







本文主要关注Linux环境堆内存的管理,详细解析Glibc与TCMalloc的malloc原理, 由于本人能力有限,难免会出现解读错误的地方,望各位大佬批评指正,后面也会在进一步解读中对本文进行修改。
1 Linux内存分布
下图的布局形式是在内核 2.6.7 以后才引入的,这是 32 位模式下进程的默认内存布局形式。Linux 系统在装载 elf 格式的程序文件时,会调用 loader 把可执行文件中的各个段依次载入到从某一地址开始的空间中(载入地址取决 link editor(ld)和机器地址位数,在 32 位机器上是 0x8048000,即 128M 处)。
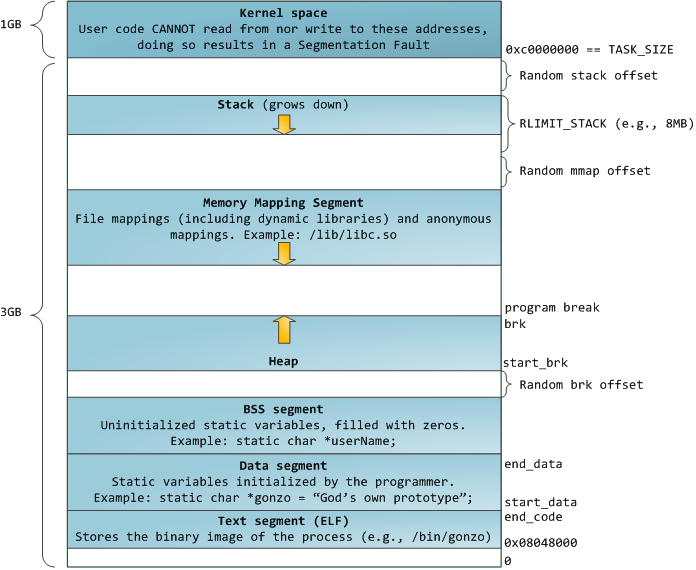
以 32 位机器为例,首先被载入的是.text 段,然后是.data 段,最后是.bss 段。这可以看作是程序的开始空间。程序所能访问的最后的地址是 0xbfffffff,也就是到 3G 地址处,3G 以上的 1G 空间是内核使用的,应用程序不可以直接访问。
应用程序的堆栈从最高地址处开始向下生长,.bss 段与堆栈之间的空间是空闲的,空闲空间被分成两部分,一部分为 heap,一部分为 mmap 映射区域,mmap 映射区域一般从 TASK_SIZE/3 的地方开始,但在不同的 Linux 内核和机器上,mmap 区域的开始位置一般是不同的。Heap和 mmap 区域都可以供用户自由使用,但是它在刚开始的时候并没有映射到内存空间内,是不可访问的。在向内核请求分配该空间之前,对这个空间的访问会导致 segmentation fault。用户程序可以直接使用系统调用来管理 heap和 mmap映射区域,但更多的时候程序都是使用 C 语言提供的 malloc()和 free()函数来动态的分配和释放内存。
Stack区域是唯一不需要映射,用户却可以访问的内存区域,这也是利用堆栈溢出进行攻击的基础。
栈至顶向下扩展,并且栈是有界的。堆至底向上扩展,mmap 映射区域至顶向下扩展,mmap映射区域和堆相对扩展,直至耗尽虚拟地址空间中的剩余区域,这种结构便于C 运行时库使用mmap映射区域和堆进行内存分配。
1.1 brk与mmap

用strace分析malloc内存申请过程。长话短说,申请内存空间一般就两种方法,一种是malloc,另一种是 mmap映射空间。 在使用malloc()分配内存的时候,可能系统调用brk(),也可能调用mmap()。malloc调用规律如下:
1、即分配一块小型内存(小于或等于128kb),malloc()会调用brk()调高断点(brk是将数据段(.data)的最高地址指针_edata往高地址推),分配的内存在堆区域。
2、当分配一块大型内存(大于128kb),malloc()会调用mmap2()分配一块内存(mmap是在进程的虚拟地址空间中(一般是堆和栈中间)找一块空闲的空间。
1.1.1 内存描写符mm_struct
内存描写符用1个结构体mm_struct(内存描写符) 表示,linux就是通过mm_struct这个结构体来实现内存管理。 1个进程的虚拟地址空间主要由两个数据结构来描写,1个是最高层次的mm_struct,1个是较高层次的vm_ares_struct。最高层次的mm_struct结构描写了1个进程的全部虚拟地址空间。较高层次的结构vm_area_struct描写了虚拟地址空间的1个区间(简称虚拟区)。每一个进程只有1个mm_struct结构,在每一个进程的task_struct结构体中,有1个指向该进程的结构。可以说,mm_struct结构是对全部用户空间的描写。
struct mm_struct
{
struct vm_area_struct *mmap; //指向虚拟区间(VMA)链表
struct rb_root mm_rb; //指向red_black树
struct vm_area_struct *mmap_cache; //找到最近的虚拟区间
unsigned long(*get_unmapped_area)(struct file *filp,unsigned long addr,unsigned long len,unsigned long pgoof,unsigned long flags);
void (*unmap_area)(struct mm_struct *mm,unsigned long addr);
unsigned long mmap_base;
unsigned long task_size; //具有该结构体的进程的虚拟地址空间的大小
unsigned long cached_hole_size;
unsigned long free_area_cache;
pgd_t *pgd; //指向页全局目录
atomic_t mm_users; //用户空间中有多少用户
atomic_t mm_count; //对"struct mm_struct"有多少援用
int map_count; //虚拟区间的个数
struct rw_semaphore mmap_sem;
spinlock_t page_table_lock; //保护任务页表和mm->rss
struct list_head mmlist; //所有活动mm的链表
mm_counter_t _file_rss;
mm_counter_t _anon_rss;
unsigned long hiwter_rss;
unsigned long hiwater_vm;
unsigned long total_vm,locked_vm,shared_vm,exec_vm;
usingned long stack_vm,reserved_vm,def_flags,nr_ptes;
unsingned long start_code,end_code,start_data,end_data; //代码段的开始start_code ,结束end_code,数据段的开始start_data,结束end_data
unsigned long start_brk,brk,start_stack; //start_brk和brk记录有关堆的信息,start_brk是用户虚拟地址空间初始化,brk是当前堆的结束地址,start_stack是栈的起始地址
unsigned long arg_start,arg_end,env_start,env_end; //参数段的开始arg_start,结束arg_end,环境段的开始env_start,结束env_end
unsigned long saved_auxv[AT_VECTOR_SIZE];
struct linux_binfmt *binfmt;
cpumask_t cpu_vm_mask;
mm_counter_t context;
unsigned int faultstamp;
unsigned int token_priority;
unsigned int last_interval;
unsigned long flags;
struct core_state *core_state;
}1.1.2 brk()系统调用
brk与sbrk 函数的头文件和原型定义如下:
#include <unistd.h>
int brk(void *addr);
void sbrk(intptr_t increment);内核数据结构mm_struct中 start_brk是进程动态分配的起始地址(heap的起始地址),brk 是堆当前最后的地址。program break就是当前brk的位置,所以他是数据段初始化结束后heap的第一个位置,而不是heap的尾部。
sbrk 通过给内核的 brk 变量增加 incr,来改变堆的大小,incr 可以为负数。当 incr 为正数时,堆增大,当 incr 为负数时,堆减小。如果 sbrk 函数执行成功,那返回值就是 brk的旧值;如果失败,就会返回 -1,同时会把 errno 设置为 ENOMEM。
一般如果用户分配的内存小于 128 KB,则通过 brk() 申请内存。而brk()的实现的方式很简单,就是通过 brk() 函数将堆顶指针向高地址移动,获得新的内存空间。如下图:

1.1.3 mmap系统调用
mmap 是一种内存映射方法,将一个文件或其他对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址一一对应的关系。内核空间对这块区域的改变也直接反应到用户空间,实现不同进程的文件共享。
Linux内核使用vm_area_struct结构表示一个独立的虚拟内存区域,一个进程使用多个vm_area_struct来分别表示不同类型的虚拟内存区域.
当vm_area_struct数目较少时,按照升序以单恋表的形式组织结构,在数目较多时使用AVL树来实现。

mmap函数是创建一个新的vm_area_struct结构,并将其与物理地址相连。
mmap 的头文件和原型如下所示:
#include <unistd.h>
#include <sys/mman.h>
void *mmap(void *start,size_t length,int prot,int flags,int fd,off_t offsize);mmap内存映射原理分为三个阶段:
1、进程启动映射过程,并在虚拟地址空间中为映射创建虚拟映射区域:
1>进程在用户空间调用mmap。
原型:void *mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset);
2>在当前进程的虚拟地址空间中,寻找一段空间满足要求的连续的虚拟地址。
3>为此虚拟区分配一个vm_area_struct 结构,接着对这个结构的各个域进行初始化
4>将新建的虚拟结构(vm_area_struct)插入到进程的虚拟地址区的链表或数种。
2、调用内核空间的系统调用函数mmap(不同于用户空间)实现文件物理地址和进程虚拟地址的一一映射关系:
5>为映射分配了新的虚拟地址区域后,通过待映射的文件指针,在文件描述符表中找到对应的文件描述符,加入到struct file中
6>linux中的file_operation结构中定义了不同事件对应的设备驱动函数,其中有 int mmap(struct file *filp, struct vm_area_struct *vma),其实这个函数就是将用户空间与设备内存相连,也就是对虚拟地址的访问转化为对设备的访问
7>通过inode模块找到对应的文件,也就是磁盘的物理地址
8>建立页表,实现文件地址和虚拟地址区域的映射关系。这里只建立了映射关系,主存中没有对应物理地址的数据。
3、进程发起对这片映射空间的访问,引发缺页异常,实现文件内容到主存的拷贝:
9>进程的读写,通过查询页表发现这一段地址不再物理页面上,引发缺页异常
10>进行缺页异常判断,申请调页
11>先判断swap cache中没有没需要访问的内存页,如果没有调用nopage把所缺德页从磁盘装入主存
12>之后可以进行读写,会有一段时间延迟,调用msync()立即更新。
1.2 c的内存管理
从操作系统角度来看,进程分配内存有两种方式,分别由两个系统调用完成:brk和mmap(不考虑共享内存)。在标准C库中,提供了malloc/free函数分配释放内存,这两个函数底层是由brk,mmap,munmap这些系统调用实现的。
1、brk是将数据段(.data)的最高地址指针_edata往高地址推;
2、mmap是在进程的虚拟地址空间中(堆和栈中间,称为文件映射区域的地方)找一块空闲的虚拟内存。
这两种方式分配的都是虚拟内存,没有分配物理内存。在第一次访问已分配的虚拟地址空间的时候,发生缺页中断,操作系统负责分配物理内存,然后建立虚拟内存和物理内存之间的映射关系。但是mmap肯定发生缺页中断,brk不一定。
各种C内存管理程序实现的对比如下:
| 策略 | 分配速度 | 回收速度 | 局部缓存 | 易用性 | 通用性 | SMP 线程友好度 |
| GNU Malloc | 中 | 快 | 中 | 容易 | 高 | 中 |
| Hoard | 中 | 中 | 中 | 容易 | 高 | 高 |
| TCMalloc | 快 | 快 | 中 | 容易 | 高 | 高 |
2 glibc ptmalloc2
Wolfram Gloger 在Doug Lea的基础上改进使得Glibc的malloc可以支持多线程——ptmalloc,在glibc-2.3.x.中已经集成ptmalloc2,这就是我们平时使用malloc,目前ptmalloc的最新版本ptmalloc3。ptmalloc2的性能略微比ptmalloc3要高一点点。
Ptmalloc2对heap的操作, 操作系统提供了brk()系统调用,设置了Heap的上边界;对 mmap 映射区域的操作,操作系统供了mmap()和 munmap()函数。因为系统调用的代价很高,不可能每次申请内存都从内核分配空间,尤其是对于小内存分配。而且因为mmap的区域容易被munmap释放,所以一般大内存采用mmap(),小内存使用brk()。
Ptmalloc2有一个主分配区(main arena),有多个非主分配区。非主分配区只能使用mmap向操作系统批发申请HEAP_MAX_SIZE(64位系统为64MB)大小的虚拟内存。当某个线程调用malloc的时候,会先查看线程私有变量中是否已经存在一个分配区,如果存在则尝试加锁,如果加锁失败则遍历arena链表试图获取一个没加锁的arena,如果依然获取不到则创建一个新的非主分配区。
free()的时候也要获取锁。分配小块内存容易产生碎片,ptmalloc在整理合并的时候也要对arena做加锁操作。在线程多的时候,锁的开销就会增大。
2.1 ptmalloc内存管理
用户请求分配的内存在ptmalloc中使用chunk表示,每个chunk至少需要8个字节额外的开销。用户free掉的内存不会马上归还操作系统,ptmalloc会统一管理heap和mmap区域的空闲chunk,避免了频繁的系统调用。
ptmalloc将相似大小的chunk用双向链表链接起来, 这样的一个链表被称为一个bin。Ptmalloc 一共维护了128个bin,并使用一个数组来存储这些bin(如下图所示)。

数组中的第一个为unsorted bin, 数组中从 2 开始编号的前 64个bin称为small bins, 同一个small bin中的chunk具有相同的大小。small bins后面的bin被称作large bins。

当free一个chunk并放入bin的时候, ptmalloc 还会检查它前后的 chunk 是否也是空闲的, 如果是的话,ptmalloc会首先把它们合并为一个大的 chunk, 然后将合并后的 chunk 放到 unstored bin 中。 另外ptmalloc 为了提高分配的速度,会把一些小的(不大于64B) chunk先放到一个叫做 fast bins 的容器内。
在fast bins和bins都不能满足需求后,ptmalloc会设法在一个叫做top chunk的空间分配内存。 对于非主分配区会预先通过mmap分配一大块内存作为top chunk, 当bins和fast bins都不能满足分配需要的时候, ptmalloc会设法在top chunk中分出一块内存给用户, 如果top chunk本身不够大, 分配程序会重新mmap分配一块内存chunk, 并将 top chunk 迁移到新的chunk上,并用单链表链接起来。如果free()的chunk恰好 与 top chunk 相邻,那么这两个 chunk 就会合并成新的 top chunk,如果top chunk大小大于某个阈值才还给操作系统。主分配区类似,不过通过sbrk()分配和调整top chunk的大小,只有heap顶部连续内存空闲超过阈值的时候才能回收内存。
需要分配的chunk足够大,而且fast bins和bins都不能满足要求,甚至top chunk本身也不能满足分配需求时,ptmalloc会使用mmap来直接使用内存映射来将页映射到进程空间。
2.2 源码解读
2.2.1 chunk内存块
ptmalloc 采用边界标记法将内存划分成很多块,从而对内存的分配与回收进行管理。在 ptmalloc 的实现源码中定义结构体 malloc_chunk 来描述这些块,并使用宏封装了对 chunk中每个域的读取,修改,校验,遍历等等。malloc_chunk 定义如下:
#ifndef MALLOC_ALIGNMENT
#define MALLOC_ALIGNMENT (2 * SIZE_SZ)
#endif
#ifndef MALLOC_ALIGNMENT
#define MALLOC_ALIGNMENT (2 * SIZE_SZ)
#endif
struct malloc_chunk {
INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */
INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */
struct malloc_chunk* fd; /* double links -- used only if free. */
struct malloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */
struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
struct malloc_chunk* bk_nextsize;
};chunk 的定义相当简单明了,对各个域做一下简单介绍:
prev_size:如果前一个 chunk 是空闲的,该域表示前一个 chunk 的大小,如果前一个 chunk 不空闲,该域无意义。
size:当前 chunk 的大小,并且记录了当前 chunk 和前一个 chunk 的一些属性,包括前 28 一个 chunk 是否在使用中,当前 chunk 是否是通过 mmap 获得的内存,当前 chunk 是否属于 非主分配区。
fd 和 bk:指针 fd 和 bk 只有当该 chunk 块空闲时才存在,其作用是用于将对应的空闲 chunk 块加入到空闲 chunk 块链表中统一管理,如果该 chunk 块被分配给应用程序使用,那 么这两个指针也就没有用(该 chunk 块已经从空闲链中拆出)了,所以也当作应用程序的使 用空间,而不至于浪费。
fd_nextsize 和 bk_nextsize:当当前的 chunk 存在于 large bins 中时,large bins 中的空闲 chunk 是按照大小排序的,但同一个大小的 chunk 可能有多个,增加了这两个字段可以加快 遍历空闲 chunk,并查找满足需要的空闲 chunk,fd_nextsize 指向下一个比当前 chunk 大小 大的第一个空闲 chunk,bk_nextszie 指向前一个比当前 chunk 大小小的第一个空闲 chunk。 如果该 chunk 块被分配给应用程序使用,那么这两个指针也就没有用(该 chunk 块已经从 size 链中拆出)了,所以也当作应用程序的使用空间,而不至于浪费。
在不同的平台下,每个chunk的最小大小,地址对齐方式是不同的,ptmalloc 依赖平台 定义的size_t长度,对于32位平台,size_t长度为4字节,对64位平台,size_t 长度可能为4字节,也可能为8字节。
chunk的结构可以分为使用中的chunk和空闲的chunk。使用中的chunk和空闲的chunk数据结构基本相同,但是会有一些设计上的小技巧,巧妙的节省了内存。
1、使用中的chunk

在图中,chunk 指针指向一个 chunk 的开始,一个 chunk 中包含了用户请求的内存区域 和相关的控制信息。图中的 mem 指针才是真正返回给用户的内存指针。chunk 的第二个域 的最低一位为 P,它表示前一个块是否在使用中,P 为 0 则表示前一个 chunk 为空闲,这时 chunk 的第一个域 prev_size 才有效,prev_size 表示前一个 chunk 的 size,程序可以使用这个 值来找到前一个 chunk 的开始地址。当 P 为 1 时,表示前一个 chunk 正在使用中,prev_size 16 无效,程序也就不可以得到前一个chunk的大小。不能对前一个chunk进行任何操作。ptmalloc 分配的第一个块总是将 P 设为 1,以防止程序引用到不存在的区域。
Chunk 的第二个域的倒数第二个位为 M,他表示当前 chunk 是从哪个内存区域获得的虚 拟内存。M 为 1 表示该 chunk 是从 mmap 映射区域分配的,否则是从 heap 区域分配的。
Chunk 的第二个域倒数第三个位为 A,表示该 chunk 属于主分配区或者非主分配区,如果属于非主分配区,将该位置为 1,否则置为 0。
2、空闲的chunk

当 chunk 空闲时,其 M 状态不存在,只有 AP 状态,原本是用户数据区的地方存储了四个指针,指针 fd 指向后一个空闲的 chunk,而 bk 指向前一个空闲的 chunk,ptmalloc 通过这 两个指针将大小相近的 chunk 连成一个双向链表。对于 large bin 中的空闲 chunk,还有两个 指针,fd_nextsize 和 bk_nextsize,这两个指针用于加快在 large bin 中查找最近匹配的空闲 chunk。不同的 chunk 链表又是通过 bins 或者 fastbins 来组织的。
3、chunk中的空间复用
为了使得 chunk 所占用的空间最小, ptmalloc 使用了空间复用, 一个 chunk 或者正在被使用, 或者已经被 free 掉, 所以 chunk 的中的一些域可以在使用状态和空闲状态表示不同的意义, 来达到空间复用的效果。以 32 位系统为例,空闲时, 一个 chunk 中至少要4个 size_t 大小的空间, 用来存储 prev_size, size , fd 和 bk ,也就是16 bytes,chuck 的大小要 align 到8 bytes. 当一个 chunk 处于使用状态时, 它的下一个 chunk 的 prev_size 域肯定是无效的. 所以实际上, 这个空间也可以被当前 chunk 使用. 这听起来有点不可思议, 但确实是合理空间复用的例子. 故而实际上, 一个使用中的 chunk 的大小的计算公式应该是:
in_use_size = ( 用户请求大小 + 8 - 4 ) align to 8 bytes 这里加8是因为需要存储 prev_size 和 size, 但又因为向下一个 chunk “借”了4个bytes, 所以要减去4. 最后, 因为空闲的 chunk 和使用中的 chunk 使用的是同一块空间. 所以肯定要取其中最大者作为实际的分配空间. 即最终的分配空间 chunk_size = max(in_use_size, 16). 这就是当用户请求内存分配时, ptmalloc 实际需要分配的内存大小, 在后面的介绍中. 如果不是特别指明的地方, 指的都是这个经过转换的实际需要分配的内存大小, 而不是用户请求的内存分配大小。
2.2.2 空闲链表bins
当用户使用free函数释放掉的内存,ptmalloc并不会马上交还给操作系统,而是被ptmalloc本身的空闲链表bins管理起来了,这样当下次进程需要malloc一块内存的时候,ptmalloc就会从空闲的bins上寻找一块合适大小的内存块分配给用户使用。这样的好处可以避免频繁的系统调用,降低内存分配的开销。
malloc将相似大小的chunk用双向链表链接起来,这样一个链表被称为一个bin。ptmalloc一共维护了128bin。每个bins都维护了大小相近的双向链表的chunk。基于chunk的大小,有下列几种可用bins:1、Fast bin 2、Unsorted bin 3、Small bin 4、Large bin。

Fast bins 是小内存块的高速缓存,当一些大小小于 64 字节的 chunk 被回收时,首先会放入 Fast bins 中,在分配小内存时,首先会查看 Fast bins 中是否有合适的 内存块,如果存在,则直接返回 fast bins 中的内存块,以加快分配速度。
Usorted bin 只有一 个,回收的 chunk 块必须先放到 unsorted bin 中,分配内存时会查看 unsorted bin 中是否有 合适的 chunk,如果找到满足条件的 chunk,则直接返回给用户,否则将 unsorted bin 的所 有 chunk 放入 small bins 或是 large bins 中。
Small bins 用于存放固定大小的 chunk,共 64 个 bin,最小的 chunk 大小为 16 字节或 32 字节,每个 bin 的大小相差 8 字节或是 16 字节,当分配小内存块时,采用精确匹配的方式从 small bins 中查找合适的 chunk。
Large bins用于存储大于等于 512B 或 1024B的空闲chunk,这些chunk使用双向链表的形式按大小顺序排序,分配内存时按最近匹配方式从large bins中分配chunk。
1、Small bins
ptmalloc使用small bins管理空闲小chunk,每个small bin中的chunk的大小与bin的index 有如下关系:
Chunk_size=2 * SIZE_SZ * index
在 SIZE_SZ 为4B的平台上,small bins中的chunk大小是以8B为公差的等差数列,最大的chunk大小为504B,最小的 chunk大小为16B,所以实际共62个bin。
ptmalloc 维护了62个双向环形链表(每个链表都具有链表头节点,加头节点的最大作 用就是便于对链表内节点的统一处理,即简化编程),每一个链表内的各空闲chunk的大小 一致,因此当应用程序需要分配某个字节大小的内存空间时直接在对应的链表内取就可以了, 这样既可以很好的满足应用程序的内存空间申请请求而又不会出现太多的内存碎片。
#define NBINS 128
#define NSMALLBINS 64
#define SMALLBIN_WIDTH MALLOC_ALIGNMENT
#define MIN_LARGE_SIZE (NSMALLBINS * SMALLBIN_WIDTH)
#define in_smallbin_range(sz) \
((unsigned long)(sz) < (unsigned long)MIN_LARGE_SIZE)
#define smallbin_index(sz) \
(SMALLBIN_WIDTH == 16 ? (((unsigned)(sz)) >> 4) : (((unsigned)(sz)) >> 3))2、Large bins
在 SIZE_SZ 为 4B 的平台上,大于等于 512B 的空闲 chunk,或者,在 SIZE_SZ 为 8B 的平 台上,大小大于等于 1024B 的空闲 chunk,由 sorted bins 管理。Large bins 一共包括 63 个 bin, 每个 bin 中的 chunk 大小不是一个固定公差的等差数列,而是分成 6 组 bin,每组 bin 是一个 固定公差的等差数列,每组的 bin 数量依次为 32、16、8、4、2、1,公差依次为 64B、512B、 4096B、32768B、262144B 等。
以 SIZE_SZ 为 4B 的平台为例,第一个 large bin 的起始 chunk 大小为 512B,共 32 个 bin, 公差为 64B,等差数列满足如下关系:
Chunk_size=512 + 64 * index
第二个 large bin 的起始 chunk 大小为第一组 bin 的结束 chunk 大小,满足如下关系:
Chunk_size=512 + 64 * 32 + 512 * index
同理,我们可计算出每个 bin 的起始 chunk 大小和结束 chunk 大小。
#define largebin_index_32(sz) \
(((((unsigned long)(sz)) >> 6) <= 38)? 56 + (((unsigned long)(sz)) >> 6): \
((((unsigned long)(sz)) >> 9) <= 20)? 91 + (((unsigned long)(sz)) >> 9): \
((((unsigned long)(sz)) >> 12) <= 10)? 110 + (((unsigned long)(sz)) >> 12): \
((((unsigned long)(sz)) >> 15) <= 4)? 119 + (((unsigned long)(sz)) >> 15): \
((((unsigned long)(sz)) >> 18) <= 2)? 124 + (((unsigned long)(sz)) >> 18): \ 126)
#define largebin_index_64(sz) \
(((((unsigned long)(sz)) >> 6) <= 48)? 48 + (((unsigned long)(sz)) >> 6): \
(((unsigned long)(sz)) >> 9) <= 20)? 91 + (((unsigned long)(sz)) >> 9): \
((((unsigned long)(sz)) >> 12) <= 10)? 110 + (((unsigned long)(sz)) >> 12): \
((((unsigned long)(sz)) >> 15) <= 4)? 119 + (((unsigned long)(sz)) >> 15): \
((((unsigned long)(sz)) >> 18) <= 2)? 124 + (((unsigned long)(sz)) >> 18): \ 126)
#define largebin_index(sz) \
(SIZE_SZ == 8 ? largebin_index_64 (sz) : largebin_index_32 (sz))
#define bin_index(sz) \
((in_smallbin_range(sz)) ? smallbin_index(sz) : largebin_index(sz))宏 bin_index(sz)根据所需内存大小计算出所需 bin 的 index,如果所需内存大小属于 small bins 的大小范围,调用 smallbin_index(sz),否则调用 largebin_index(sz))。
3、Unsorted bin
Unsorted bin 可以看作是 small bins 和 large bins 的 cache,只有一个 unsorted bin,以双 向链表管理空闲 chunk,空闲 chunk 不排序,所有的 chunk 在回收时都要先放到 unsorted bin 41 中,分配时,如果在 unsorted bin 中没有合适的 chunk,就会把 unsorted bin 中的所有 chunk 分别加入到所属的 bin 中,然后再在 bin 中分配合适的 chunk。Bins 数组中的元素 bin[1]用于 存储 unsorted bin 的 chunk 链表头。
#define unsorted_chunks(M) (bin_at(M, 1))
#define initial_top(M) (unsorted_chunks(M))4、Fast bins
Fast bins主要是用于提高小内存的分配效率,默认情况下,对于 SIZE_SZ 为 4B 的平台,小于 64B 的 chunk 分配请求,对于 SIZE_SZ 为 8B 的平台,小于 128B 的 chunk 分配请求,首先会查找 fast bins 中是否有所需大小的 chunk 存在(精确匹配),如果存在,就直接返回。
Fast bins 可以看着是 small bins 的一小部分 cache,默认情况下,fast bins 只 cache 了 small bins 的前 7 个大小的空闲 chunk,也就是说,对于 SIZE_SZ 为 4B 的平台,fast bins 有 7 个 chunk 空闲链表(bin),每个 bin 的 chunk 大小依次为 16B,24B,32B,40B,48B,56B,64B。

当用户释放一块不大于max_fast(默认值64B)的chunk的时候,会默认会被放到fast bins上。当需要给用户分配的 chunk 小于或等于 max_fast 时,malloc 首先会到fast bins上寻找是否有合适的chunk。(一定大小内的chunk无论是分配还是释放,都会先在fast bin中过一遍) 除非特定情况,两个毗连的空闲chunk并不会被合并成一个空闲chunk。不合并可能会导致碎片化问题,但是却可以大大加速释放的过程! 分配时,binlist中被检索的第一个个chunk将被摘除并返回给用户。free掉的chunk将被添加在索引到的binlist的前端。
2.2.3 三种特殊的chunk
并不是所有chunk都按照上面的方式来组织,有三种列外情况。top chunk,mmaped chunk 和last remainder chunk。
1、top chunk
top chunk相当于分配区的顶部空闲内存(可能就是由brk调用控制的brk指针),当bins上都不能满足内存分配要求的时候,就会来top chunk上分配。 当top chunk大小比用户所请求大小还大的时候,top chunk会分为两个部分:User chunk(用户请求大小)和Remainder chunk(剩余大小)。其中Remainder chunk成为新的top chunk。 当top chunk大小小于用户所请求的大小时,top chunk就通过sbrk(main arena)或mmap(thread arena)系统调用来扩容。
2、mmaped chunk
当分配的内存非常大(大于分配阀值,默认128K)的时候,需要被mmap映射,则会放到mmaped chunk上,当释放mmaped chunk上的内存的时候会直接交还给操作系统。 (chunk中的M标志位置1)
3、last remainder chunk
Last remainder chunk是另外一种特殊的chunk,就像top chunk和mmaped chunk一样,不会在任何bins中找到这种chunk。当需要分配一个small chunk,但在small bins中找不到合适的chunk,如果last remainder chunk的大小大于所需要的small chunk大小,last remainder chunk被分裂成两个chunk,其中一个chunk返回给用户,另一个chunk变成新的last remainder chunk。
2.3 ptmalloc的缺点
总的来看ptmalloc的主要问题其实是内存浪费、内存碎片、以及加锁导致的性能问题:
1、如果后分配的内存先释放,无法及时归还系统。因为 ptmalloc 收缩内存是从 top chunk 开始,如果与 top chunk 相邻的 chunk 不能释放, top chunk 以下的 chunk 都无法释放。
2、内存从thread的arena中分配,内存不能从一个arena移动到另一个arena,就是说如果多线程使用内存不均衡,容易导致内存的浪费。比如说线程1使用了300M内存,完成任务后glibc没有释放给操作系统,线程2开始创建了一个新的arena,但是线程1的300M却不能用了。
3、每个chunk至少8字节的开销。
4、多线程锁开销大, 需要避免多线程频繁分配释放。
不定期分配长生命周期的内存容易造成内存碎片,不利于回收。 64位系统最好分配32M以上内存,这是使用mmap的阈值。
5、加锁耗时,无论当前分区有无耗时,在内存分配和释放时,会首先加锁。
3 TCMalloc
TCMalloc全称是Thread-Caching Malloc,是Google 开发的内存分配器,在不少项目中都有使用,例如在 Golang 中就使用了类似的算法进行内存分配。它具有现代化内存分配器的基本特征:对抗内存碎片、在多核处理器能够 scale。TCMalloc相比glibc 2.3而言内存分配更快;对于多线程程序而言,减少了锁机制,对于小对象而言,可以说没有锁的操作,对于大的对象而言的更加高效的自旋锁(spinlock);对小对象的处理空间效率更好。
3.1 TCMalloc内存管理
整体的TCMalloc的大体分为三个部分:
1、Front-end,主要维护线程cache,用来为应用提供快速分配以及释放内存的需求。
2、Middle-end,主要负责为font-end 中的thread-cache 填充内存。
3、back-end,负责从os直接获取内存。

3.1.1 Front-end
Front-end 提供了Cache ,能够缓存一部分内存用来分配给应用 ,也能够持有应用释放的内存。这个Cache 作为per-cpu/per-thread 存在,其同一时刻只能由一个线程访问,所以本身不需要任何的锁,这也是多线程下内存分配释放高效的原因。
如果Front-end 持有的内存大小足够,其能够满足应用线程任何内存需求。如果持有的内存为空了,那它会从 middle-end 组件请求一批内存页进行填充。
如果用户请求的内存大小超过了front-end 本身能缓存的大小(大内存需求),或者middle-end 缓存的内存页也被用尽了,那这个时候会直接让从back-end分配内存给用户。
3.1.2 Middle-end
Middle-end,这一部分是TCMalloc的设计核心,主要提升多线程内存分配性能并有效降低内存碎片。它负责:
1、在Front-end部分的thread-cache内存不够的时候进行填充
2、将未使用的内存释放还给给操作系统。
3、可以将一个thread-cache的内存移动到另一个thread-cache,从而降低内存碎片,提升内存使用效率。
3.1.3 Back-end
tcmalloc 的back-end 主要有三个工作线程:
1、管理未使用的大块内存区域;
2、负责从 os 中获取内存,来满足其他组件的内存需求
3、负责将其他组件不需要返回的内存,还给os
还有两个后端组件:
1、legacy pageheap. 管理tcmalloc 的pages
2、管理大页内存的 pageheap。用来提升应用程序大页内存的申请需求,降低TLB的miss。
3.2 TCMalloc的分配与回收
TCMalloc的基本思想是,前面的层次分配内存失败,则从下一层分配一批补充上来;前面的层次释放了过多的内存,则回收一批到下一层次。
根据TCMalloc的实现架构,将内存管理单元整体分成了三种结构:
1、PageHeap-内存管理单位:span(连续的page的内存)
2、CentralCache-内存管理单位:object(由span切成的小块,同一个span切出来的object都是相同的规格)
3、ThreadCache-内存管理单位:class(由span切成的小块),线程私有的缓存,理想情况下,每个线程的内存需求都在自己的ThreadCache中完成,线程之间不需要竞争,非常高效。

3.2.1 分配
1)小块内存(<256KB)
ThreadCache:先尝试在list_[class]的FreeList分配。
CentralCache:找到对应class的tc_slots链表,从链表中分配 -> 从nonempty_链表分配(尽量分配batch_size个object)。
HeadPage:伙伴系统对应的npages的span链表 (normal->returned)-> 更大的npages的span链表,拆小。
kernel:申请若干个page的内存(可能大于npages)。
2)大块内存(>256KB)
HeadPage:伙伴系统对应的npages的span链表 (normal->returned)-> 更大的npages的span链表,拆小。
kernel:申请若干个page的内存(可能大于npages)。
3.2.2 回收
与申请流程类似
1)ThreadCache => CentralCache
ThreadCache容量限额:
a、为每一个ThreadCache初始化一个比较小的限额,然后每当ThreadCache由于cache超限而触发object到CentralCache的回收时,就增大限额。
b、预设所有ThreadCache的总容量,一个ThreadCache容量不够时,从其他ThreadCache收刮(轮询)。
c、每个ThreadCache也有最大最小值限制,不能无限增大限额。
d、每个ThreadCache超过限额时,对其每个FreeList回收。
单个FreeList的限额:
a、慢启动。初始长度限制为1,限额1~batch_size之间为慢启动,每次限额+1。
b、超过batch_size,限额按照batch_size整数倍扩展。
c、FreeList限额超限,直接回收batch_size个object。
2)CentralCache => PageHeap
只要一个span里面的object都空闲了,就将它回收到PageHeap。
3)PageHead中的normal => returned
a、每当PageHeap回收到N个page的span时(这个过程中可能伴随着相当数目的span分配),触发一次normal到returned的回收,只回收一个span。
b、这个N值初始化为1G内存的page数,每次回收span到returned链之后,可能还会增加N值,但是最大不超过4G。
c、触发回收的过程,每次进来轮询伙伴系统中的一个normal链表,将链尾的span回收即可。
3.3 TCMalloc的使用
3.3.1 库的下载
下载路径如下:
Perftools:https://code.google.com/p/google-perftools/
gperftools:http://code.google.com/p/gperftools/downloads/list
https://github.com/gperftools/gperftools(下载release版本)
3.3.2 TCMalloc的生效
TCMalloc在libc_override.h中实现了覆盖机制,在使用指定-ltcmalloc链接后,应用程序对malloc、free、new、delete等调用就从默认glibc中的函数调用变为TCMalloc库中相应的函数调用。
1、动态库方式
通过-ltcmalloc或-ltcmalloc_minimal将TCMalloc链接到应用程序。
通过LD_PRELOAD预载入TCMalloc库可以不用重新编译应用程序即可使用TCMalloc。
LD_PRELOAD="/usr/lib/libtcmalloc.so"
2、静态库方式
在编译选项的最后加入/usr/local/lib/libtcmalloc_minimal.a链接静态库。
3.3.3 TCMalloc排查内存问题
Linux的项目中使用TCMalloc的主要目的在于堆内存统计与内存问题的排查,此内容可见本人的另一篇博客:
参考文献:
Glibc-Malloc和TCMalloc 的基本设计原理 及 Glibc-malloc,Jemalloc,TCMalloc性能差异_jemalloc 和 malloc-CSDN博客
TCMalloc(Thread-Caching malloc) 基本设计原理-CSDN博客
https://zhuanlan.zhihu.com/p/513463384
linux 内存管理(四)malloc--mmap--brk
《Glibc 内存管理 Ptmalloc2 源代码分析 》华庭(庄明强) 2011/4/17















 274
274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









