







目录
1. 简介
不基于比较的排序算法主要有计数排序、基数排序等。
核心思想是避免直接比较元素之间的大小关系,而是利用其他信息(如数值的分布特征或数字的位信息)来实现排序。
2. 计数排序
2.1 简介
计数排序是一种非比较型整数排序算法,其核心在于将输入的数据值转化为键,存储在额外开辟的数组空间中。
2.2 实现步骤
- 确定计数数组的大小:找出待排序数组中的最大值
max,创建一个长度为max + 1的计数数组count,并将所有元素的值初始化为0。- 计数:遍历原始数组,对于每个元素
x,增加bucket[x]的值,即bucket[x] = bucket[x] + 1。这样bucket数组中的每个索引对应的值就是该索引在原始数组中出现的次数。- 生成排序结果:从
bucket数组的第一个元素开始,依次覆盖原始数组arr,填充的次数等于该索引在bucket数组中的值。
2.3 图解
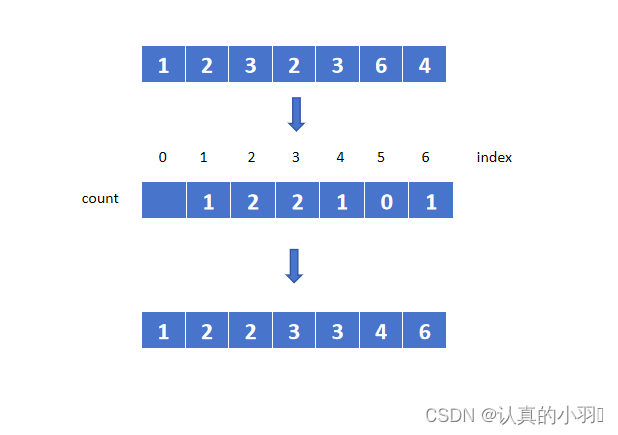
2.4 代码实现
// 计数排序
public static void countSort(int[] arr){
if (arr == null || arr.length < 2) {
return;
}
// 找出数组中的最大值
int max = arr[0];
for (int i = 1; i < arr.length; i++){
if(arr[i] > max){
max = arr[i];
}
}
// 将最大值作为数组的容量,创建计数数组
int[] count = new int[max+1];
for (int j : arr) {
count[j]++;
}
// 遍历取得的顺序就是排好序的顺序
int index = 0;
for (int i = 0; i < count.length; i++){
while(count[i] > 0){
arr[index++] = i;
count[i]--;
}
}
}2.5 复杂度分析
计数排序的时间复杂度为O(n+k),其中n是数组的长度,k是数组中最大值与最小值的差加1。由于它不是基于比较的排序算法,因此在特定条件下(如数据范围有限且为整数),它的排序速度快于任何比较排序算法。
2.6 应用时机
在数据范围有限且分布较为密集时,使用计数排序通常会比其他排序算法更节省内存。
- 有限的数据范围:当待排序的数据是有确定范围的整数时,计数排序通过创建一个与数据范围大小相匹配的计数数组来工作。如果这个范围不是很大,那么计数数组所占用的空间也会相对较小,这样就能有效地节省内存。
- 数据分布密集:对于分布密集的数据集,即大多数值都接近最小值或最大值,计数排序可以更准确地分配空间,避免浪费。这是因为计数数组的大小取决于数据的范围(最大值与最小值之差加1),而不是数据的数量。
- 非比较型算法:计数排序不基于元素之间的比较,而是直接根据元素的值来确定其在输出数组中的位置。这种方法在处理特定范围的整数时,可以减少内存的使用量。
2.7 总结
计数排序在处理有限范围内的整数排序问题时,尤其是在数据分布密集的情况下,通常能够提供更好的内存效率。然而,如果数据范围很大或者数据分布非常稀疏,那么计数排序可能会导致辅助空间过大,从而不再节省内存。因此,在选择排序算法时,需要根据具体的数据特性和应用场景来决定。
3. 基数排序
3.1 简介
基数排序(Radix Sort)通过将整数拆分为不同的位数,然后按每个位数分别进行比较来排序。它可以选择从最低有效位(LSD)或最高有效位(MSD)开始处理。
3.2 实现步骤
以下是使用LSD方法的基数排序:
- 找到数组中的最大值,并计算最小和最大位数。
- 对于每个位数(从最低到最高),执行以下操作:
- 根据当前位数将数字分组。
- 将排序后的数字复制回原数组。
- 重复步骤2,直到所有位数都被处理过。
3.3 图解
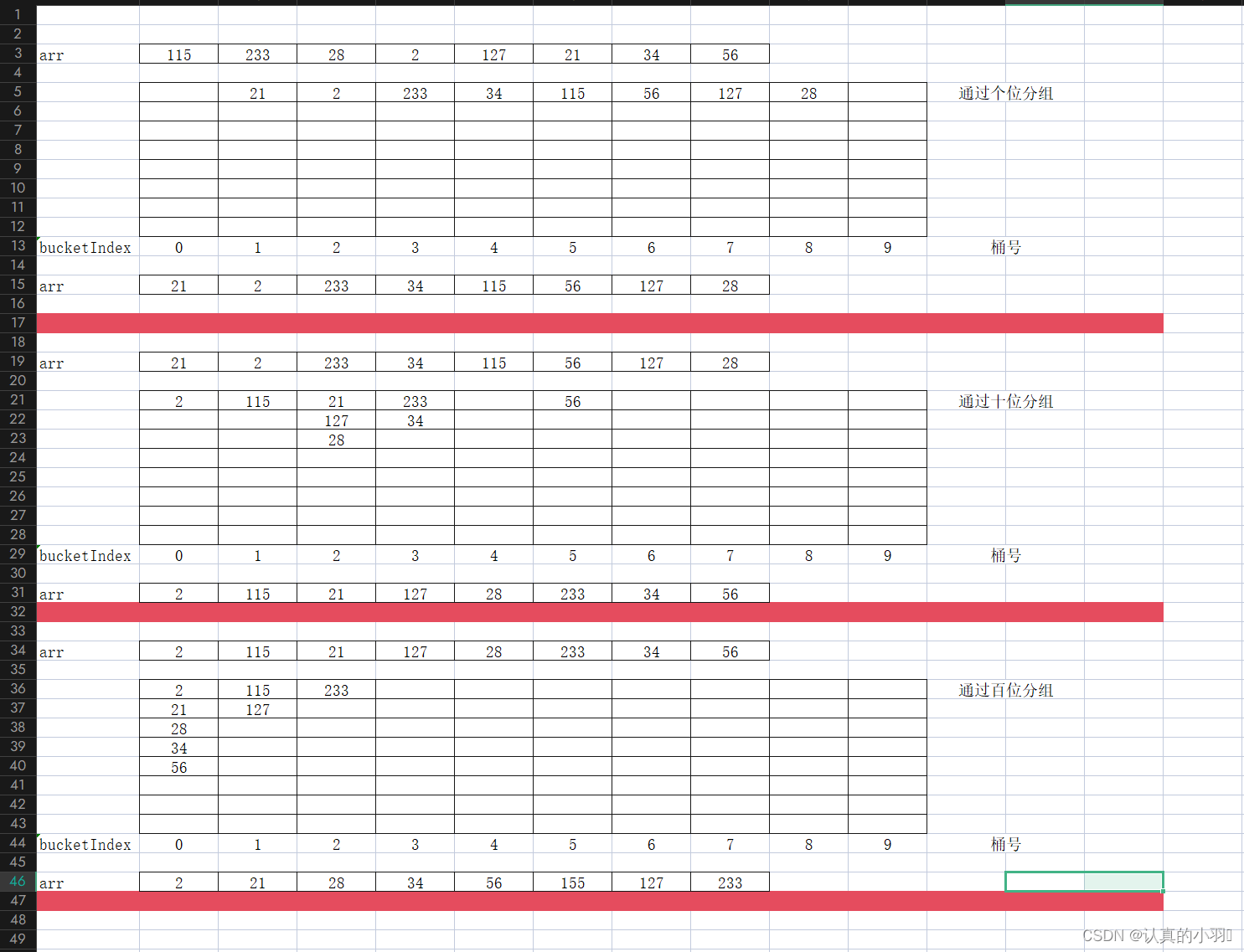
3.4 代码实现
public static void radixSort(int[] arr) {
// 获取数组中最大的数
int max = Arrays.stream(arr).max().getAsInt();
// 获取数组中最大的数的位数
int maxLength = String.valueOf(max).length();
// 进行maxLength次排序
for (int i = 0; i < maxLength; i++) {
// 用于存储每个位上的数字
int[][] bucket = new int[10][arr.length];
// 用于存储每个位元素的个数
int[] bucketElementCounts = new int[10];
// 将每个数字按照每个位上的数字放入对应的桶中
for (int num : arr) {
int digit = (num / (int) Math.pow(10, i)) % 10;
bucket[digit][bucketElementCounts[digit]] = num;
bucketElementCounts[digit]++;
}
// 将每个桶中的数字按照每个位上的数字放入原数组中
int index = 0;
for (int j = 0; j < 10; j++) {
if (bucketElementCounts[j] > 0) {
for (int k = 0; k < bucketElementCounts[j]; k++) {
// 将每个桶中的数字按照每个位上的数字放入原数组中
arr[index++] = bucket[j][k];
}
bucketElementCounts[j] = 0;
}
}
}
}3.5 复杂度分析
- 时间复杂度为O(d⋅(n+k)),其中d是元素位数,n是数组长度,k是数字的进制(即每个位上可能的不同取值数目,例如十进制数的基数是10)。这个时间复杂度意味着算法的性能与输入数据的大小和数据的位数密切相关。在最坏的情况下,如果所有数字的所有位都不同,那么时间复杂度可以简化为O(dn)。
- 基数排序的空间复杂度主要取决于用于存储计数数组的额外空间。在LSD方法中,由于需要为每一位创建一个计数数组。所以时间复杂度为O(nk),其中n是数组长度,k是数字的进制。
3.6 应用时机
- 大规模整数排序:当待排序数据为大量整数或整数编码的字符串时,基数排序能够充分利用数据特性,实现高效排序。例如,电话号码、身份证号码等,这些通常具有固定长度的数字字符串,非常适合使用基数排序。
- 高效稳定排序需求:在需要保持相等元素原始相对顺序的同时对数据进行排序时,基数排序不仅能够提供稳定的排序结果,还能够保证较高的效率。这对于某些数据处理任务来说是非常重要的,尤其是在数据需要保持原有顺序不变的情况下。
3.7 总结
对于计数排序来说,当数值范围(m)稍微大一些时,空间复杂度可能会成为问题。基数排序作为计数排序的优化版本,能够更好地处理自然数范围内的排序问题,尤其是当数值范围较大时,基数排序相比计数排序能够更有效地减少空间复杂度。
4. 总结
非比较型的排序算是一类思想,不依赖于元素之间的相互比较来进行排序,而是根据元素的值来确定其在排序后数组中的位置。上述非比较型排序算法的共同特点是在某些情况下可以提供比比较型排序算法(如快速排序、归并排序)更高的效率,尤其是当数据满足特定条件时。















 667
667











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









