







1.OpenMP
1.调用并行计算
1.代码
#include <iostream>
#include "omp.h"
using std::cout;
using std::endl;
int main()
{
#pragma omp parallel
cout<<"hello,openmp!"<<endl;
}
2.运行结果
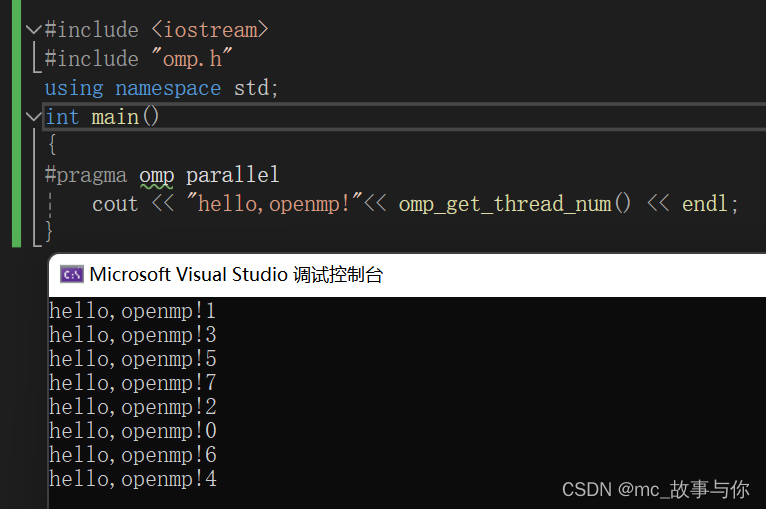
3.omp_get_thread_num()
omp_get_thread_num()函数用于获取当前执行迭代的线程编号
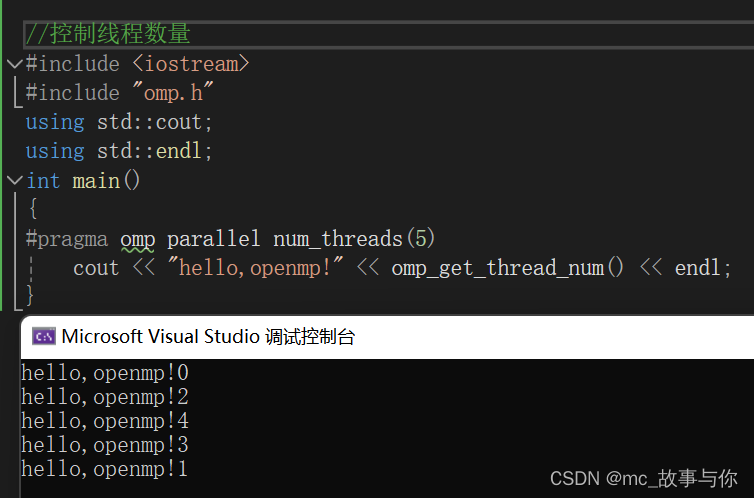
2.控制线程数量
1.num_threads()
使用预处理指令的num_threads()来设置线程数量
#include <iostream>
#include "omp.h"
using std::cout;
using std::endl;
int main()
{
#pragma omp parallel num_threads(5)
cout<<"hello,openmp!"<<endl;
}
运行结果
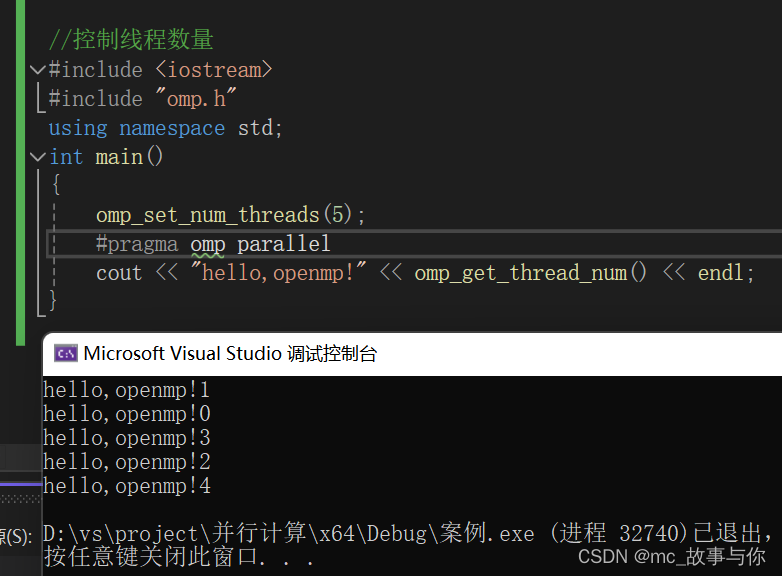
2.API omp_set_num_threads()
使用API omp_set_num_threads()控制线程数量
#include <iostream>
#include "omp.h"
using std::cout;
using std::endl;
int main()
{
omp_set_num_threads(5)
#pragma omp parallel{
cout<<"hello,openmp!"<<endl;
}
}
运行结果
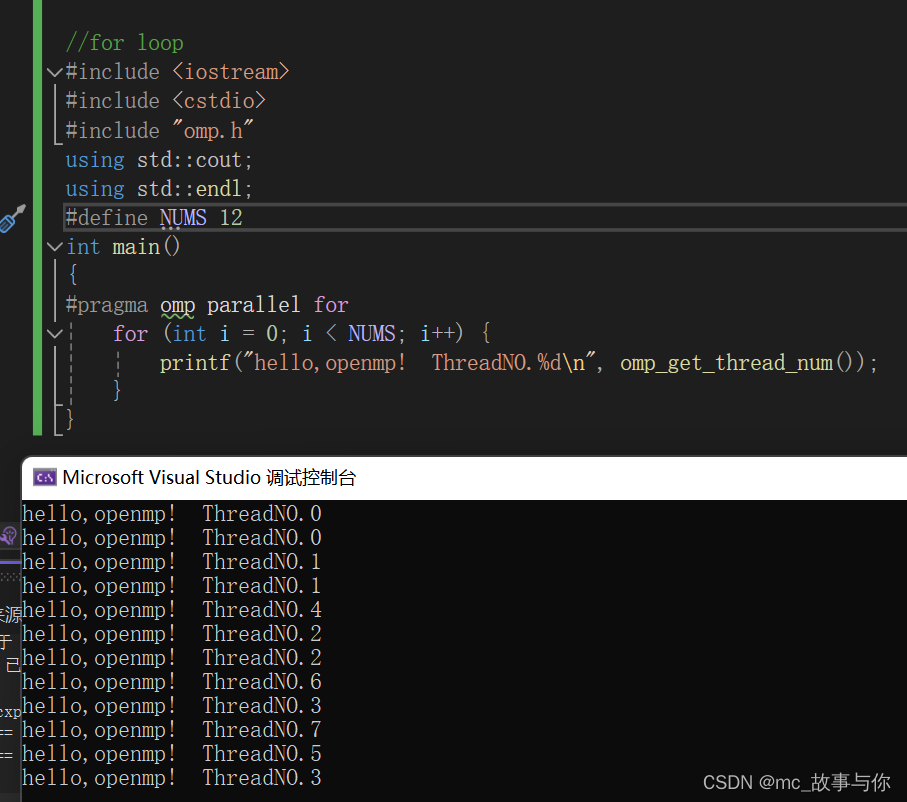
3.for loop
1.命令说明
#pragma omp parallel for是OpenMP API中的一个编译器指令,用于在C/C++程序中实现并行计算。这个指令告诉编译器下面的for循环应该被并行执行,即循环的迭代被分配到多个线程中,以便同时执行。这样做的目的是为了利用现代多核处理器的并行处理能力,从而加速循环的执行时间。
2.解析命令
#pragma omp:这是OpenMP的指令前缀,所有OpenMP指令都以这个前缀开始。
parallel:这个关键字指示编译器创建一个并行区域,其中的代码将由多个线程并行执行。
for:这个关键字指示紧随其后的for循环是要并行执行的循环。
3.代码
omp会分配一定数量的线程,每个线程会负责执行某几次循环
2.MPI
1.第一个MPI程序“Hello Word”
1.代码区块划分

2.程序的执行流程
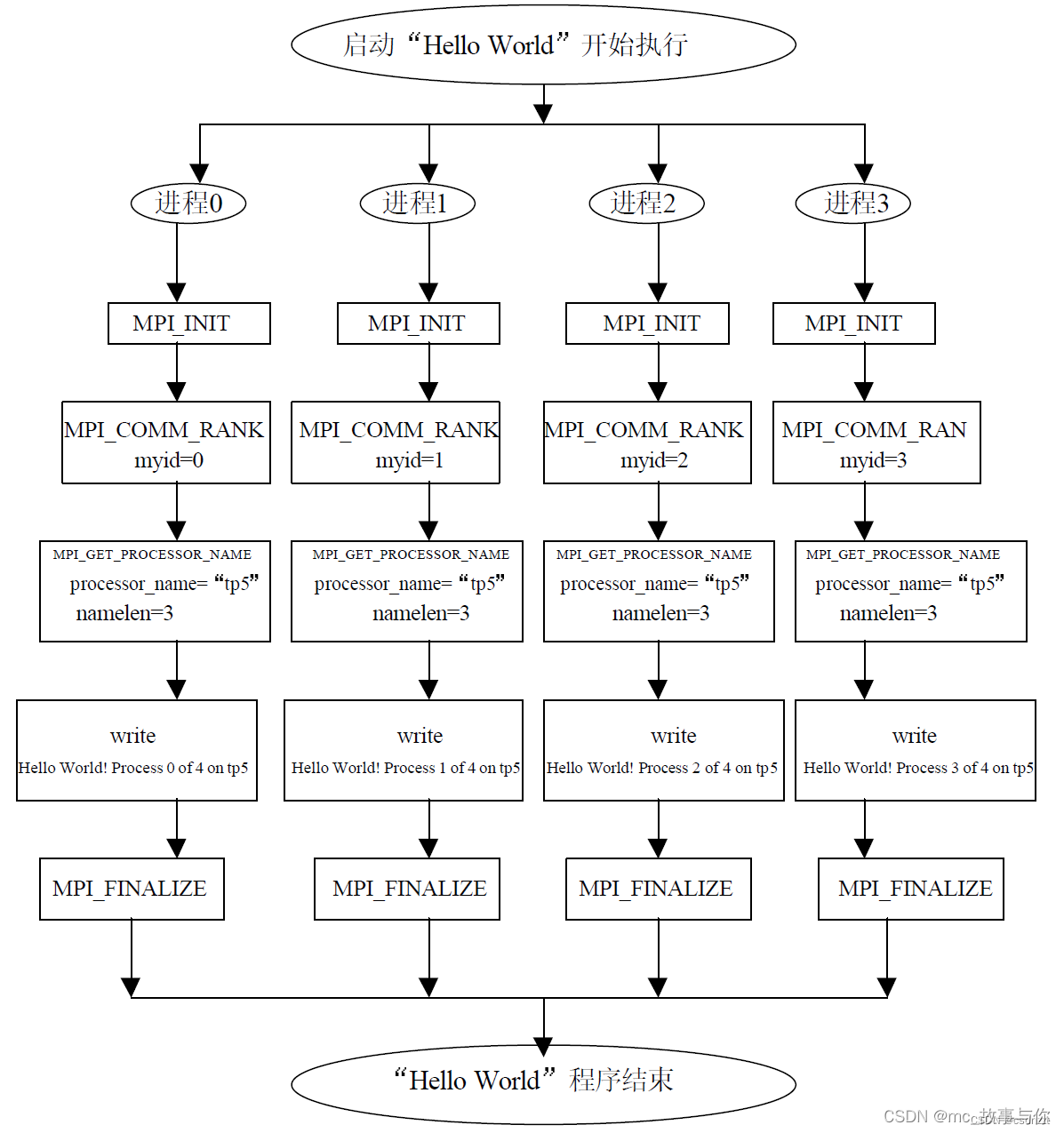
2.MPI六个基本函数
1.MPI_Init MPI初始化
任何MPI程序都应该首先调用该函数。 此函数不必深究,只需在MPI程序开始时调用即可(必须保证程序中第一个调用的MPI函数是这个函数)。
例:
MPI_Init(&argc, &argv) //C++ & C
2.MPI_Finalize() MPI结束
任何MPI程序结束时,都需要调用该函数。切记Fortran在调用MPI_Finalize的时候,需要加个参数ierr来接收返回的值,否则计算结果可能会出问题甚至编译报错。
例:
MPI_Finalize(); // MPI程序结束前的清理工作
3.MPI_COMM_RANK 当前进程标识
MPI_Comm_Rank(MPI_Comm comm, int *rank)
该函数是获得当前进程的进程标识,如进程0在执行该函数时,可以获得返回值0。可以看出该函数接口有两个参数,前者为进程所在的通信域,后者为返回的进程号。通信域可以理解为给进程分组,比如有0-5这六个进程。可以通过定义通信域,来将比如[0,1,5]这三个进程分为一组,这样就可以针对该组进行“组”操作,比如规约之类的操作。MPI_COMM_WORLD是MPI已经预定义好的通信域,是一个包含所有进程的通信域,目前只需要用该通信域即可。
在调用该函数时,需要先定义一个整型变量如myid,不需要赋值。将该变量传入函数中,会将该进程号存入myid变量中并返回。
4.MPI_COMM_SIZE 通信域包含的进程数
该函数是获取该通信域内的总进程数,如果通信域为MP_COMM_WORLD,即获取总进程数,使用方法和MPI_COMM_RANK相近。
例子
MPI_COMM_SIZE(comm, size) int MPI_Comm_Size(MPI_Comm, int *size)
5.MPI_SEND 消息发送
该函数为发送函数,用于进程间发送消息,如进程0计算得到的结果A,需要传给进程1,就需要调用该函数。
call MPI_SEND(buf, count, datatype, dest, tag, comm) int MPI_Send(type* buf, int count, MPI_Datatype, int dest, int tag, MPI_Comm comm)
该函数参数过多,不过这些参数都很有必要存在。
这些参数均为传入的参数,其中buf为你需要传递的数据的起始地址,比如你要传递一个数组A,长度是5,则buf为数组A的首地址。count即为长度,从首地址之后count个变量。datatype为变量类型,注意该位置的变量类型是MPI预定义的变量类型,比如需要传递的是C++的int型,则在此处需要传入的参数是MPI_INT,其余同理。dest为接收的进程号,即被传递信息进程的进程号。tag为信息标志,同为整型变量,发送和接收需要tag一致,这将可以区分同一目的地的不同消息。比如进程0给进程1分别发送了数据A和数据B,tag可分别定义成0和1,这样在进程1接收时同样设置tag0和1去接收,避免接收混乱。
6.MPI_RECV 消息接收
该函数为MPI的接收函数,需要和MPI_SEND成对出现
call MPI_RECV(buf, count, datatype, source, tag, comm,status) int MPI_Recv(type* buf, int count, MPI_Datatype, int source, int tag, MPI_Comm comm, MPI_Status *status)
参数和MPI_SEND大体相同,不同的是source这一参数,这一参数标明从哪个进程接收消息。最后多一个用于返回状态信息的参数status。
在C和C++中,status的变量类型为MPI_Status,分别有三个域,可以通过status.MPI_SOURCE,status.MPI_TAG和status.MPI_ERROR的方式调用这三个信息。这三个信息分别返回的值是所收到数据发送源的进程号,该消息的tag值和接收操作的错误代码。
SEND和RECV需要成对出现,若两进程需要相互发送消息时,对调用的顺序也有要求,不然可能会出现死锁或内存溢出等比较严重的问题
3.调用并行计算
1.对于rank,size的理解
#include <mpi.h>
#include <stdio.h>
int main(int argc, char **argv)
{
int num, rk;
MPI_Init(&argc, &argv); // MPI初始化
MPI_Comm_size(MPI_COMM_WORLD, &num); // 获取进程总数
MPI_Comm_rank(MPI_COMM_WORLD, &rk); // 获取当前进程的编号
printf("Hello world from Process %d of %d\n", rk, num); // 打印当前进程的编号和总进程数量
MPI_Finalize(); // MPI程序结束前的清理工作
}
在不同的进程数中运行代码,可以看到并不是按顺序输出的,这说明各个进程所用的时间不一样,先完成的进程先输出了。这也是并行的特点之一。
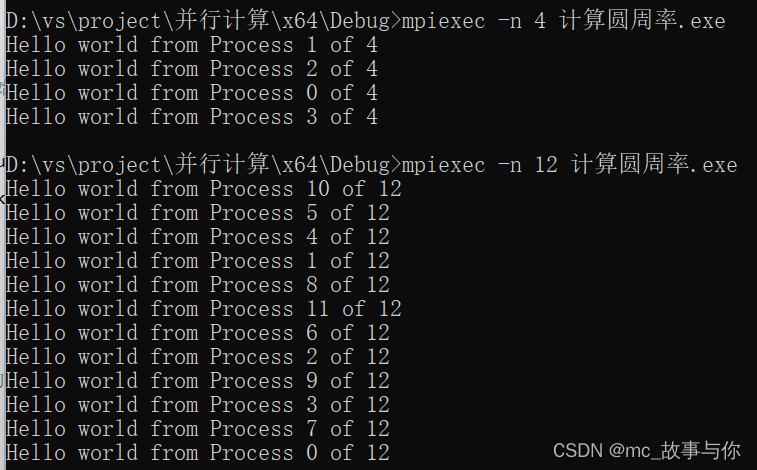
2.对于发送、接收的理解
#include <iostream> // 引入输入输出流库
#include <mpi.h> // 引入MPI库
int main(int argc, char** argv) { // 主函数入口,接受命令行参数
MPI_Init(&argc, &argv); // MPI初始化
int rank, size;
MPI_Comm_rank(MPI_COMM_WORLD, &rank); // 获取当前进程编号
MPI_Comm_size(MPI_COMM_WORLD, &size); // 获取总进程数
if (size < 2) { // 检查进程数是否小于2
std::cerr << "This program requires at least 2 processes.\n"; // 输出错误信息
MPI_Abort(MPI_COMM_WORLD, 1); // 终止MPI环境
}
if (rank == 0) { // 如果当前进程是0号进程
int message = 42; // 定义消息
MPI_Send(&message, 1, MPI_INT, 1, 0, MPI_COMM_WORLD); // 发送消息给进程1
std::cout << "Process 0 sent message: " << message << std::endl; // 输出发送消息的信息
}
else if (rank == 1) { // 如果当前进程是1号进程
int message; // 定义消息变量
MPI_Recv(&message, 1, MPI_INT, 0, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE); // 接收来自进程0的消息
std::cout << "Process 1 received message: " << message << std::endl; // 输出接收到的消息
}
MPI_Finalize(); // 结束MPI环境
return 0; // 返回程序执行成功的标志
}
参数解析
1.发送消息的函数
MPI_Send(void* buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm):发送消息的函数。
buf:指向发送数据缓冲区的指针。
count:发送数据的数量。
datatype:发送数据的类型,比如 MPI_INT 表示整型数据。
dest:目标进程的标识号。
tag:消息的标签,用于区分不同类型的消息。
comm:通信域,通常使用 MPI_COMM_WORLD 表示全局通信。
2.接收消息的函数
MPI_Recv(void* buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Status* status):接收消息的函数。
buf:指向接收数据缓冲区的指针。
count:接收数据的数量。
datatype:接收数据的类型。
source:消息来源的进程标识号。
tag:消息的标签,需要与发送时匹配。
comm:通信域,通常使用 MPI_COMM_WORLD。
status:接收消息的状态对象,可以使用 MPI_STATUS_IGNORE 来忽略状态信息。
在代码中的具体应用如下:
1.发送
MPI_Send(&message, 1, MPI_INT, 1, 0, MPI_COMM_WORLD);
发送整型数据 message 到进程标识号为 1 的进程。
MPI_INT 表示发送的数据类型为整型。
1 表示目标进程的标识号为 1。
0 表示消息的标签,这里是用于区分不同类型消息的一个标记。
MPI_COMM_WORLD 表示全局通信域。
2.接收
MPI_Recv(&message, 1, MPI_INT, 0, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
接收来自进程标识号为 0 的进程的整型数据,并存储到 message 中。
MPI_INT 表示接收的数据类型为整型。
0 表示消息来源的进程标识号为 0。
0 表示消息的标签,需要与发送时匹配。
MPI_COMM_WORLD 表示全局通信域。
MPI_STATUS_IGNORE 表示忽略接收消息的状态信息。
MPI初始化后,通过循环下标控制多个进程向主进程发送消息,主进程接收并打印。发送和接收消息是对应的
结果

4.计算圆周率
1.公式解释
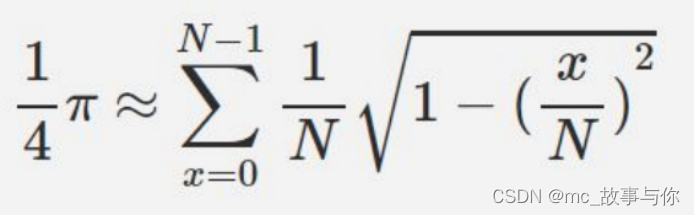
2.代码
#include<iostream>
#include"mpi.h"
#include<ctime>
#include<cmath>
using namespace std;
const int N = 1000000; // 计算步数
double start, finish; // 计算的起止时间
int main(int argc, char* argv[])
{
MPI_Init(&argc, &argv); // MPI 库的初始化
int numprocs, myid; // 定义进程总数及进程标识
MPI_Comm_size(MPI_COMM_WORLD, &numprocs); // 获得进程数
MPI_Comm_rank(MPI_COMM_WORLD, &myid); // 获得当前进程标识号 0, 1, 2, 3, ..., numprocs - 1
start = MPI_Wtime(); // 获取当前时间,用于计时
double partSum = 0.0; // 定义部分和
double pi = 0.0; // 定义 pi 的值
// 循环计算每个进程的部分和
for (int i = myid; i < N; i += numprocs)
{
partSum += sqrt(1 - (double(i) / N) * (double(i) / N)) / N;
// partSum += sqrt(1.0 - (double)(i * i) / (N * N)) / N; // int 型乘法会有溢出问题,建议使用上面的方式
}
MPI_Reduce(&partSum, &pi, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
// 规约操作,将各进程的 partSum 发送到 0 号进程并求和
cout << "我的标识是" << myid << ",求得的 partSum 值为:" << partSum << endl;
if (myid == 0)
{
pi *= 4.0; // 计算 pi 的近似值
finish = MPI_Wtime(); // 获取结束时间
cout << "求得近似的 pi 值为:" << pi << endl;
cout << "调用" << numprocs << "个进程的计算时间为:" << finish - start << endl;
}
MPI_Finalize(); // 结束 MPI 库
return 0;
}
发送的参数解析
&partSum:发送进程(各个进程)的部分和的指针。
&pi:接收进程(0号进程)的存储结果的变量的指针。
1:发送数据的数量,这里是一个双精度浮点数。
MPI_DOUBLE:数据类型,这里是双精度浮点数。
MPI_SUM:操作符,表示求和操作。
0:接收进程的标识号,即接收结果的进程,在这里是0号进程。
MPI_COMM_WORLD:通信域,表示全局通信。















 1527
1527











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









