






建议先看我写的 Pandas快速入门 和 Pandas进阶 (上) ,这样方便理解接下来的内容
入门篇:
Python数据分析 Pandas进阶(上) 这篇就够了-CSDN博客![]() https://blog.csdn.net/qq_69183322/article/details/135913014
https://blog.csdn.net/qq_69183322/article/details/135913014
一、数据分组统计
1.1使用groupby函数进行数据分组统计
示例:
import pandas as pd
# 创建一个简单的数据框
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35, 30, 35, 40],
'Salary': [50000, 60000, 70000, 60000, 70000, 80000]
}
df = pd.DataFrame(data)
# 使用 Name 列对数据进行分组
grouped = df.groupby('Name')
# 输出分组后的数据框
print(grouped.sum())运行结果:
Age Salary
Name
Alice 55 110000
Bob 65 130000
Charlie 75 150000
1.2使用Series对象和字典进行分组统计
示例:
import pandas as pd
# 创建一个简单的Series对象
data = pd.Series([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
# 使用自定义的键进行分组
group_keys = data.apply(lambda x: x % 2 == 0)
# 使用groupby方法按照自定义键进行分组
grouped = data.groupby(group_keys)
# 使用agg方法对每个组执行统计操作
group_stats = grouped.agg(['mean', 'sum'])
# 打印分组统计结果
print(group_stats)运行结果:
mean sum
False 5.0 25
True 6.0 30二、数据移位
2.1使用shift函数
示例1:
import pandas as pd
# 创建一个简单的Series对象
s = pd.Series([1, 2, 3, 4, 5])
# 将Series中的元素向后移动一位
s_shifted = s.shift(1)
print(s_shifted)运行结果:
0 NaN
1 1.0
2 2.0
3 3.0
4 4.0
dtype: float64
示例2:
import pandas as pd
# 创建一个简单的DataFrame对象
df = pd.DataFrame({
'A': [1, 2, 3, 4, 5],
'B': [5, 4, 3, 2, 1]
})
# 将列 'A' 中的元素向后移动一位,将列 'B' 中的元素向前移动一位
df['A'] = df['A'].shift(1)
df['B'] = df['B'].shift(-1)
print(df)运行结果:
A B
0 NaN 4.0
1 1.0 3.0
2 2.0 2.0
3 3.0 1.0
4 4.0 NaN
三、数据转换
3.1split方法
示例:
import pandas as pd
data = {'name': ['Tom Hanks', 'Jack Black', 'Will Smith']}
df = pd.DataFrame(data)
print(df)
df[['firstname', 'lastname']] = df['name'].str.split(' ', expand=True)
print(df)运行结果:
name
0 Tom Hanks
1 Jack Black
2 Will Smith
name firstname lastname
0 Tom Hanks Tom Hanks
1 Jack Black Jack Black
2 Will Smith Will Smith
2.DataFrame转换为字典
使用to_dict方法
示例:
import pandas as pd
data = {'name': ['Alice', 'Bob', 'Charlie'], 'age': [25, 30, 35]}
df = pd.DataFrame(data)
print(df)
dict_data = df.to_dict(orient='list')
print(dict_data)运行结果:
name age
0 Alice 25
1 Bob 30
2 Charlie 35
{'name': ['Alice', 'Bob', 'Charlie'], 'age': [25, 30, 35]}
3.DataFrame转换为列表
使用tolist方法
示例:
import pandas as pd
# 创建一个简单的DataFrame
data = {
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35]
}
df = pd.DataFrame(data)
# 使用values属性将DataFrame转换为NumPy数组
# .values是一个将DataFrame或Series转化为numpy数组的快捷方式
array_data = df.values
print("转换为NumPy数组:")
print(array_data)
print()
# 使用tolist方法将NumPy数组转换为列表
# tolist()方法用于将numpy数组转化为Python的列表
list_data = array_data.tolist()
print("转换为列表:")
print(list_data)运行结果:
转换为NumPy数组:
[['Alice' 25]
['Bob' 30]
['Charlie' 35]]转换为列表:
[['Alice', 25], ['Bob', 30], ['Charlie', 35]]
4.DataFrame转换为元组
使用元组函数tuple转换为元组
示例:
import pandas as pd
# 创建一个简单的DataFrame
df = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]
})
tuples = [tuple(x) for x in df.values]
for t in tuples:
print(t)运行结果:
(1, 4, 7)
(2, 5, 8)
(3, 6, 9)
5.Excel转换为HTML网页格式
使用to_html方法将Excel转换为HTML格式的功能
示例:
# 导入必要的库
import pandas as pd
from IPython.display import HTML
# 读取Excel文件
# 假设你的Excel文件名为"data.xlsx"
df = pd.read_excel("Excel/data.xlsx")
# 创建一个HTML表格来显示数据
html_table = df.to_html(index=False, table_id="my_table")
# 这将直接在Jupyter Notebook中显示HTML内容
HTML(html_table)Jupyter的运行结果:
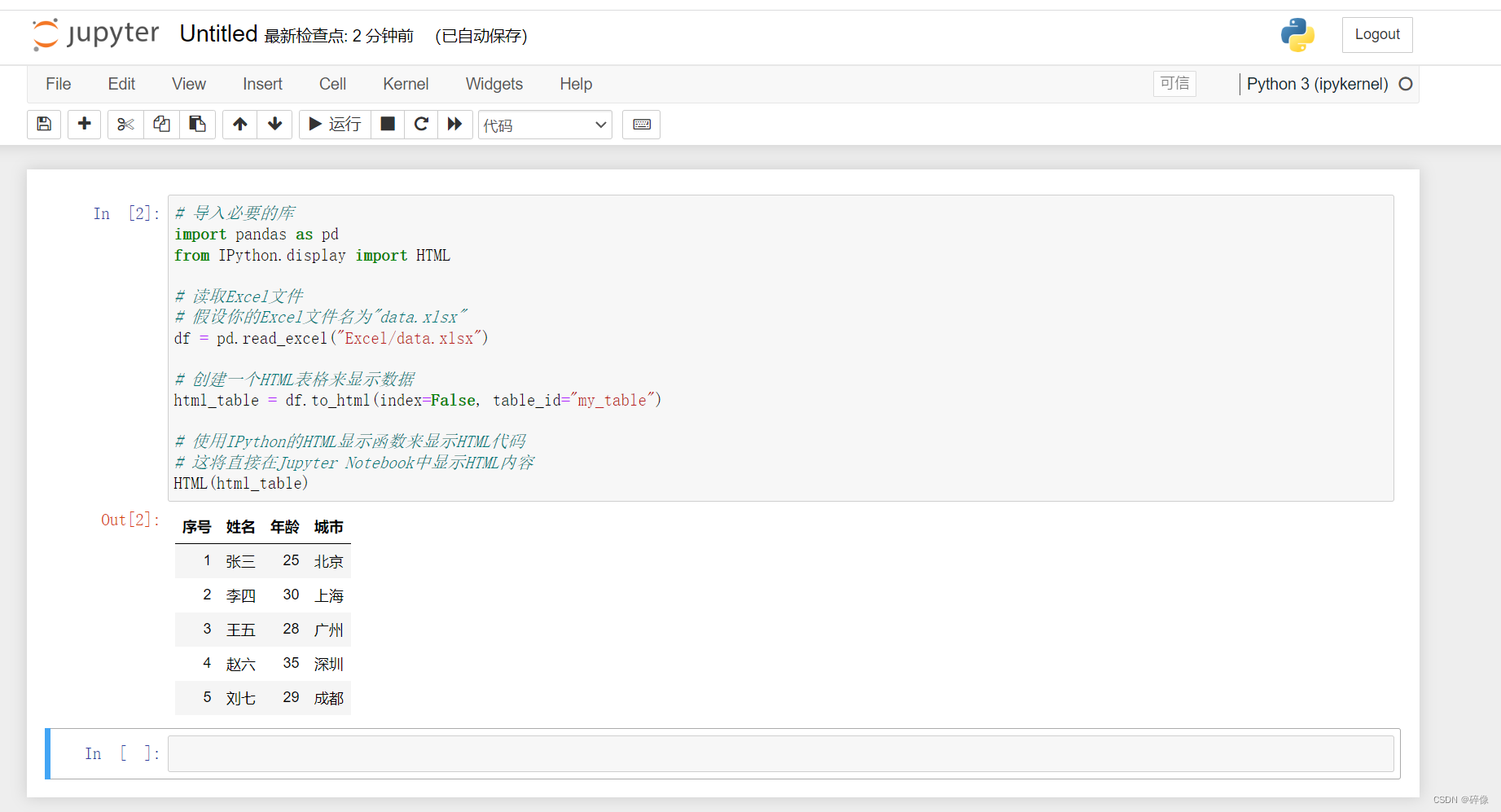
补充:Jupyter的基本使用:
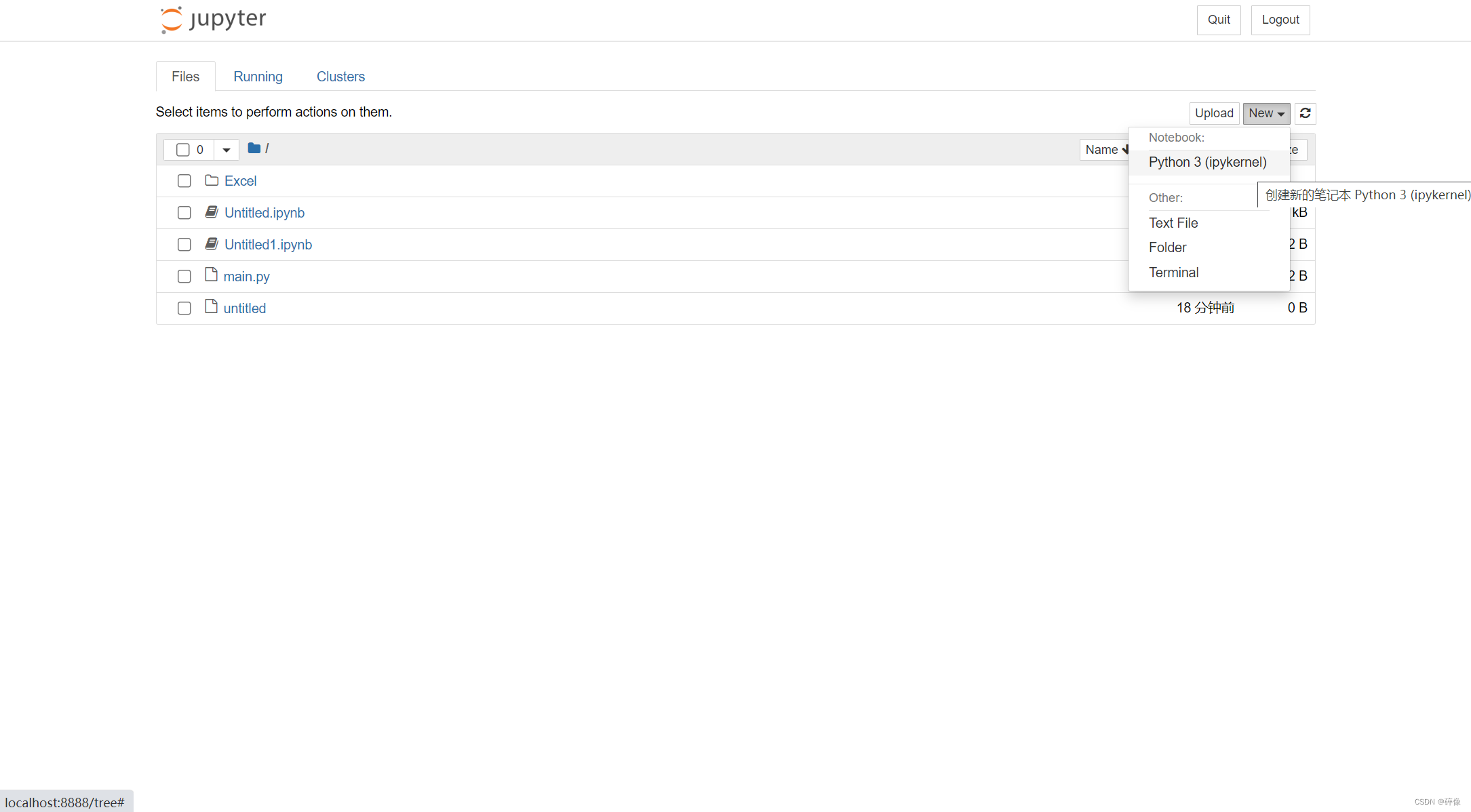
首先安装
pip install jupyter
终端输入启动 jupyter:
jupyter notebook
此时弹出网址:http://localhost:8888/tree
的网站点击New -> Python3
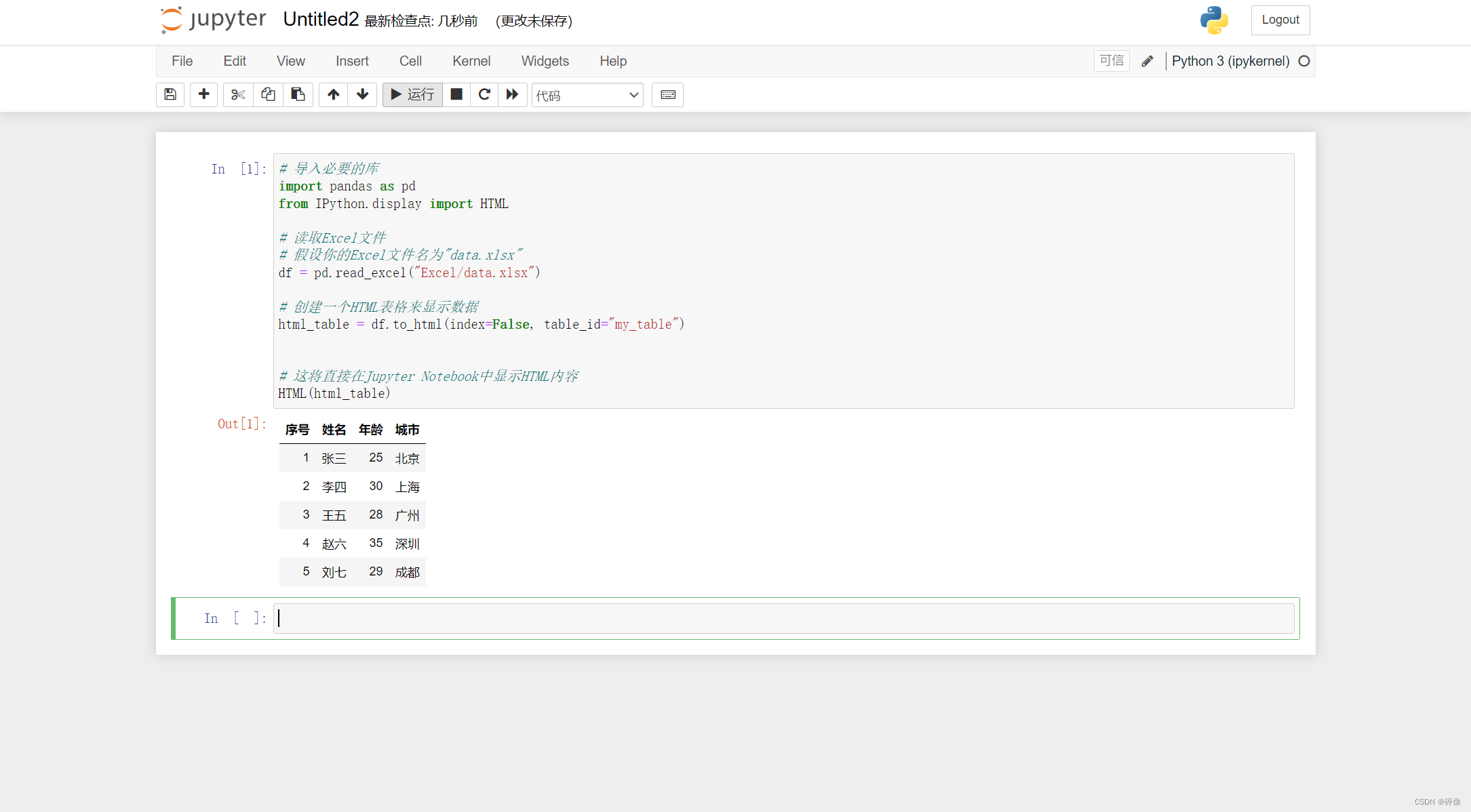
将代码复制进框中,然后点击运行则显示实现的效果
6.行列转换
Stack、Unstack和Pivot都是用于数据转换的方法,但它们在操作方式和应用场景上存在一些区别。
Stack主要用于数据的重新组合和排序,它将列转换为行,将原本的一列数据放在一行上。这个操作通常用于数据的重塑和整理,例如在时间序列分析中将时间轴上的数据按照需要重新排列。
Unstack则是将行转换为列,将原本的一行数据放在一个列上。这个操作通常用于数据的透视分析和宽格式数据的转换。通过Unstack,可以将分组数据转换成宽格式数据,使得数据的维度更加清晰,便于分析。
Pivot则是用于创建透视表,实现行列的重新排列和聚合计算。与Stack和Unstack不同,Pivot需要指定相应的列分别作为行、列索引以及值。通过Pivot,可以将数据的行和列进行转换,同时还可以进行聚合计算,从而方便地分析数据的分布和关系
(1) stack方法
示例:
import pandas as pd
# 创建一个DataFrame
data = {'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
df = pd.DataFrame(data)
# 使用stack方法将列转换为行
stacked_df = df.stack()
# 打印转换后的DataFrame
print(stacked_df)运行结果:
0 A 1
B 4
C 7
1 A 2
B 5
C 8
2 A 3
B 6
C 9
dtype: int64
(2) unstack方法
示例:
import pandas as pd
# 创建一个DataFrame
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]})
# 使用unstack方法进行行列转换
transposed_df = df.unstack()
# 打印转置后的DataFrame
print(transposed_df)运行结果:
A 0 1
1 2
2 3
B 0 4
1 5
2 6
C 0 7
1 8
2 9
dtype: int64
(3) pivot方法
示例:
import pandas as pd
# 创建一个DataFrame
data = {'A': ['foo', 'foo', 'foo', 'bar', 'bar', 'bar'],
'B': ['one', 'one', 'two', 'two', 'one', 'one'],
'C': [1, 2, 3, 4, 5, 6],
'D': [2.5, 3.5, 4.5, 5.5, 6.5, 7.5]}
df = pd.DataFrame(data)
# 使用pivot方法创建透视表
pivot_table = df.pivot_table(index='A', columns='B', values=['C', 'D'], aggfunc='sum')
# 打印透视表
print(pivot_table)运行结果:
C D
B one two one two
A
bar 11 4 14.0 5.5
foo 3 3 6.0 4.5
















 876
876











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









