







目录
训练自己的数据集分为4部分,先配置环境,再获取制作自己的数据集,然后修改配置训练,最后验证训练结果,可选择将结果进行可视化界面展示。yolov7训练起来较为简单,跟yolov5相差不多,只需要多加一步将数据集所有的图片导入文本之中。如果有其他目标检测的数据集理论上可以直接拿来用,从第3训练模型开始看,新手小白0基础建议一步一步跟着来,哪里看不懂的或者遇到哪有问题可以评论区交流或者私信问~
1. 环境配置
在训练yolov7模型前环境必须配置完成,还不会配置环境的可以看我的这篇博客。
环境配置完验证之后就可以获取自己的数据集。
点击下载训练源码 夸克网盘下载 ,建议先全部转存提前下载,若有需要下载的资源失效,可至公众号获取百度盘链接下载。
YOLOv7网络结构图,论文必备,无水印图可 微信公众号-笑脸惹桃花 回复“777” 获取。
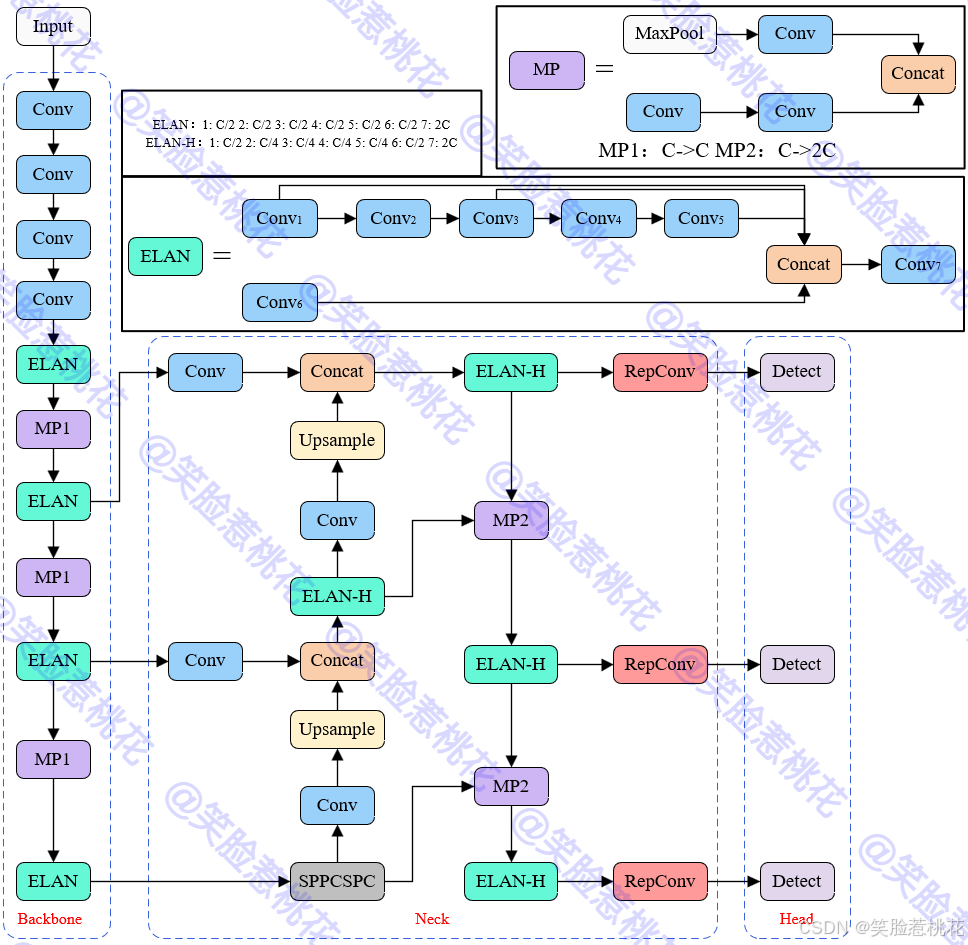
2. 数据集获取
目标检测相关的数据集一般是需要有图片+标注文件。数据集可以使用网上公开的跟自己研究相契合的数据集,或者是搜索/拍摄自己研究所需要的图片进行标注制作成数据集,这里两种方法都详细介绍一下。
2.1 网上搜索公开数据集
可以在搜索引擎上搜索或者在公开数据集的网站上搜索关键词,使用到的公开数据集网站为kaggleKaggle: Your Machine Learning and Data Science CommunityKaggle is the world’s largest data science community with powerful tools and resources to help you achieve your data science goals.https://www.kaggle.com/![]() https://www.kaggle.com/比如这里做一个安全帽检测的研究,就可以在搜索框输入安全帽的英文(因为是英文网站,都需要翻译成英文后搜索)Safety helmet
https://www.kaggle.com/比如这里做一个安全帽检测的研究,就可以在搜索框输入安全帽的英文(因为是英文网站,都需要翻译成英文后搜索)Safety helmet

搜索后就可以找到相关的内容,点击datasets筛选数据集,下载几个看一下数据集是否为目标检测的数据格式,一般文件夹为JPEGImages和Annotations包含这两个就可以使用。

点开一个后点击download即可下载。
若是下载到分割数据集,即json格式的标注可以看我的这篇文章转为txt,其他数据格式转换也可以私聊定制。
2.2 自制数据集
自制数据集需要先获取一定数量的目标图片,可以拍摄或者下载,图片足够之后使用标注工具Labelimg进行标注
2.2.1 Labelimg安装
使用Labelimg建议使用python3.10以下的环境,这里创建一个python3.8的虚拟环境,不会创建的可以去环境配置的文章下学习
conda create -n labelimg python=3.8这里创建完之后进入labelimg环境
conda activate labelimg进入labelimg环境之后通过pip下载labelimg(需要关闭加速软件)
pip install labelimg安装完成之后就可以使用
2.2.2 Labelimg使用
在使用labelimg之前,需要准备好数据集存放位置,这里推荐创建一个大文件夹为data,里面有JPEGImages、Annotations和classes.txt,其中JPEGImages文件夹里面放所有的图片,Annotations文件夹是将会用来对标签文件存放,classes.txt里存放所有的类别,每种一行

classes.txt里存放所有的类别,可以自己起名,需要是英文,如果有空格最好用下划线比如no_hat

上述工作准备好之后,在labelimg环境中cd到data目录下,如果不是在c盘需要先输入其他盘符+:
例如d: 回车之后再输入文件路径,接着输入以下命令打开labelimg
labelimg JPEGImages classes.txt打开软件后可以看到左侧有很多按钮,open dir是选择图片文件夹,上面选过了

点击change save dir 切换到Annotations目录之中,点击save下面的图标切换到pascal voc格式
切换好之后点击软件上边的view,将 Auto Save mode(切换到下一张图会自动保存标签)和Display Labels(显示标注框和标签) 保持打开状态。
常用快捷键:
A:切换到上一张图片
D:切换到下一张图片
W:调出标注十字架
del :删除标注框
例如,按下w调出标注十字架,标注完成之后选择对应的类别,这张图全部标注完后按d下一张

所有图像标注完成后数据集即制作完成。
2.3 数据集转换及划分
2.3.1 数据集VOC格式转yolo格式
暂时还没有数据集可以先点击网盘下载跟着本文进行训练,注意,此数据集的两个标签分别为 'person','hat' 。
如何查看自己数据集格式,打开Annotations文件夹,如果看到文件后缀为.xml,则为VOC格式,如果文件后缀为.txt则为yolo格式,后缀名看不到请搜索 如何显示文件后缀名。yolov7训练需要转为yolo格式训练,转换代码如下:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
def convert(size, box):
x_center = (box[0] + box[1]) / 2.0
y_center = (box[2] + box[3]) / 2.0
x = x_center / size[0]
y = y_center / size[1]
w = (box[1] - box[0]) / size[0]
h = (box[3] - box[2]) / size[1]
return (x, y, w, h)
def convert_annotation(xml_files_path, save_txt_files_path, classes):
xml_files = os.listdir(xml_files_path)
print(xml_files)
for xml_name in xml_files:
print(xml_name)
xml_file = os.path.join(xml_files_path, xml_name)
out_txt_path = os.path.join(save_txt_files_path, xml_name.split('.')[0] + '.txt')
out_txt_f = open(out_txt_path, 'w')
tree = ET.parse(xml_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
# b=(xmin, xmax, ymin, ymax)
print(w, h, b)
bb = convert((w, h), b)
out_txt_f.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
if __name__ == "__main__":
# 需要转换的类别,需要一一对应
classes1 = ['hat','nohat']
# 2、voc格式的xml标签文件路径
xml_files1 = r'f:\data\Annotations'
# 3、转化为yolo格式的txt标签文件存储路径
save_txt_files1 = r'f:\data\labels'
convert_annotation(xml_files1, save_txt_files1, classes1)需要自行将类别以及文件路径替换,这里顺序要记住,文件夹也对应替换,不知道有哪些类别可以看这篇博客。
2.3.2 数据集划分
训练自己的yolov7检测模型,数据集需要划分为训练集、验证集,这里提供一个参考代码,划分比例为8:2(这里不再划分测试集),也可以按照自己的比例划分修改代码,三者加起来为1即可。
# 作者:CSDN-笑脸惹桃花 https://blog.csdn.net/qq_67105081?type=blog
# github:peng-xiaobai https://github.com/peng-xiaobai/Dataset-Conversion
import os
import shutil
import random
# random.seed(0) #随机种子,可自选开启
def split_data(file_path, label_path, new_file_path, train_rate, val_rate, test_rate):
images = os.listdir(file_path)
labels = os.listdir(label_path)
images_no_ext = {os.path.splitext(image)[0]: image for image in images}
labels_no_ext = {os.path.splitext(label)[0]: label for label in labels}
matched_data = [(img, images_no_ext[img], labels_no_ext[img]) for img in images_no_ext if img in labels_no_ext]
unmatched_images = [img for img in images_no_ext if img not in labels_no_ext]
unmatched_labels = [label for label in labels_no_ext if label not in images_no_ext]
if unmatched_images:
print("未匹配的图片文件:")
for img in unmatched_images:
print(images_no_ext[img])
if unmatched_labels:
print("未匹配的标签文件:")
for label in unmatched_labels:
print(labels_no_ext[label])
random.shuffle(matched_data)
total = len(matched_data)
train_data = matched_data[:int(train_rate * total)]
val_data = matched_data[int(train_rate * total):int((train_rate + val_rate) * total)]
test_data = matched_data[int((train_rate + val_rate) * total):]
# 处理训练集
for img_name, img_file, label_file in train_data:
old_img_path = os.path.join(file_path, img_file)
old_label_path = os.path.join(label_path, label_file)
new_img_dir = os.path.join(new_file_path, 'train', 'images')
new_label_dir = os.path.join(new_file_path, 'train', 'labels')
os.makedirs(new_img_dir, exist_ok=True)
os.makedirs(new_label_dir, exist_ok=True)
shutil.copy(old_img_path, os.path.join(new_img_dir, img_file))
shutil.copy(old_label_path, os.path.join(new_label_dir, label_file))
# 处理验证集
for img_name, img_file, label_file in val_data:
old_img_path = os.path.join(file_path, img_file)
old_label_path = os.path.join(label_path, label_file)
new_img_dir = os.path.join(new_file_path, 'val', 'images')
new_label_dir = os.path.join(new_file_path, 'val', 'labels')
os.makedirs(new_img_dir, exist_ok=True)
os.makedirs(new_label_dir, exist_ok=True)
shutil.copy(old_img_path, os.path.join(new_img_dir, img_file))
shutil.copy(old_label_path, os.path.join(new_label_dir, label_file))
# 处理测试集
for img_name, img_file, label_file in test_data:
old_img_path = os.path.join(file_path, img_file)
old_label_path = os.path.join(label_path, label_file)
new_img_dir = os.path.join(new_file_path, 'test', 'images')
new_label_dir = os.path.join(new_file_path, 'test', 'labels')
os.makedirs(new_img_dir, exist_ok=True)
os.makedirs(new_label_dir, exist_ok=True)
shutil.copy(old_img_path, os.path.join(new_img_dir, img_file))
shutil.copy(old_label_path, os.path.join(new_label_dir, label_file))
print("数据集已划分完成")
if __name__ == '__main__':
file_path = r"f:\data\JPEGImages" # 图片文件夹
label_path = r'f:\data\labels' # 标签文件夹
new_file_path = r"f:\VOCdevkit" # 新数据存放位置
split_data(file_path, label_path, new_file_path, train_rate=0.8, val_rate=0.2, test_rate=0.0)代码可以自动划分各种格式的图片及标签文件,且无论图片及标签数量是否对应,均会对应移动到相同的文件夹下,同时给出出现差异的图片或标签文件名,方便小白快速查找原因。划分完成之后,想要训练yolov7的数据集还需要将数据集的路径添加入txt中供训练数据读取。
2.3.3 添加数据集列表
这里需要添加刚才划分的训练集、验证集路径至txt文本中保存,代码如下。
# importing the os Library
import os
train_list = r'f:/VOCdevkit/train/images/'
val_list = r'f:/VOCdevkit/val/images/'
path_list1 = r'f:/VOCdevkit/train_list.txt'
path_list2 = r'f:/VOCdevkit/val_list.txt'
def findfiles(path,path_list):
# 首先遍历当前目录所有文件及文件夹
file_list = os.listdir(path)
# 循环判断每个元素是否是文件夹还是文件,是文件夹的话,递归
for file in file_list:
# 利用os.path.join()方法取得路径全名,并存入cur_path变量,否则每次只能遍历一层目录
cur_path = os.path.join(path, file)
# 判断是否是文件夹
with open(path_list,'a') as f:
f.write(cur_path+'\n')
f.close()
if __name__ == '__main__':
findfiles(train_list,path_list1)
findfiles(val_list, path_list2)3. 训练模型
需要下载源码,这里选择的是yolov7默认的main版本,可以点此下载本文演示的安全帽数据集。
不会下载源码的可以看我的这篇博客点此查看,也可以点此下载,我这里把源码和预训练权重yolov7.pt和yolov7-tiny.pt一起打包上传了,链接资源失效请评论区反馈,看到都会补。

有了源码之后需要修改里面的参数,导入自己的数据集。
3.1 创建data.yaml
在yolov7/data目录下(也就是本文所用的yolov7-main/data目录下)创建一个新的data.yaml文件,也可以是其他名字的例如hat.yaml文件,后缀需要为.yaml,内容如下。
train: f:/VOCdevkit/train_list.txt # train images (relative to 'path') 128 images
val: f:/VOCdevkit/val_list.txt # val images (relative to 'path') 128 images
nc: 2
# Classes
names: ['hat','nohat']具体路径和类别自己替换,需要和上面数据集转换那里类别顺序一致。
3.2 训练模型
这是使用官方提供的预训练权重进行训练,使用yolov7.pt,训练较慢也可以使用yolov7-tiny.pt。

下载完成之后放入yolov7-main根目录中,建议点击上面链接下载,yolov7-tiny.pt权重文件不容易获取。打开train.py文件,修改方框中框选部分内容。

其中weights为导入模型,这里修改为yolov7.pt或者其他模型,cdg为改为yolov7.yaml或者pt对应的yaml文件名,data改为data/data.yaml,修改为自己新建的文件名,epochs可以先设为10,能够正常训练并且保存结果再修改为100或者更多,batch-size根据自己的电脑性能设置大小,建议为2的n次方,可以多次修改找到最适合自己电脑的参数大小。
训练过程如图,耐心等待训练完成即可,训练完成后会生成best.pt权重文件,可以用来验证训练效果或者部署到可视化界面之中展示。

训练过程中遇到报错可以评论区留言,看到都会及时回复。
4. 模型测试
找到之前训练的结果保存路径,打开一个detect.py文件,修改图中yolov7.pt为训练好的权重文件路径,如runs/train/exp4/weights/best.pt,然后将待检测图片或视频放入inference/images文件夹中

运行后就会得到预测模型结果。

可以打开对应路径下查看预测的图片效果,模型就训练好啦~
5. 可视化界面
部分同学的需求是制作出一个可视化图形界面来展示实时预测的效果,yolov7的可视化界面可以私聊定制。
如果遇到报错或者有疑问可以评论区交流,关注公众号获取更多资源~




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











