







gdb是什么
在linux中可以使用vim和nano来编译文件的内容,可以使用gcc和g++来生成可执行程序,那么如果在linux中想要对我们写的代码进行调试的话就得gdb指令,当然gdb这个东西刚买的云服务器上是没有的,所以得先下载这个东西这里的下载指令如下:
yum install -y gdb
下载完gdb就可以进入这篇文章的主题。
如何使用gdb打开文件
在命令行中输入:gdb 文件名就可以对指定的文件进行调试,我们先创建一个文件test.c并且往这个文件里面输入内容:

1 #include<stdio.h>
2 int main()
3 {
4 int a =20;
5 int b=10;
6 printf("a+b的值为:%d\n",a+b);
7 printf("a*b的值为:%d\n",a*b);
8 printf("a-b的值为:%d\n",a-b);
9 printf("a/b的值为:%d\n",a/b);
10 return 0;
11 }
然后创建一个makefile文件,在文件里面填入基本操作:
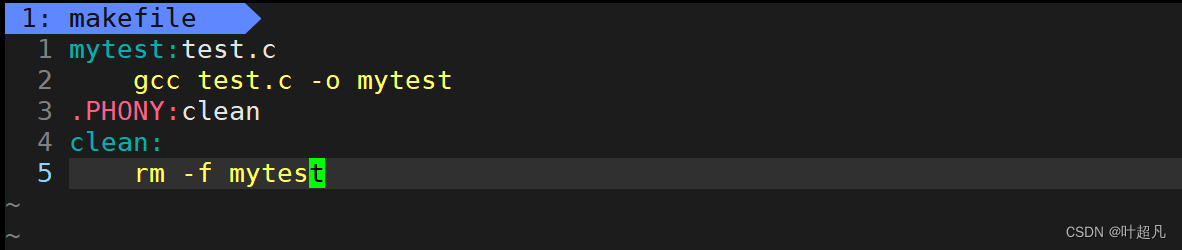
然后在命令行中输入make就可以看到当前路径下出现了一个可执行程序:

运行一下这个可执行程序就可以看到这个程序运行起来是没有问题的:

那如果这里想要调试一下这个可执行程序的话就可以在命令行中输入这段指令:gdb mytest 但是按下回车却出现了这样的现象:
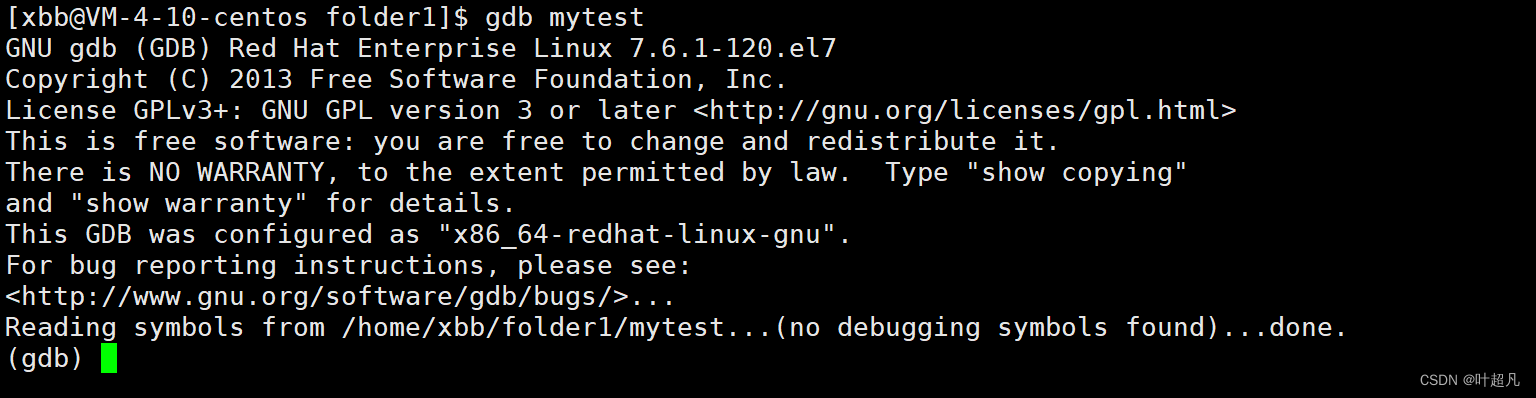
出现这样的原因就是因为代码生成的可执行程序有两个不同的版本一个是面向广大用户的release版本,一个是面向程序员方便调试的debug版本,而gcc默认生成的可执行程序是release版本所以这里使用gdb对其进行调试,如果想要生成dubug版本的可执行程序的话就得在gcc指令中加入 -g选项,当然执行下面操作之前我们得输入q来退出当前的gdb然后对makefile的内容进行修改
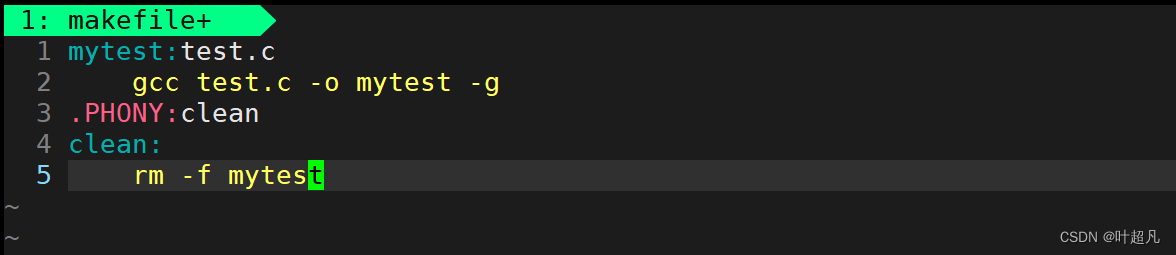
然后在命令行中使用make clean删除之前生成的release版本的可执行程序,然后输入make再生成一个debug版本的可执行程序:

再输入指令gdb mytest就可以看到出现了下面的内容:
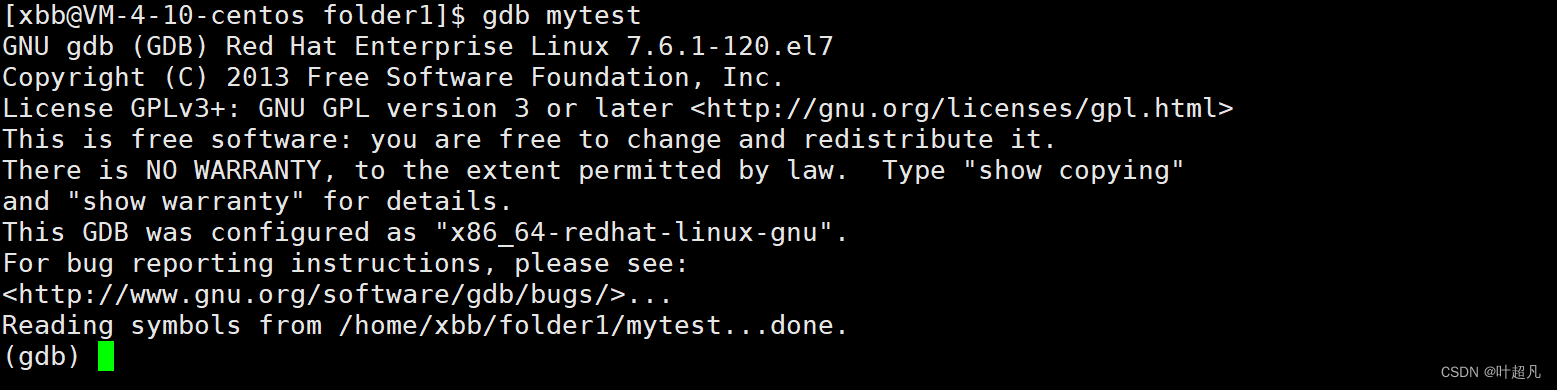
与之前的现象完全不同那么这就说明当前的文件是可以进行调试的,并且我们输入一些指令可以出现对应的内容,比如说输入一个l就可以看到出现了文件中对应的代码:
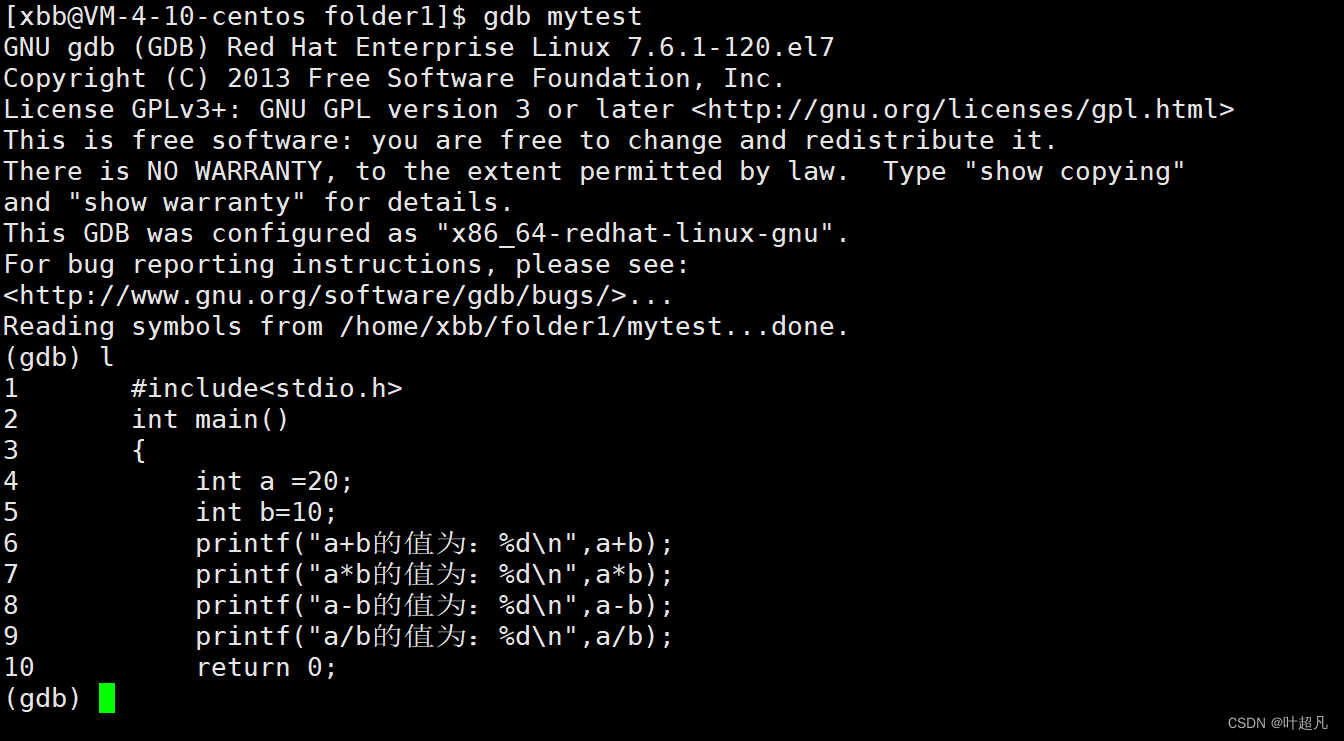
但是之前release版本的文件在使用dgb时确实这样的现象:
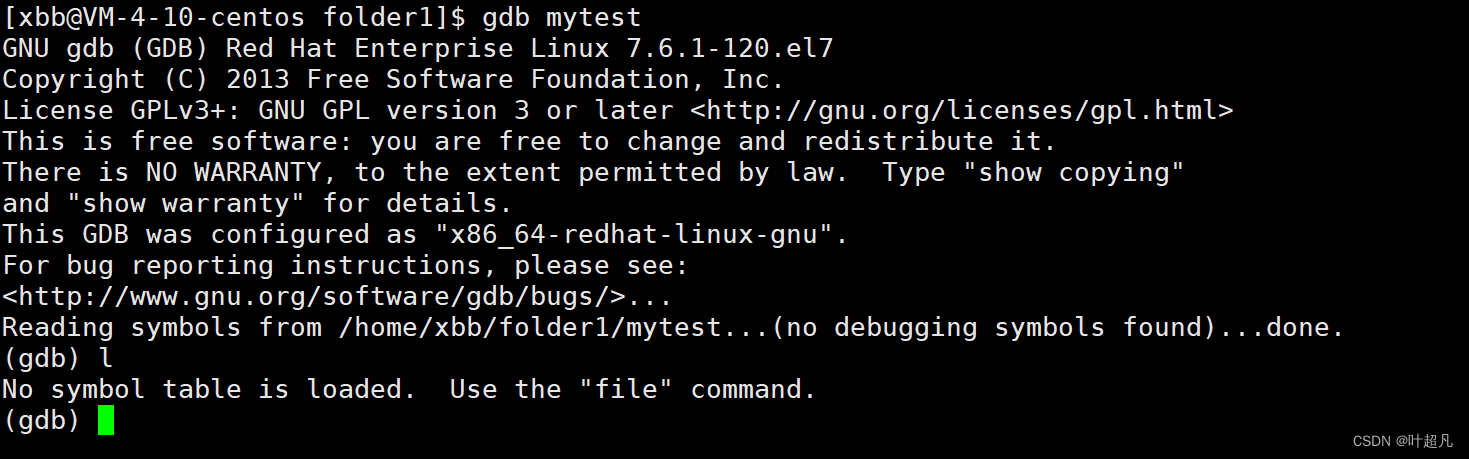
那么这就是不同版本的文件使用gdb所产生的不同现象希望大家可以理解。
如何查看release和debug的不同
在之前的学习中我们知道release版本的文件相较于debug会做出一些优化使得文件的大小更小,文件的运行速度更快,所以这里可以在makefile文件中做出一些修改让其增加一个指令使其能够产生两个不同版本的文件,那么这里修改的结果就如下:
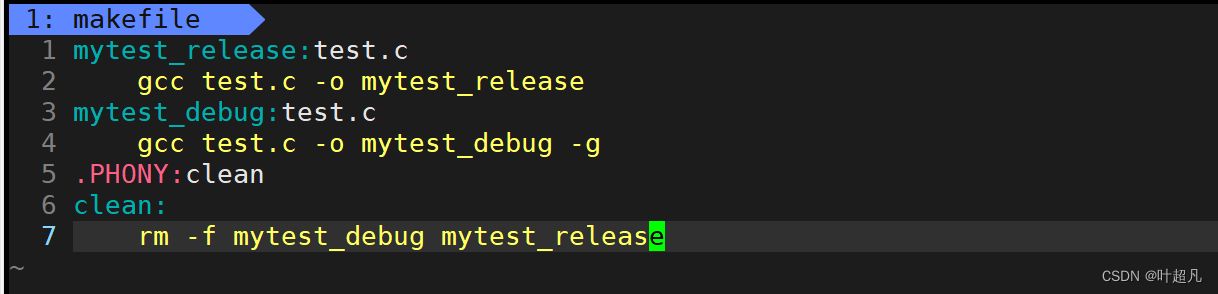
退出makefile将之前生成的可执行程序删除再输入对应指令生成对应的可执行程序使用再输入ll指令就可以看到下面的现象:
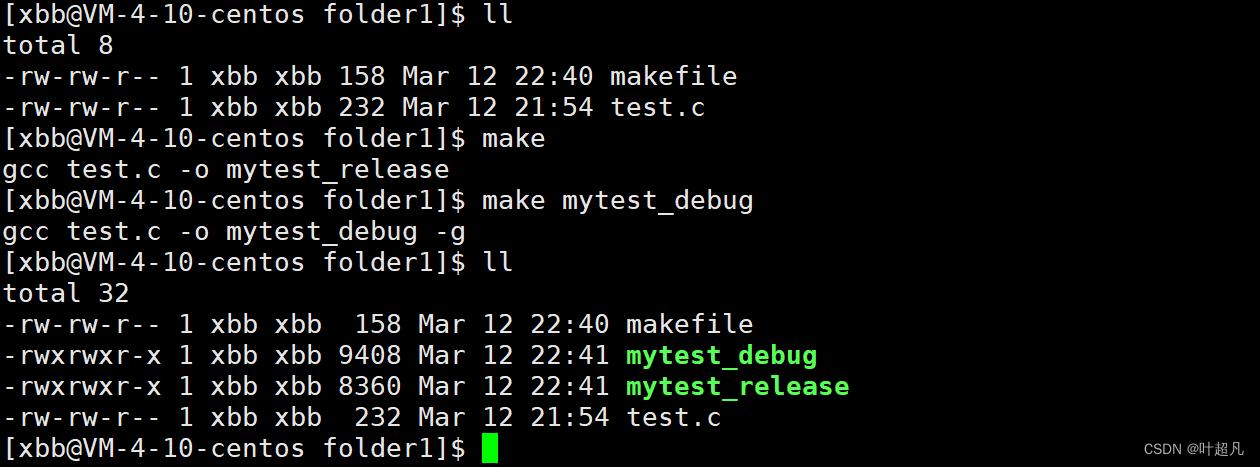
两个同一个文件生成的两个不同版本的可执行程序的大小不相同,并且debug版本的文件大小要比release版本的大小要大,那么出现这种情况的原因就是该版本的文件中含有一些调试所必要的信息,我们可以通过下面的指令来证明这一点readelf -S 可执行程序名这个指令可以显示一个文件的内容信息以及这个文件的二进制构成,比如说哪一部分是数据区,bss区,代码区,链接区等等等反正就是各种区,然后我们使用这个指令来查看不同版本的可执行程序的二进制构成时就可以看到下面的现象,debug版本的文件相较于release版本多了一个debug区比如说下面的两个图片:这是debug版本的二进制构成:
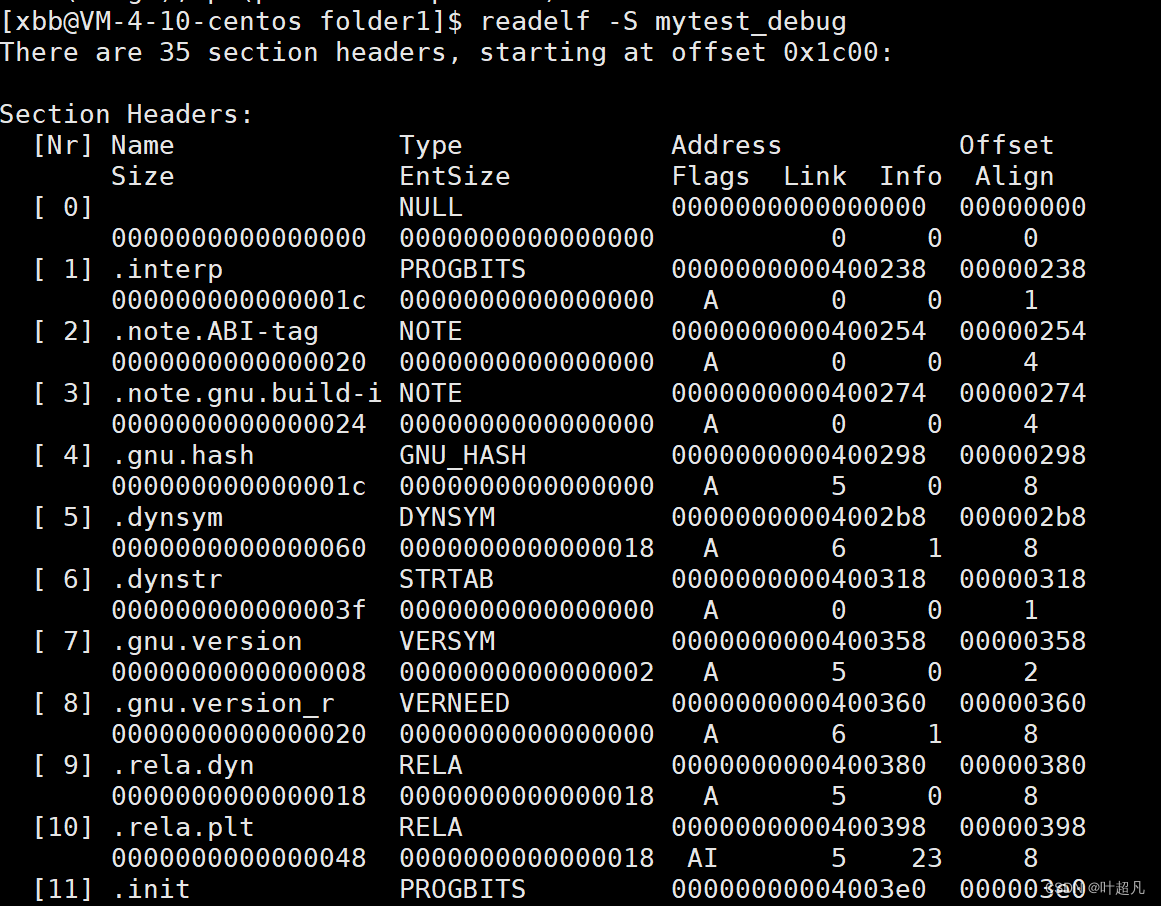
当然这里显示的东西太多了不方便展示,我就使用管道加grep的方式来给大家展示一下这里的关键信息:

但是同样的指令将文件改成release版本的话就可以发现这里找不出来任何与debug相关的信息:

那么这就是release版本和debug版本的不同希望大家可以理解。
正式调试
l
首先对文件的内容进行修改添加一些内容这样就可以方便我们往后的展示,修改的代码如下:
10 }
11 void mul_function(int a,int b)
12 {
13
14 printf("a*b的结果为:%d",a*b);
15 }
16 void div_function(int a,int b)
17 {
18
19 printf("a/b的结果为:%d",a/b);
20 }
21 int main()
22 {
23 int a =20;
24 int b= 10;
25 add_function(a,b);
26 sub_function(a,b);
27 mul_function(a,b);
28 div_function(a,b);
29 printf("hello world");
30 printf("hello world");
31 printf("hello world");
32 printf("hello world");
33 return 0;
34 }
修改完之后使用make mytest_debug指令对文件进行更新,然后对这个debug版本的可执行程序使用gdb指令进行调试:gdb mytest_debug就可以看到出现这样的现象:
这里没有显示任何内容,所以这里要想查看文件中的代码的话就可以输入l:
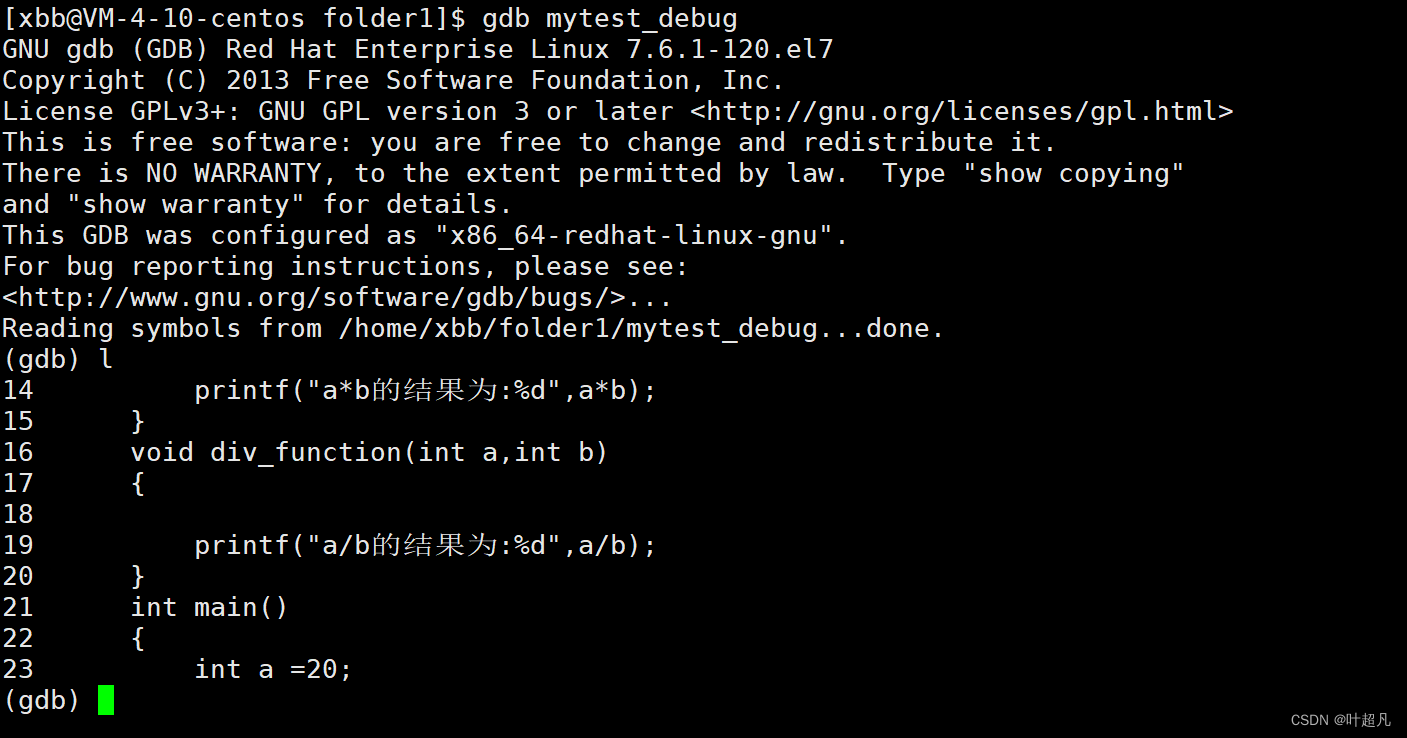
但是这里只随机显示了文件中的部分代码如果想要从头开始显示的话就得在指令l后面加一个0(数字0)选项,这样他就会第一行开始显示你的代码:

但是这里有个问题就是他虽然是从0开始显示的后面的代码,但是他只显示了部分代码所以要想查看后面的代码的话就得继续输入l,这时他会紧接着上面的显示的内容继续往下显示:
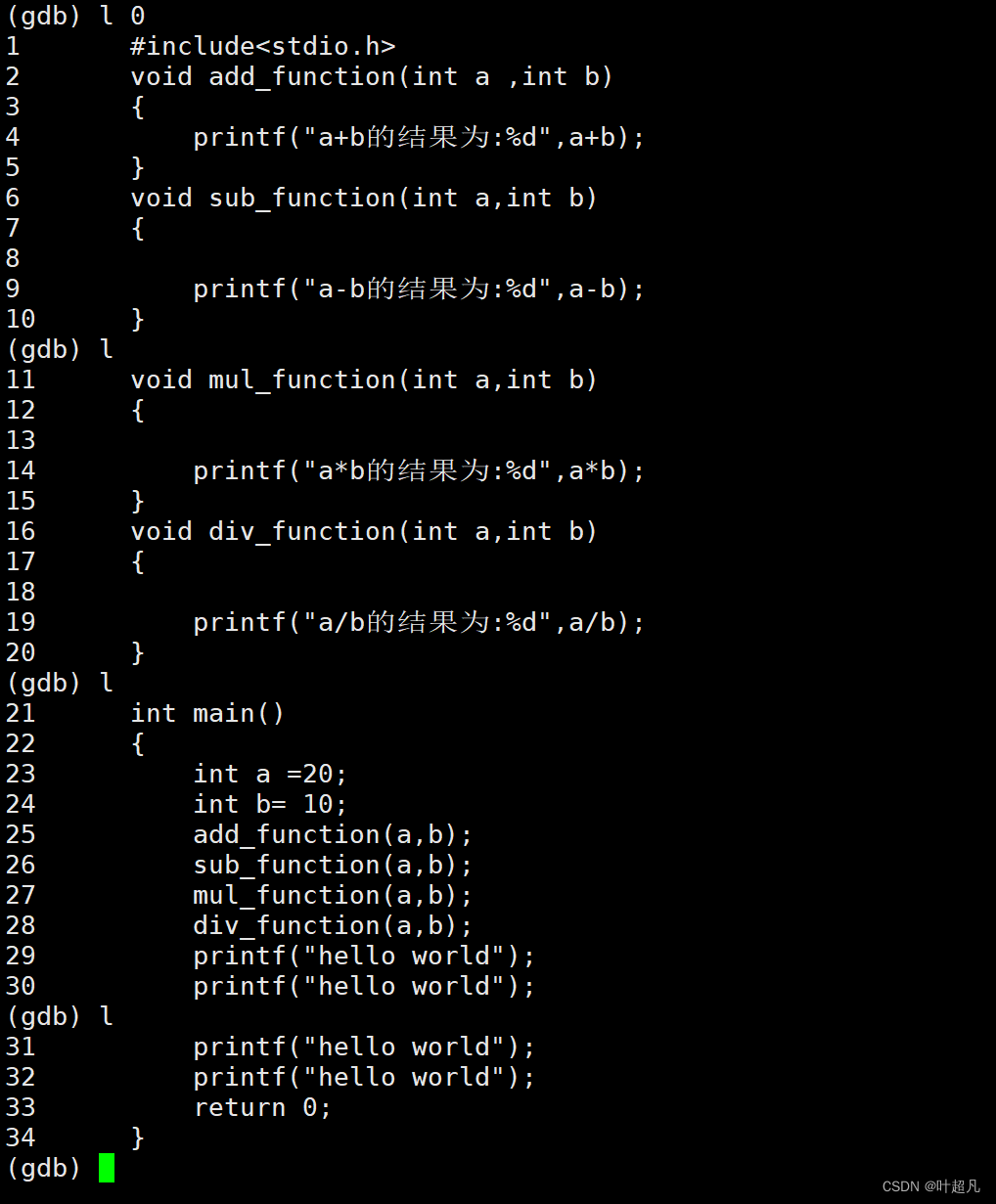
那么这就是l指令希望大家可以理解.
断点
使用break指令可以在对应行上添加断点其指令形式如下:break n其中n代表的意思是断点所在行,当断点添加成功时就会在命令行中显示这些内容:

break可以在命令行中添加断点,如果大家嫌break太麻烦的话也可以使用break的首字母b来添加断点其指令的形式如下:b n其使用的方法如下:

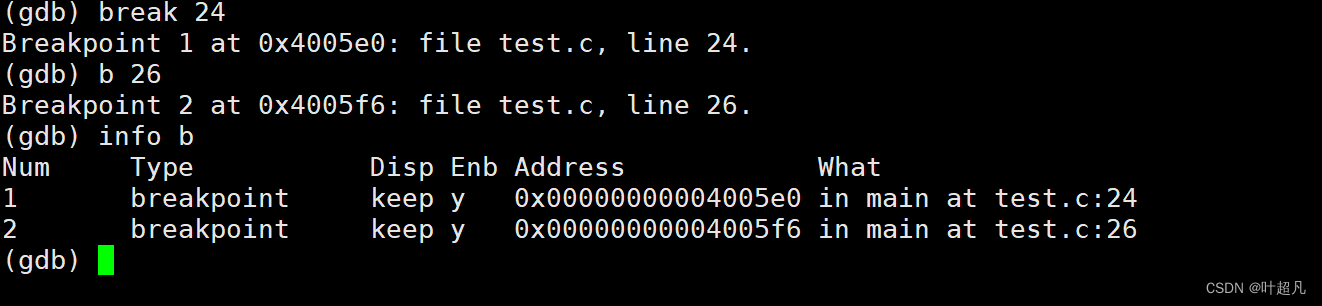
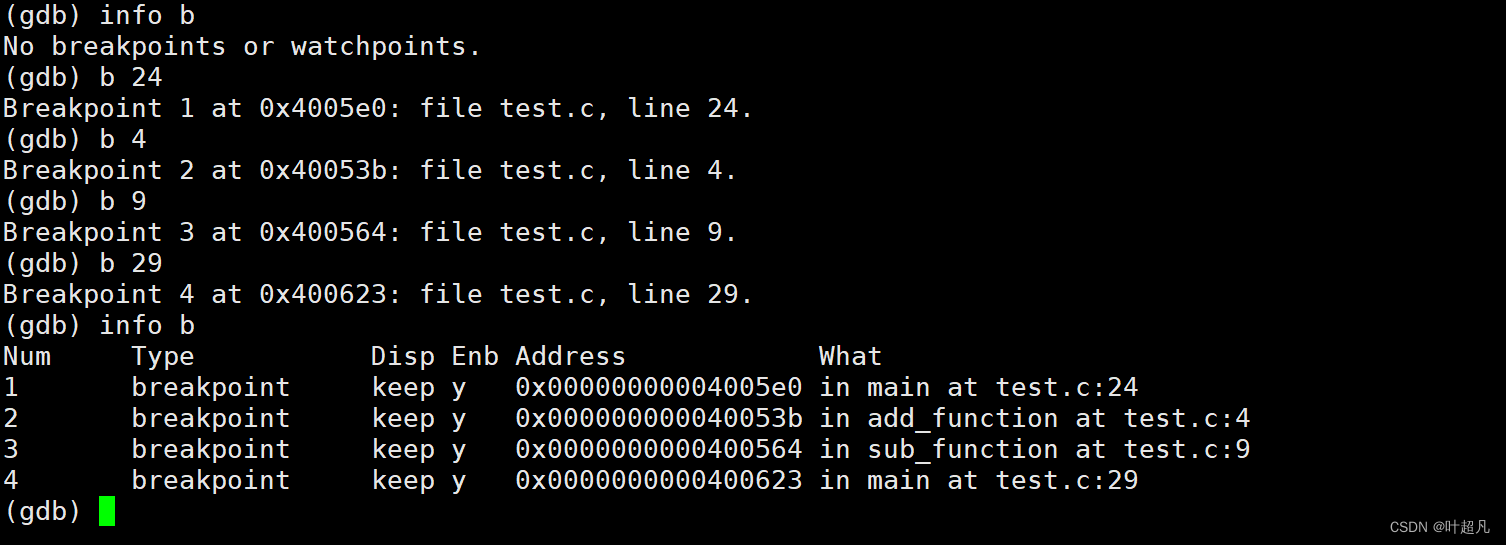
当在一段代码中添加了许多断点之后就可以使用info指令来查看添加的断点的信息其指令的形式如下:info b其中b的全称是break断点的意思,这里在24行和26行添加了断点所以使用info指令查看断点信息的时候就会显示两个断点的信息:
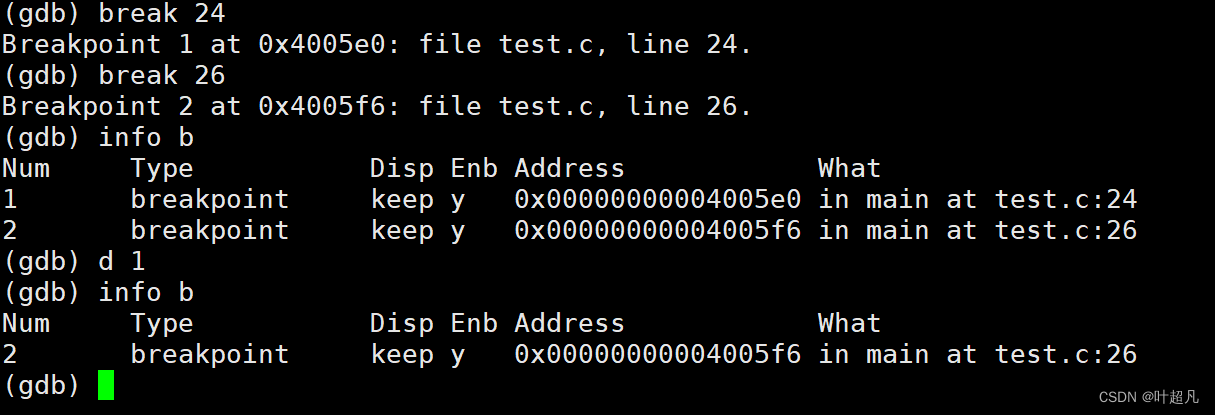
当我们在使用的时候想要删除一些断点时就可以使用d指令其形式为:d n这里大家要注意的一点这里的n不是代码中的行号而是断点的编号,使用info指令可以显示代码的编号也就是第一行显示的Num其表示的意思是1号断点2号断点等等,那么这里的d指令就得跟上断点的编号来进行删除比如说下面的操作:
运行
断点添加完之后就可以运行并调试这段代码,在vs中单独按F5可以使编译器开始调试并运行到第一个断点所在处,如果没有断点那就将所有的代码全部运行完,比如说下面的操作:

输入r指令就开始调试并运行文件中的代码,因为代码执行的过程中出现的第一个断点是2号断点,所以命令行就会显示此时程序已经运行到了2号断点此断点在代码中的第26行,那么这里我们就称这个行为为断点被命中,使用info b指令就可以查看断点是否被命中以及被命中的次数,比如说下面的操作:

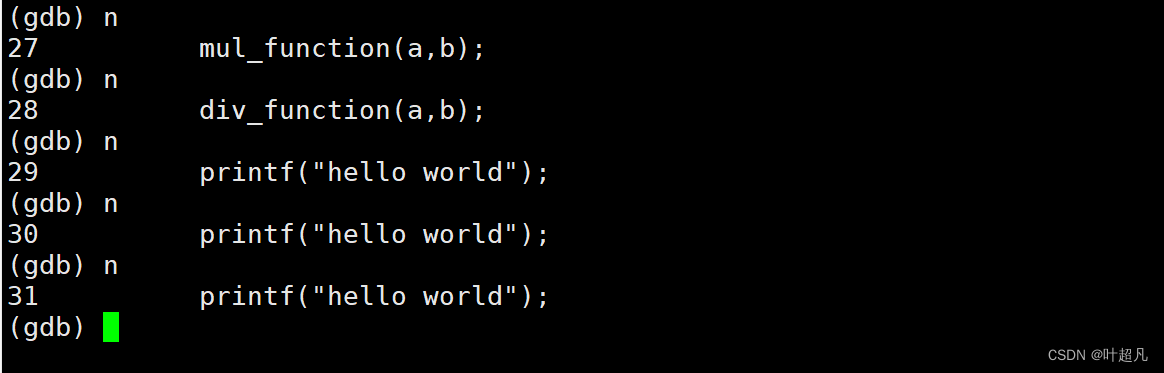
这里就显示了此断点已经被命中且命中的次数为1次。vs中按下F5会将程序运行到第一个断点处如果想要让程序运行到该断点的下一行的话就可以按F10,F10的功能就是逐过程调试程序也就是一行一行的调试程序,那么这个功能在gdb中就是n指令,此时的程序运行到了第26行输入n指令后程序就运行到了第27行:
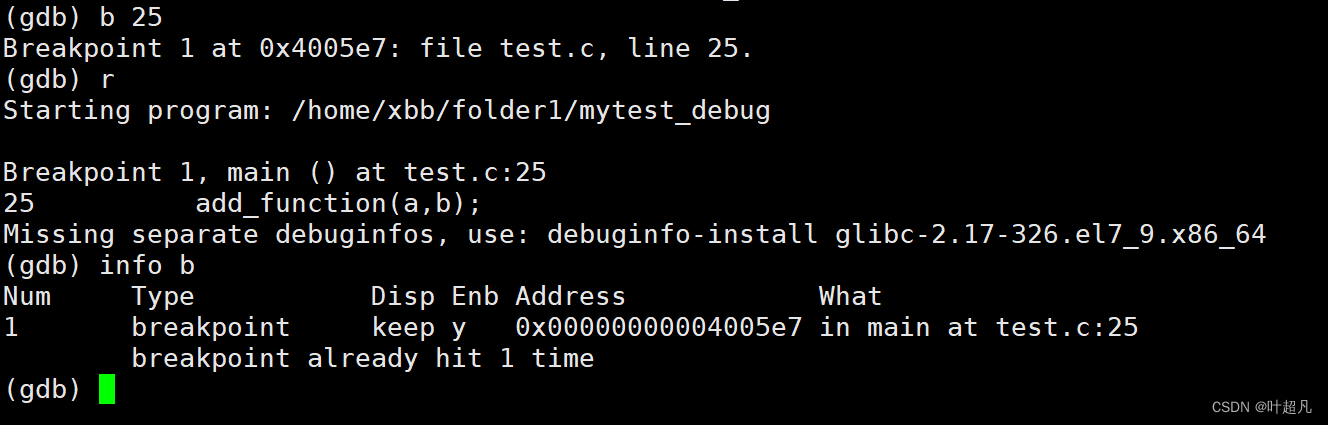
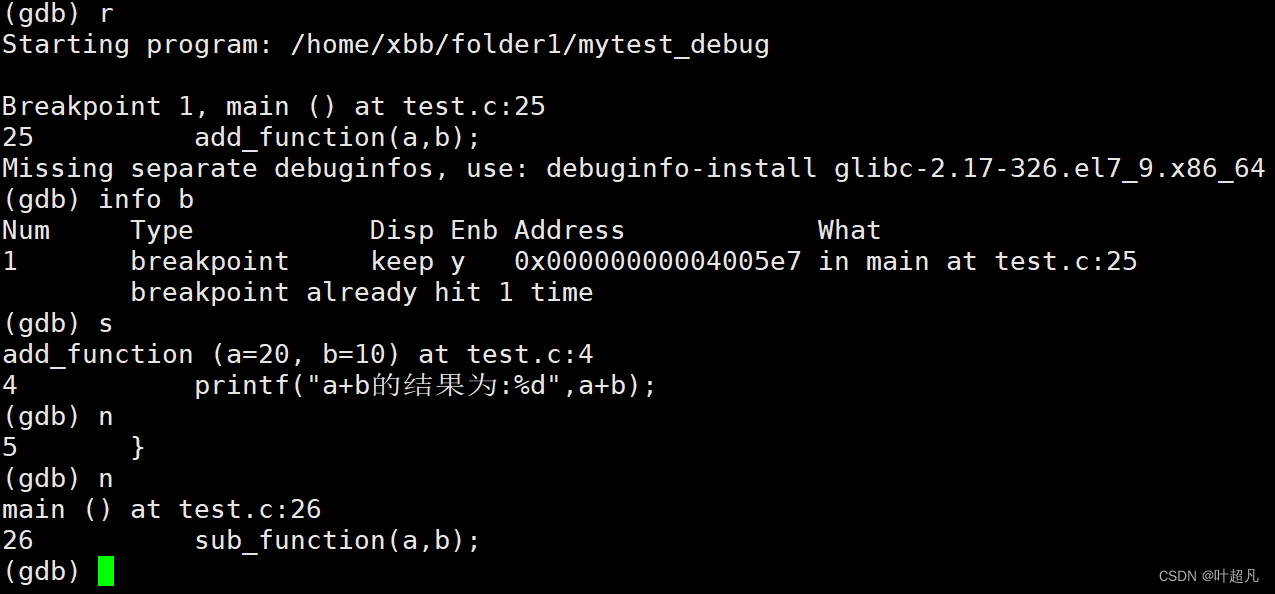
在vs中如果想要查看自定义函数的运行过程的话就可以将程序运行到调用函数的那一行然后按F11键程序运行到函数的内部,我们把这种调试的方式称为逐过程,而gdb中的s指令就相当于vs中的F11我们来看看下面的操作:重新运行gdb让程序运行到第一个断点处,这里将第一个断点设置到第25行:
这时再输入s就可以看到程序运行到了add_function函数里面,并且显示了这个函数的参数所对应的值:
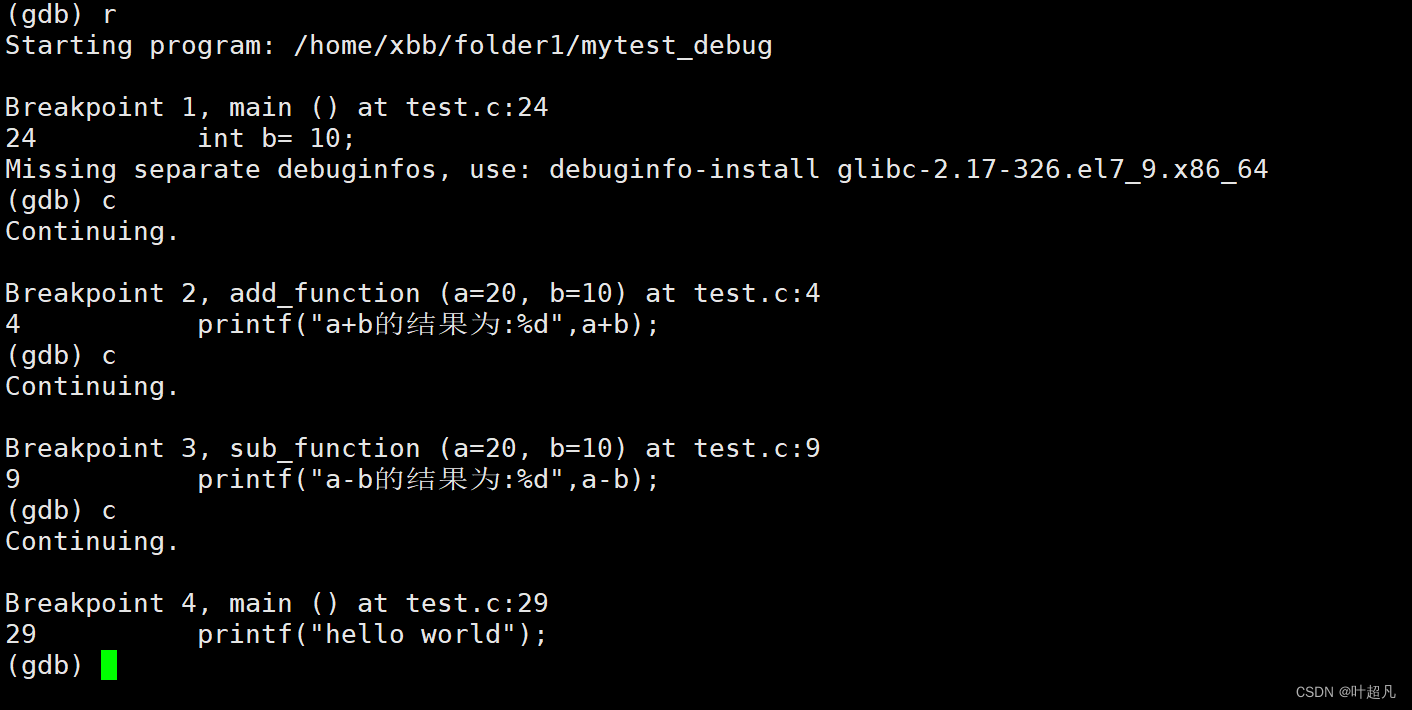
在vs中多次输入F5可以将程序从一个断点处运行到下一个断点我们将这种行为称为逐断点,而在gdb中指令c的功能就是逐断点,在代码中添加多个断点:
然后输入r指令就可以将当前程序运行到第一个断点处,然后再输入c指令就可以将当前程序运行到下一个断点处:
使用bt指令可以查看当前函数的调用堆栈,将程序运行到第25行并进入到这个函数里面输入bt指令就可以查看当前程序的调用堆栈:
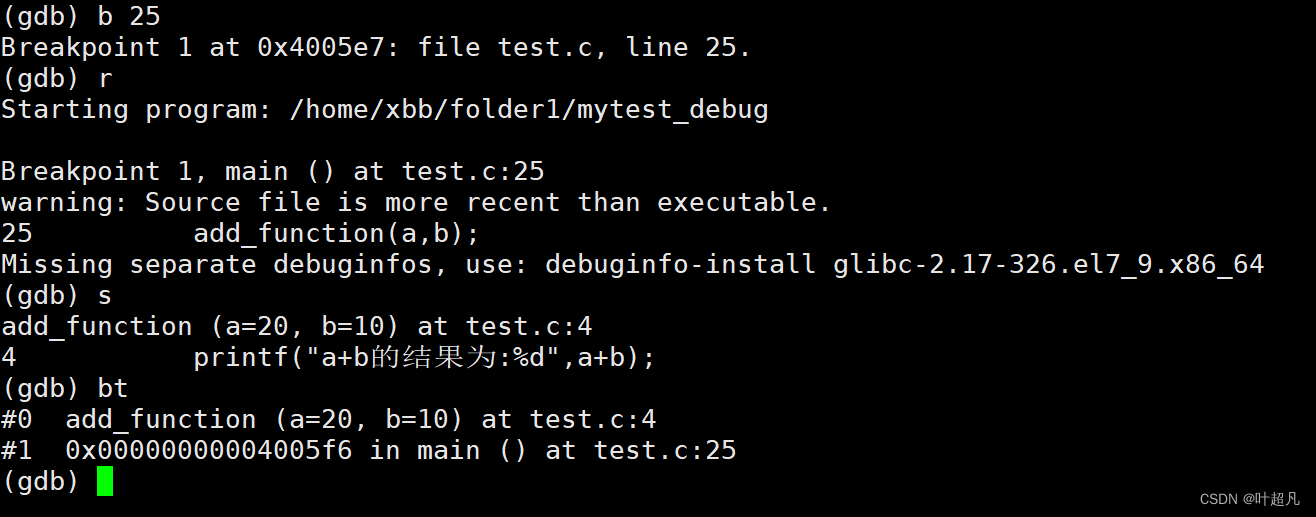
最上面的是当前执行过程所在的函数,越往下越是基层函数也就是说当前是在main函数中调用的add_function函数。我们来看看下面的代码:
#include<stdio.h>
2 int func(int x,int y)
3 {
4 printf("x+y=%d\n",x+y);
5 printf("x+y=%d\n",x+y);
6 printf("x+y=%d\n",x+y);
7 printf("x+y=%d\n",x+y);
8 return x+y;
9 }
10 int main()
11 {
12 int a=10;
13 int b=20;
14 func(a,b);
15 printf("a=%d,b=%d\n",a,b);
16 return 0;
17 }
在第4行添加一个断点这样输入r指令时就可以让程序直接运行到第4行:
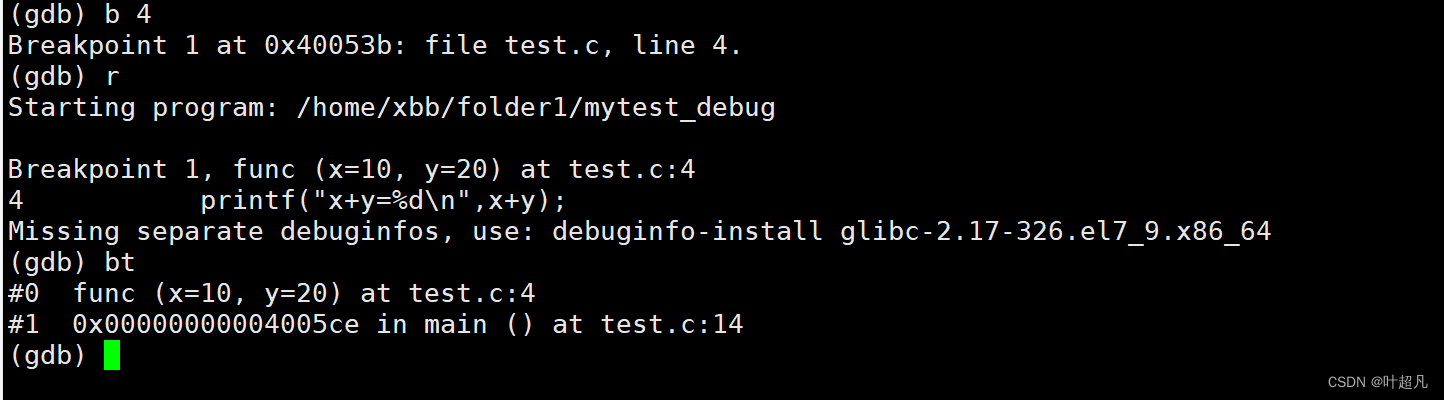
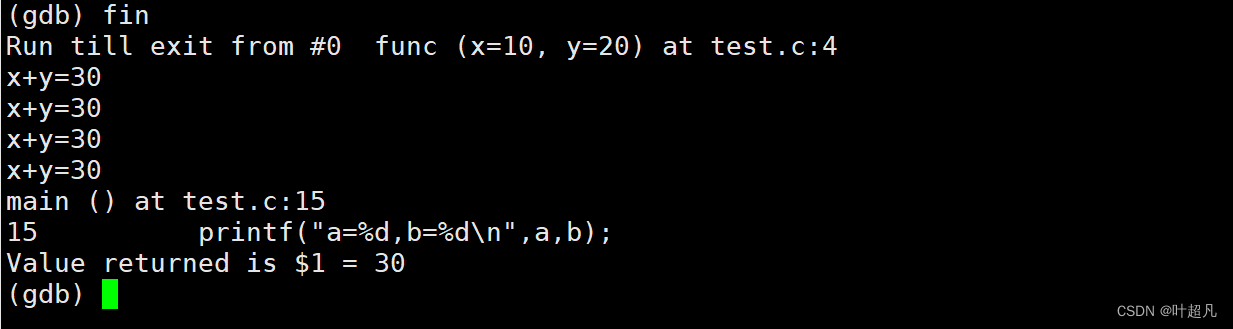
并且通过调用堆栈功能可以看到此时在main函数中调用了func函数,这时想要执行完这个函数的话有两个方法一个是不停的输入n指令一步一步的走出函数,另外一个就是在main函数中的函数调用的下面再添加一个断点然后输入c指令使其能够跳转到下一个断点从而执行完函数,如果大家既不想一步一步的走又不想添加断点的话就可以使用fin指令这个指令的功能就是立刻执行完该函数并将程序停止到该函数调用的下一行:
使用p指令可以查看临时变量的值其使用的形式为:p + 变量名
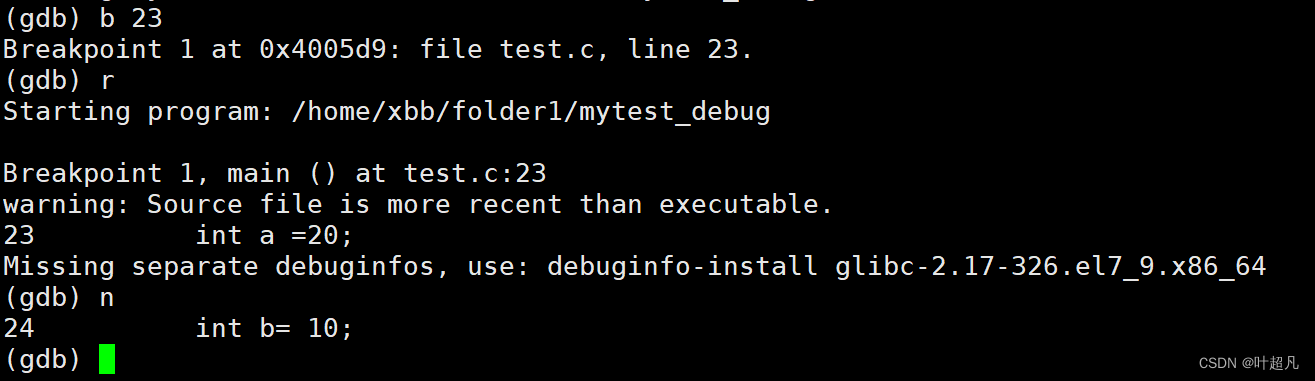
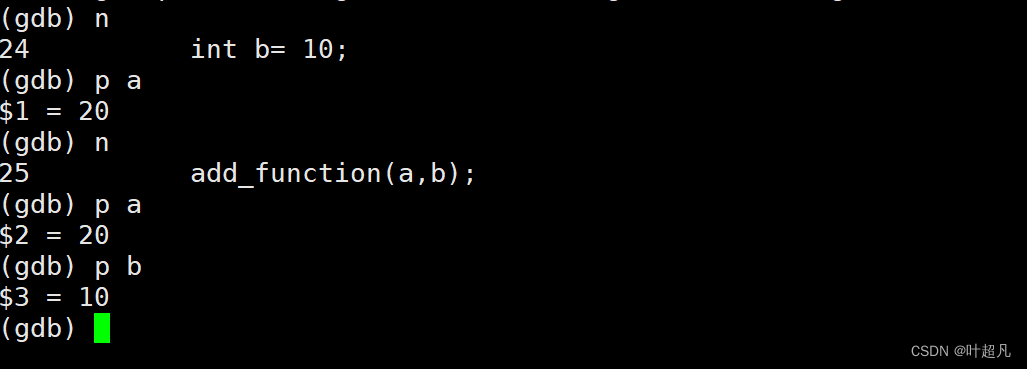
输入p a就可以查看变量a的值:

但是再输入一个n指令就可以发现使用这个指令显示的变量无法永远存在,我们得再次输入p a来查看变量a的值
如果想要永久的查看变量的值得话就得使用display指令display 变量名比如说下面得操作:
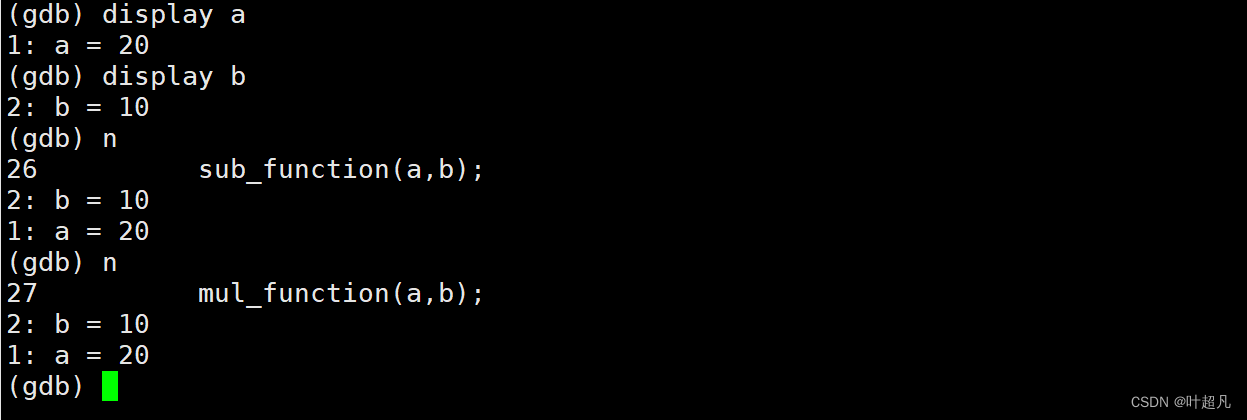
如果想要删除display显示得永久变量的值的话就可以使用undisplay指令其形式为:undisplay n这里的n为变量的序号也就是显示的变量名前面的序号,这里的b的序号为2,a的序号为1,所以要想删除a的话就得输入display 1:

如果大家觉得这种显示变量的值的方式太麻烦的话就可以输入info locals来显示当前函数中的所有变量的值,比如说我们当前所在的函数为main函数这个函数里面有变量a和变量b,那么输入info locals就会将变量a和b的值全部显示出来:

那么这就是这篇文章的全部内容希望大家可以理解。


















 689
689

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











