







1. 简介
并查集是一种非常简洁而优雅的数据结构,它以树的形式管理一系列不相交的集合。这种数据结构在处理元素分组问题时表现出了极高的效率和简洁性。它常常被用来解决图论中动态连通性的问题。
2. 实现步骤
并查集的主要操作有两个,查找(Find)和合并(Union)。
- 初始化:将每个元素视为一个独立的集合,每个元素的父指针指向自己,表示它们是自己的代表元素。
- 查找(Find):俗称“认爹”,确定某个元素属于哪个集合。这通常用来判断两个元素是否处于同一个集合。一般是是通过追踪元素的父指针直到达到代表元素(根节点)来实现的。
- 合并(Union):将两个集合合并为一个集合。这通常是通过找到两个集合的代表元素x和y,然后将其中一个集合的代表元素的父指针指向另一个集合的代表元素来完成的。擒贼先擒王,只改祖宗即可。
3. 图解
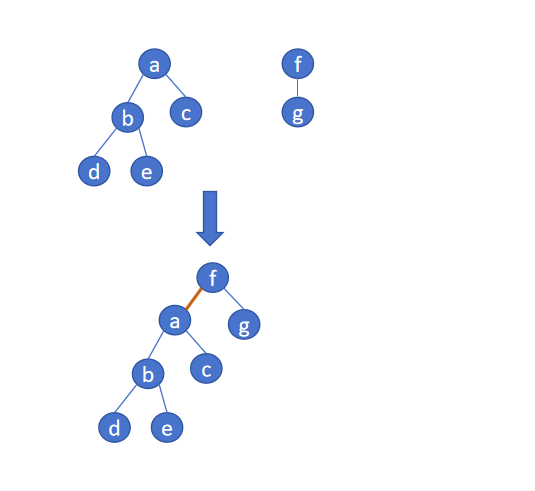
4.实现方法
并查集的实现有几种不同的方法,包括:
- 基本实现:这是并查集的最基础形式,使用一个数组来存储每个元素的父节点信息。通过指针或索引可以找到每个元素的代表元素(根节点),从而确定元素所属的集合。
- 带路径压缩的实现:在基本实现的基础上,当执行查找操作时,将查找路径上的每个节点直接连接到根节点上。这样做可以减少后续查找时的步数,提高查找效率。
- 带按秩合并的实现:在合并两个集合时,总是将较小的树连接到较大的树上,这样可以避免树的不平衡增长,保持树的高度尽可能小,从而提高合并操作的效率。
- 带路径压缩和按秩合并的实现:结合了路径压缩和按秩合并两种优化策略,是并查集中效率较高的一种实现方式。
- 使用双向链接的实现:在基本的并查集中,每个节点只记录其父节点信息。而在双向链接的实现中,每个节点还会记录子节点信息,这样可以进一步加快查找和合并的速度。
- 使用链表的实现:在这种实现中,每个集合用一个链表来表示,链表中的每个节点包含集合中的一个元素。这种方式在处理动态变化较多的集合时较为有效。
- 使用哈希表的实现:利用哈希表可以在常数时间内完成查找和插入操作,适合处理大量数据且需要快速访问的情况。
5. 代码实现
5.1 带路径压缩和按秩合并的实现
public class UnionFind {
private int[] parent; // 存储每个节点的父节点
private int[] rank; // 存储每个集合的秩(树的高度)
// 初始化
public UnionFind(int size) {
parent = new int[size];
rank = new int[size];
for (int i = 0; i < size; i++) {
// 初始时,每个节点都是自己的代表元素
parent[i] = i;
// 初始时,每个集合的秩都为1
rank[i] = 1;
}
}
// 查找操作,使用路径压缩优化
public int find(int x) {
if (parent[x] != x) {
parent[x] = find(parent[x]); // 递归查找根节点,并进行路径压缩
}
return parent[x];
}
// 合并操作,使用按秩合并优化
public void union(int x, int y) {
// 找到两个集合的根节点
int rootX = find(x);
int rootY = find(y);
// 如果两个元素已经在同一个集合中,无需合并
if (rootX == rootY) {
return;
}
// 将较小的树连接到较大的树上
if (rank[rootX] > rank[rootY]) {
parent[rootY] = rootX;
} else if (rank[rootX] < rank[rootY]) {
parent[rootX] = rootY;
} else {
// 如果两棵树的秩相等,选择任意一棵树连接到另一棵树上,并将秩加1
parent[rootY] = rootX;
rank[rootX]++;
}
}
}5.2 使用哈希表的实现
public static class Node<T> {
T value;
public Node(T t){
this.value = t;
}
}
public static class UnionFind<T> {
public HashMap<T, Node<T>> nodes; // 节点映射
public HashMap<Node<T>, Node<T>> parents; // 父节点
public HashMap<Node<T>, Integer> rank; // 秩
// 初始化
public UnionFind(List<T> values){
this.nodes = new HashMap<>(values.size());
this.parents = new HashMap<>(values.size());
this.rank = new HashMap<>(values.size());
for (T value : values) {
this.nodes.put(value, new Node<>(value));
this.parents.put(this.nodes.get(value), this.nodes.get(value));
this.rank.put(this.nodes.get(value), 1);
}
}
public Node<T> find(Node<T> node){
Stack<Node<T>> path = new Stack<>();
// 循环查找根节点
while (node!= this.parents.get(node.value)){
path.push(node);
node = this.parents.get(node);
}
while (!path.isEmpty()){
parents.put(path.pop(), node);
}
return node;
}
public void union(T a, T b){
// nodes没有就直接返回
if (!nodes.containsKey(a) || !nodes.containsKey(b)){
return;
}
// 找两点的祖宗
Node<T> nodeA = find(nodes.get(a));
Node<T> nodeB = find(nodes.get(b));
// 祖宗不一样,合并
if (nodeA != nodeB){
int sizeA = rank.get(a);
int sizeB = rank.get(b);
// 通过秩,小挂大
Node<T> big = sizeA >= sizeB ? nodeA : nodeB;
Node<T> small = sizeA >= sizeB? nodeB : nodeA;
parents.put(small, big);
rank.put(big, sizeA + sizeB);
rank.remove(small);
}
}
}6. 复杂度分析
并查集的查询操作时间复杂度为O(1),而合并操作的时间复杂度在未优化的情况下为O(n)。
- init(x):创建一个只包含元素x的新集合,这通常是O(1)的操作。
find(x):查找元素x所在集合的代表元素,即根节点。未优化的实现可能是O(N),但通过路径压缩可以优化到接近O(1)。union(x, y):将元素x和y所在的集合合并。在未优化的情况下可能是O(N),但通过按秩合并可以优化到接近O(1)。
其次,在实际应用中,并查集的性能往往取决于这些操作的复合效应。例如,在执行了M次操作后,整体的时间复杂度可能表示为O(Mα(N)),其中M是操作次数,N是元素个数。
7. 总结
并查集是一种用于处理不相交集合的高效数据结构,主要用于解决元素分组和查询问题。可以用来判断图的连通性、找出图中的连通分量、网络连接、最近公共祖先查询等问题。















 223
223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









