







1. 简介
快速排序是一种二叉树结构的交换排序方法,采用分治策略来对数据进行排序。
基本步骤如下:
- 选择基准值:通常选择序列的第一个或最后一个元素作为基准值。
- 分区操作:重新排列序列,使得所有小于或等于基准值的元素都移到基准的左边,而所有大于基准值的元素都移到基准的右边。这一步完成后,基准值所在的位置就是其最终位置。
- 递归排序:递归地将小于基准值的子序列和大于基准值的子序列再次进行快速排序。
简而言之,就是将待排序集合分割成两个子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值。再对左右两子序列分别递归排序。
2. 图解
2.1 通过基准值分区
2.1.1 方法一
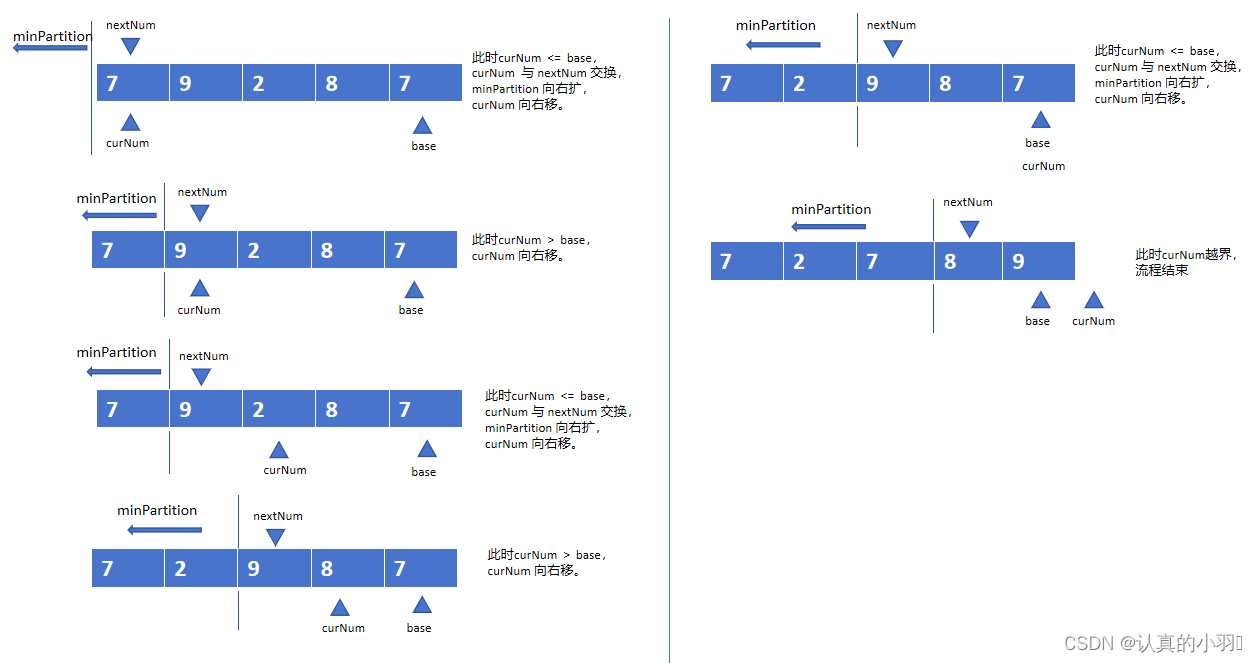
将区域分成两部分,小于等于基准值区域和大于基准值区域。
基准值 : base
当前值 : curNum
比基准值小或等的分区(小分区): minPartition
小分区的下一个值 : nextNum
步骤:
① 当前值 <= 基准值,当前值 与 小分区的下一个值 交换,
小分区的范围 向右扩,
当前值 向右移。
② 当前值 > 基准值,当前值向右移。
void partitioning(int[] arr) {
int nextNum = 0;
int curNum = 0;
int len = arr.length;
int base = len - 1;
while(nextNum < len){
if(arr[curNum] <= arr[base]){
// 通过交换,放入小分区,其他的默认大分区
swap(arr, nextNum, curNum);
nextNum++;
curNum++;
}else{
curNum++;
}
}
}
void swap(int[] arr, int l, int r){
int tmp = arr[l];
arr[l] = arr[r];
arr[r] = tmp;
}2.1.2 方法二(优化)
由于方法一并不是严格意义上的小于基准值的分区,如果基准值有多个,效率会低一点。
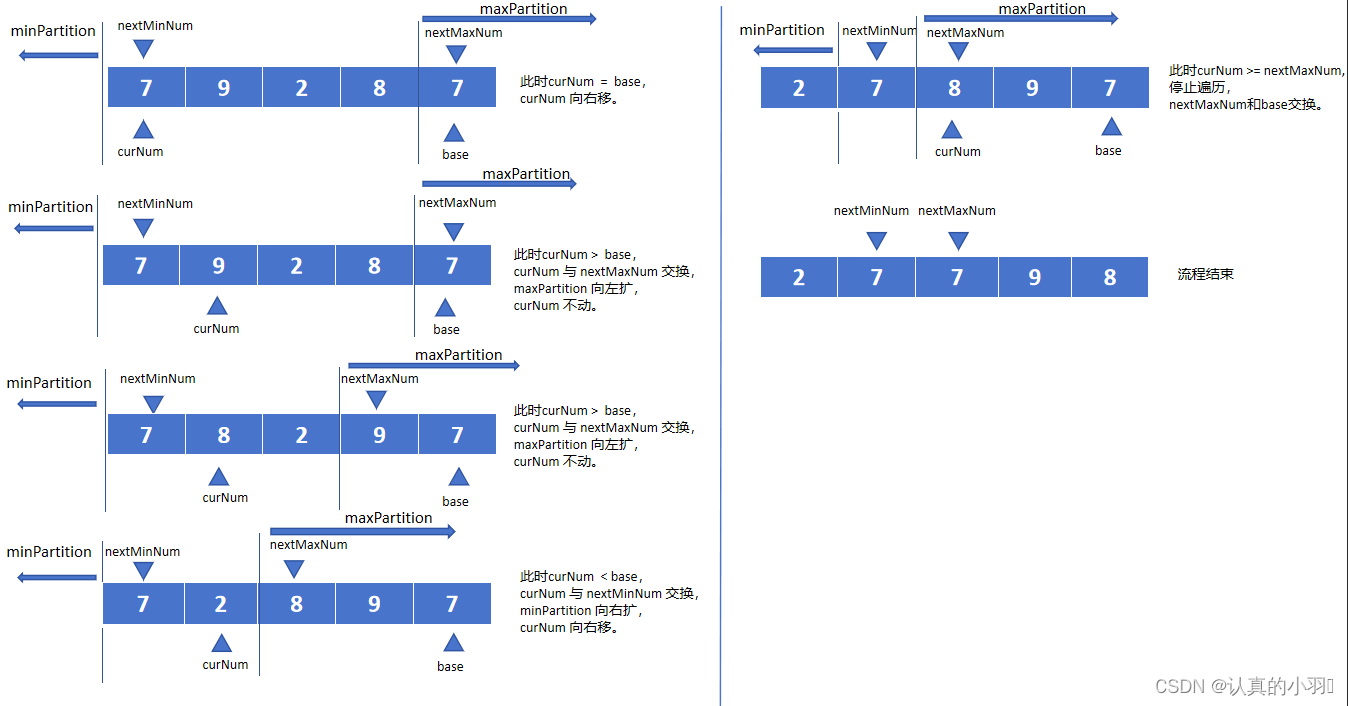
将数组分成三部分,小于基准值区域,等于基准值区域和大于基准值区域。这样多个等于基准值的将不参与后续排序。
基准值 : base
当前值 : curNum
比基准值小的分区(小分区) : minPartition
比基准值大的分区(大分区) : maxPartition
小分区的下一个值 : nextMinNum
大分区的下一个值 : nextMaxNum
步骤:
① 当前值 < 基准值,当前值 与 小分区的下一个值 交换,
小分区的范围 向右扩,
当前值 向右移。
② 当前值 > 基准值,当前值 与 大分区的下一个值 交换,
大分区的范围 向左扩,
当前值 不动。
③ 当前值 = 基准值, 当前值向右移。
void partitioning(int[] arr) {
int len = arr.length;
int nextMinNum = 0;
int base = len - 1;
int nextMaxNum = len - 2;
int curNum = 0;
while(curNum < nextMaxNum){
if(arr[curNum] < arr[base]){
// 通过交换,放入小分区
swap(arr, nextMinNum, curNum);
nextNum++;
curNum++;
}else if(arr[curNum] > arr[base]){
// 通过交换,放入大分区
swap(arr, nextMaxNum, curNum);
nextMaxNum--;
}else{
curNum++;
}
}
// 达到终止条件,curNum > nextMaxNum, 即当前值进入大分区
// nextMaxNum和base交换
swap(arr, curNum, base);
}
void swap(int[] arr, int l, int r){
int tmp = arr[l];
arr[l] = arr[r];
arr[r] = tmp;
}2.2. 递归排序
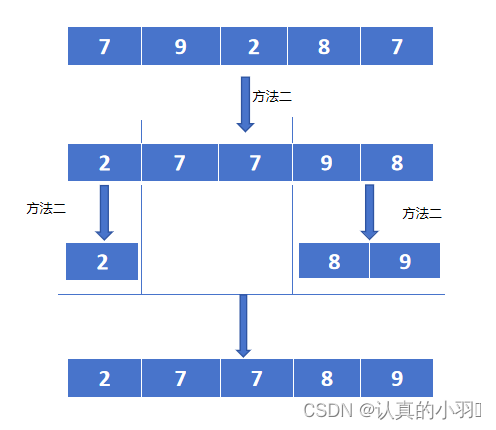
通过方法二对数组快速排序,将数组分成小分区和大分区,再对两部分分别进行快速排序,一直递归到不能再分,结果就是排好序的数组。
public void quickSort(int[] arr){
if (arr == null || arr.length == 0){
return;
}
process(arr, 0, arr.length);
}
// 对数组按方案二递归排序
void process(int[] arr, int l, int r){
if (l >= r){
return;
}
int[] midPartition = partition(arr, l, r);
// 递归小分区
process(arr, l, midPartition[0] - 1);
// 递归大分区
process(arr, midPartition[1] + 1, r);
}
/*
* 通过方法二排序,分组
*
* @Param int[] arr 需排序数组
* @Param int l 左边界
* @Param int r 右边界
* @Return int[2] 返回中间分区的边界
*/
int[] partition(int[] arr, int l, int r){
int nextMinNum = l;
int nextMaxNum = r;
int curNum = l;
while(curNum < nextMaxNum){
if(arr[curNum] < arr[r]){
// 通过交换,放入小分区
swap(arr, nextMinNum, curNum);
nextNum++;
curNum++;
}else if(arr[curNum] > arr[r]){
// 通过交换,放入大分区
swap(arr, nextMaxNum, curNum);
nextMaxNum--;
}else{
curNum++;
}
}
// 达到终止条件,curNum > nextMaxNum, 即当前值进入大分区
// nextMaxNum和base交换
swap(arr, nextMaxNum, r);
return new int[]{nextMinNum, nextMaxNum};
}
void swap(int[] arr, int l, int r){
int tmp = arr[l];
arr[l] = arr[r];
arr[r] = tmp;
}3. 复杂度分析
快速排序是一种效率较高的排序算法,其时间复杂度在最优情况下是O(nlogn),而在最坏情况下是O(n^2)。以下是具体分析:
- 最优情况:当快速排序的每一次分区操作都能将数组平分为两个几乎相等的部分时,这时的时间复杂度为O(nlogn)。这是因为每一层递归大约处理一半的元素,而递归树的深度为logn,因此总的操作次数是T(n) = 2T(n/2) + O(n),其中T(n/2)是递归调用的时间复杂度,O(n)是划分操作的时间复杂度。
- 平均情况:在随机选择基准值的情况下,快速排序的平均时间复杂度也是O(nlogn)。这是因为虽然每次划分不一定能够完美平分数组,但通过随机化可以减少出现最坏情况的概率,使得算法的性能接近最优情况。
- 最坏情况:当每次分区操作都将数组划分为两个极端不平衡的部分时,例如一个部分包含n-1个元素,另一个部分为空,这时快速排序的时间复杂度会退化成类似于冒泡排序的性能,即为O(n^2)。这种情况通常发生在待排序序列已经是有序或者逆序的情况下。















 2584
2584

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









