






- 简答题:
项目需求:有一份bigdata.txt文件,请将它上传到大数据平台的HDFS上,然后编写MapReduce算法统计该文件中每一个单词出现的次数。
备注:关键步骤截图,整理成实验报告提交
实验步骤:
- 下载对应的bigdata.txt文件到本机合适的位置;

- 打开VMware中自己构建的Hadoop伪分布式集群,检查创建的虚拟机是否能够正常ping通网络(包括ping主机)ping网关、ping百度)(注:使用命令ping);
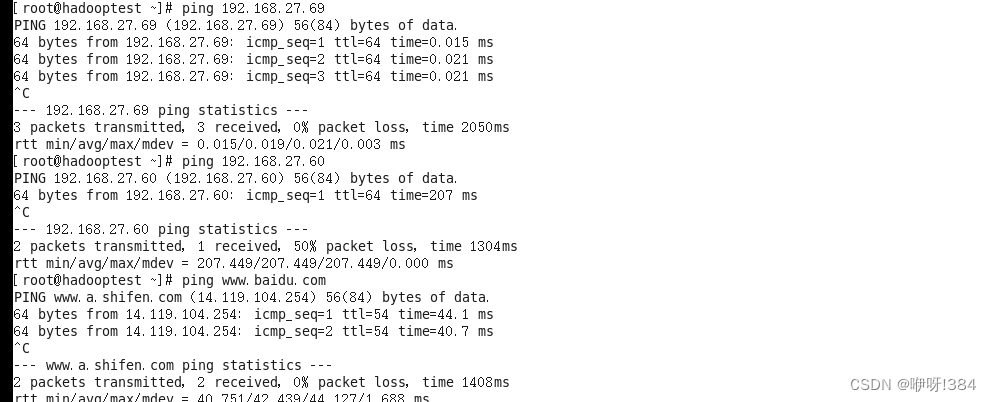
- 启动Hadoop的伪分布式集群(注:使用命令start-all.sh以及jps)


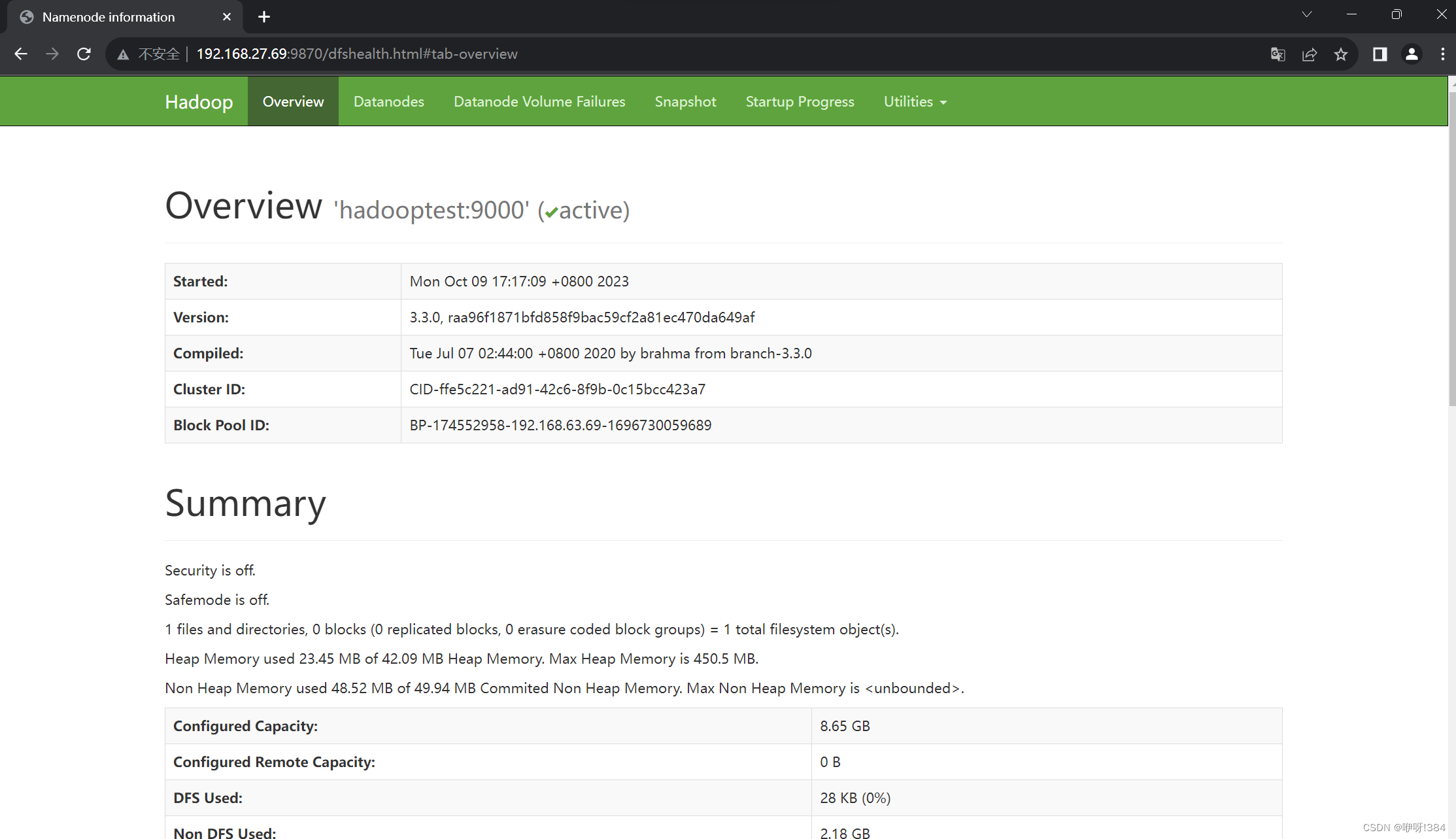
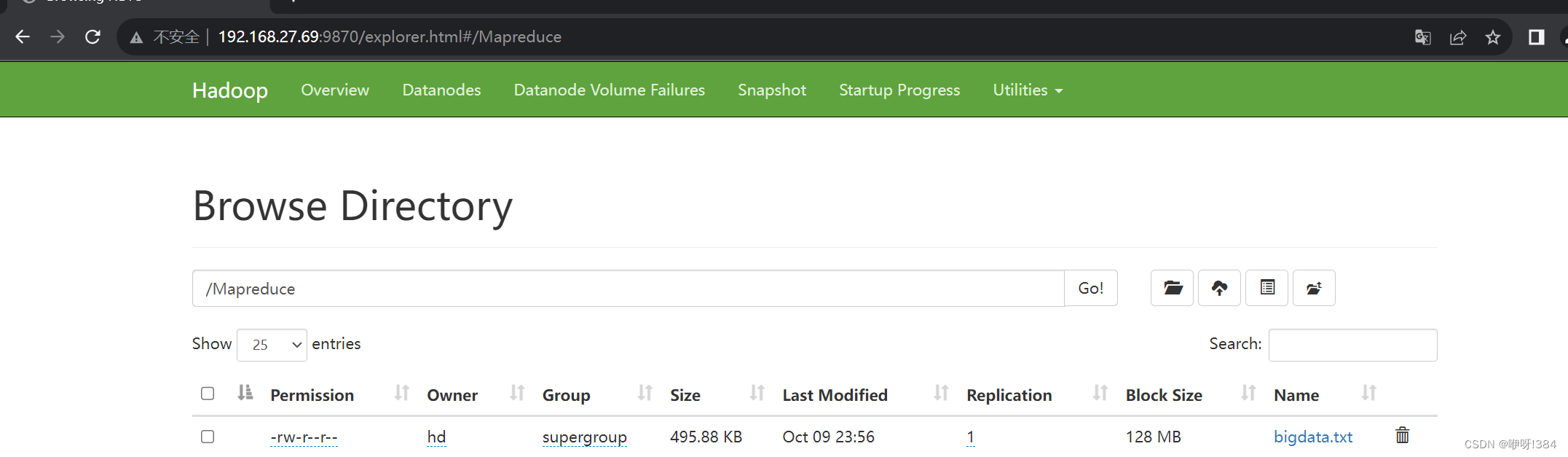
- 到浏览器当中连接9870端口看是否能够正常查看(出现如下图所示的界面则是正常可以查看);
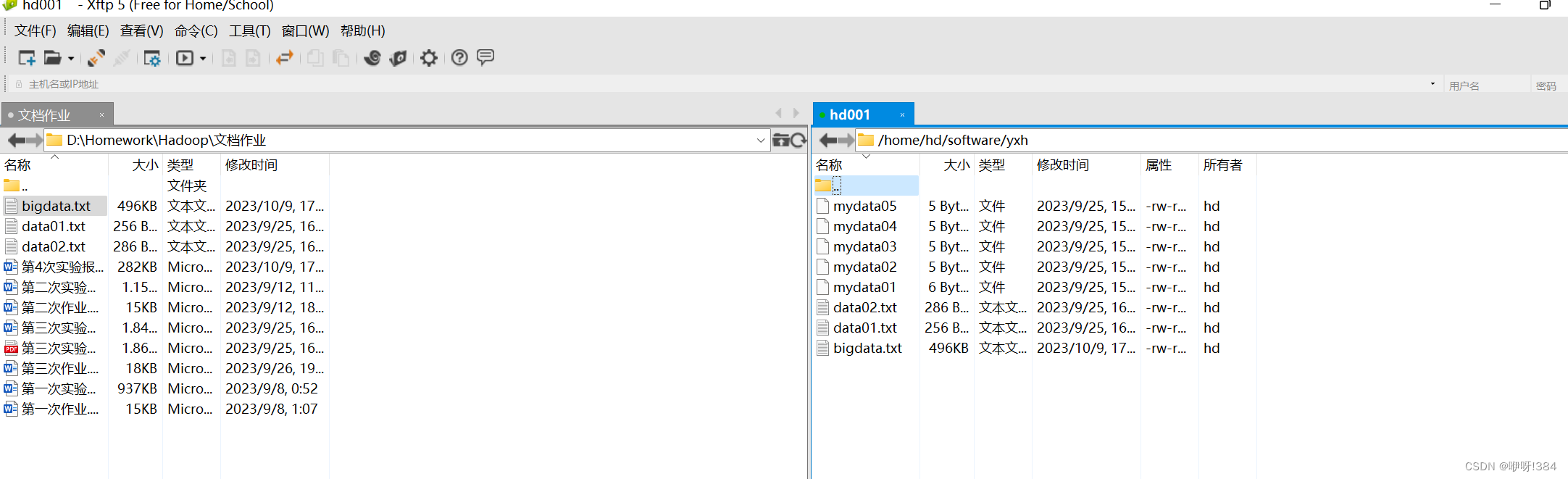
- 使用传输文件的文件连接虚拟机,将所需要的bigdata.txt文件先上传到虚拟机中(本人将bigdata.txt文件上传到虚拟机名为yxh的文件夹中)(注:使用命令cd切换目录到yxh中去之后,是否能够看到bigdata.txt文件);
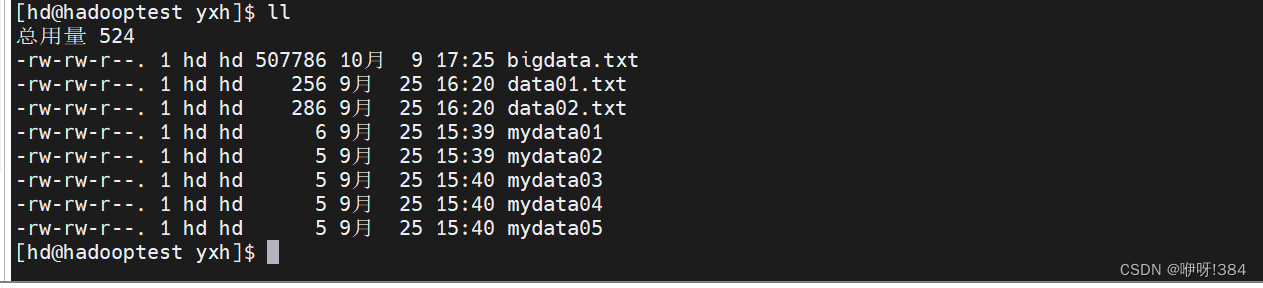
- 接着将对应上传的bigdata.txt文件上传到hdfs的大数据平台上(注:使用命令hdfs dfs -put /Mapreduce/bigdata.txt);

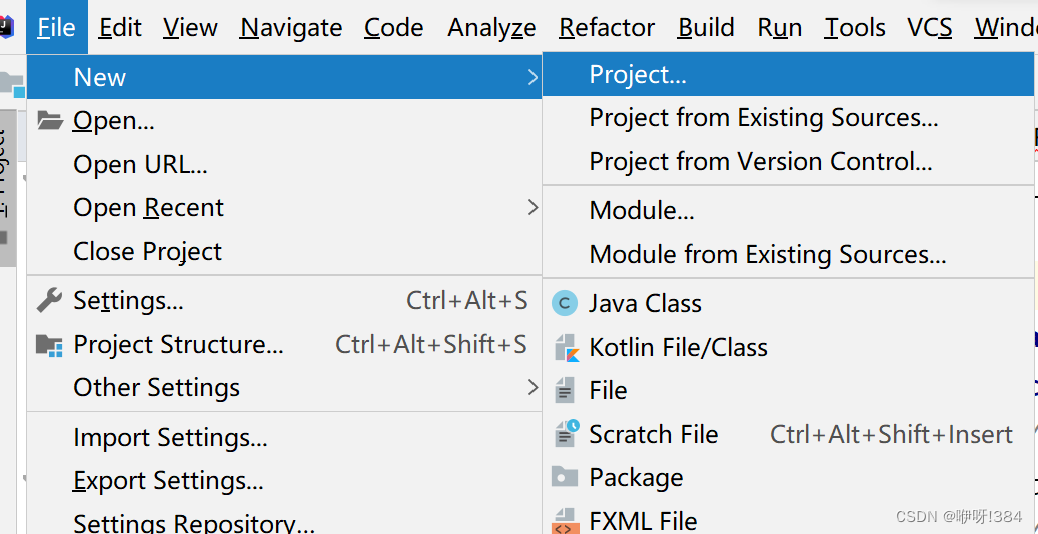
- 在IDEA中新建一个Java项目,在新建的项目中导入对应的jar包;
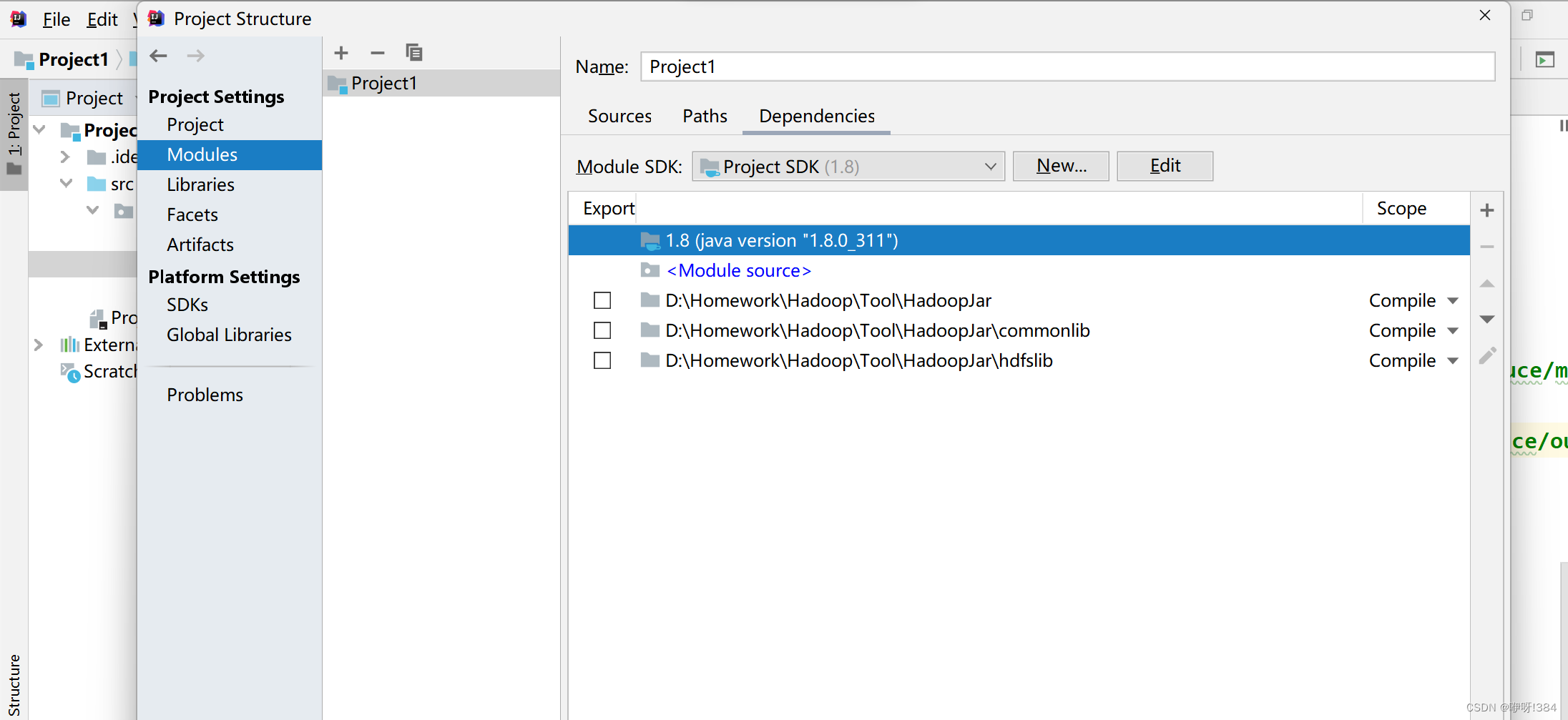
- 选择IDEA中的File——>Project Structure..——>Modules中导入对应的依赖(首先可以将需要的jar包导入进入一个文件夹中便于后续的导入,之后选中要导入的jar包所在的文件夹的位置),之后将对应的依赖导入之后,点击Apply——>OK就可以在对应的位置看到导入的依赖了;

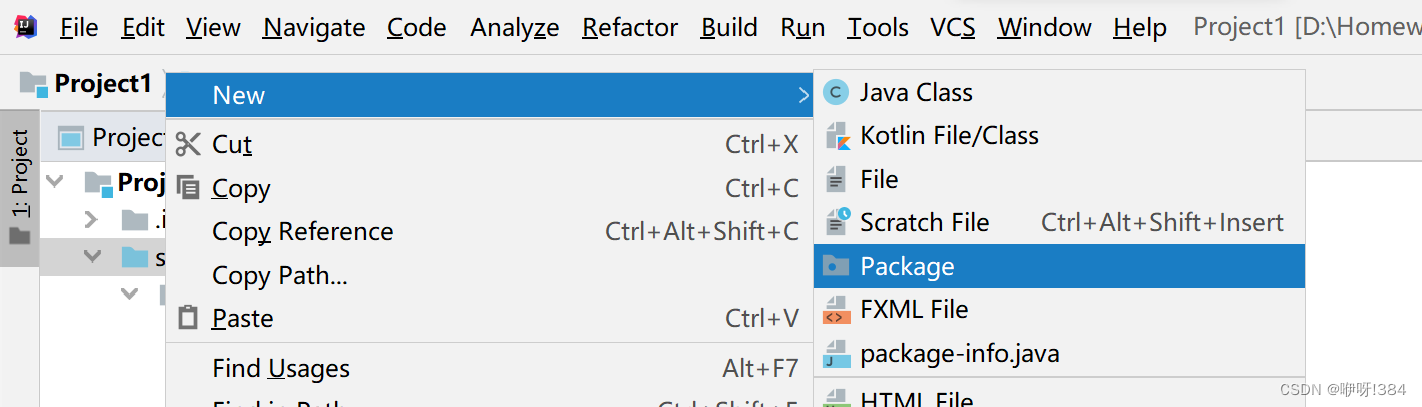
- 导入成功之后,就可以创建一个文件夹(便于管理),然后选择创建对应的java程序;
- 在创建好的java Class中写入Map、Reduce、Main对应的代码;
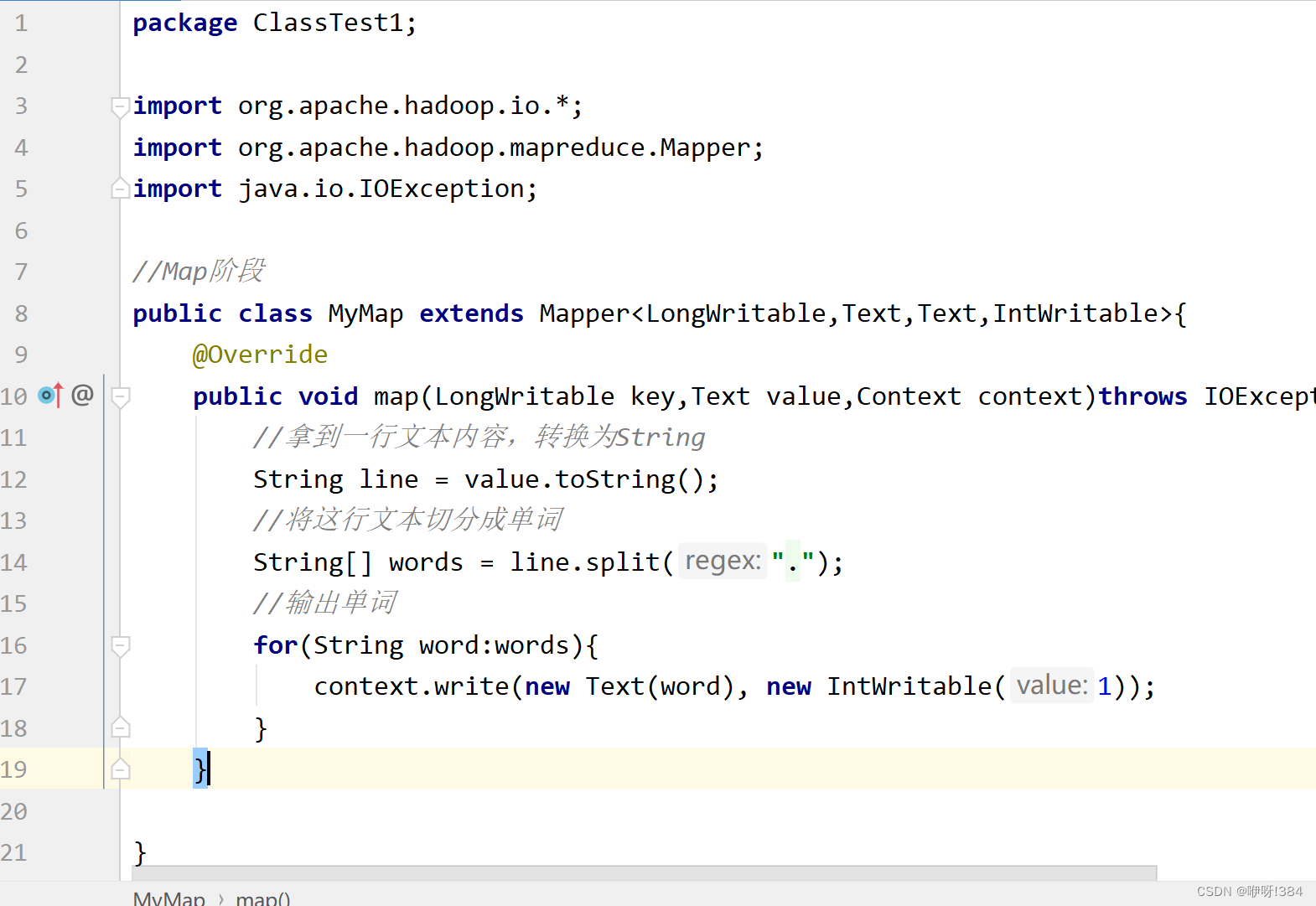
Map:
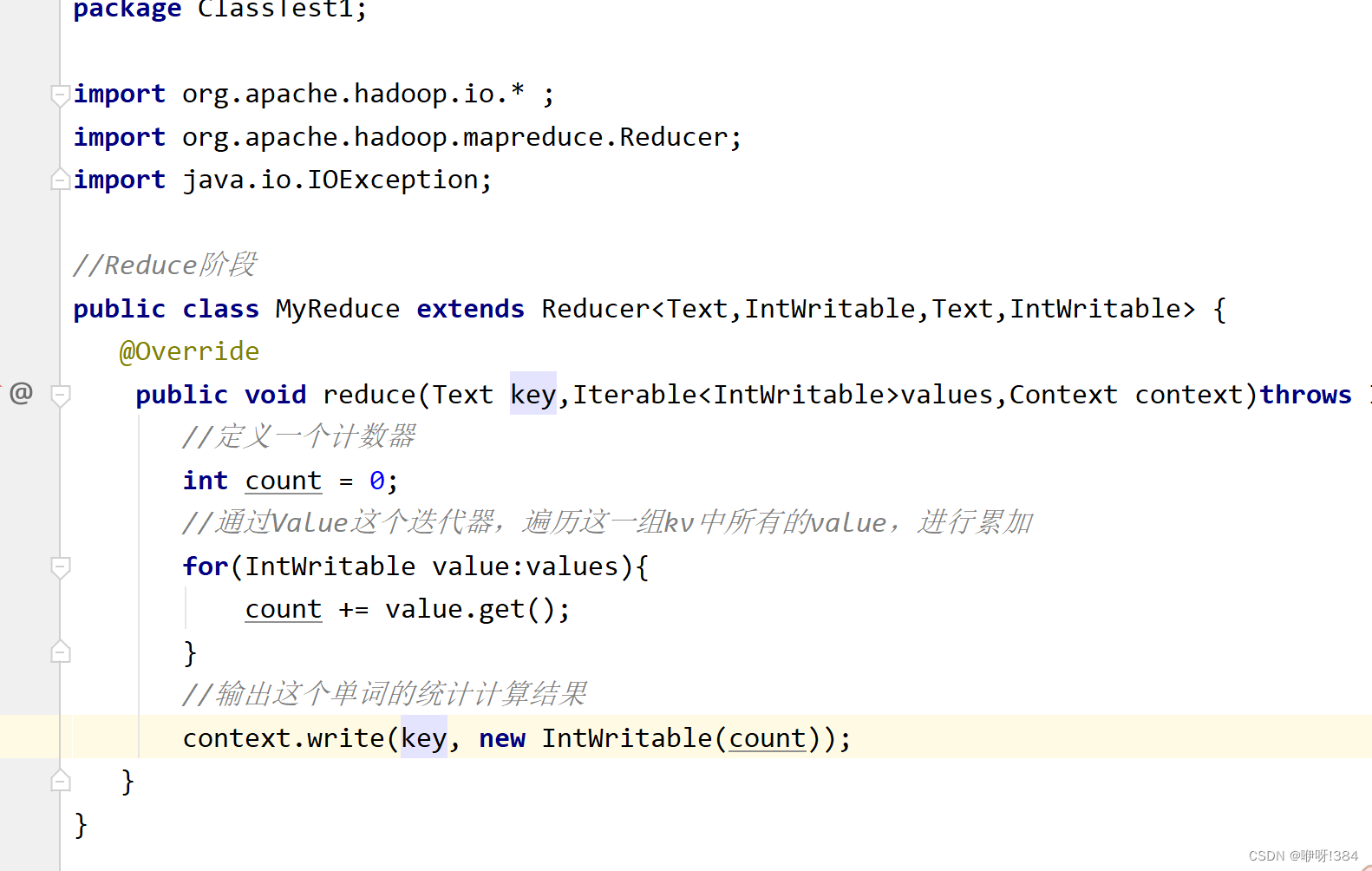
Reduce:
Main:

- 由于需要对统计的文件以及统计的结果进行输出的操作,所以可以在大数据平台上创建一个目录,对这些进行管理(注:使用命令hdfs dfs -mkdir 创建的目录的位置和名称);

- 在IDEA中选中File——>Project Structure——>Artifacts——>jar——>From Modules with dependencies..
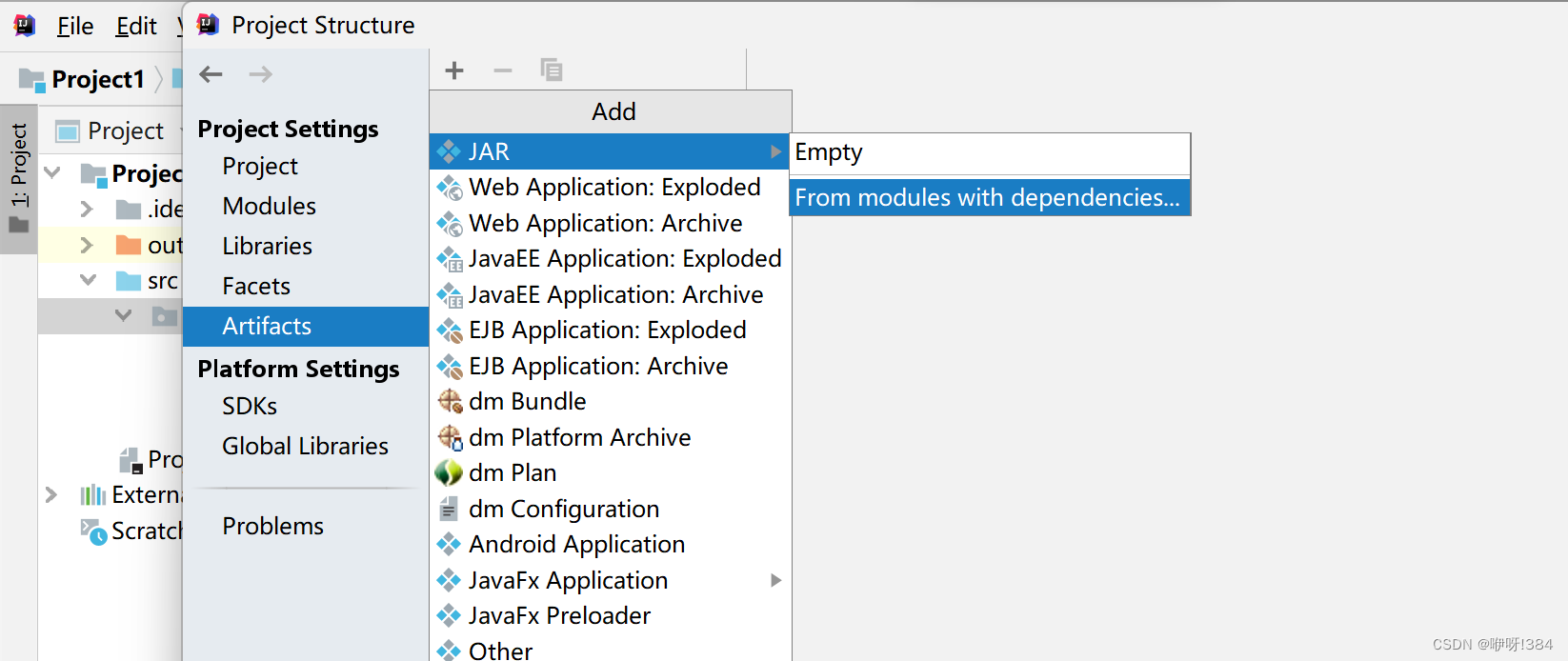
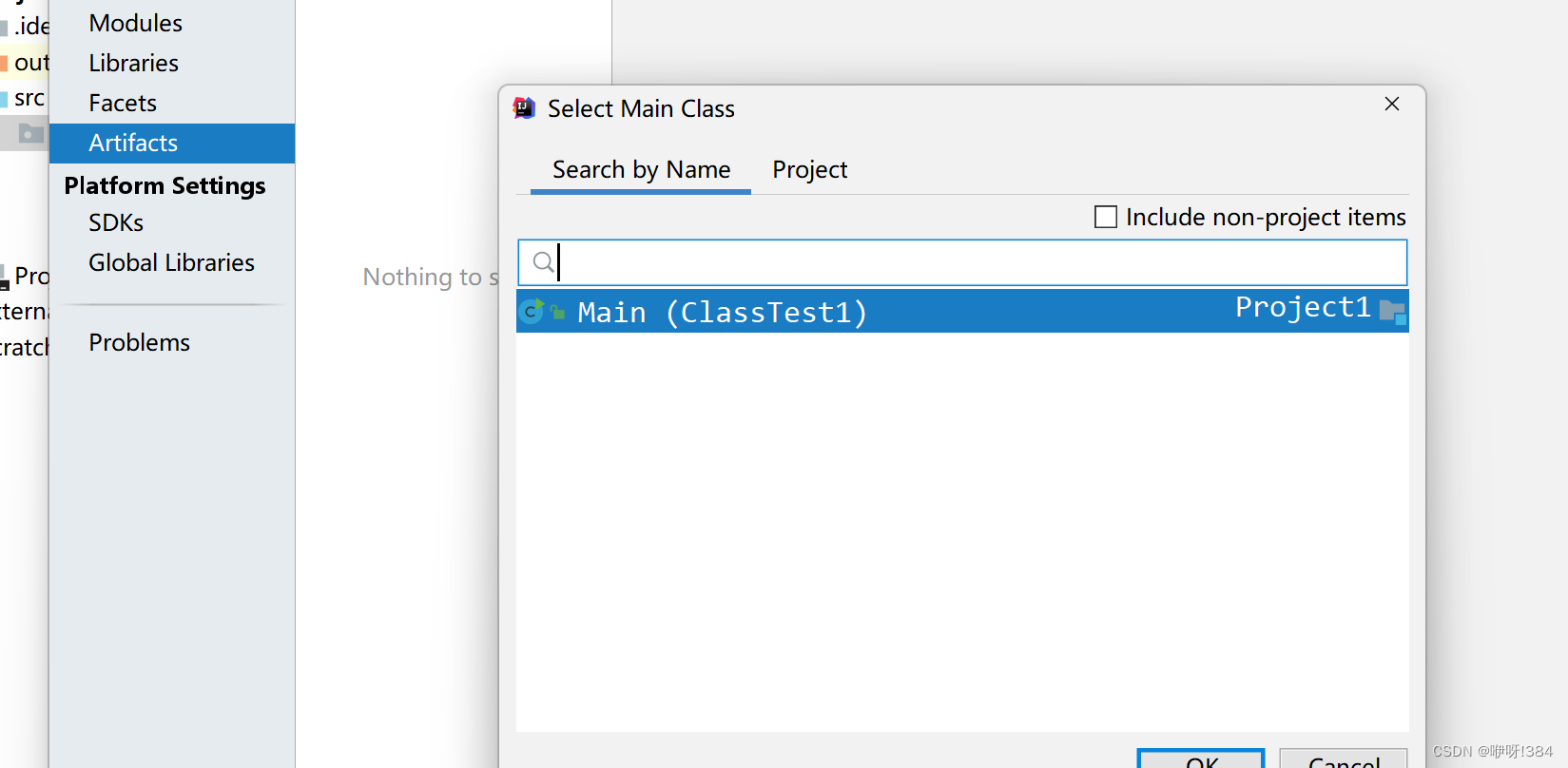
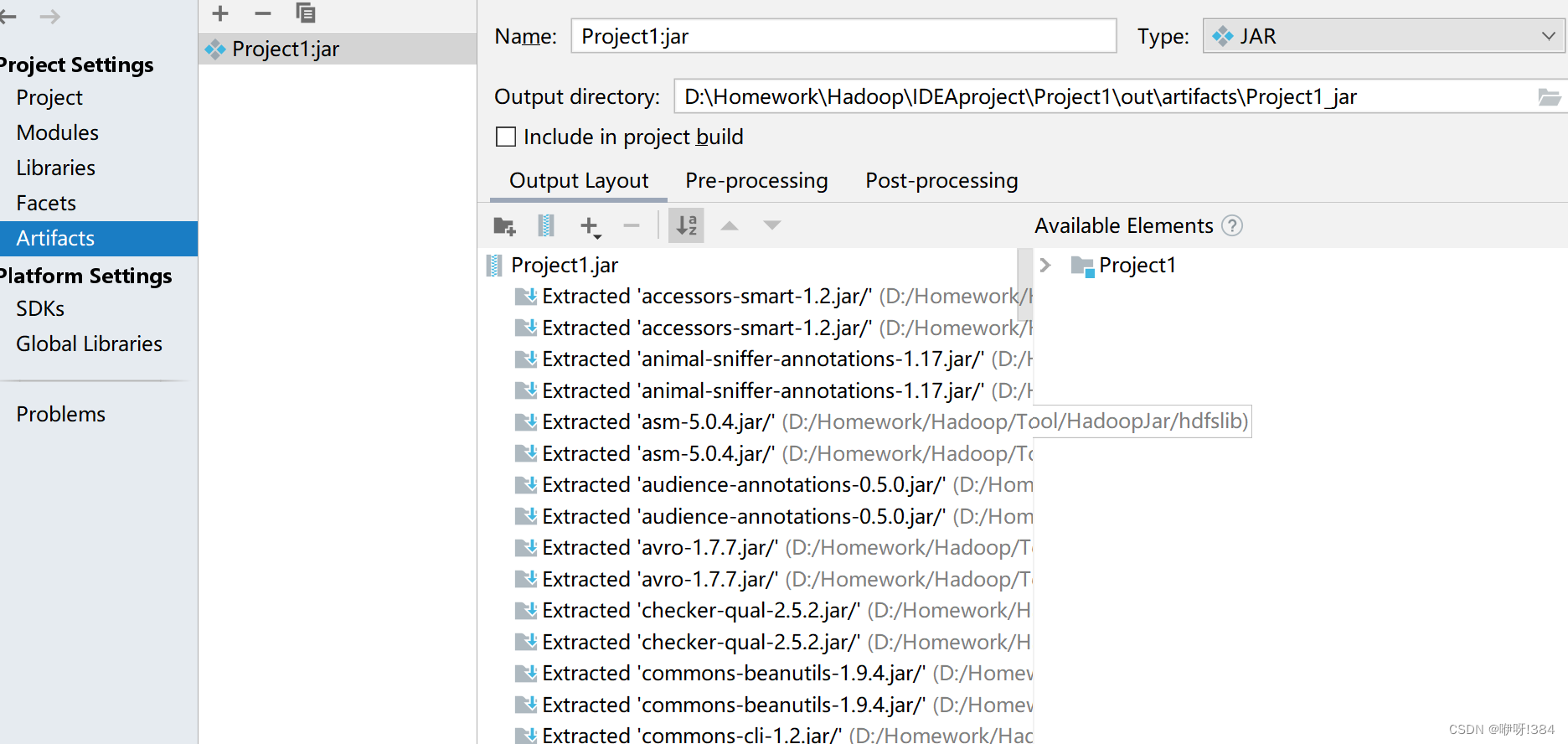
- 选中build进行构建

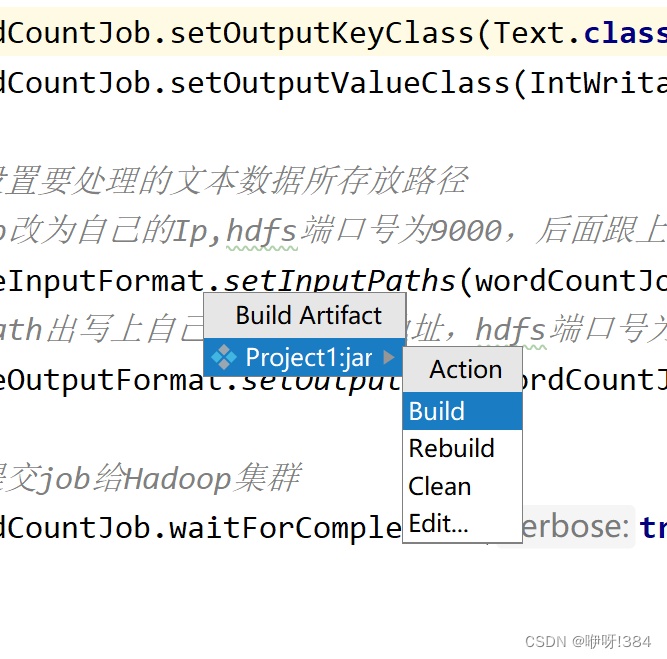
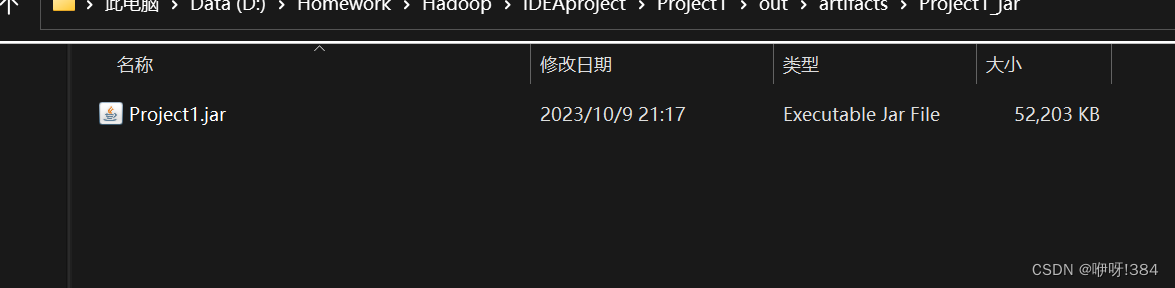
- 将IDEA中打出的jar包使用传输工具上传到Linux中;
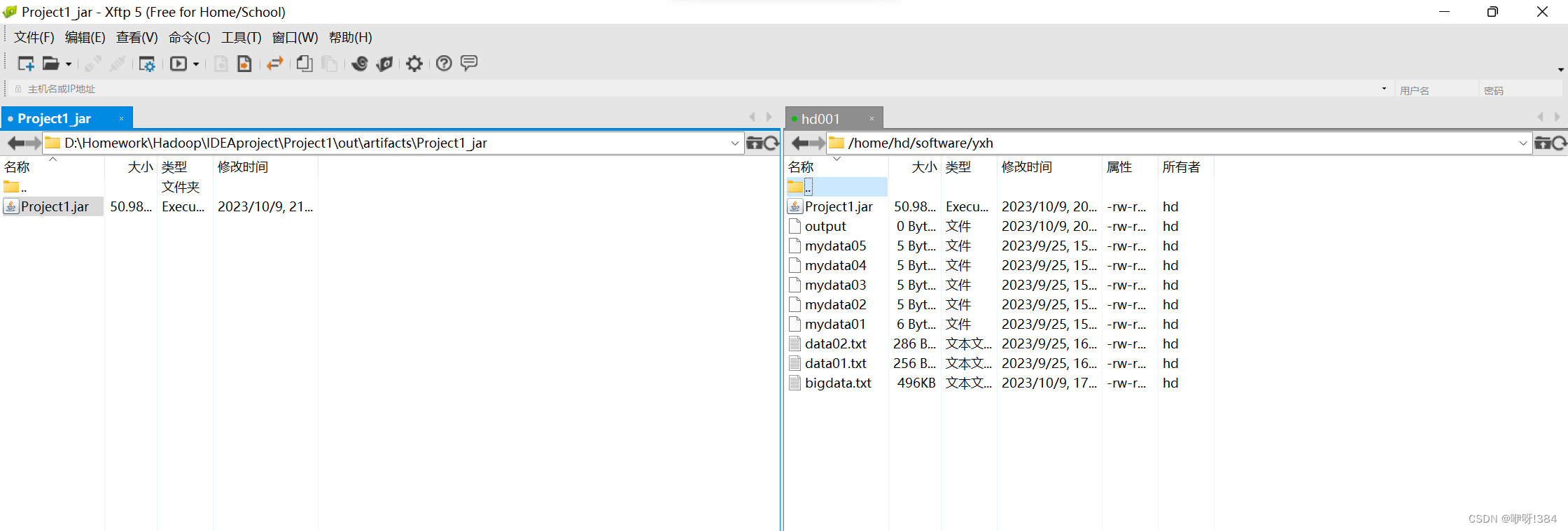
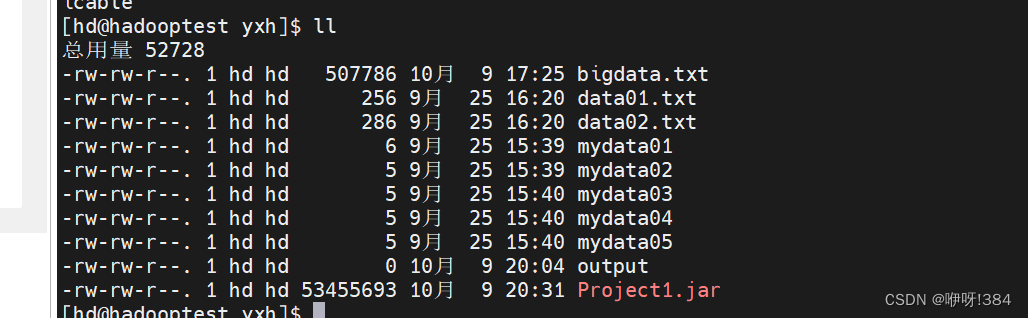
- 接着在linux中运行对应的jar包实现对于数据的统计(注:hadoop jar 上传的jar包所在的路径 主函数的位置);
![]()
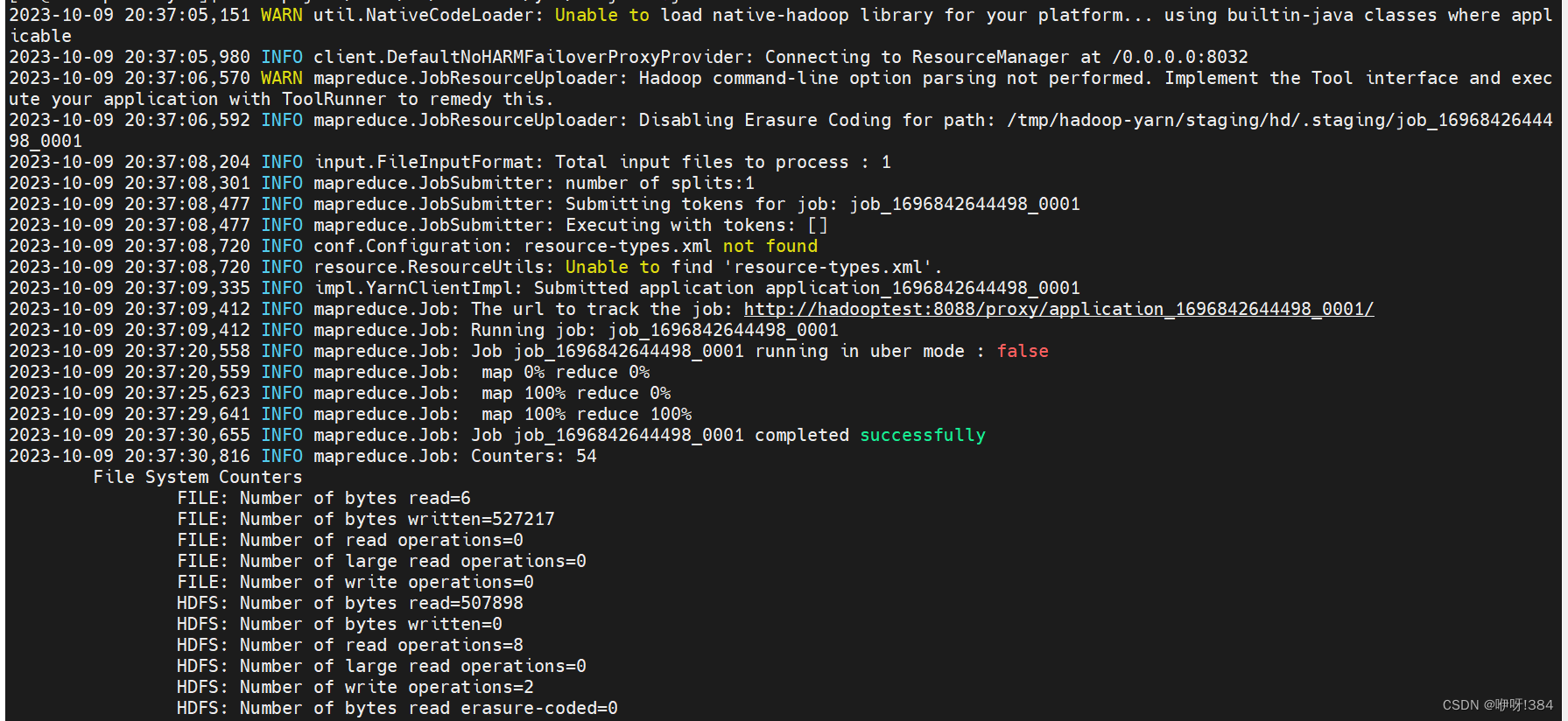
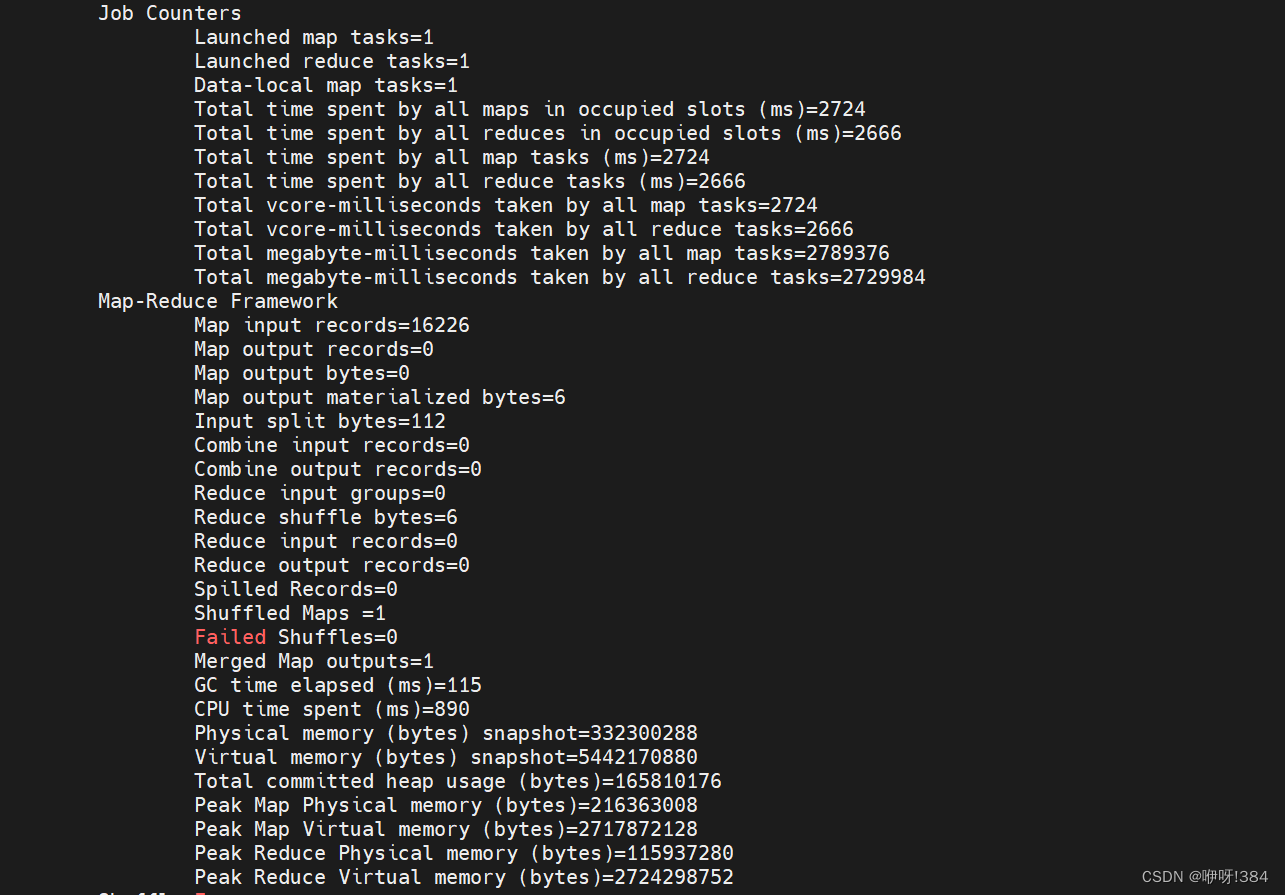
- 查看在大数据平台(注:使用命令hdfs dfs -ls /Mapreduce);
 jie
jie
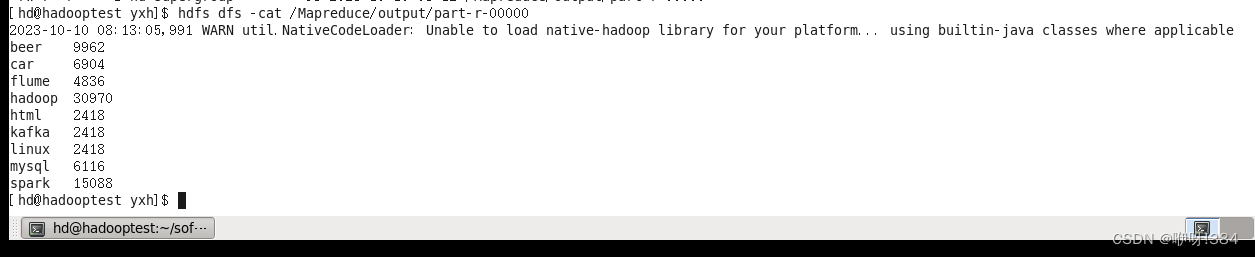
- 查看生成的output文件中的内容(注:使用命令hdfs dfs -ls /Mapreduce/output);

- 接着进入文件查看文件part-r-00000文件中的统计结果的具体内容(注:使用命令hdfs dfs -cat /Mapreduce/output/part-r-00000);
实验心得:
- 在创建IDEA项目中,在编写代码之前必须将对应的jar包导入到对应的项目当中去,否则项目会出现报错的情况;
- 在IDEA中编写好代码之后,是不可以直接在IDEA中去运行羡慕代码的,需要将创建好的项目打包形成一个jar包,再将对应打好的jar包放到虚拟机中合适的位置,在Hadoop集群中进行运行处理;
- 在IDEA中最后显示的输出的文件夹的位置,该文件夹必须是在大数据平台上是没有出现的(即是没有同名的文件夹),否则在运行时会出现运行错误;
- 如果上传到虚拟机中的Jar包IDEA代码生成的文件中不再存在文件内容,那么肯呢个出现的问题是在IDEA中项目的代码内容是出现存在问题的;















 1622
1622











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









