







1.什么是并行计算
目前公开文献可查到比较早提出的定义是Gottlieb等人在1989年《高性能计算》一书中给出的。Gottlieb等认为:并行计算是一种计算类型,其中许多计算或计算过程的执行是同时执行的。
并行计算的目的是加快计算速度。我国学者张林波在其编写的教材《并行计算导论》中对并行计算进行了描述性定义:并行计算(parallel computing)是指,在并行机上,将一个应用分解成多个子任务,分配给不同的处理器,各个处理器之间相互协同,并行地执行子任务,从而达到加速求解速度,或者求解应用问题规模的目的。
通俗而言,并行计算是一种计算体系结构,其中多个处理器同时执行从一个较大的复杂问题中分解出来的多个、较小的计算任务。近年来并行计算已成为计算机体系结构中的主要范例,主要以多核处理器的形式出现。
1.并行计算的三个基本条件
1.并行机
并行机至少包含两台或两台以上处理机,这些处理机通过互连网络相互连接,相互通信。
2.应用问题必须具有并行度。
也就是说,应用可以分解为多个子任务,这些子任务可以并行地执行。将一个应用分解为多个子任务的过程,称为并行算法的设计。
3.并行编程。
在并行机提供的并行编程环境上,具体实现并行算法,编制并行程序,并运行该程序,从而达到并行求解应用问题的目的。
2.并行计算的四种形式
1.位级并行(Bit-level parallelism)
增加处理器字的大小,这减少了处理器必须执行的指令量,才能对大于字长的变量执行操作。
从1970年代超大规模集成(VLSI)计算机芯片制造技术问世到1986年左右,计算机体系结构的提速是由计算机字长加倍(即每个周期处理器可处理的信息量)推动的。增加字长会减少处理器必须执行的指令数量,以执行对大于字长的变量的操作。例如,如果一个8位处理器必须将两个16位整数相加,则处理器必须首先使用标准加法指令将每个整数中的8个低位位相加,然后使用加法器将8个高位位相加。一个8位处理器需要两条指令来完成一个操作,而一个16位处理器将能够用一条指令来完成操作。
从历史上看,4位微处理器先后被8位,16位,32位微处理器所取代。而32位处理器已经成为通用计算的标准已有二十年了。直到2000年代初期,随着x86-64体系结构的出现,64位处理器才开始逐步普遍应用。
2.指令集并行(Instruction-level parallelism)
本质上,计算机程序是由处理器执行的指令流。没有指令级并行性,处理器每个时钟周期只能发出少于一条指令(IPC<1)。这些处理器称为次标量处理器。这些指令可以重新排序并组合成组,然后在不更改程序结果的情况下并行执行。这称为指令级并行性。从1980年代中期到1990年代中期,指令级并行性的进步主导了计算机体系结构[5]。即当指令之间不存在相关时,它们在流水线中是可以重叠起来并行执行[6]。
3.任务并行(Task parallelism)
任务并行性是并行程序的一个特征,即“可以对相同或不同的数据集执行完全不同的计算”[7]。这与数据并行性相反,数据并行性是对相同或不同的数据集执行相同的计算。任务并行性涉及将任务分解为子任务,然后将每个子任务分配给处理器以执行。然后,处理器将同时并经常协作地执行这些子任务。任务并行性通常不会随问题的规模而扩展[8]。
4.超字级并行(Superword-level)
超字级并行性是一种基于循环展开和基本块矢量化的矢量化技术。它与循环矢量化算法的不同之处在于,它可以利用内联代码的并行性,例如操纵坐标,颜色通道或手动展开的循环[9]。
2.OpenMP环境搭建
1.什么是OpenMP
OpenMP是一种用于共享内存并行系统的多线程程序设计方案,支持的编程语言包括C、C++和Fortran。OpenMP提供了对并行算法的高层抽象描述,特别适合在多核CPU机器上的并行程序设计。编译器根据程序中添加的pragma指令,自动将程序并行处理,使用OpenMP降低了并行编程的难度和复杂度。当编译器不支持OpenMP时,程序会退化成普通(串行)程序。程序中已有的OpenMP指令不会影响程序的正常编译运行。
1.OpenMP执行模式
OpenMP采用fork-join的执行模式。开始的时候只存在一个主线程,当需要进行并行计算的时候,派生出若干个分支线程来执行并行任务。当并行代码执行完成之后,分支线程会合,并把控制流程交给单独的主线程。
一个典型的fork-join执行模型的示意图如下:

2.三种编程要素
OpenMP编程模型以线程为基础,通过编译制导指令制导并行化,有三种编程要素可以实现并行化控制,他们分别是编译制导、API函数集和环境变量。
1.编译制导
编译制导指令以#pragma omp 开始,后边跟具体的功能指令,格式如:#pragma omp 指令[子句[,子句] …]。常用的功能指令如下:
parallel:用在一个结构块之前,表示这段代码将被多个线程并行执行;
for:用于for循环语句之前,表示将循环计算任务分配到多个线程中并行执行,以实现任务分担,必须由编程人员自己保证每次循环之间无数据相关性;
parallel for:parallel和for指令的结合,也是用在for循环语句之前,表示for循环体的代码将被多个线程并行执行,它同时具有并行域的产生和任务分担两个功能;
sections:用在可被并行执行的代码段之前,用于实现多个结构块语句的任务分担,可并行执行的代码段各自用section指令标出(注意区分sections和section);
parallel sections:parallel和sections两个语句的结合,类似于parallel for;
single:用在并行域内,表示一段只被单个线程执行的代码;
critical:用在一段代码临界区之前,保证每次只有一个OpenMP线程进入;
flush:保证各个OpenMP线程的数据影像的一致性;
barrier:用于并行域内代码的线程同步,线程执行到barrier时要停下等待,直到所有线程都执行到barrier时才继续往下执行;
atomic:用于指定一个数据操作需要原子性地完成;
master:用于指定一段代码由主线程执行;
threadprivate:用于指定一个或多个变量是线程专用,后面会解释线程专有和私有的区别。
相应的OpenMP子句为:
private:指定一个或多个变量在每个线程中都有它自己的私有副本;
firstprivate:指定一个或多个变量在每个线程都有它自己的私有副本,并且私有变量要在进入并行域或任务分担域时,继承主线程中的同名变量的值作为初值;
lastprivate:是用来指定将线程中的一个或多个私有变量的值在并行处理结束后复制到主线程中的同名变量中,负责拷贝的线程是for或sections任务分担中的最后一个线程;
reduction:用来指定一个或多个变量是私有的,并且在并行处理结束后这些变量要执行指定的归约运算,并将结果返回给主线程同名变量;
nowait:指出并发线程可以忽略其他制导指令暗含的路障同步;
num_threads:指定并行域内的线程的数目;
schedule:指定for任务分担中的任务分配调度类型;
shared:指定一个或多个变量为多个线程间的共享变量;
ordered:用来指定for任务分担域内指定代码段需要按照串行循环次序执行;
copyprivate:配合single指令,将指定线程的专有变量广播到并行域内其他线程的同名变量中;
copyin:用来指定一个threadprivate类型的变量需要用主线程同名变量进行初始化;
default:用来指定并行域内的变量的使用方式,缺省是shared。
2.API函数
除上述编译制导指令之外,OpenMP还提供了一组API函数用于控制并发线程的某些行为,下面是一些常用的OpenMP API函数以及说明:

3.环境变量
OpenMP中定义一些环境变量,可以通过这些环境变量控制OpenMP程序的行为,常用的环境变量:
OMP_SCHEDULE:用于for循环并行化后的调度,它的值就是循环调度的类型;
OMP_NUM_THREADS:用于设置并行域中的线程数;
OMP_DYNAMIC:通过设定变量值,来确定是否允许动态设定并行域内的线程数;
OMP_NESTED:指出是否可以并行嵌套。
2.vs2022搭建OpenMP
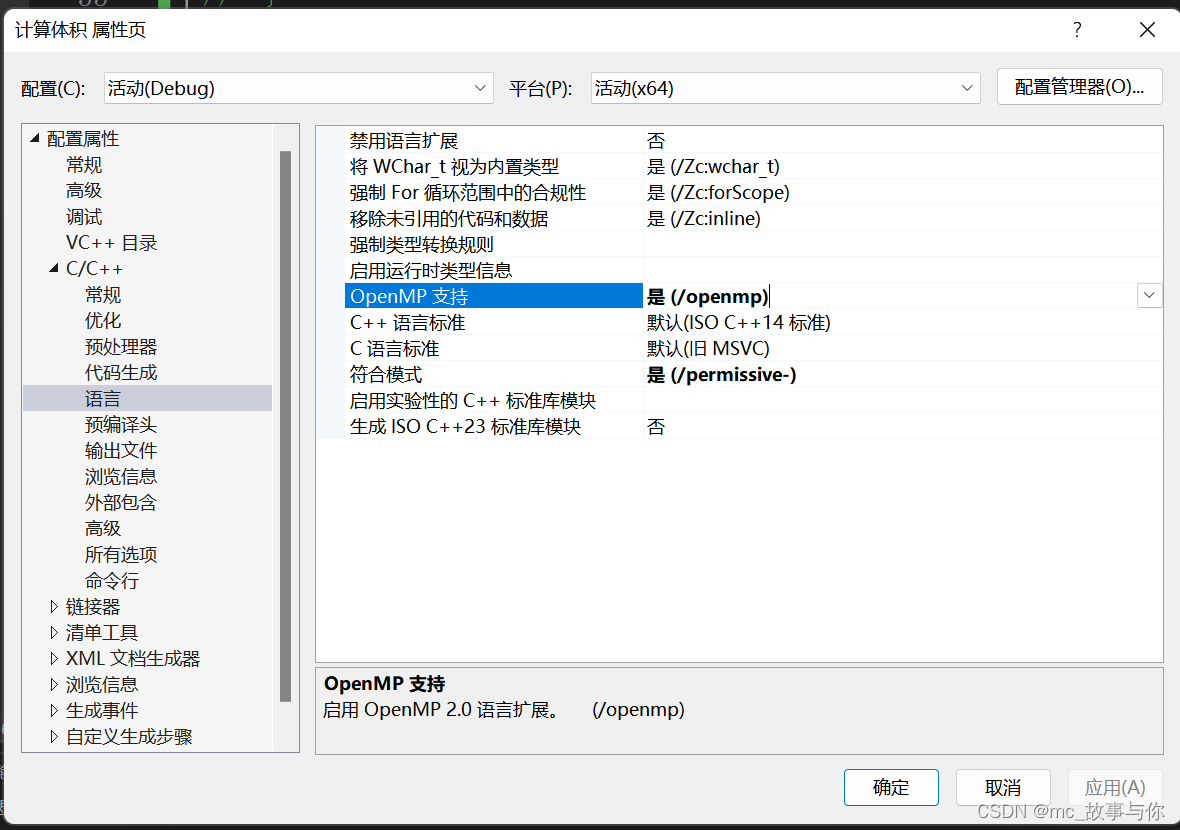
在VS中启用OpenMP很简单,很多主流的编译环境都内置了OpenMP。在项目上右键->属性->配置属性->C/C+±>语言->OpenMP支持,选择“是”即可。
1.右击项目文件,点击属性
2.打开OpenMP
注:有可能属性中找不到c/c++当跑一遍hello入门代码后就会出现

3.测试用例
#include <iostream>
int main()
{
#pragma omp parallel
{
std::cout << "Hello World!\n";
}
}
可以查看电脑核数,我的为8核,则显示8行
//验证OpenMP正确性
#include <iostream>
#include <time.h>
#include <math.h>
#include "omp.h"
using namespace std;
void test_fn(int epochs, int num_thread) {
omp_set_num_threads(num_thread);
double c = 0;
clock_t start = clock();
#pragma omp parallel for
for (int i = 0; i < epochs; i++) {
//随便做一个无用的计算
c += exp(1) * exp(1) * log(2);
}
clock_t end = clock();
cout << num_thread << "线程:用时" << end - start << ends << "循环次数:" << epochs << endl;
}
int main()
{
test_fn(10000000, 1);
test_fn(10000000, 2);
test_fn(10000000, 4);
test_fn(10000000, 8);
return 0;
}
上面代码可以验证OpenMP
3.MPI环境搭建
1.什么是MPI
1.MPI简介
Massage Passing Interface:是消息传递函数库的标准规范,由MPI论坛开发。
一种新的库描述,不是一种语言。共有上百个函数调用接口,提供与C和Fortran语言的绑定
MPI是一种标准或规范的代表,而不是特指某一个对它的具体实现
MPI是一种消息传递编程模型,并成为这种编程模型的代表和事实上的标准
2.MPI的特点
MPI有以下的特点:
消息传递式并行程序设计
指用户必须通过显式地发送和接收消息来实现处理机间的数据交换。
在这种并行编程中,每个并行进程均有自己独立的地址空间,相互之间访问不能直接进行,必须通过显式的消息传递来实现。
这种编程方式是大规模并行处理机(MPP)和机群(Cluster)采用的主要编程方式。
并行计算粒度大,特别适合于大规模可扩展并行算法
用户决定问题分解策略、进程间的数据交换策略,在挖掘潜在并行性方面更主动,并行计算粒度大,特别适合于大规模可扩展并行算法
消息传递是当前并行计算领域的一个非常重要的并行程序设计方式
2.vs2022搭建MPI
1.下载安装包
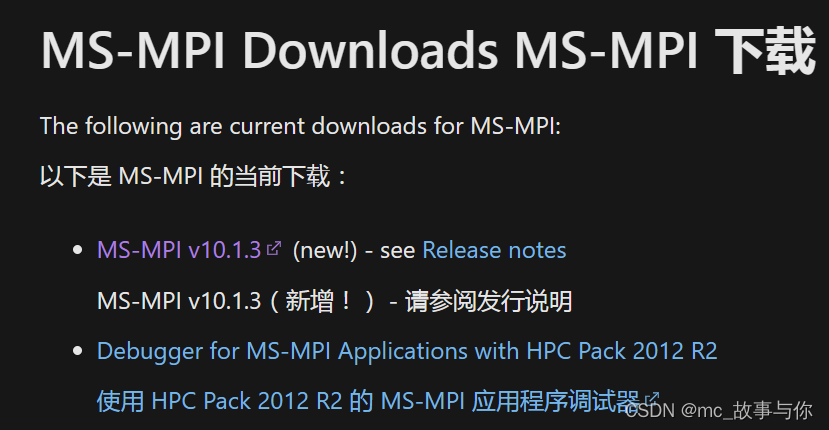
最新的MPI已经由微软进行托管,网址如下:
http://www.mpich.org/downloads/
进入后选择自己对应的操作系统,本文以Windows10为例。点击http进入。
找到Downloads部分,选择最新的下载即可。(new!)
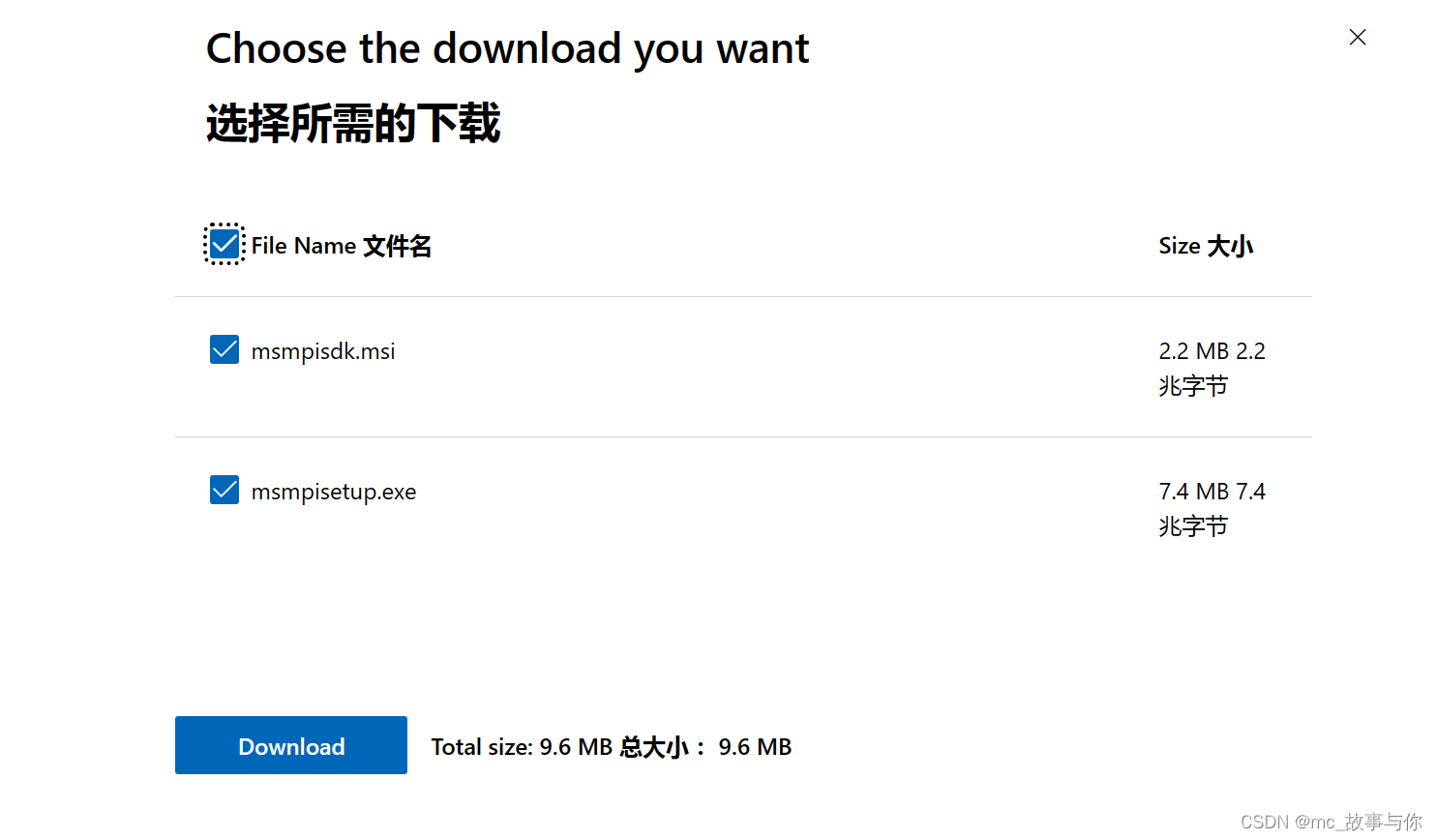
点击downloads
全选进行下载


2.安装MPI
下载后得到两个文件,分别进行安装即可
MSMPI已经帮助我们配置好了Path变量,我们无需手动进行配置。接下来,可以验证一下安装是否成功。
Win+R调出cmd,输入指令set MSMPI,如果出现类似如上图的地址,就表示安装已经成功。



3.配置vs
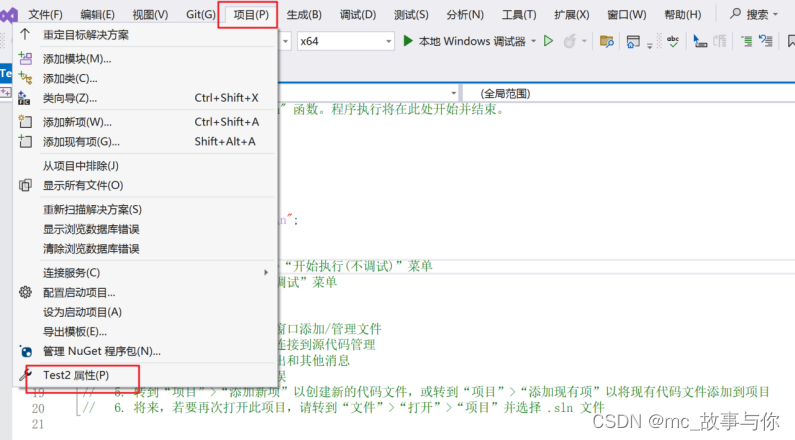
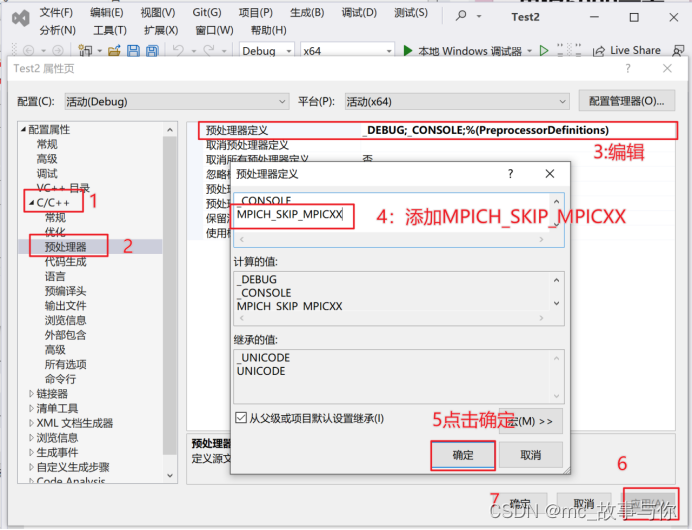
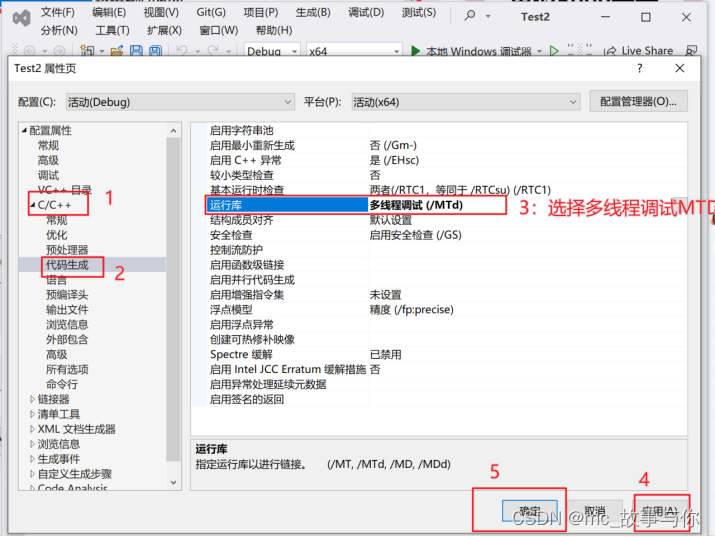
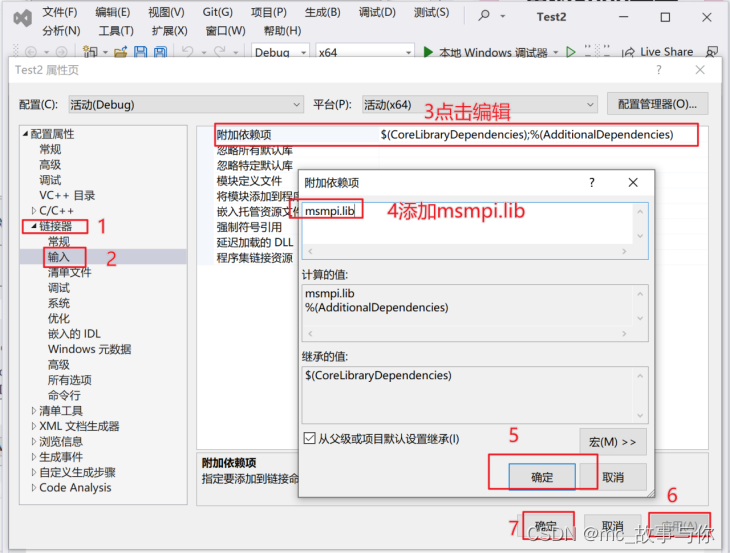
打开VS,选择创建新项目->控制台应用,选择属性。
之后进行如下操作:
以上步骤配置好了之后,程序就可以编译成功了。



3.测试用例
#include<iostream>
#include"mpi.h"
#include<ctime>
#include<cmath>
using namespace std;
const int N = 1000000;
double start, finish;//计算的起止时间
int main(int argc, char* argv[])
{
MPI_Init(&argc, &argv);//MPI库的初始化
int numprocs, myid;//定义进程总数及进程标识
MPI_Comm_size(MPI_COMM_WORLD, &numprocs);//获得进程数
MPI_Comm_rank(MPI_COMM_WORLD, &myid);//获得当前进程标识号0,1,2,3,....,numprocs - 1
start = MPI_Wtime();//获得时间
double partSum = 0.0;//定义部分和
double pi = 0.0;//定义pi的值
for (int i = myid; i < N; i += numprocs)
{
partSum += sqrt(1 - (double(i) / N) * (double(i) / N)) / N;
//partSum += sqrt(1.0 - (double)(i * i) / (N * N))/N; int型乘法会有溢出问题
}
MPI_Reduce(&partSum, &pi, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
//规约操作,将各进程的partSum发送到0号进程并求和
cout << "我的标识是" << myid << ",求得的partSum值为:" << partSum << endl;
if (myid == 0)
{
pi *= 4.0;
finish = MPI_Wtime();
cout << "求得近似的pi值为:" << pi << endl;
cout << "调用" << numprocs << "个进程的计算时间为:" << finish - start << endl;
}
MPI_Finalize();
//system("pause");
return 0;
}
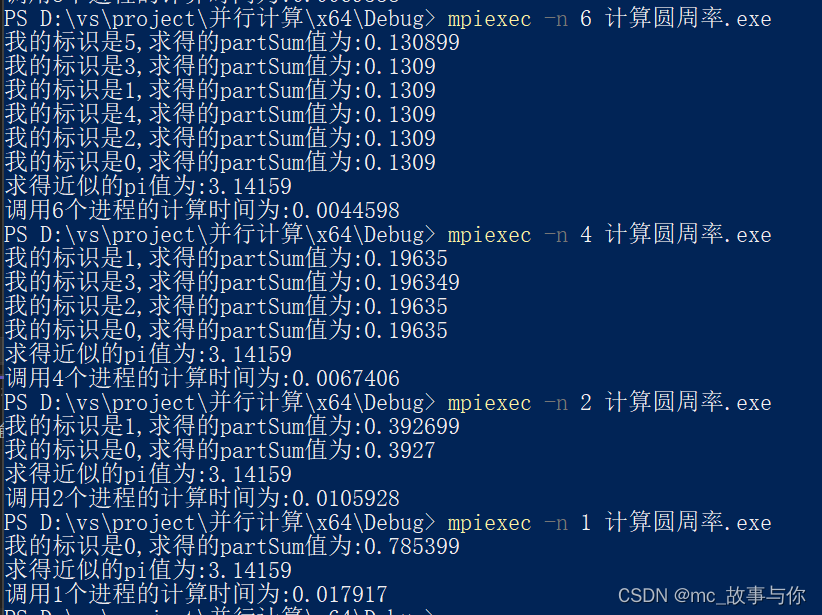
运行成功后,返回生成exe的文件夹,在该文件夹打开power shell,运行脚本

4.MPI 与 OpenMP 的区别
MPI(Message Passing Interface)和OpenMP(Open Multi-Processing)都是用于并行计算的编程模型,但它们在实现并行计算的方式和应用场景上有一些区别。
1.并行模型
MPI是一种消息传递编程模型。它允许在不同进程(通常在不同计算节点上)之间通过消息传递来进行通信和协作。MPI适用于分布式内存系统,如集群或超级计算机,可以在不同的计算节点上运行独立的进程,这些进程通过消息传递来交换数据和同步计算。OpenMP是一种共享内存编程模型。它使用指令来指定需要并行化的代码段,然后由多个线程并发执行这些代码段。OpenMP适用于共享内存系统,如多核处理器或共享内存多处理器系统。
2.编程风格
MPI需要显式地处理进程间的通信和同步。程序员需要定义消息的发送和接收操作,以及进程间的同步。这使得MPI在编程上相对较复杂,但同时也提供了更细粒度的控制和更灵活的并行策略。OpenMP通过使用编译器指令(pragma)来实现并行化。程序员可以在代码中插入指令来告诉编译器哪些部分可以并行执行。这使得OpenMP在编程上相对简单,对于某些类型的并行任务,可以更容易地实现并行化。
3.应用场景
MPI通常用于解决需要高度并行化的大规模科学和工程计算问题,如天气模拟、流体力学、分子动力学等。它在分布式内存系统上的灵活性使其可以在大规模集群上有效扩展。OpenMP更适合于解决在单个节点上可并行化的任务,例如循环并行化、数据并行化等。它在共享内存系统中的开销较小,可以利用多核处理器的并行性。
4.可扩展性
MPI的可扩展性较好,因为它可以在大规模集群上运行,并且进程间通信的开销相对较小。在多节点的情况下,MPI通常能够实现很好的性能扩展。OpenMP的可扩展性受限于共享内存系统的规模和硬件限制。在多核处理器上,OpenMP可以获得相对较好的性能扩展,但在超大规模并行任务中,其可扩展性可能不如MPI。
总的来说,MPI和OpenMP是两种不同的并行编程模型,各有其适用的场景。在选择哪种模型时,需要考虑到问题规模、系统架构、通信开销以及编程复杂性等因素。有时候,也可以将MPI和OpenMP结合使用,以在不同层次上实现更细粒度的并行化。















 4054
4054











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









