






一.决策树算法
根据以下代码,可以得到预测客户购买股票意图的决策树模型,并进行可视化分析,可以分析出最重要的特征和决策过程,以便进行进一步的分析和预测。
1.导入项目运行所需要的包
1.import pandas as pd
2.from sklearn.tree import DecisionTreeClassifier
3.import matplotlib.pyplot as plt
4.from sklearn.tree import plot_tree
5.from sklearn.model_selection import train_test_split
6.from sklearn.preprocessing import LabelEncoder
7.from sklearn.ensemble import RandomForestClassifier
8.from sklearn.svm import SVC
9.from sklearn.metrics import accuracy_score, precision_score, recall_score2.读取数据文件
1. df = pd.read_excel('C:/Users/DELL/Desktop/数据集 (1)/股票购买数据集.xlsx')3.数据预处理
使用LabelEncoder对数据进行标签编码的代码片段,目的是将分类变量转换为数字格式,以便于使用机器学习算法进行训练和预测。首先,将job、marital、education、bankrupt、mortgage、loan、contact、month、poutcome这些分类变量分别进行标签编码。LabelEncoder() 是sklearn中的一个函数,可以将每个变量的不同值映射为整数。
接着,通过dropna函数,删除数据中包含缺失值的行。然后将X和y分别定义为DataFrame中除最后一列外的所有列和最后一列。y列是我们想要预测的变量,将其用le.fit_transform(y)编码为数字。最终,X和y将用于训练一个分类模型。
1.le = LabelEncoder()
2.df['job'] = le.fit_transform(df['job'])
3.df['marital'] = le.fit_transform(df['marital'])
4.df['education'] = le.fit_transform(df['education'])
5.df['bankrupt'] = le.fit_transform(df['bankrupt'])
6.df['mortgage'] = le.fit_transform(df['mortgage'])
7.df['loan'] = le.fit_transform(df['loan'])
8.df['contact'] = le.fit_transform(df['contact'])
9.df['month'] = le.fit_transform(df['month'])
10.df['poutcome'] = le.fit_transform(df['poutcome'])
11.df['purchased'] = le.fit_transform(df['purchased'])
12.df.dropna(inplace=True)
13.X = df.iloc[:, :-1]
14.y = df.iloc[:, -1]
15.le = LabelEncoder()
16.y = le.fit_transform(y)4.数据划分训练集和测试集
将数据集X和y分别拆分成X_train,X_test,y_train和y_test四个数据集,其中测试集的比例为20%(test_size=0.2),随机种子为42(random_state=42)。最终,X_train和y_train将用于训练模型,而X_test和y_test将用于评估模型的性能。
1.X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42
5.训练和测试决策树模型
首先,将DecisionTreeClassifier类实例化一个分类器clf_dt,传递参数random_state=42,以便于结果具有可重复性。然后使用训练数据集进行模型拟合 clf_dt.fit(X_train,y_train)。接着,使用测试数据集X_test进行预测y_pred_dt,将预测结果保存在y_pred_dt中。最后,使用accuracy_score函数来计算分类器在测试集上的准确率acc_dt,将其打印输出,以检查模型的性能表现。
1.clf_dt = DecisionTreeClassifier(random_state=42)
2.clf_dt.fit(X_train, y_train)
3.y_pred_dt = clf_dt.predict(X_test)
4.acc_dt = accuracy_score(y_test, y_pred_dt)
5.print("Decision Tree Classifier Accuracy:", acc_dt)6.可视化结果
首先使用matplotlib设置一个图形画布大小为(30,15),以适配决策树的展示。然后调用plot_tree函数,传递参数clf_dt、feature_names和class_names,其中clf_dt是上一步中训练得到的决策树分类器,feature_names是数据集特征名称列表,class_names是数据集标签名称列表。plot_tree函数会将决策树模型可视化输出,其中每个节点代表一个决策或者一个特征分裂点,用不同颜色表示不同的类别,以及给出一些重要的统计信息,如样本数、熵等。最后通过plt.show()函数将可视化结果展示在画布中。
1.plt.figure(figsize=(30,15))
2.plot_tree(clf_dt, filled=True, feature_names=X.columns, class_names=["No", "Yes"])
3.plt.show()
二.随机森林算法
前四个步骤与决策树算法实现过程前四个步骤一样,在这里就不做过多的解释了。
1.导入项目运行所需要的包
1.import pandas as pd
2.from sklearn.tree import DecisionTreeClassifier
3.import matplotlib.pyplot as plt
4.from sklearn.tree import plot_tree
5.from sklearn.model_selection import train_test_split
6.from sklearn.preprocessing import LabelEncoder
7.from sklearn.ensemble import RandomForestClassifier
8.from sklearn.svm import SVC
9.from sklearn.metrics import accuracy_score, precision_score, recall_score2.读取数据文件
1.df = pd.read_excel('C:/Users/DELL/Desktop/数据集 (1)/股票购买数据集.xlsx')3.数据预处理
1.le = LabelEncoder()
2.df['job'] = le.fit_transform(df['job'])
3.df['marital'] = le.fit_transform(df['marital'])
4.df['education'] = le.fit_transform(df['education'])
5.df['bankrupt'] = le.fit_transform(df['bankrupt'])
6.df['mortgage'] = le.fit_transform(df['mortgage'])
7.df['loan'] = le.fit_transform(df['loan'])
8.df['contact'] = le.fit_transform(df['contact'])
9.df['month'] = le.fit_transform(df['month'])
10.df['poutcome'] = le.fit_transform(df['poutcome'])
11.df['purchased'] = le.fit_transform(df['purchased'])
12.df.dropna(inplace=True)
13.X = df.iloc[:, :-1]
14.y = df.iloc[:, -1]
15.le = LabelEncoder()
16.y = le.fit_transform(y)4.数据划分训练集和测试集
1.X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=425.训练和测试随机森林模型
1.rf = RandomForestClassifier(n_estimators=100, random_state=42)
2.rf.fit(X_train, y_train)
3.y_rf_pred = rf.predict(X_test)6.可视化其中的一棵树
首先使用matplotlib设置一个图形画布大小为(30,15),以适配决策树的展示。然后调用plot_tree函数,传递参数rf.estimators_[0]、feature_names和class_names。其中rf.estimators_[0]是随机森林中的第一个决策树,feature_names是数据集特征名称列表,class_names是数据集标签名称列表。
1.plt.figure(figsize=(30,15))
2.plot_tree(rf.estimators_[0], filled=True, feature_names=X.columns, class_names=["No", "Yes"])
3.plt.show()7.模型评估
使用了三个评价指标来对随机森林模型的性能进行评估,这些指标为准确率(accuracy)、精准率(precision)和召回率(recall)。其中,accuracy_score()函数用于计算模型在测试集上的准确率,precision_score()函数用于计算模型在测试集上的精准率,而recall_score()函数用于计算模型在测试集上的召回率。
1.print("Random Forest: Accuracy: {:.3f}, Precision: {:.3f}, Recall: {:.3f}"
2. .format(accuracy_score(y_test, y_rf_pred), precision_score(y_test, y_rf_pred), recall_score(y_test, y_rf_pred)))
三.svm算法
前五个步骤与决策树算法实现过程前五个步骤一样,在这里就不做过多的解释了。
1.导入项目运行所需要的包
3.import pandas as pd
4.from sklearn.tree import DecisionTreeClassifier
5.import matplotlib.pyplot as plt
6.from sklearn.tree import plot_tree
7.from sklearn.model_selection import train_test_split
8.from sklearn.preprocessing import LabelEncoder
9.from sklearn.ensemble import RandomForestClassifier
10.from sklearn.svm import SVC
11.from sklearn.metrics import accuracy_score, precision_score, recall_score2.读取数据文件
1.df = pd.read_excel('C:/Users/DELL/Desktop/数据集 (1)/股票购买数据集.xlsx')3.数据预处理
1.le = LabelEncoder()
2.df['job'] = le.fit_transform(df['job'])
3.df['marital'] = le.fit_transform(df['marital'])
4.df['education'] = le.fit_transform(df['education'])
5.df['bankrupt'] = le.fit_transform(df['bankrupt'])
6.df['mortgage'] = le.fit_transform(df['mortgage'])
7.df['loan'] = le.fit_transform(df['loan'])
8.df['contact'] = le.fit_transform(df['contact'])
9.df['month'] = le.fit_transform(df['month'])
10.df['poutcome'] = le.fit_transform(df['poutcome'])
11.df['purchased'] = le.fit_transform(df['purchased'])
12.df.dropna(inplace=True)
13.X = df.iloc[:, :-1]
14.y = df.iloc[:, -1]
15.le = LabelEncoder()
16.y = le.fit_transform(y)4.数据划分训练集和测试集
1.X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=425.训练和测试模型
首先,使用SVC(kernel=‘linear’, random_state=42)实例化一个SVM分类器,其中kernel='linear’表示采用线性核函数进行分类,random_state=42表示设置随机种子,使结果具有可重复性。然后,使用训练数据集进行SVM模型的拟合:svm.fit(X_train, y_train)。接下来,使用测试数据集进行预测,并将预测结果保存在变量y_svm_pred中:y_svm_pred = svm.predict(X_test)。最后,使用print()函数输出变量y_svm_pred,查看预测结果。
1.svm = SVC(kernel='linear', random_state=42)
2.svm.fit(X_train, y_train)
3.y_svm_pred = svm.predict(X_test)
4.print(y_svm_pred)6.模型评估
使用了三个评价指标来对SVM模型的性能进行评估,这些指标为准确率(accuracy)、精准率(precision)和召回率(recall)。其中,accuracy_score()函数用于计算模型在测试集上的准确率,precision_score()函数用于计算模型在测试集上的精准率,而recall_score()函数用于计算模型在测试集上的召回率。
1.print("SVM: Accuracy: {:.3f}, Precision: {:.3f}, Recall: {:.3f}"
2. .format(accuracy_score(y_test, y_svm_pred), precision_score(y_test, y_svm_pred), recall_score(y_test, y_svm_pred)))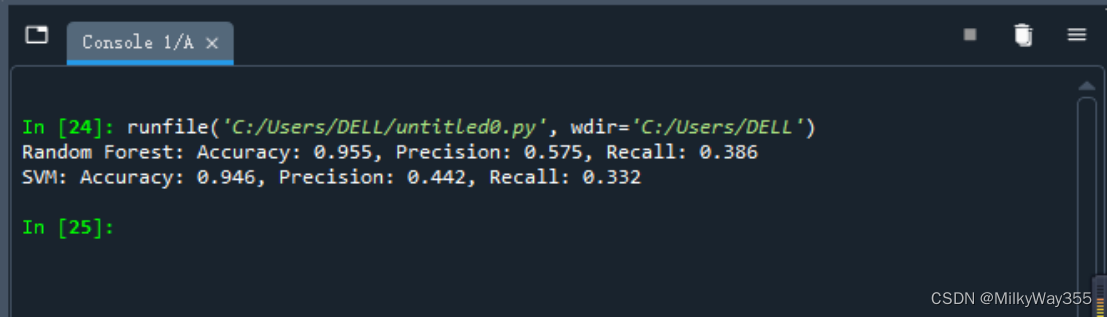
四.对比不同预测算法模型
决策树算法是一种基于树结构的分类器,其建立的是一棵树,每个结点代表一个属性,每个分支代表一个可能的取值,而每个叶子结点代表一个分类(或回归)结果。决策树算法适用于小数据集、易于解释、可视化和处理缺失值。
随机森林算法是一种基于多个决策树的分类器,它通过集成多个决策树来提高模型的预测准确率和鲁棒性。随机森林算法通过随机选择训练数据和特征,来训练多棵决策树,并通过集成这些决策树的预测结果,来得到最终的分类(或回归)结果。随机森林算法适合处理高维数据、数据质量较差,以及需要快速建模和准确预测的场景。
SVM算法基于数据点之间的边界(或叫决策边界)来分离类别。SVM算法最小化向量间距离来寻找最优边界,同时也有一些技巧来处理非线性问题,例如核函数。SVM适用于确信决策边界对预测结果影响显著,以及需要具有较高准确度、较少参数和容错率的场景。
总之,决策树算法适用于小数据集、易于解释;随机森林算法适用于高维数据、数据质量较差、快速建模和准确预测的场景;而SVM算法适用于确信决策边界对预测结果影响显著、准确度较高、参数较少和容错率高的场景。
根据预测结果的准确度可以比较出,随机森林模型的预测准确率最高为0.955,svm模型的预测准确率次之为0.946,预测准确率最低的是决策树模型为0.940。















 139
139











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









