






序章 看似寻常最奇崛,成如容易却艰辛
1 GPT-4:点亮人工通用智能的火花
GPT-4可以跨越任务和领域的限制,解决数学、编码、视觉等领域中新颖或困难的任务,通过将各种类型的任务统一到对话形式的人机交互接口,极大地提高了使用的便利性。这样无论是谁,都能够通过对话简单地操作它。这种普适性和易用性,正是人工通用智能(AGI)的显著特征。
2 人工智能演进之路:神经网络两落三起
人工智能的发展史:
阈值逻辑单元(Threshold Logic Unit):一种简单的逻辑门,通过设置阈值来确定输出,他被认为是神经网络和人工智能领域的基石。
感知器(Perceptron):是第一个具有自我学习能力的模型,根据输入和目标值的误差调整权重,而且能够进行简单的二分类任务。虽然感知器只是一种简单的线性分类器,但是它具有重要的历史地位,是现代神经网络的雏形和起点。
自适应线性神经元(Adalin):它的学习规则基于最小均方误差,与感知器相似,但有更好的收敛能力。
第一次AI寒冬-XOR问题(XOR problem):单层感知器具有局限性,无法解决非线性问题(XOR问题,异或问题就是一种非线性问题)。
多层反向传播算法(Multilayer Backpropagation):多层反向传播算法是一种训练多层神经网络的方法,这种方法允许梯度通过多层神经网络反向传播,使得训练深度网络成为可能。
卷积神经网络(Convolutional Neural Network,CNN):卷积神经网络是一种特殊的深度学习模型,它使用卷积层来学习局部特征,被广泛应用于图像识别和机器视觉领域。
长短期记忆网络(Long Short-Term Memory,LSTM):长短期记忆网络是1997提出的一种循环神经网络结构。LSTM通过引入入门控机制解决了RNN中梯度消失和梯度爆炸问题,使得模型能够更好地捕捉长距离依赖关系,被广泛运用于自然语言处理和时间序列预测等任务。
第二次AI寒冬-支持向量机(SVM):支持向量机通过最大化类别间的间隔来进行分类。SVM只是多种机器学习算法中的一种,它的特殊的历史意义在于——SVM在许多任务重表现出的优越性能以及良好的可解释性让人们开始在读质疑人工神经网络的潜力。
AlexNet:随着互联网和计算能力的发展,使得深度学习在更大数据集更复杂的模型上训练成为可能,而图像处理器的并行计算能力使得深度学习研究和应用发展加速。2012年提出的深度卷积神经网络标志着深度学习的开始
Transformer:2017年提出的一种神经网络结构,transformer引入了自注意力机制,摒弃了传统循环神经网络和卷积神经网络结构,从而大幅提高了训练速度和处理长序列的能力,成为后续很多先进模型的基础架构。
ChatGPT和GPT系列预训练模型:ChatGPT是基于GPT(Generative Pre-trained Transformer)架构的一种大规模语言模型。
3 现代自然语言处理:从规则到统计
3.1 何为语言?信息又如何传播?
要让计算机可以理解人类的语言,就要对语言进行编码将其转换为计算机能够听懂的形式,这个解码编码的任务可以简化为下图所示的简化的通信模型

3.2 NLP 是人类和计算机沟通的桥梁
NLP的核心任务就是为人类的语言编码并解码,只有让计算机理解人类的语言,他才有可能完成原本只有人才能完成的任务。
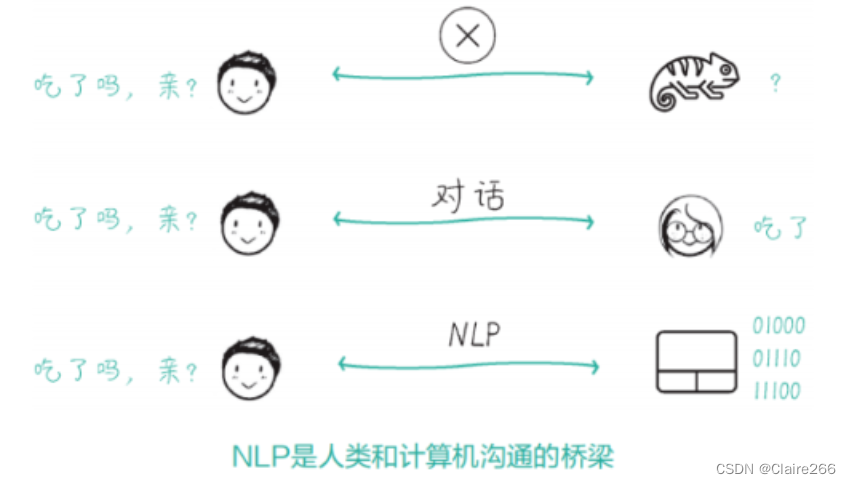 因此我们可以说:NLP是人类和计算机沟通的桥梁。
因此我们可以说:NLP是人类和计算机沟通的桥梁。
3.3 NLP 技术的演进史
本书中将NLP的演进过程粗略分为4个阶段,如图所示使用了4个词来概括他们,分别是起源、基于规则、基于统计、深度学习和大数据驱动。
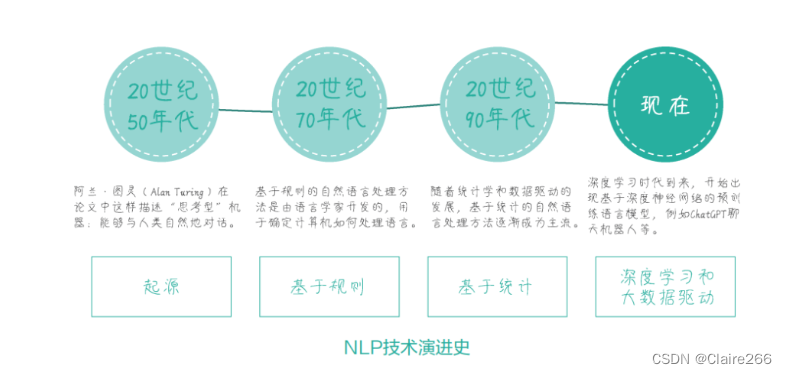
起源:图灵测试的基本思想是,如果一个计算机程序能够在自然语言对话中表现得像一个人,那么我们说它拥有智能。
基于规则:随后数十年,人们尝试通过基于语法和语言规则的方法来解决NLP问题,然而由于规则很多而且十分复杂,这种方法无法涵盖所有语言现象。
基于统计:采用基于统计的方法解决语音识别问题,终于将基于规则的问题转换成了一个数学问题,最终使NLP任务的准确率有了质的提高。因此人们基于统计定义了语言模型(language model,LM):语言模型是一种用于捕捉自然语言中词汇、短语和句子的概率分布的统计模型。简单来说语言模型旨在估计给定文本序列中出现的概率,以帮助理解语言结构和生成新文本。
深度学习和大数据驱动:在确定了以统计方法作为解决NLP问题的主要武器之后,随着计算能力的提升和深度学习技术的发展,大数据驱动的NLP技术已经成为主流。这种技术使用深度神经网络等技术来处理海量的自然语言是数据,从而学习到语言的复杂结构和语义。目前的大型预训练语言模型在很多NLP任务上表现甚至已经超过人类,不仅可以应用于语音识别、文本分类等任务,还可以生成自然语言文本,如对话系统、机器翻译等。
基于规则和基于统计的语言模型是 NLP 技术发展的关键节点,而大规模语言模型的诞生又进一步拓展了 NLP 技术的应用范围。
4 大规模预训练语言模型:BERT与GPT争锋
4.1 语言模型的诞生和进化
语言模型是一种用于计算和预测自然语言序列概率分布的模型,他通过分析大量的语言数据,基于自然语言上下文相关的特性建立数学模型,来推断和预测语言现象。简单来说,语言模型会根据给定的上下文预测接下来出现的单词。常见的语言模型有N-Gram模型,循环神经网络模型、长短期记忆网络模型,以及现在非常流畅的基于Transformer架构的预训练语言模型(PLM),如BERT、GPT系列等。
通过条件概率公式和马尔可夫假设(任意一个词出现的概率只同他前面那个词有关),你就可以得到一个句子是不是人类语言的概率。
基于统计的语言模型具有以下特点:
(1)可扩展性:可以处理大规模的数据集,从而可以扩展到更广泛的语言任务和环境中。
(2)自适应性:可以从实际的语言数据中自适应地学习语言规律和模式并进行实时更新和调整。
(3)对错误容忍度高:可以处理错误或缺失的数据,并从中提取有用的信息。
(4)易于实现和使用:基于统计,并使用简单的数学和统计方法来搭建语言模型。
4.2 统计语言模型的发展历程
基于统计的语言模型早期由于网络结构和数据量的局限,并没有实现突破性的应用。这些语言模型存在不少缺点,例如过拟合、无法处理文本间长距离依赖性、无法捕捉微妙的语义信息等。
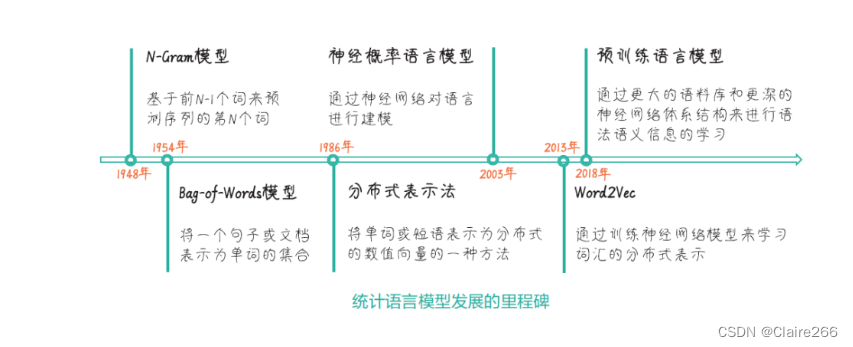
图中每一个节点都为后续技术的诞生打下了基础,其中最为关键的点是从基于规则的模型到基于统计的模型的跃迁,以及海量语料库训练出来的大模型的使用。
4.3 基于Transformer 架构的预训练模型
以BERT为代表的基于Transformer架构的预训练语言模型一登场就引起了大量的关注, BERT通过同时学习文本的上下文信息,实现对句子结构的深入理解。Transformer是几乎所有预训练模型的核心底层架构。自然语言处理中的预训练,通常指在大量无标注文本数据上训练语言模型。预训练所得的大规模语言模型也称为“基础模型”。在预训练过程中,模型学习了词汇、语法、句子结构及上下文信息等丰富的语言知识。这种在大量数据中学习到的知识为后续的下游任务(情感分析、文本分类、命名实体识别等)提供了一个通用的语言表示基础,为解决许多复杂的NLP问题提供了可能。
4.4 “预训练+微调大模型”的模式
经过预训练的大模型所习得的语义信息和所蕴含的语言知识很容易向下游任务迁移。可以根据自己的需要对模型的头部或者部分参数进行适应性的调整,这通常涉及在相对较小的有标注数据集上进行有监督学习,让模型适应特点任务的需求。这就是对预训练模型的微调(Fine-tuning)。微调过程相对于从头训练一个模型来说快得多,需要的数据也少得多,这使得NLP应用人员能够更高效的开发和部署各种NLp解决方案。
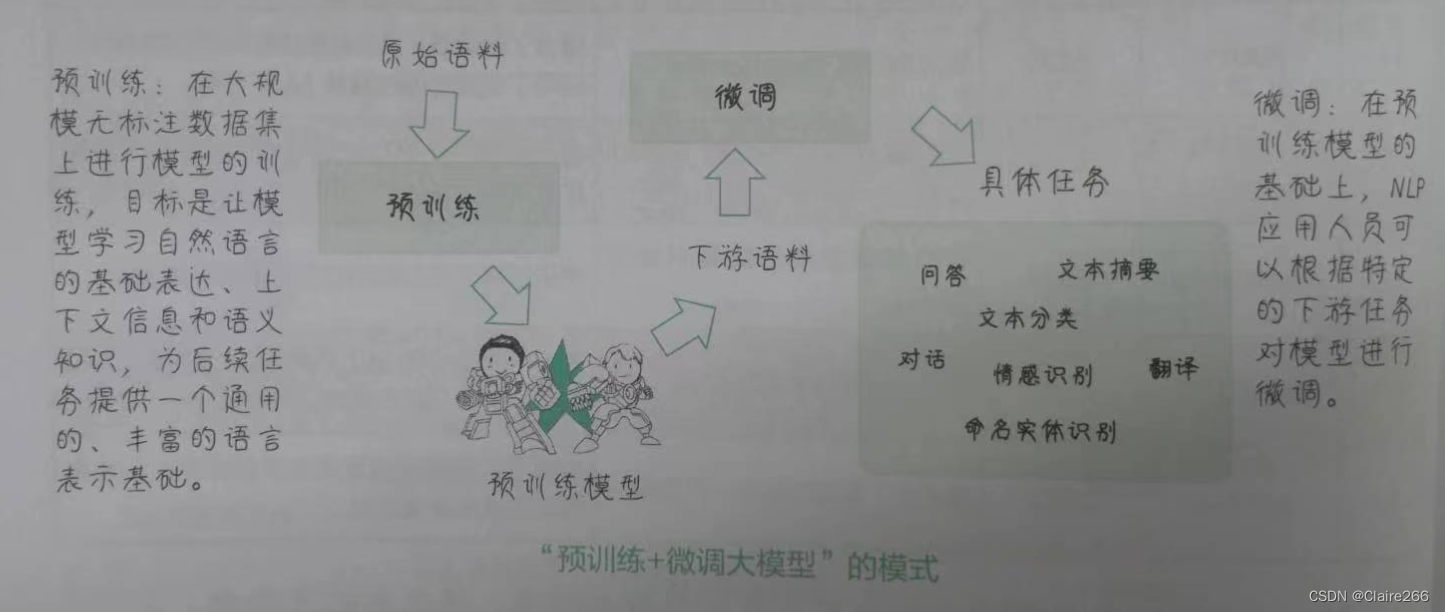
这种“预训练+微调大模型”的模式优点明显:(1)节省了训练时间和数据需求(2)微调过程可以快速根据特定任务进行优化,降低了模型部署的难度(3)具有很强的可扩展性,提高了NLP技术在实际应用中的可用性和普及程度。
4.5 以提示/指令模式直接使用大模型
随着GPT这种生成式大学预训练模型的突飞猛进,“预训练+微调大模型”的使用模式有被一种称为“提示(prompt)”或者说“指令(instruct)”的使用模型所取代的趋势。
prompt模式和instruct模式都基于一个思想:在训练阶段,这些模型通过学习大量的文本数据,掌握了语言的结构、语法和一定程度的语义知识。那么在应用阶段,通过在输入中提供恰当的信息和指导,可以引导大型预训练模型生成相关性很强且更有用的输出。这种方法可以看做与模型的一种对话,用户提供输入,模型根据输入生成相应输出。
(1)prompt模式:输入通常是一次词或者短语,模型需要根据这个提示生成自然且连续的文本,适用于生成任务
(2)instruct模式:输入是一条明确的指令,要求模型完成特定任务,适用于需要明确指示的任务。
prompt模式/instruct模式和“预训练+微调大模型”的相同点在于两种模型都依赖于大学预训练模型,都利用了预训练模型的迁移学习能力,减少了时间需求和数据需求。不同点在于前者是直接利用大模型的生成能力,更具设计合适的提示来解决问题,后者则是通过在特定任务上对模型进行微调,使模型更加精确的适应任务需求。
5 从初代GPT到ChatGPT,再到GPT-4
GPT的核心思想是利用Transformer架构对大量文本进行无监督学习,其目标就是最大化语句序列出现的概率。
5.1 GPT作为生成式模型的天然优势
BERT的预训练过程就像是做填空题。在这个过程中,模型通过大量的文本数来学习,随机地遮住一些单词(或者说“挖空”),然后尝试根据上下文来预测被遮的单词是什么(这是双向的学习)。这样,模型学会了理解句子结构、语法及词汇间的联系。
GPT的预训练过程则类似于做文字接龙游戏。在这个过程中,模型同样通过大量的文本数据来学习,但是它需要预测给定上文的下一个单词(这是单向的学习)。就像是在一个接龙游戏中,你需要根据前面的单词来接龙后面的单词。通过这种方式,GPT学会了生成连贯的文本,并能理解句子结构、语法及词汇之间的关系。
虽然BERT模型通过双向的上下文学习增强了语言模型理解能力,但是语言模型的核心任务是为给定的上下文生成合理的概率分布。在应用中,我们通常需要模型根据给定的上下文生成接下来的文本,而不是填充已有本中的空白部分。而GPT正是通过从左到右逐个预测单词,使得模型在生成过程中能够学习到自然语言中连贯的表达、语法和语义信息。
两者相比较,GPT更接近语言模型的本质,因为他的预训练过程紧凑且有效地再现来自然语言生成的过程。

5.2 ChatGPT背后的推手--OpenAI
5.3 从初代 GPT 到 ChatGPT,再到 GPT-4 的进化史
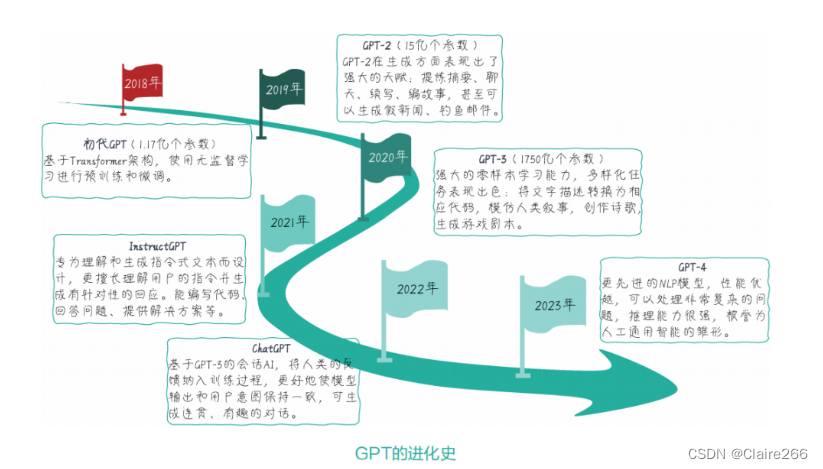
从GPT-3迈向ChatGPT的过程中,技术进展主要集中在基于聊天场景的微调、提示工程、控制性能(控制文本生成的长度、风格、内容),以及安全性和道德责任等方面。在大型预训练模型的发展过程中,随着模型参数数量的增加和训练语料库的扩充,大模型逐渐展现出一系列新的能力,这些能力并不是通过编程引入的,而是在训练过程中自然呈现出来的,我们将这种大模型逐步展现出新能力的现象称为“涌现能力”。

















 1377
1377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









