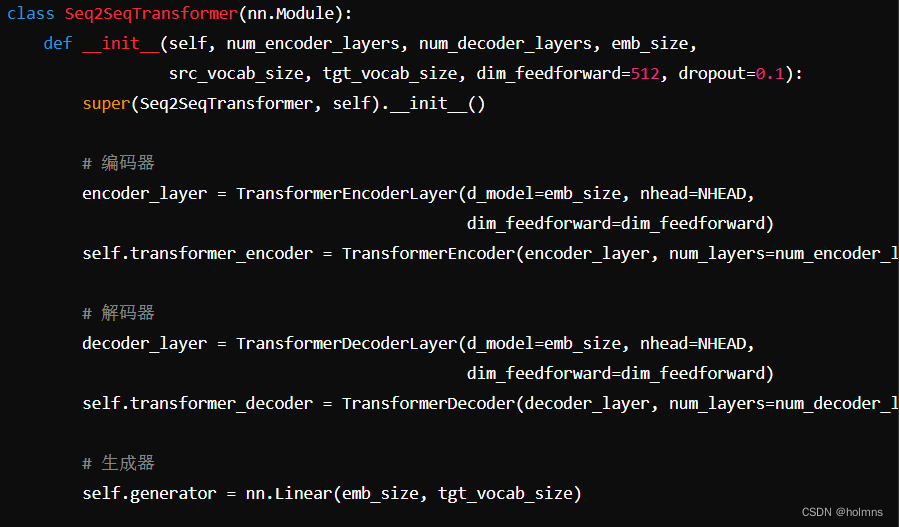
构建模型
接下来,我们构建基于Transformer的Seq2Seq模型。模型的核心包括编码器(TransformerEncoder)、解码器(TransformerDecoder)、位置编码(PositionalEncoding)、词嵌入(TokenEmbedding)等组件。

训练与评估模型
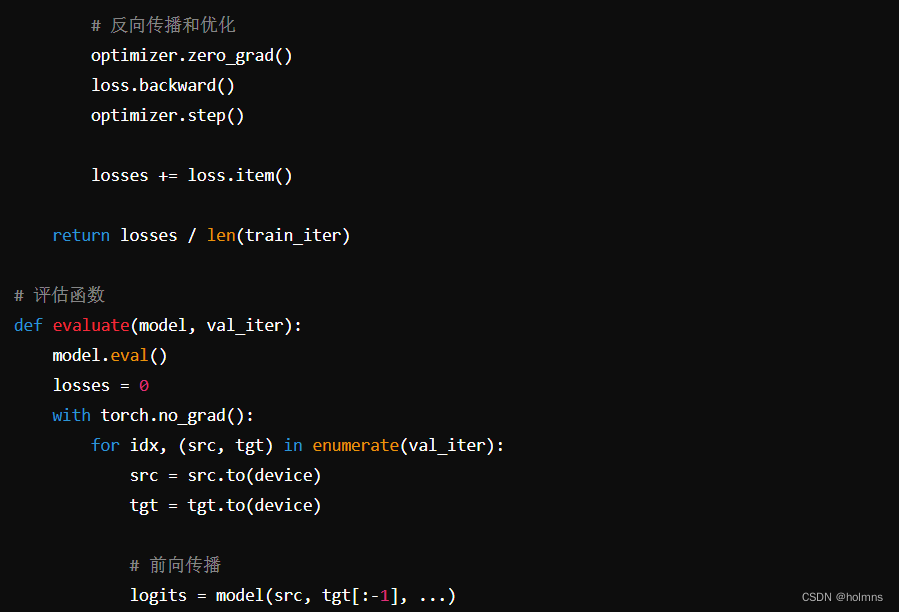
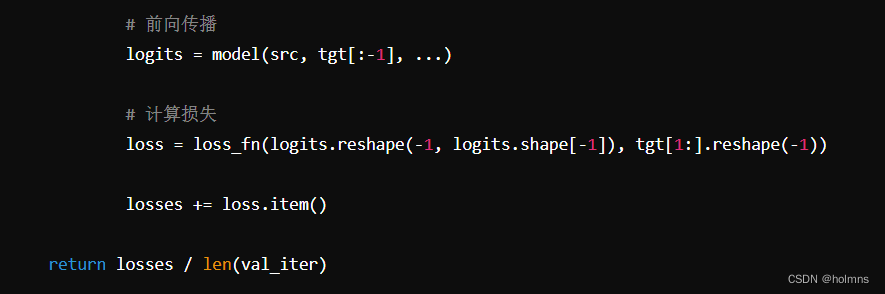
在模型构建完成后,我们需要定义训练和评估的过程。这包括定义损失函数、优化器以及训练和评估函数。
翻译函数
最后,我们定义一个翻译函数,使用训练好的模型将输入的源语言文本翻译成目标语言文本。
总结
通过构建模型、定义损失函数和优化器,以及编写训练、评估和翻译函数,我们实现了一个端到端的机器翻译系统。Transformer模型的强大之处在于其能够并行处理序列中的所有位置信息,以及利用多头注意力机制有效地捕捉长距离依赖关系,使其在机器翻译等任务中表现优异。















 54
54

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









