import numpy as np
# 最大迭代次数,用于控制迭代求解线性方程组的循环次数,防止无限循环
max_iter = 100
# 收敛精度,当相邻两次迭代结果的差值小于此值时,认为迭代收敛,找到了满足精度要求的解
Delta = 0.01
# 矩阵的行数,这里特意设置为与列数相等,确保要处理的矩阵是方阵(因为后续一些操作要求矩阵为方阵,比如求逆)
m = 3
# 矩阵的列数,与行数相等,共同确定矩阵的形状
n = 3
# 定义矩阵的形状,为一个包含行数和列数的元组,用于后续创建和操作矩阵
shape = (m, n)
def read_tensor(f, shape):
"""
从给定的文件对象中读取数据,并将其转换为指定形状的多维数组(在这里表示二维矩阵)。
参数:
f (file object): 已经打开的文件对象,从中按行读取数据。
shape (tuple): 期望得到的矩阵形状,格式为 (行数, 列数)。
返回:
np.array: 转换后的多维数组(二维矩阵),其形状与传入的 shape 参数一致。
"""
data = []
# 按矩阵的行数进行循环,逐行读取数据
for i in range(shape[0]):
line = f.readline()
# 将读取到的每行字符串数据按逗号分割,然后使用 eval 函数将每个元素转换为合适的Python对象(通常是数字),
# 并添加到 data 列表中,这里使用 eval 需要确保文件中的数据格式是合法的,否则可能存在安全风险,
# 更安全的做法可以是明确转换为特定的数据类型(如 float),如果数据格式固定的话。
data.append(list(map(eval, line.split(","))))
return np.array(data).reshape(shape)
def read_vector(f):
"""
从给定的文件对象中读取一行数据,并将其转换为一维数组(向量)。
参数:
f (file object): 已经打开的文件对象,从中读取一行数据。
返回:
np.array: 转换后的一维数组(向量)。
"""
line = f.readline()
# 去除行末的换行符,确保数据的纯净性,便于后续处理
line = line.replace("\n", "")
# 将处理后的字符串按逗号分割,再使用 eval 函数将每个元素转换为合适的Python对象(通常是数字),
# 最后转换为 numpy 数组返回,同样使用 eval 存在安全风险,可视情况替换为更安全的类型转换方式。
line = list(map(eval, line.split(",")))
return np.array(line)
# 打开名为 "123.txt" 的文件,用于读取矩阵 A 和向量 b 的数据,这里没有指定编码,
# 可能会依赖系统默认编码,若出现编码相关问题,需明确指定合适的编码格式打开文件。
f = open("123.txt")
# 调用 read_tensor 函数从文件中读取数据并构建矩阵 A,传入文件对象和矩阵形状参数
A = read_tensor(f, shape)
# 调用 read_vector 函数从文件中读取数据构建向量 b,传入文件对象
b = read_vector(f)
# 关闭文件,释放相关资源
f.close()
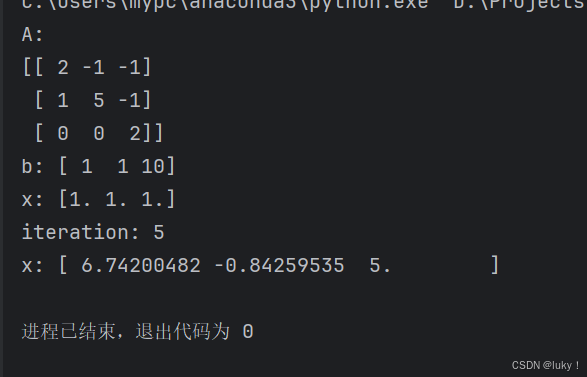
print('A:')
print(A)
print('b:', b)
# 对矩阵 A 进行拷贝,得到 LU 矩阵,后续将基于 LU 矩阵进行一些分解相关的操作(类似 LU 分解的一种变形操作)
LU = np.copy(A)
# 循环遍历矩阵的主对角线元素(行数和列数相等,所以可以同时用 m 表示范围)
for i in range(m):
# 将 LU 矩阵的主对角线元素设置为 0,这可能是为了分离出某种特定的矩阵结构,符合特定算法要求(比如类似 LU 分解中的操作)
LU[i, i] = 0
# 对 LU 矩阵取负,改变其元素的值,这一步也是基于特定的算法逻辑来构建相应的矩阵形式
LU = -LU
# 对矩阵 A 进行拷贝,得到 D 矩阵,D 矩阵将在后续与 LU 矩阵配合用于迭代求解过程
D = np.copy(A)
# 通过 D 矩阵减去 LU 矩阵来更新 D 矩阵,这里构建 D 矩阵的方式同样是基于特定的算法原理,
# 可能与整体的迭代求解线性方程组的方法相关(例如某种迭代法中对系数矩阵的处理)
D = D - LU
# 创建一个长度为 n 的全 1 数组,作为线性方程组解的初始猜测值,这里初始化为全 1 是一种常见的简单初始化方式,
# 不同的初始值可能会影响迭代的收敛速度和结果,具体要根据问题特点选择合适的初始值。
x = np.ones(n)
# 同样创建一个长度为 n 的全 1 数组,用于在迭代过程中临时存储计算结果,后续会不断更新其值
y = np.ones(n)
# 计算 DLU,即先对 D 矩阵求逆,然后与 LU 矩阵进行矩阵乘法运算,得到的结果 DLU 在迭代过程中起到关键作用,
# 其与当前的解向量估计值 x 相乘等操作来逐步逼近真实解,这是基于特定迭代算法的数学原理。
DLU = np.dot(np.linalg.inv(D), LU)
# 计算 Db,即对 D 矩阵求逆后与向量 b 进行矩阵乘法运算,Db 同样是迭代过程中用于更新解向量的重要部分,
# 它与 DLU 和当前解向量的计算共同构成了每次迭代的更新规则。
Db = np.dot(np.linalg.inv(D), b)
print('x:', x)
# 开始迭代过程,循环 max_iter 次,除非在迭代过程中提前满足收敛条件而跳出循环
for iteration in range(max_iter):
# 根据当前的解向量 x、DLU 和 Db,按照特定的迭代公式计算下一次迭代的解向量估计值 y,
# 这一步体现了迭代算法中基于前一次结果来更新当前结果的核心思想,通过矩阵乘法和向量加法来更新 y 的值。
y = np.dot(DLU, x) + Db
# 计算当前解向量估计值 x 和新计算出的 y 之间差值的绝对值,然后取这些差值绝对值中的最大值,
# 判断这个最大值是否小于预设的收敛精度 Delta,如果小于则说明迭代已经收敛,找到了满足精度要求的解。
if np.max(np.abs(x - y)) < Delta:
print('iteration:', iteration)
break
# 如果还未满足收敛条件,将本次计算得到的 y 值赋给 x,作为下一次迭代的基础,继续进行迭代更新。
x = np.copy(y)
print('x:', x)
返回结果:

























 6176
6176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











