






搭建Hadoop伪分布式集群
- 创建hd普通用户
- 配置免密钥
- 准备软件包
- 安装JDK,并配置JDK环境变量
- 安装配置Hadoop伪分布式集群
- 启动Hadoop伪分布式集群
- 检查Hadoop集群
实验步骤:
- 回到家目录之下,创建一个用户(使用命令useradd 用户名)

- 对自己新建的用户的密码进行修改(使用命令passwd 用户名)

- 切换用户,切换为自己刚刚创建的用户(使用命令su - 用户名,加上“-”可以使得进入该对应用户的家目录当中)

- 在新创建的用户中创建一个文件夹(使用命令mkdir 文件夹名)

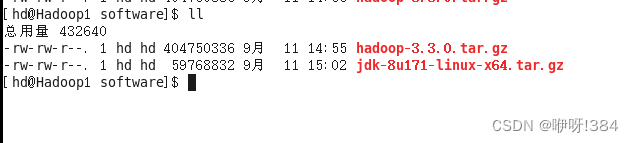
- 切换路径进入到新创建的文件夹当中,之后利用传输工具,将部署Haddop伪分布式的需要的Hadoop、jdk上传到新创建的文件夹当中
- 在进行接下来的步骤之前,先对用户进行设置免密登录(使用命令 ssh-keygen -t rsa ),连续按下回车之后,设置完成

切换目录,进入.ssh/之下,将密钥文件内容拷贝进入公钥中就可以实现免密登录

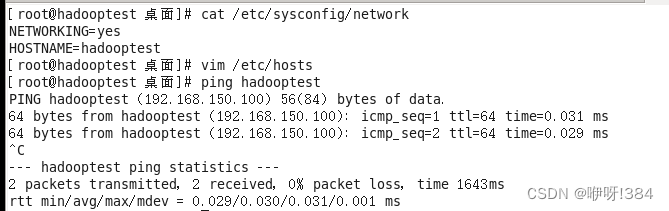
在此之前,你需要已经进行了绑定主机才可实现

- 之后进行jdk的解压(使用命令tar -zxvf 压缩包名),之后查看是否解压成功

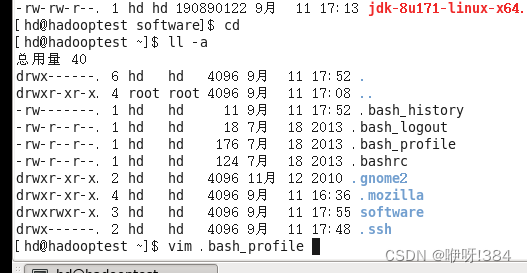
压缩完成之后,进入家目录,对.bash_profile进行配置(vim 文件名)
配置内容:
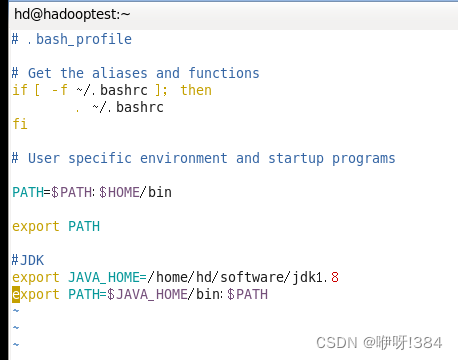
使用source命令之后,使用java -version之后,配置成功

- Jdk配置安装完成之后,进行Hadoop安装配置,找到Hadoop压缩包的位置之后,进行解压(使用tar -zxvf 压缩包名)

切换目录进入到修改配置文件的位置
接着对配置文件(hadoop-env.sh)进行修改(vi 文件名)
![]()
配置内容:
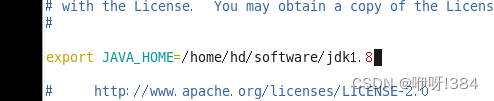
紧接着进行下一个文件的配置()
![]()
在此之前,需要在hadoop解压后的位置创建一个文件夹
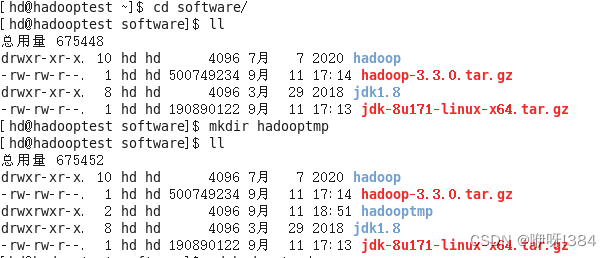
配置内容

接着进行第三个文件的配置
配置文件:

配置内容:

接着进行第四个文件的配置
配置文件:
![]()
配置内容: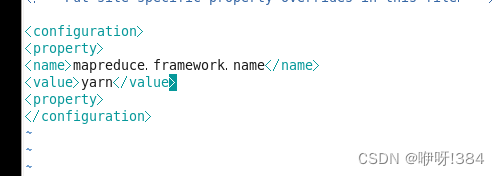
接着进行第五个文件的配置
配置文件:

配置内容:
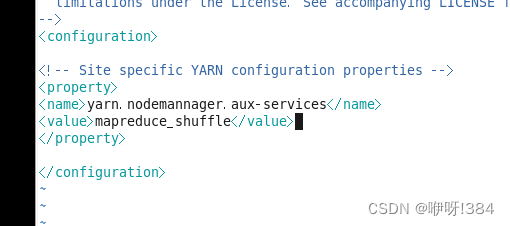
进行第六个文件的配置
配置文件:
![]()
配置内容: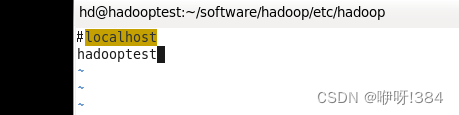
- 进行Hadoop环境变量的配置

![]()
- 接着进行格式化配置
![]()
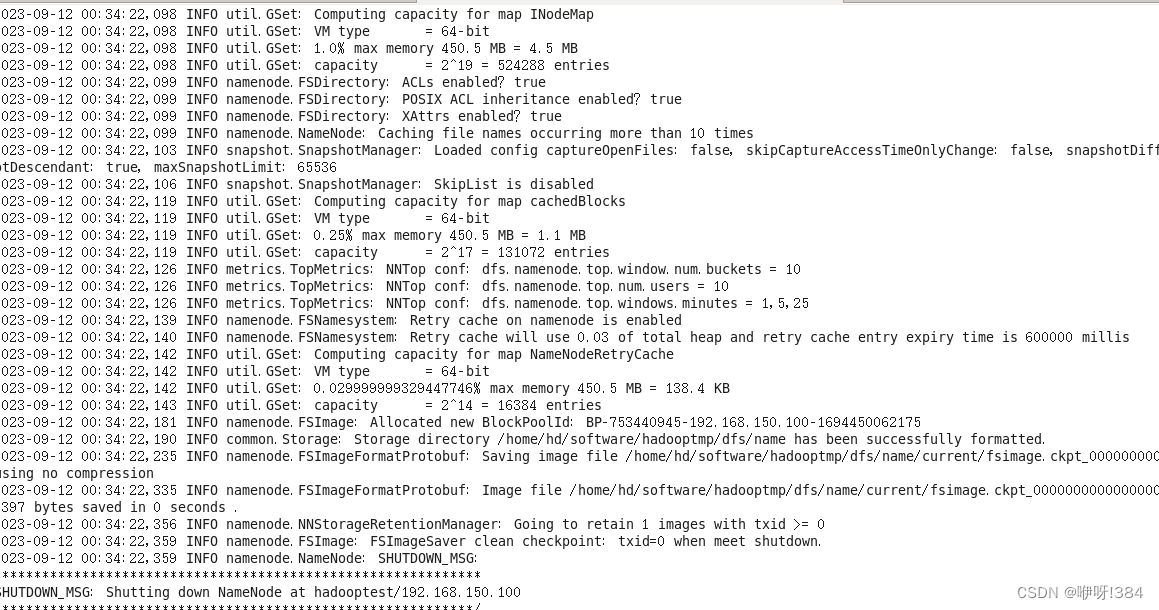
- 重新加载文件之后,启动
![]()
![]()


- 在浏览器当中输入自己的主机号以及对应的端口进行检查是否部署成功
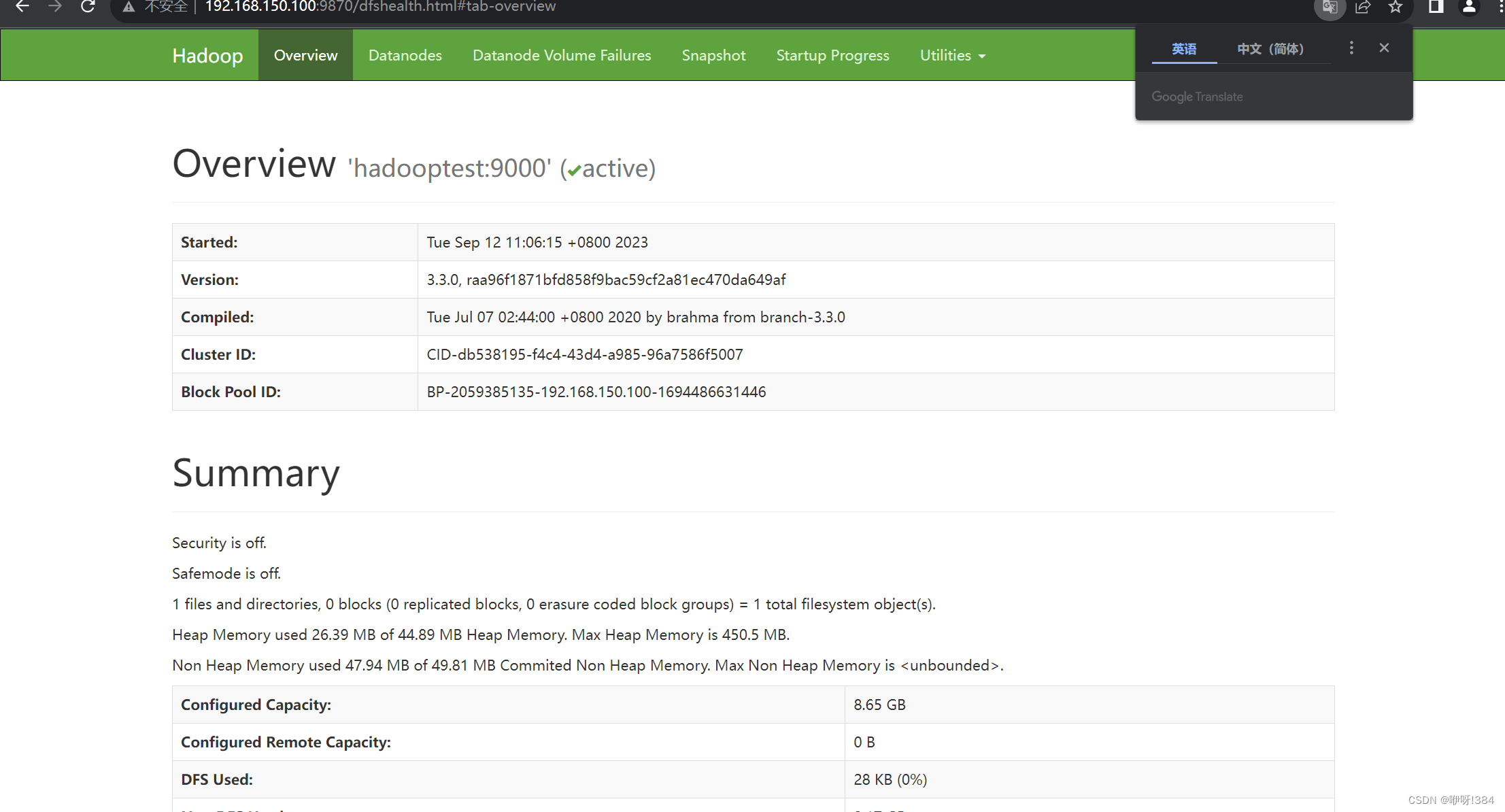
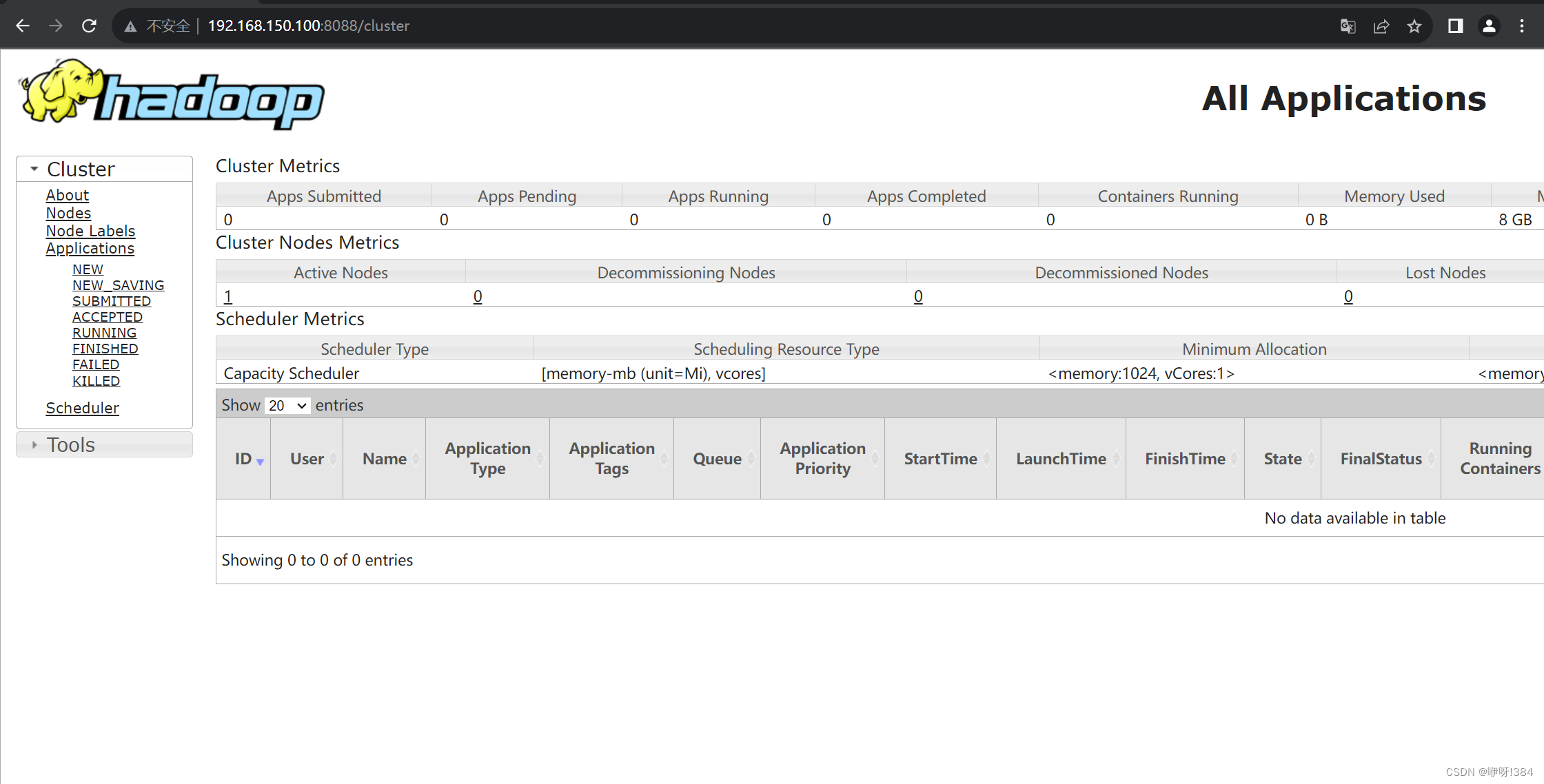















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









