






1.1实验目的
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
本实验要求掌握Linux环境下,完成Flume的下载、安装与简单的操作使用。
Flume主要由3个重要的组件构成:
1.Source:完成对日志数据的收集,分成transtion 和 event 打入到channel之中。
2.Channel:主要提供一个队列的功能,对source提供中的数据进行简单的缓存。
3.Sink:取出Channel中的数据,进行相应的存储文件系统,数据库,或者提交到远程服务器。
1.2 实验步骤
1.2.1 下载Flume压缩包
(1) 打开虚拟机中的Firefox浏览器
进入Flume的下载官网(http://www.apache.org/dyn/closer.lua/flume/1.9.0/apache-flume-1.9.0-tar.gz),页面如下,点击红色方框的选项进行下载,本实验使用的flume的版本是1.9.0。

(2)保存压缩包
在如下提示框中选择Save File,之后文件会被保存到“/home/hadoop/下载/”目录下

1.2.2 解压安装Flume
( 1)找到压缩包的目录(/home/hadoop/下载),将压缩包解压到/usr/local目录下,这里一定要加上-C,否则会出现归档找不到的错误!


(2)进入/usr/local目录查看是否解压成功
$cd /usr/local
$ls
 (3)将解压的文件名修改为flume,方便之后的操作
(3)将解压的文件名修改为flume,方便之后的操作
$sudo mv apache-flume-1.9.0-bin flume
$ls

(4)把/usr/local/flume目录的权限赋予当前用户hadoop
$sudo chown -R hadoop:hadoop flume
![]()
1.2.3 配置环境变量
(1)修改系统环境变量配置文件,在里面加上flume的路径
$sudo vi /etc/profile
# flume
export FLUME_HOME=/usr/local/flume # Flume 安装路径
export PATH=$PATH:$FLUME_HOME/bin # 添加系统 PATH 环境变量
$source /etc/profile


(2)修改flume配置文件
进入/usr/local/flume/conf目录,拷贝flume-env.sh.template文件并重命名为flume-env.sh
$cd /usr/local/flume/conf
$cp flume-env.sh.template flume-env.sh
修改配置文件flume-env.sh
$vi /usr/local/flume/conf/flume-env.sh

(3)修改 JAVA_HOME 参数值为 jdk 安装路径
export JAVA_HOME=/usr/local/java/jdk1.8.0_162

1.2.4测试安装结果
(1)测试是否安装成功,若出现无法显示主类则参考(2)
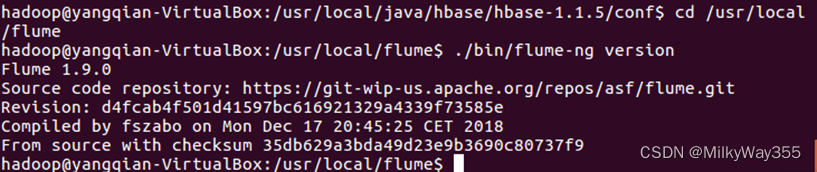
$cd /usr/local/flume
$./bin/flume-ng version
(2)如果系统之前安装过hbase,则会报错:找不到或无法加载主类

解决方法:进入hbase的conf目录,修改hbase的配置文件,将hbase的路径注释掉即可
$cd /usr/local/hbase/hbase-1.1.5/conf
$sudo vim hbase-env.sh
#export HBASE_CLASSPATH=/usr/local/java/hadoop/hadoop-2.7.1/conf


修改完之后重新执行(1)中命令即可
1.2.5 Flume测试与使用
案例一:
(1)进入flume目录,在该目录下创建avro.conf文件,并在里面写入以下内容
$cd /usr/local/flume
$sudo vim ./conf/avro.conf
点击i启动编辑,将下面内容复制进入文档里。点击ESC后输入:wq,保存退出。
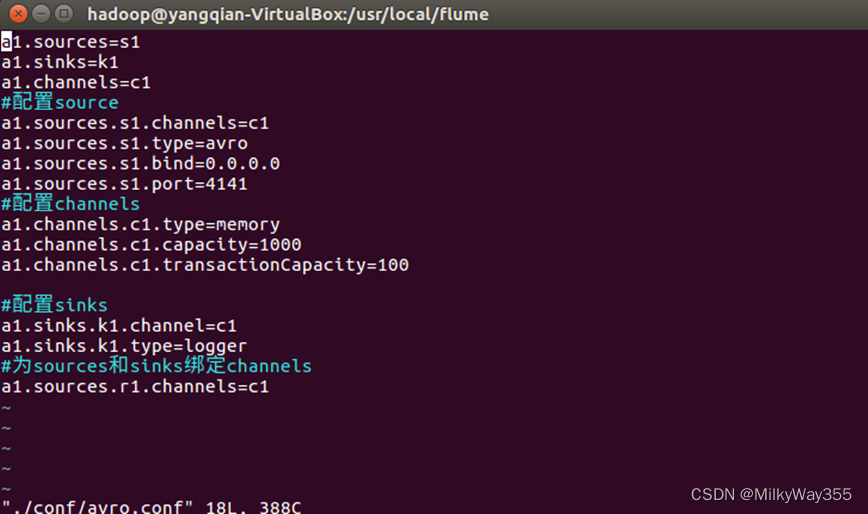
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 4141
#注意这个端口名,在后面的教程中会用得到
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
![]()
上面Avro Source参数说明如下:
Avro Source的别名是avro,也可以使用完整类别名称org.apache.flume.source.AvroSource,因此,上面有一行设置是a1.sources.r1.type = avro,表示数据源的类型是avro。
bind绑定的ip地址或主机名,使用0.0.0.0表示绑定机器所有的接口。a1.sources.r1.bind = 0.0.0.0,就表示绑定机器所有的接口。
port表示绑定的端口。a1.sources.r1.port = 4141,表示绑定的端口是4141。
a1.sinks.k1.type = logger,表示sinks的类型是logger。
(2)启动flume agent a1,即启动日志控制台,输入以下命令:
$/usr/local/flume/bin/flume-ng agent -c . -f /usr/local/flume/conf/avro.conf -n a1 -Dflume.root.logger=INFO,console
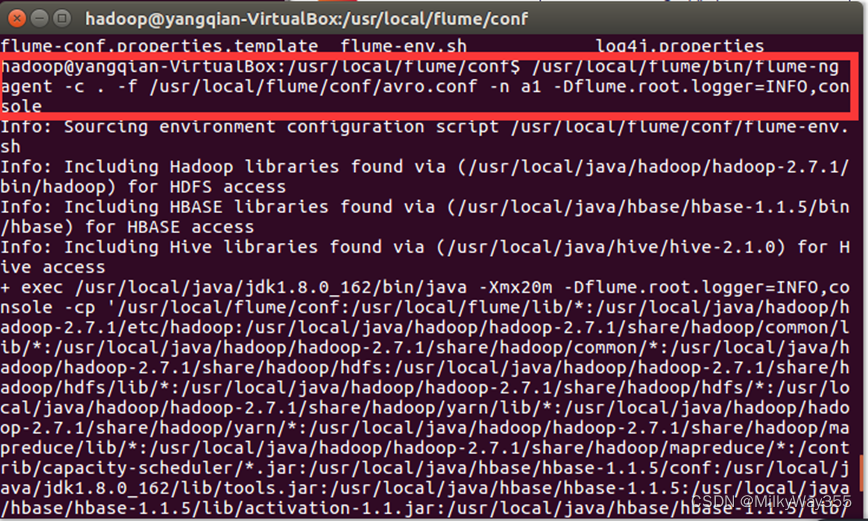
出现一下界面表示启动成功!我们把这个窗口成为agent窗口
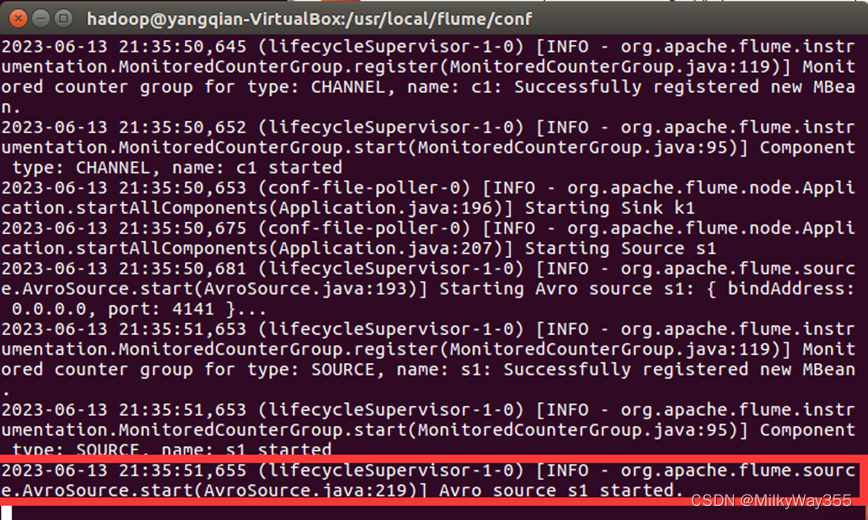
(3)创建指定文件
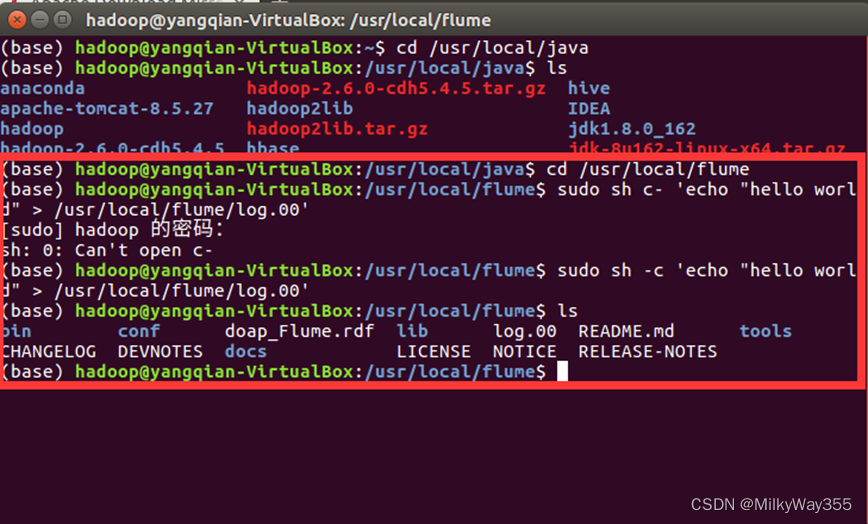
打开另一个终端,进入/usr/local/flume目录,创建一个名为log.00的文件,在里面加入hello world,并查看文件是否创建成功
$cd /usr/local/flume
$sudo sh -c 'echo "hello world" > /usr/local/flume/log.00'
$ls
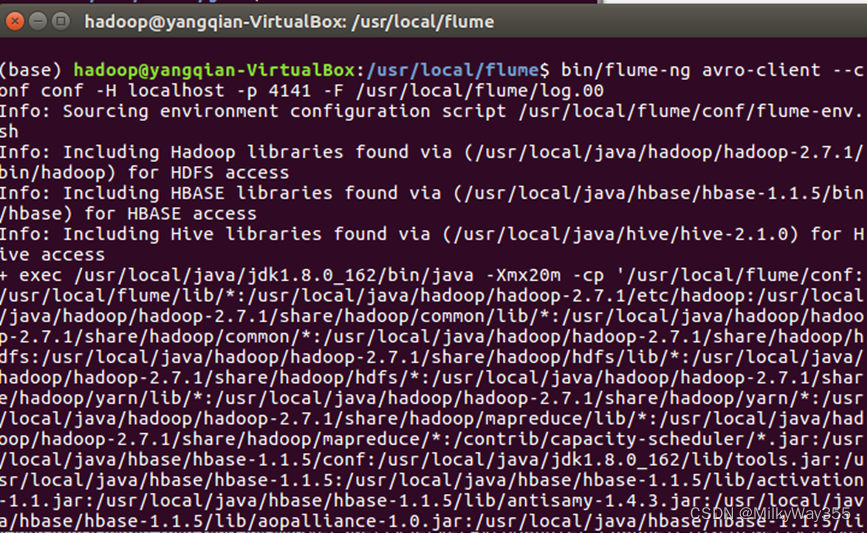
(4)再打开一个终端,进入flume目录,执行以下命令,此时就可以看到第一个终端下的日志控制台会显示log.00文件的内容
$cd /usr/local/flume
$ bin/flume-ng avro-client --conf conf -H localhost -p 4141 -F /usr/local/flume/log.00 #4141是avro.conf文件里的端口名
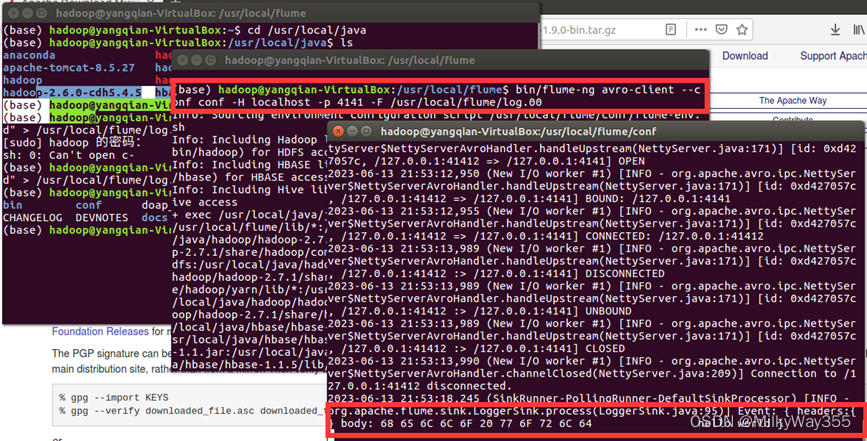
案例一到这里就结束啦!
案例二:
1.创建agent 配置文件,进入/use/local/flume目录,在conf目录下创建example.conf文件,并在文件中加入以下内容。
$cd /usr/local/flume
$sudo vim ./conf/example.conf
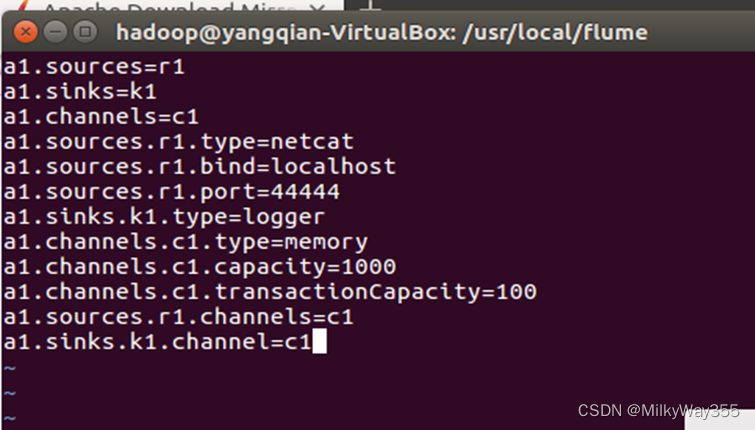
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
a1.sinks.k1.type = logger
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1

2.进入/usr/local/flume/conf目录,启动flume agent(即打开日志控制台),命令如下:
$cd /usr/local/flume/conf
$/usr/local/flume/bin/flume-ng agent -n a1 -f conf -f example.conf -Dflume.root.logger=INFO,console

出现一下界面则表示启动成功!

3.再打开一个终端输入以下命令,注意这的44444为刚才配置文件中的端口号
$telnet localhost 44444
出现以下界面即为成功!

4.在第二个打开的终端中输入“hello world”“hello hadoopppp”,第一个终端的日志控制台也会有相应显示

注意:flume只能传递英文和字符,不能用中文!例如我们在第二个终端输入“我爱中国”,第一个终端的日志控制台并不会显示,如下图
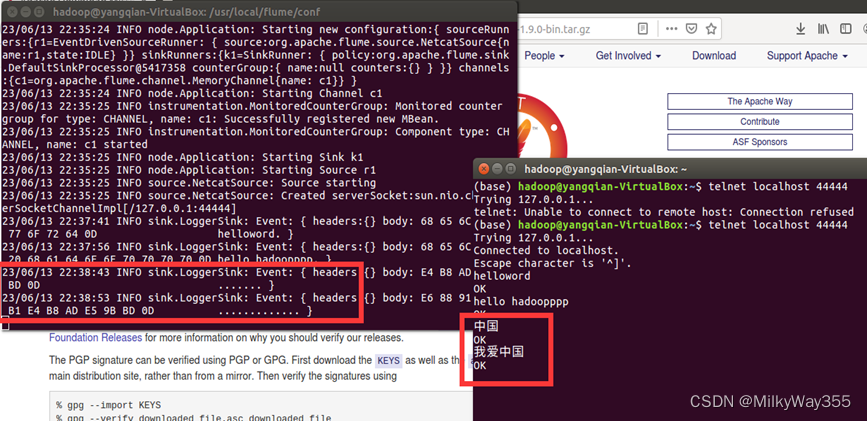
第二个案例到这里也就完成啦!
案例三:
1.切换到/usr/local/java/hadoop/hadoop-2.7.1/sbin目录下,启动Hadoop
并查看是否启动成功。
$cd /usr/local/java/hadoop/hadoop-2.7.1/sbin
$start-dfs.sh
$jps


2.进入flume下的conf目录,创建flume配置文件syslog_mem_hdfsandlogger.conf
$cd /usr/local/flume/conf
$touch syslog_mem_hdfsandlogger.conf

3.在flume的配置文件中定义如下信息
$sudo vim syslog_mem_hdfsandlogger.conf

#定义各个组件
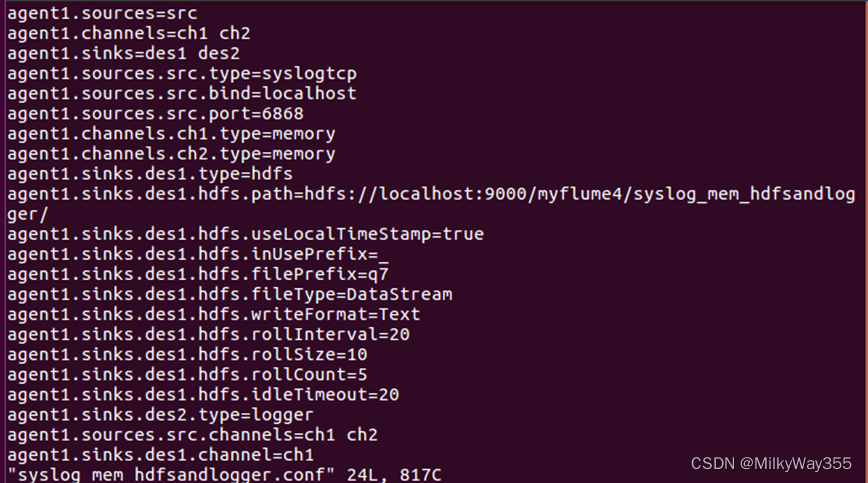
agent1.sources = src
agent1.channels = ch1 ch2
agent1.sinks = des1 des2
#配置source
agent1.sources.src.type = syslogtcp
agent1.sources.src.bind = localhost
agent1.sources.src.port = 6868
#配置channel
agent1.channels.ch1.type = memory
agent1.channels.ch2.type = memory
#配置hdfs sink
agent1.sinks.des1.type = hdfs
agent1.sinks.des1.hdfs.path = hdfs://localhost:9000/myflume4/syslog_mem_hdfsandlogger/
agent1.sinks.des1.hdfs.useLocalTimeStamp = true
#设置flume临时文件的前缀为 . 或 _ 在hive加载时,会忽略此文件。
agent1.sinks.des1.hdfs.inUsePrefix=_
#设置flume写入文件的前缀是什么
agent1.sinks.des1.hdfs.filePrefix = q7
agent1.sinks.des1.hdfs.fileType = DataStream
agent1.sinks.des1.hdfs.writeFormat = Text
#hdfs创建多久会新建一个文件,0为不基于时间判断,单位为秒
agent1.sinks.des1.hdfs.rollInterval = 20
#hdfs写入的文件达到多大时,创建新文件 0为不基于空间大小,单位B
agent1.sinks.des1.hdfs.rollSize = 10
#hdfs有多少条消息记录时,创建文件,0为不基于条数判断
agent1.sinks.des1.hdfs.rollCount = 5
#hdfs空闲多久就新建一个文件,单位秒
agent1.sinks.des1.hdfs.idleTimeout = 20
#配置logger sink
agent1.sinks.des2.type = logger
agent1.sinks.des1.channel=ch1
agent1.sinks.des2.channel=ch2

4.定义好配置文件后,保存退出并进入/usr/local/flume目录,启动flume-ng的配置。命令如下:
$cd /usr/local/flume
$flume-ng agent -c /conf -f /usr/local/flume/conf/syslog_mem_hdfsandlogger.conf -n agent1 -Dflume.root.logger=DEBUG,console

出现如下界面则表示启动成功!

5.打开一个新的终端,执行nc命令,向6868端口发送消息。
$echo “hello can you hear me?” | nc localhost 6868
![]()
6.查看执行效果
第一个终端显示,即在flume-ng配置的界面输出结果,可以看到sink.LoggerSink,也就是发送给logger的输出

再来看HDFS上的输出,再打开的第二个终端输入以下命令查看:
$hadoop fs -ls -R /
$hadoop fs -cat /myflume4/syslog_mem_hdfsandlogger/*


第三个案例到这里就结束啦!















 3205
3205











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









