






 文章介绍了在股票购买数据集上使用K-means、AgglomerativeClustering和DBSCAN聚类算法的过程,包括数据预处理、特征缩放和选择最佳聚类数或参数的方法,通过轮廓系数评估模型性能。
文章介绍了在股票购买数据集上使用K-means、AgglomerativeClustering和DBSCAN聚类算法的过程,包括数据预处理、特征缩放和选择最佳聚类数或参数的方法,通过轮廓系数评估模型性能。
一.K-means模型
模型构建的读取数据,数据预处理与预测模型的决策树解析相同,在这里不再赘述。
1.导入项目所需要的包
1.import pandas as pd
2.import matplotlib.pyplot as plt
3.from sklearn.preprocessing import LabelEncoder
4.import numpy as np
5.from sklearn.cluster import KMeans, AgglomerativeClustering, DBSCAN
6.from sklearn.metrics import adjusted_rand_score, silhouette_score2.读取数据
1.df = pd.read_excel('C:/Users/DELL/Desktop/数据集 (1)/股票购买数据集.xlsx')3.数据预处理
1.le = LabelEncoder()
2.df['job'] = le.fit_transform(df['job'])
3.df['marital'] = le.fit_transform(df['marital'])
4.df['education'] = le.fit_transform(df['education'])
5.df['bankrupt'] = le.fit_transform(df['bankrupt'])
6.df['mortgage'] = le.fit_transform(df['mortgage'])
7.df['loan'] = le.fit_transform(df['loan'])
8.df['contact'] = le.fit_transform(df['contact'])
9.df['month'] = le.fit_transform(df['month'])
10.df['poutcome'] = le.fit_transform(df['poutcome'])
11.df['purchased'] = le.fit_transform(df['purchased'])
12.df.dropna(inplace=True)
13.X = df.iloc[:, :-1]
14.y = df.iloc[:, -1]
15.le = LabelEncoder()
16.y = le.fit_transform(y)4.对数据集中的数值变量进行特征缩放
首先,从scikit-learn库中导入StandardScaler类。然后,将需要进行标准化的数值变量的列名保存在num_cols列表中。接着,创建一个StandardScaler的实例对象scaler。最后,调用scaler的fit_transform方法,并传递包含需要进行标准化的数值变量的列的数据框df[num_cols]作为其输入参数。该方法对数据进行训练(fit)并转换(transform),返回标准化后的数据,最终将其赋值给df[num_cols],完成标准化操作。
1.from sklearn.preprocessing import StandardScaler
2.scaler = StandardScaler()
3.num_cols = ['age','duration','campaign','pdays','previous','balance']
4.df[num_cols] = scaler.fit_transform(df[num_cols])5.使用轮廓系数方法来寻找最佳的簇数
首先,创建空列表 wcss 和 silhouette_scores,用来分别保存每个聚类数下的 WCSS 和轮廓系数分数。接着,使用一个 for 循环,在下标从 2 开始到 13(不包括13)的范围内,遍历每个聚类数 k。在循环中,创建一个 KMeans 类的实例对象 kmeans,并将其聚类数设为 k。调用该实例对象的 fit 方法,对数据集 df 进行聚类。将聚类后的模型的 WCSS(误差平方和)保存在列表 wcss 中。同时,通过调用轮廓系数函数 silhouette_score,计算模型的轮廓系数分数,并将其保存在另一个列表 silhouette_scores 中。
最后,绘制两张图表。第一张图表使用 plt.plot 函数绘制了聚类数 k 和 WCSS 的关系,并使用 plt.title、plt.xlabel 和 plt.ylabel 函数分别设置图表的标题、x轴标签和y轴标签。第二张图表同理,只是绘制的是聚类数 k 和轮廓系数的关系。通过这两张图表可以视觉化地选择最优的聚类数。
1.wcss = []
2.silhouette_scores = []
3.for k in range(2, 13):
4. kmeans = KMeans(n_clusters=k)
5. kmeans.fit(df)
6. wcss.append(kmeans.inertia_)
7. score = silhouette_score(df, kmeans.labels_)
8. silhouette_scores.append(score)
9.
10.plt.plot(range(2,13), wcss)
11.plt.title('肘部计算法')
12.plt.xlabel('簇数')
13.plt.ylabel('WCSS')
14.plt.show()
15.
16.plt.plot(range(2,13), silhouette_scores)
17.plt.title('轮廓系数法')
18.plt.xlabel('簇数')
19.plt.ylabel('轮廓系数')
20.plt.show()二.cluster模型
模型构建的读取数据,数据预处理,特征缩放与kmeans模型解析相同,在这里不再赘述。
1.导入项目所需要的包
1.import pandas as pd
2.import seaborn as sns
3.import matplotlib.pyplot as plt
4.from sklearn.preprocessing import LabelEncoder
5.from sklearn.cluster import AgglomerativeClustering
6.from sklearn.metrics import silhouette_score2.读取数据
1.df = pd.read_excel('C:/Users/DELL/Desktop/数据集 (1)/股票购买数据集.xlsx')3.数据预处理
1.le = LabelEncoder()
2.df['job'] = le.fit_transform(df['job'])
3.df['marital'] = le.fit_transform(df['marital'])
4.df['education'] = le.fit_transform(df['education'])
5.df['bankrupt'] = le.fit_transform(df['bankrupt'])
6.df['mortgage'] = le.fit_transform(df['mortgage'])
7.df['loan'] = le.fit_transform(df['loan'])
8.df['contact'] = le.fit_transform(df['contact'])
9.df['month'] = le.fit_transform(df['month'])
10.df['poutcome'] = le.fit_transform(df['poutcome'])
11.df['purchased'] = le.fit_transform(df['purchased'])
12.df.dropna(inplace=True)
13.X = df.iloc[:, :-1]
14.y = df.iloc[:, -1]
15.le = LabelEncoder()
16.y = le.fit_transform(y)4.对数据集中的数值变量进行特征缩放
1.from sklearn.preprocessing import StandardScaler
2.scaler = StandardScaler()
3.num_cols = ['age','duration','campaign','pdays','previous','balance']
4.df[num_cols] = scaler.fit_transform(df[num_cols])5.使用轮廓系数方法来寻找最佳的簇数
首先,创建空列表 silhouette_scores,用来保存每个聚类数下的轮廓系数分数。接着,使用一个 for 循环,在下标从 2 开始到 13(不包括13)的范围内,遍历每个聚类数 k。在循环中,创建一个 AgglomerativeClustering 类的实例对象 clusterer,并将其聚类数设为 k。调用该实例对象的 fit_predict 方法,对数据集 df 进行聚类,并将聚类后的标签保存在 cluster_labels 中。然后,通过调用轮廓系数函数 silhouette_score,计算模型的轮廓系数分数 silhouette_avg,该值即为该聚类数 k 对应的轮廓系数分数。将该分数保存在列表 silhouette_scores 中。
最后,绘制一张图表。使用 plt.plot 函数绘制了聚类数 k 和轮廓系数的关系,并使用 plt.title、plt.xlabel 和 plt.ylabel 函数分别设置图表的标题、x轴标签和y轴标签。通过这张图表可以视觉化地选择最优的聚类数。
1.silhouette_scores = []
2.for k in range(2, 13):
3. clusterer = AgglomerativeClustering(n_clusters=k)
4. cluster_labels = clusterer.fit_predict(df)
5. silhouette_avg = silhouette_score(df, cluster_labels)
6. silhouette_scores.append(silhouette_avg)
7.
8.plt.plot(range(2,13), silhouette_scores)
9.plt.title('轮廓系数法')
10.plt.xlabel('聚类数')
11.plt.ylabel('轮廓系数')
12.plt.show()三.DBSCAN模型
模型构建的导入包,读取数据,数据预处理,特征缩放与kmeans模型解析相同,在这里不再赘述。不同地方在于:
使用轮廓系数方法来寻找最佳EPS值
DBSCAN算法中eps参数的值从0.1到2被等间隔地取了20个数,对每一个参数值,都进行了一次聚类并计算了对应的轮廓系数。如果聚类结果中聚类数量超过了1,就使用sklearn的silhouette_score函数计算轮廓系数,否则将轮廓系数设置为-1。最后,使用matplotlib将eps与轮廓系数绘制在一张图表上。然后通过选择合得宜的eps参数,来进行DBSCAN聚类,并用不同颜色的散点图展现聚类效果。
1.silhouette_scores = []
2.epsilons = np.linspace(0.1, 2, num=20)
3.for eps in epsilons:
4. dbscan = DBSCAN(eps=eps, min_samples=5)
5. dbscan.fit(df)
6. if len(set(dbscan.labels_)) > 1:
7. score = silhouette_score(df, dbscan.labels_)
8. silhouette_scores.append(score)
9. else:
10. silhouette_scores.append(-1)
11.
12.plt.plot(epsilons, silhouette_scores)
13.plt.title('DBSCAN聚类的轮廓系数')
14.plt.xlabel('EPS')
15.plt.ylabel('轮廓系数')
16.plt.show()
17.dbscan = DBSCAN(eps=0.75, min_samples=5)
18.dbscan.fit(df)
19.colors = ['blue', 'red', 'green', 'orange', 'black', 'purple', 'brown', 'pink']
20.cluster_labels = dbscan.labels_
21.unique_labels = set(cluster_labels)
22.fig, ax = plt.subplots(figsize=(10,7))
23.for i, label in enumerate(unique_labels):
24. df_subset = df[cluster_labels==label]
25. ax.scatter(df_subset.iloc[:, 0], df_subset.iloc[:, 1], c=colors[i], label='Cluster {}'.format(label), alpha=0.5)
26.ax.legend()
27.plt.xlabel('age')
28.plt.ylabel('duration')
29.plt.title('DBSCAN聚类结果')
30.plt.show()四.对比不同聚类算法
K-Means算法是一种基于距离的聚类算法,通过计算每个数据点与聚类中心的距离,将数据点分配到距离最近的聚类中心,不断迭代更新聚类中心直到收敛。K-Means算法适用于聚类的簇数已知、簇形较为规则和数据分布较为均匀的情况。
Cluster算法是一种基于密度的聚类算法,将数据点分配到高密度区域,从而划分区域边界,不需要预先指定簇数。Cluster算法适用于聚类的簇数未知、簇形不规则,以及存在噪声点的情况。
DBSCAN算法也是一种基于密度的聚类算法,通过定义邻域内数据点的密度来划分数据点属于核心点、边界点或噪声点,从而聚集有着足够密度的核心点。DBSCAN算法适用于聚类的簇数未知、簇形不规则以及存在噪声点的情况。
总之,K-Means算法适用于聚类的簇数已知、簇形较为规则和数据分布较为均匀的情况;Cluster算法和DBSCAN算法适用于聚类的簇数未知、簇形不规则,其中Cluster算法需要满足密度的盖区间,而DBSCAN算法需要定义密度半径,并且不同的算法有着不同的对噪声点的处理方式。
1.import pandas as pd
2.from sklearn.preprocessing import LabelEncoder
3.import numpy as np
4.from sklearn.cluster import KMeans, AgglomerativeClustering, DBSCAN
5.from sklearn.metrics import adjusted_rand_score, silhouette_score
6.# 读取数据
7.df = pd.read_excel('C:/Users/DELL/Desktop/数据集 (1)/股票购买数据集.xlsx')
8.le = LabelEncoder()
9.df['job'] = le.fit_transform(df['job'])
10.df['marital'] = le.fit_transform(df['marital'])
11.df['education'] = le.fit_transform(df['education'])
12.df['bankrupt'] = le.fit_transform(df['bankrupt'])
13.df['mortgage'] = le.fit_transform(df['mortgage'])
14.df['loan'] = le.fit_transform(df['loan'])
15.df['contact'] = le.fit_transform(df['contact'])
16.df['month'] = le.fit_transform(df['month'])
17.df['poutcome'] = le.fit_transform(df['poutcome'])
18.df['purchased'] = le.fit_transform(df['purchased'])
19.# 数据预处理
20.df.dropna(inplace=True)
21.X = df.iloc[:, :-1]
22.y = df.iloc[:, -1]
23.le = LabelEncoder()
24.y = le.fit_transform(y)
25.# 数据标准化
26.X = (X - np.mean(X, axis=0)) / np.std(X, axis=0)
27.# 聚类模型
28.models = {
29. 'KMeans': KMeans(n_clusters=2, random_state=42),
30. 'AgglomerativeClustering': AgglomerativeClustering(n_clusters=2),
31. 'DBSCAN': DBSCAN(eps=3, min_samples=2)
32.}
33.# 聚类分析
34.for name, model in models.items():
35. y_pred = model.fit_predict(X)
36. print("{} ARI: {:.3f}, Silhouette Score: {:.3f}".format(name, adjusted_rand_score(y, y_pred),
37. silhouette_score(X, y_pred)))
38.以上代码使用了K-means、层次聚类和DBSCAN三种算法进行客户聚类分析,并输出了ARI和轮廓系数指标。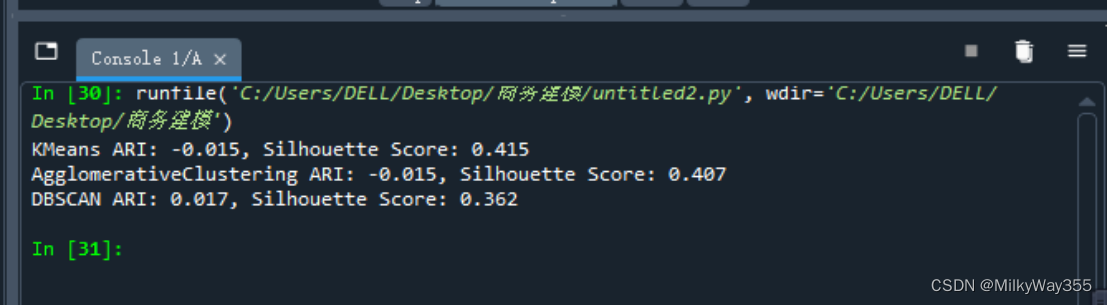
通过运行结果可以看出kmeans的轮廓系数指标最高为0.415,拟合效果最好
DBSCAN模型的轮廓系数最低为0.362,拟合效果最差。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









