






530. 二叉搜索树的最小绝对差
题目中要求在二叉搜索树上任意两节点的差的绝对值的最小值
注意是二叉搜索树,二叉搜索树可是有序的
遇到在二叉搜索树上求什么最值啊,差值之类的,就把它想成在一个有序数组上求最值,求差值,这样就简单多了
递归
那么二叉搜索树采用中序遍历,其实就是一个有序数组
在一个有序数组上求两个数最小差值,这是不是就是一道送分题了
最直观的想法,就是把二叉搜索树转换成有序数组,然后遍历一遍数组,就统计出来最小差值了
class Solution {
public:
vector<int> vec;
void traversal (TreeNode* node){
if(node == NULL) return;
traversal(node->left);
vec.push_back(node->val);// 将二叉搜索树转换为有序数组
traversal(node->right);
}
int getMinimumDifference(TreeNode* root) { // 统计有序数组的最小差值
int result = INT_MAX;
traversal(root);
for(int i = 1; i < vec.size(); i++){
if(result > vec[i] - vec[i-1]){
result = vec[i] - vec[i-1];
}
}
return result;
}
};
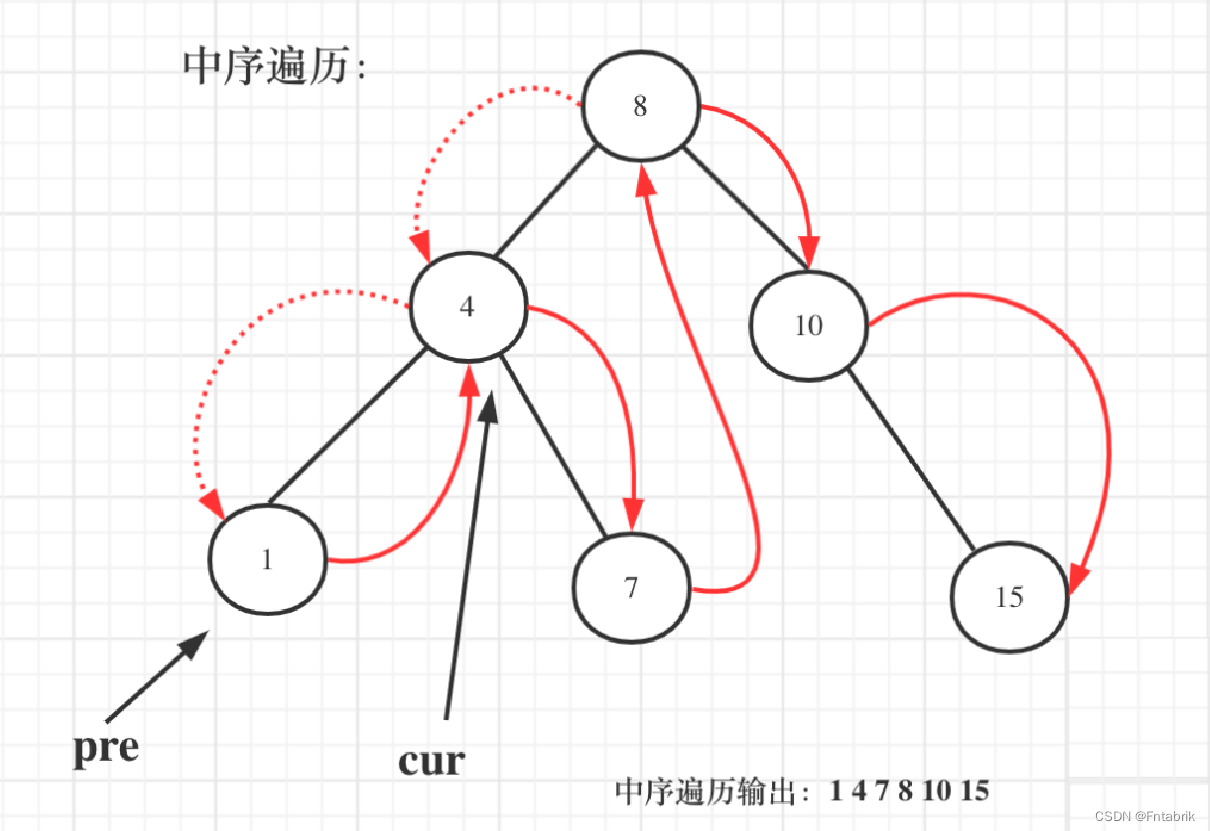
以上代码是把二叉搜索树转化为有序数组了,其实在二叉搜素树中序遍历的过程中,我们就可以直接计算了
需要用一个pre节点记录一下cur节点的前一个节点
如图:
代码如下:
class Solution {
private:
int result = INT_MAX;
TreeNode* pre = NULL;
void traversal(TreeNode* cur) {
if (cur == NULL) return;
traversal(cur->left); // 左
if (pre != NULL){ // 中
result = min(result, cur->val - pre->val);
}
pre = cur; // 记录前一个
traversal(cur->right); // 右
}
public:
int getMinimumDifference(TreeNode* root) {
traversal(root);
return result;
}
};
迭代
中序遍历的迭代法,代码如下:
class Solution {
public:
int getMinimumDifference(TreeNode* root) {
stack<TreeNode*> st;
TreeNode* cur = root;
TreeNode* pre = NULL;
int result = INT_MAX;
while (cur != NULL || !st.empty()) {
if (cur != NULL) { // 指针来访问节点,访问到最底层
st.push(cur); // 将访问的节点放进栈
cur = cur->left; // 左
} else {
cur = st.top();
st.pop();
if (pre != NULL) { // 中
result = min(result, cur->val - pre->val);
}
pre = cur;
cur = cur->right; // 右
}
}
return result;
}
};
501.二叉搜索树中的众数
既然是搜索树,它中序遍历就是有序的
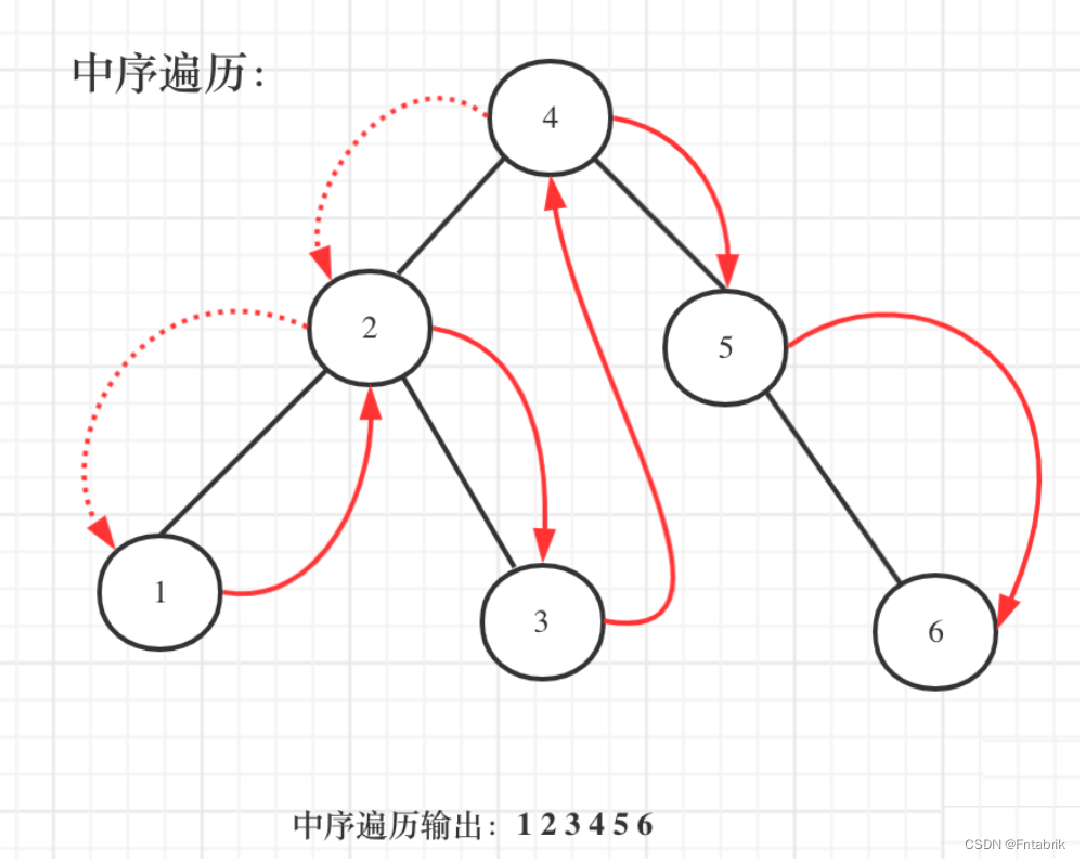
中序遍历代码如下:
void searchBST(TreeNode* cur) {
if (cur == NULL) return ;
searchBST(cur->left); // 左
(处理节点) // 中
searchBST(cur->right); // 右
return ;
}
遍历有序数组的元素出现频率,从头遍历,那么一定是相邻两个元素作比较,然后就把出现频率最高的元素输出就可以了
关键是在有序数组上的话,好搞,在树上怎么搞呢?
这就考察对树的操作了
可以用一个指针pre指向前一个节点,这样每次cur(当前节点)才能和pre(前一个节点)作比较
而且初始化的时候pre = NULL,这样当pre为NULL时候,我们就知道这是比较的第一个元素
if (pre == NULL) { // 第一个节点
count = 1; // 频率为1
} else if (pre->val == cur->val) { // 与前一个节点数值相同
count++;
} else { // 与前一个节点数值不同
count = 1;
}
pre = cur; // 更新上一个节点
此时又有问题了,因为要求最大频率的元素集合(注意是集合,不是一个元素,可以有多个众数),如果是数组上大家一般怎么办?
应该是先遍历一遍数组,找出最大频率(maxCount),然后再重新遍历一遍数组把出现频率为maxCount的元素放进集合。(因为众数有多个)
这种方式遍历了两遍数组
那么我们遍历两遍二叉搜索树,把众数集合算出来也是可以的
但这里其实只需要遍历一次就可以找到所有的众数
那么如何只遍历一遍呢?
如果 频率count 等于 maxCount(最大频率),当然要把这个元素加入到结果集中(以下代码为result数组),代码如下:
if (count == maxCount) { // 如果和最大值相同,放进result中
result.push_back(cur->val);
}
是不是感觉这里有问题,result怎么能轻易就把元素放进去了呢,万一,这个maxCount此时还不是真正最大频率呢
所以下面要做如下操作:
频率count 大于 maxCount的时候,不仅要更新maxCount,而且要清空结果集(以下代码为result数组),因为结果集之前的元素都失效了
if (count > maxCount) { // 如果计数大于最大值
maxCount = count; // 更新最大频率
result.clear(); // 很关键的一步,不要忘记清空result,之前result里的元素都失效了
result.push_back(cur->val);
}
关键代码都讲完了,完整代码如下:(只需要遍历一遍二叉搜索树,就求出了众数的集合)
class Solution {
private:
int maxCount = 0; // 最大频率
int count = 0; // 统计频率
TreeNode* pre = NULL;
vector<int> result;
void searchBST(TreeNode* cur) {
if (cur == NULL) return ;
searchBST(cur->left); // 左
// 中
if (pre == NULL) { // 第一个节点
count = 1;
} else if (pre->val == cur->val) { // 与前一个节点数值相同
count++;
} else { // 与前一个节点数值不同
count = 1;
}
pre = cur; // 更新上一个节点
if (count == maxCount) { // 如果和最大值相同,放进result中
result.push_back(cur->val);
}
if (count > maxCount) { // 如果计数大于最大值频率
maxCount = count; // 更新最大频率
result.clear(); // 很关键的一步,不要忘记清空result,之前result里的元素都失效了
result.push_back(cur->val);
}
searchBST(cur->right); // 右
return ;
}
public:
vector<int> findMode(TreeNode* root) {
count = 0;
maxCount = 0;
pre = NULL; // 记录前一个节点
result.clear();
searchBST(root);
return result;
}
};
236. 二叉树的最近公共祖先
遇到这个题目首先想的是要是能自底向上查找就好了,这样就可以找到公共祖先了
那么二叉树如何可以自底向上查找呢?
回溯啊,二叉树回溯的过程就是从低到上
后序遍历(左右中)就是天然的回溯过程,可以根据左右子树的返回值,来处理中节点的逻辑
接下来就看如何判断一个节点是节点q和节点p的公共祖先呢
首先最容易想到的一种情况:如果找到一个节点,发现左子树出现结点p,右子树出现节点q,或者 左子树出现结点q,右子树出现节点p,那么该节点就是节点p和q的最近公共祖先
判断逻辑是 如果递归遍历遇到q,就将q返回,遇到p 就将p返回,那么如果 左右子树的返回值都不为空,说明此时的中节点,一定是q 和p 的最近祖先
还有一种情况,就是节点本身p(q),它拥有一个子孙节点q§
其实情况一 和 情况二 代码实现过程都是一样的,也可以说,实现情况一的逻辑,顺便包含了情况二
因为遇到 q 或者 p 就返回,这样也包含了 q 或者 p 本身就是 公共祖先的情况
递归三部曲:
- 确定递归函数返回值以及参数
需要递归函数返回值,来告诉我们是否找到节点q或者p,那么返回值为bool类型就可以了
但我们还要返回最近公共节点,可以利用上题目中返回值是TreeNode * ,那么如果遇到p或者q,就把q或者p返回,返回值不为空,就说明找到了q或者p
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q)
- 确定终止条件
遇到空的话,因为树都是空了,所以返回空。
那么我们来说一说,如果 root == q,或者 root == p,说明找到 q p ,则将其返回,这个返回值,后面在中节点的处理过程中会用到,那么中节点的处理逻辑,在到3点
if (root == q || root == p || root == NULL) return root;
- 确定单层递归逻辑
值得注意的是 本题函数有返回值,是因为回溯的过程需要递归函数的返回值做判断,但本题我们依然要遍历树的所有节点
我们在之前的文章中说了 递归函数有返回值就是要遍历某一条边,但有返回值也要看如何处理返回值!
如果递归函数有返回值,如何区分要搜索一条边,还是搜索整个树呢?
搜索一条边的写法:
if (递归函数(root->left)) return ;
if (递归函数(root->right)) return ;
搜索整个树写法:
left = 递归函数(root->left); // 左
right = 递归函数(root->right); // 右
left与right的逻辑处理; // 中
看出区别了没?
在递归函数有返回值的情况下:如果要搜索一条边,递归函数返回值不为空的时候,立刻返回,如果搜索整个树,直接用一个变量left、right接住返回值,这个left、right后序还有逻辑处理的需要,也就是后序遍历中处理中间节点的逻辑(也是回溯)
那么为什么要遍历整棵树呢?直观上来看,好像找到最近公共祖先,直接一路返回就可以了
但事实上还要遍历根节点右子树(即使此时已经找到了目标节点了)
因为在如下代码的后序遍历中,如果想利用left和right做逻辑处理, 不能立刻返回,而是要等left与right逻辑处理完之后才能返回
left = 递归函数(root->left); // 左
right = 递归函数(root->right); // 右
left与right的逻辑处理; // 中
所以此时我们要遍历整棵树。知道这一点,对本题就有一定深度的理解了
那么先用left和right接住左子树和右子树的返回值,代码如下:
TreeNode* left = lowestCommonAncestor(root->left, p, q);
TreeNode* right = lowestCommonAncestor(root->right, p, q);
如果left 和 right都不为空,说明此时root就是最近公共节点。这个比较好理解
如果left为空,right不为空,就返回right,说明目标节点是通过right返回的,反之依然
如果left和right都为空,则返回left或者right都是可以的,也就是返回空
if (left == NULL && right != NULL) return right;
else if (left != NULL && right == NULL) return left;
else { // (left == NULL && right == NULL)
return NULL;
}
整体代码如下:
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if (root == q || root == p || root == NULL) return root;
TreeNode* left = lowestCommonAncestor(root->left, p, q);
TreeNode* right = lowestCommonAncestor(root->right, p, q);
if (left != NULL && right != NULL) return root;
if (left == NULL && right != NULL) return right;
else if (left != NULL && right == NULL) return left;
else { // (left == NULL && right == NULL)
return NULL;
}
}
};















 1123
1123

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









