






第二课 问君文本何所似:词的向量表示Word2Vec和Embedding
2.1 词向量≈词嵌入
词向量通常也叫词嵌入,是一种寻找词和词之间相似性的NLP技术,它把词汇各个维度上的特征用数值向量进行表示,利用这些维度上特征的相似程度可以判断哪些词和哪些词语义更接近。在实际运用中,词向量和词嵌入两个重要术语其实可以互换使用,都表示将词汇表中单词映射到固定大小的连续向量空间的过程。但是在默写情况下也可能有细微的差别:
词向量:通常用于描述具体的向量表示,即一个词对应的实际数值向量。例如我们可以说“‘cat’这个词的词向量是一个300维的向量”。
词嵌入:通常用于描述将词映射到向量空间的过程或者表示方法。通常包括训练算法和生成的词向量空间,例如我们可以说“我们使用Word2Vec算法来生成词嵌入”。
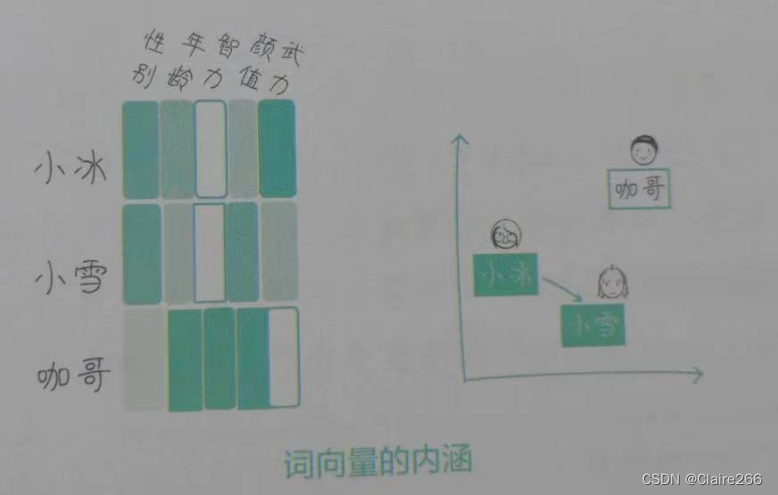
初始状态的词向量是一组无意义的多维数据。如果在语料库中,“小冰”“小雪”这两个词总是和“女生”一起出现,那么,在这些词的学习过程中,我们按照某种算法逐渐更新词向量数据,就会有一个或一些维度的向量开始蕴含与“性别”相关的信息,而这一行或几行数值,我们就可以理解成“性别向量。如果“小冰”“小雪”这两个词也总是和“年轻”一起出现,那么在某个维度,就会表示“年龄”相关的信息,这一行数值可以理解成“年龄向量”;这样,这些词就变成了向量组合,综合各个维度进行比较,“小冰”和“小雪”的余弦相似度就会高,而“咖哥”这个词在各个维度上都和它们不同,与它们的余弦相似度就低。也就是说,我们把库中的词和某些上下文信息,都“嵌入”了向量表示中。
我们从语料库中学习和发现词的“维度”和“向量表示”
2.2 Word2Vec:CBOW模型和Skip-Gram模型
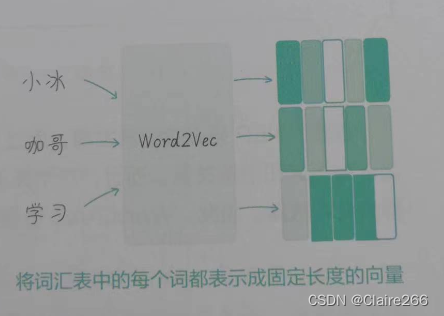
Word2Vec采用了一种高效的方法来学习词汇的连续向量表示,这种方法将词汇表中的每一个词都表达成固定长度的向量从而使在大规模数据集上进行训练变得可行。通过Word2Vec学习得到的向量可以捕捉到词和词之间的语义和语法关系,Word2Vec通过训练一个神经网络模型来学习词嵌入,模型的任务就是基于给定的上下文词来预测目标词,或者基于目标词来预测上下文词。
Word2Vec有两种主要的实现方式:CBOW(连续词袋)模型和Skip-Gram(跳字)模型。CBOW模型通过给定上下文来预测目标词,而Skip-Gram通过目标词来预测上下文。两个模型都是通过训练神经网络来学习词向量的。在训练过程中通过最小化预测词和实际词之间的损失来学习词向量。训练完成后将词向量提取出来。
2.3 Skip-Gram模型的代码实现
使用Skip-Gram模型实现Word2Vec模型,通过学习词的向量表示来捕捉词和词之间的语义和语法关系。程序结构如下:
(1)构建实验语料库
# 定义一个句子列表,后面会用这些句子来训练 CBOW 和 Skip-Gram 模型
sentences = ["Kage is Teacher", "Mazong is Boss", "Niuzong is Boss",
"Xiaobing is Student", "Xiaoxue is Student",]
# 将所有句子连接在一起,然后用空格分隔成多个单词
words = ' '.join(sentences).split()
# 构建词汇表,去除重复的词
word_list = list(set(words))
# 创建一个字典,将每个词映射到一个唯一的索引
word_to_idx = {word: idx for idx, word in enumerate(word_list)}
# 创建一个字典,将每个索引映射到对应的词
idx_to_word = {idx: word for idx, word in enumerate(word_list)}
voc_size = len(word_list) # 计算词汇表的大小
print(" 词汇表:", word_list) # 输出词汇表
print(" 词汇到索引的字典:", word_to_idx) # 输出词汇到索引的字典
print(" 索引到词汇的字典:", idx_to_word) # 输出索引到词汇的字典
print(" 词汇表大小:", voc_size) # 输出词汇表大小(2)生成Skip-Gram数据
# 生成 Skip-Gram 训练数据
def create_skipgram_dataset(sentences, window_size=2):
data = [] # 初始化数据
for sentence in sentences: # 遍历句子
sentence = sentence.split() # 将句子分割成单词列表
for idx, word in enumerate(sentence): # 遍历单词及其索引
# 获取相邻的单词,将当前单词前后各 N 个单词作为相邻单词
for neighbor in sentence[max(idx - window_size, 0):
min(idx + window_size + 1, len(sentence))]:
if neighbor != word: # 排除当前单词本身
# 将相邻单词与当前单词作为一组训练数据
data.append((neighbor, word))
return data
# 使用函数创建 Skip-Gram 训练数据
skipgram_data = create_skipgram_dataset(sentences)
# 打印未编码的 Skip-Gram 数据样例(前 3 个)
print("Skip-Gram 数据样例(未编码):", skipgram_data[:3])(3)进行One-Hot编码
# 定义 One-Hot 编码函数
import torch # 导入 torch 库
def one_hot_encoding(word, word_to_idx):
tensor = torch.zeros(len(word_to_idx)) # 创建一个长度与词汇表相同的全 0 张量
tensor[word_to_idx[word]] = 1 # 将对应词的索引设为 1
return tensor # 返回生成的 One-Hot 向量
# 展示 One-Hot 编码前后的数据
word_example = "Teacher"
print("One-Hot 编码前的单词:", word_example)
print("One-Hot 编码后的向量:", one_hot_encoding(word_example, word_to_idx))
# 展示编码后的 Skip-Gram 训练数据样例
print("Skip-Gram 数据样例(已编码):", [(one_hot_encoding(context, word_to_idx),
word_to_idx[target]) for context, target in skipgram_data[:3]])此时One-Hot编码后的数据是向量,这种形式的向量就是稀疏向量,其长度等于词汇表大小。此处目的是通过学习将稀疏向量压缩为更具表现力的稠密向量。
(4)定义Skip-Gram类
# 定义 Skip-Gram 类
import torch.nn as nn # 导入 neural network
class SkipGram(nn.Module):
def __init__(self, voc_size, embedding_size):
super(SkipGram, self).__init__()
# 从词汇表大小到嵌入层大小(维度)的线性层(权重矩阵)
self.input_to_hidden = nn.Linear(voc_size, embedding_size, bias=False)
# 从嵌入层大小(维度)到词汇表大小的线性层(权重矩阵)
self.hidden_to_output = nn.Linear(embedding_size, voc_size, bias=False)
def forward(self, X): # 前向传播的方式,X 形状为 (batch_size, voc_size)
# 通过隐藏层,hidden 形状为 (batch_size, embedding_size)
hidden = self.input_to_hidden(X)
# 通过输出层,output_layer 形状为 (batch_size, voc_size)
output = self.hidden_to_output(hidden)
return output
embedding_size = 2 # 设定嵌入层的大小,这里选择 2 是为了方便展示
skipgram_model = SkipGram(voc_size, embedding_size) # 实例化 Skip-Gram 模型
print("Skip-Gram 模型:", skipgram_model)(5)训练Skip-Gram类
# 训练 Skip-Gram 类
learning_rate = 0.001 # 设置学习速率
epochs = 1000 # 设置训练轮次
criterion = nn.CrossEntropyLoss() # 定义交叉熵损失函数
import torch.optim as optim # 导入随机梯度下降优化器
optimizer = optim.SGD(skipgram_model.parameters(), lr=learning_rate)
# 开始训练循环
loss_values = [] # 用于存储每轮的平均损失值
for epoch in range(epochs):
loss_sum = 0 # 初始化损失值
for context, target in skipgram_data:
X = one_hot_encoding(target, word_to_idx).float().unsqueeze(0) # 将中心词转换为 One-Hot 向量
y_true = torch.tensor([word_to_idx[context]], dtype=torch.long) # 将周围词转换为索引值
y_pred = skipgram_model(X) # 计算预测值
loss = criterion(y_pred, y_true) # 计算损失
loss_sum += loss.item() # 累积损失
optimizer.zero_grad() # 清空梯度
loss.backward() # 反向传播
optimizer.step() # 更新参数
if (epoch+1) % 100 == 0: # 输出每 100 轮的损失,并记录损失
print(f"Epoch: {epoch+1}, Loss: {loss_sum/len(skipgram_data)}")
loss_values.append(loss_sum / len(skipgram_data))
# 绘制训练损失曲线
import matplotlib.pyplot as plt # 导入 matplotlib
# 绘制二维词向量图
plt.rcParams["font.family"]=['SimHei'] # 用来设定字体样式
plt.rcParams['font.sans-serif']=['SimHei'] # 用来设定无衬线字体样式
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
plt.plot(range(1, epochs//100 + 1), loss_values) # 绘图
plt.title(' 训练损失曲线 ') # 图题
plt.xlabel(' 轮次 ') # X 轴 Label
plt.ylabel(' 损失 ') # Y 轴 Label
plt.show() # 显示图(6)展示词向量
fig, ax = plt.subplots()
for word, idx in word_to_idx.items():
# 获取每个单词的嵌入向量
vec = skipgram_model.input_to_hidden.weight[:,idx].detach().numpy()
ax.scatter(vec[0], vec[1]) # 在图中绘制嵌入向量的点
ax.annotate(word, (vec[0], vec[1]), fontsize=12) # 点旁添加单词标签
plt.title(' 二维词嵌入 ') # 图题
plt.xlabel(' 向量维度 1') # X 轴 Label
plt.ylabel(' 向量维度 2') # Y 轴 Label
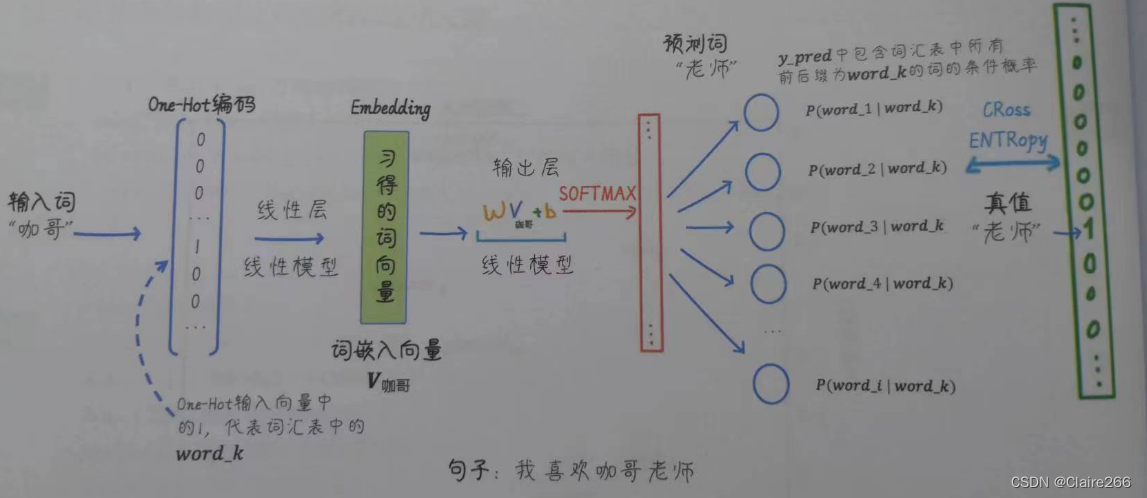
plt.show() # 显示图这里的Word2Vec模型包括输入层、隐藏层和输出层。输入层接收中心词(经过One-Hot编码后的向量形式),接下来输入层到隐藏层的权重矩阵将向量转换为词嵌入,该词嵌入直接作为隐藏层的输出到输出层的权重矩阵将隐藏层的输出转换成一个概率分布用于预测和中心词相关的周围词。通过最小化预测词和实际目标词之间的分类交叉熵损失可以学习词嵌入向量。
2.4 CBOW模型的代码实现
CBOW模型的主要任务是根据给定的周围词来预测中心词。
(1)构建数据集
# 定义一个句子列表,后面会用这些句子来训练 CBOW 和 Skip-Gram 模型
sentences = ["Kage is Teacher", "Mazong is Boss", "Niuzong is Boss",
"Xiaobing is Student", "Xiaoxue is Student",]
# 将所有句子连接在一起,然后用空格分隔成多个单词
words = ' '.join(sentences).split()
# 构建词汇表,去除重复的词
word_list = list(set(words))
# 创建一个字典,将每个词映射到一个唯一的索引
word_to_idx = {word: idx for idx, word in enumerate(word_list)}
# 创建一个字典,将每个索引映射到对应的词
idx_to_word = {idx: word for idx, word in enumerate(word_list)}
voc_size = len(word_list) # 计算词汇表的大小
print(" 词汇表:", word_list) # 输出词汇表
print(" 词汇到索引的字典:", word_to_idx) # 输出词汇到索引的字典
print(" 索引到词汇的字典:", idx_to_word) # 输出索引到词汇的字典
print(" 词汇表大小:", voc_size) # 输出词汇表大小(2)生成训练数据
# 生成 CBOW 训练数据
def create_cbow_dataset(sentences, window_size=2):
data = []# 初始化数据
for sentence in sentences:
sentence = sentence.split() # 将句子分割成单词列表
for idx, word in enumerate(sentence): # 遍历单词及其索引
# 获取上下文词汇,将当前单词前后各 window_size 个单词作为周围词
context_words = sentence[max(idx - window_size, 0):idx] \
+ sentence[idx + 1:min(idx + window_size + 1, len(sentence))]
# 将当前单词与上下文词汇作为一组训练数据
data.append((word, context_words))
return data
# 使用函数创建 CBOW 训练数据
cbow_data = create_cbow_dataset(sentences)
# 打印未编码的 CBOW 数据样例(前三个)
print("CBOW 数据样例(未编码):", cbow_data[:3])(3)定义One-Hot编码
# 定义 One-Hot 编码函数
import torch # 导入 torch 库
def one_hot_encoding(word, word_to_idx):
tensor = torch.zeros(len(word_to_idx)) # 创建一个长度与词汇表相同的全 0 张量
tensor[word_to_idx[word]] = 1 # 将对应词的索引设为 1
return tensor # 返回生成的 One-Hot 向量
# 展示 One-Hot 编码前后的数据
word_example = "Teacher"
print("One-Hot 编码前的单词:", word_example)
print("One-Hot 编码后的向量:", one_hot_encoding(word_example, word_to_idx))(4)定义COBW类
# 定义 CBOW 模型
import torch.nn as nn # 导入 neural network
class CBOW(nn.Module):
def __init__(self, voc_size, embedding_size):
super(CBOW, self).__init__()
# 从词汇表大小到嵌入大小的线性层(权重矩阵)
self.input_to_hidden = nn.Linear(voc_size,
embedding_size, bias=False)
# 从嵌入大小到词汇表大小的线性层(权重矩阵)
self.hidden_to_output = nn.Linear(embedding_size,
voc_size, bias=False)
def forward(self, X): # X: [num_context_words, voc_size]
# 生成嵌入:[num_context_words, embedding_size]
embeddings = self.input_to_hidden(X)
# 计算隐藏层,求嵌入的均值:[embedding_size]
hidden_layer = torch.mean(embeddings, dim=0)
# 生成输出层:[1, voc_size]
output_layer = self.hidden_to_output(hidden_layer.unsqueeze(0))
return output_layer
embedding_size = 2 # 设定嵌入层的大小,这里选择 2 是为了方便展示
cbow_model = CBOW(voc_size,embedding_size) # 实例化 CBOW 模型
print("CBOW 模型:", cbow_model)(5)训练COBW类
# 训练 CBOW类
learning_rate = 0.001 # 设置学习速率
epochs = 1000 # 设置训练轮次
criterion = nn.CrossEntropyLoss() # 定义交叉熵损失函数
import torch.optim as optim # 导入随机梯度下降优化器
optimizer = optim.SGD(cbow_model.parameters(), lr=learning_rate)
# 开始训练循环
loss_values = [] # 用于存储每轮的平均损失值
for epoch in range(epochs):
loss_sum = 0 # 初始化损失值
for target, context_words in cbow_data:
# 将上下文词转换为 One-Hot 向量并堆叠
X = torch.stack([one_hot_encoding(word, word_to_idx) for word in context_words]).float()
# 将目标词转换为索引值
y_true = torch.tensor([word_to_idx[target]], dtype=torch.long)
y_pred = cbow_model(X) # 计算预测值
loss = criterion(y_pred, y_true) # 计算损失
loss_sum += loss.item() # 累积损失
optimizer.zero_grad() # 清空梯度
loss.backward() # 反向传播
optimizer.step() # 更新参数
if (epoch+1) % 100 == 0: # 输出每 100 轮的损失,并记录损失
print(f"Epoch: {epoch+1}, Loss: {loss_sum/len(cbow_data)}")
loss_values.append(loss_sum / len(cbow_data))
# 绘制训练损失曲线
import matplotlib.pyplot as plt # 导入 matplotlib
# 绘制二维词向量图
plt.rcParams["font.family"]=['SimHei'] # 用来设定字体样式
plt.rcParams['font.sans-serif']=['SimHei'] # 用来设定无衬线字体样式
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
plt.plot(range(1, epochs//100 + 1), loss_values) # 绘图
plt.title(' 训练损失曲线 ') # 图题
plt.xlabel(' 轮次 ') # X 轴 Label
plt.ylabel(' 损失 ') # Y 轴 Label
plt.show() # 显示图(6)输出词向量
fig, ax = plt.subplots()
for word, idx in word_to_idx.items():
# 获取每个单词的嵌入向量
vec = cbow_model.input_to_hidden.weight[:,idx].detach().numpy()
ax.scatter(vec[0], vec[1]) # 在图中绘制嵌入向量的点
ax.annotate(word, (vec[0], vec[1]), fontsize=12) # 点旁添加单词标签
plt.title(' 二维词嵌入 ') # 图题
plt.xlabel(' 向量维度 1') # X 轴 Label
plt.ylabel(' 向量维度 2') # Y 轴 Label
plt.show() # 显示图Skip-Gram模型和CBOW模型的区别主要在于训练目标(给定目标词预测上下文和给定上下文预测目标词)、结构(将目标词映射到向量空间然后从嵌入向量空间映射回词汇表以预测上下文分布概率,将上下文词映射到嵌入向量空间然后从嵌入向量空间映射回词汇表以预测目标词的概率分布)和性能(在捕捉西由此和更复杂词语关系方面表现好,在训练速度和捕捉高频词语关系方面表现得更好)
2.5 小结
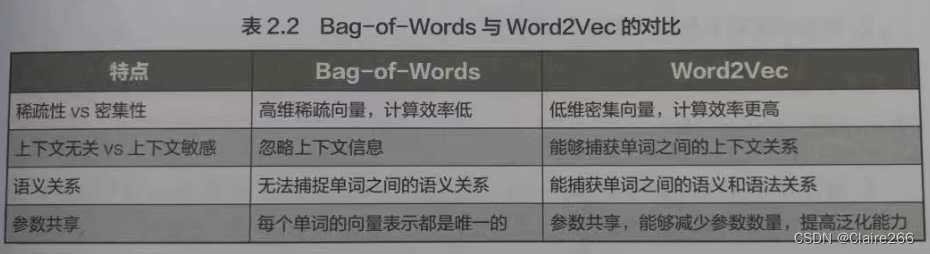
上节课中介绍的 Bag-of-Words(BoW)和本课介绍的Word2Vec(W2V)都可以看作分布式表示的应用实例。这两种方法都试图将离散的符号(如单词)映射到连续的向量空间,让原本没有意义的词汇编码变成蕴含某些语言信息的表示--这也就是分布式表示的内涵。然而,它们在实现方式和表示能力上有很大的不同。
Bag-of-Words是一种简单的分布式表示方法,它将文本表示为单词计数或权重的向量。这种表示方法捕获了文本中单词的频率信息,但忽略了单词的顺序和上下文关系因此,Bag-of-Words 的表达能力较弱,特别是不太善于捕获单词之间的语义关系,
Word2Vec 是一种更先进的分布式表示方法,它通过学习单词在上下文中的共现关系来生成低维、密集的词向量。这种表示方法能够捕获单词之间的语义和语法关系并在向量空间中体现这些关系。与 Bag-of-Words相比,Word2Vec的表达能力更强,计算效率更高。
Word2Vec的局限性
(1)词向量的大小是固定的。Word2Vec这种“在全部语料上一次习得,然后反复使用”的词向量被称为静态词向量。它为每个单词生成一个固定大小的向量,这限制了模型捕捉词义多样性的能力。
(2)无法处理未知词汇。Word2Vec只能为训练过程中出现过的单词生成词向量对于未知或低频词汇,Word2Vec无法生成合适的向量表示。虽然可以通过拼接词相等方法来解决这个问题,但这并非Word2Vec 本身的功能。















 878
878

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









