






一、功能介绍
功能1:输入某个关键字,访问该关键字相关内容;
功能2:将访问的内容保存为.txt、.html两种格式;
功能3:提取相关访问内容的超链接;
功能4:随机提取一条超链接,进行访问,并将访问页面的内容存储。
二、代码解读
1.导入所需的库
import requests
import re
这部分导入了两个Python库:requests用于发送HTTP请求,re用于正则表达式匹配。
2.headars设置和获取用户输入
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0'
}
它包含了一系列的HTTP头部信息(通常称为“headers”)。这些头部信息主要用于发送HTTP请求时提供一些附加的元数据,如认证信息、自定义标头或特定的服务器配置等。
keyword = input("请输入关键字:")
这里使用input()函数获取用户输入的关键字。
3.发送GET请求到Bing并获取响应:
response = requests.get(f'https://cn.bing.com/search?q={keyword}',headers =headers)
response.encoding = 'utf-8'
pagetext = response.text
使用requests.get()函数发送一个GET请求到Bing的搜索API,并将用户输入的关键字作为查询参数。然后设置响应的编码为'utf-8',并获取响应的内容。
4. 保存页面内容到文件,保存为html文件和txt文件
with open(f'./{keyword}frst.html', 'w', encoding='utf-8') as fp:
fp.write(pagetext)
print('网页保存结束')
这部分使用with语句打开一个文件,并将Bing搜索结果的内容写入该文件。文件名由用户输入的关键字和“frst.html”组成。完成后,打印“网页保存结束”的消息。
with open(f'./{keyword}frst.html', 'w', encoding='utf-8') as fp:
fp.write(pagetext)
print('网页保存结束')
这部分使用with语句打开一个文件,并将Bing搜索结果的内容写入该文件。文件名由用户输入的关键字和“frst.txt”组成。完成后,打印“网页保存结束”的消息。
5. 提取第一层访问的超链接:
urls = re.findall(r'target="_blank" href="(.*?)"', pagetext)
使用正则表达式从页面内容中提取所有超链接。这些URLs通常在HTML中的`target="_blank"`属性中。
6. 打印每个超链接:
for i in range(0,len(urls)):
print('跳转链接',urls[i])
print('第一层超链接提取成功')
print('--'*10)
这段代码的功能是:提取网页中的超链接,并打印出每个超链接,最后输出一个表示成功的消息。其中,使用破折号是为了在输出结果中增加可视化的分隔,使得输出结果更加清晰易读。
7.随机从输入关键字得到的链接中获取的链接进行访问
Import random
j=random.randint(0,len(urls))
print('随机数为:',j)
导入模块:导入Python的random模块,用于生成随机数。使用random.randint(0, len(urls))生成一个随机整数j,用于从urls列表中随机选择一个超链接。
8.获取和保存网页内容
ur = urls[j]
response = requests.get(ur,headers=headers)
response.encoding = 'utf-8'
pagetext1 = response.text
with open(f'./{keyword}gwanye2.html', 'w', encoding='utf-8') as fp:
fp.write(pagetext1)
with open(f'./{keyword}gwanye2.txt', 'w', encoding='utf-8') as fp:
fp.write(pagetext1)
从urls列表中使用随机数j选择一个超链接,使用requests.get()方法向该超链接发送GET请求,设置响应的编码为'utf-8',将响应内容(即网页的HTML代码)保存在编码pagetext1中,打开一个新的文件,并使用文件获取内容写入该文件。文件的名称基于变量keyword的值,一个保存为变量keyword的值gwanye2.html格式,另外一个保存为keyword的值gwanye2.txt格式。
9.提取超链接和打印提取的超链接
ur2 = re.findall(r'target="_blank" href="(.*?)"', pagetext1)
print(ur2)
for i in range(0,len(ur2)):
print('跳转链接:',ur2[i])
print('第二层超链接提取成功')
使用正则表达式从已保存的HTML内容中提取所有带有`target="_blank"`属性的链接。这些链接是那些在新窗口或新标签页中打开的链接。通过循环遍历所有提取的链接,并逐个打印它们。
三、演示结果分析
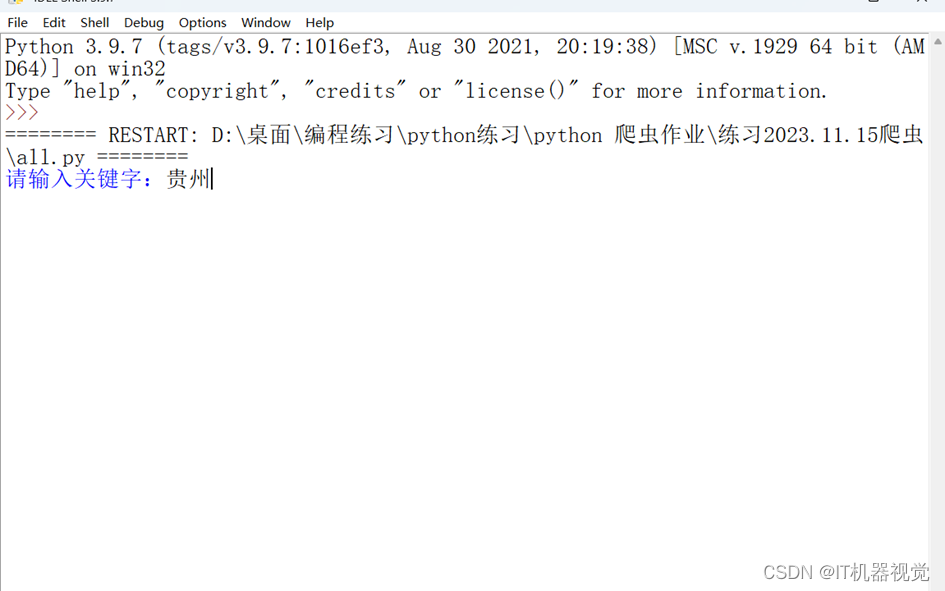
1.按照提示输入关键字为贵州,结果如图所示:
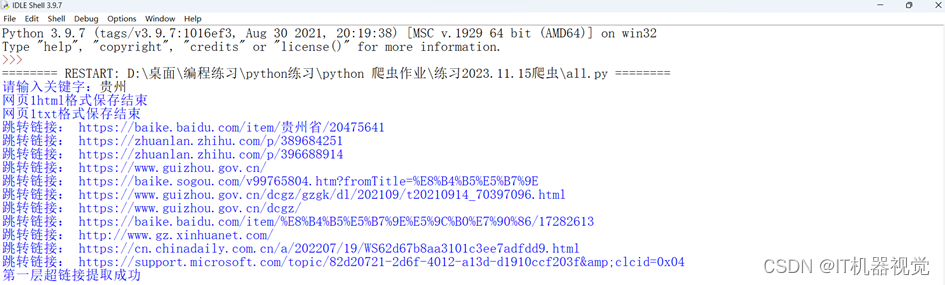
2.提取第一层超链接结果如图所示:
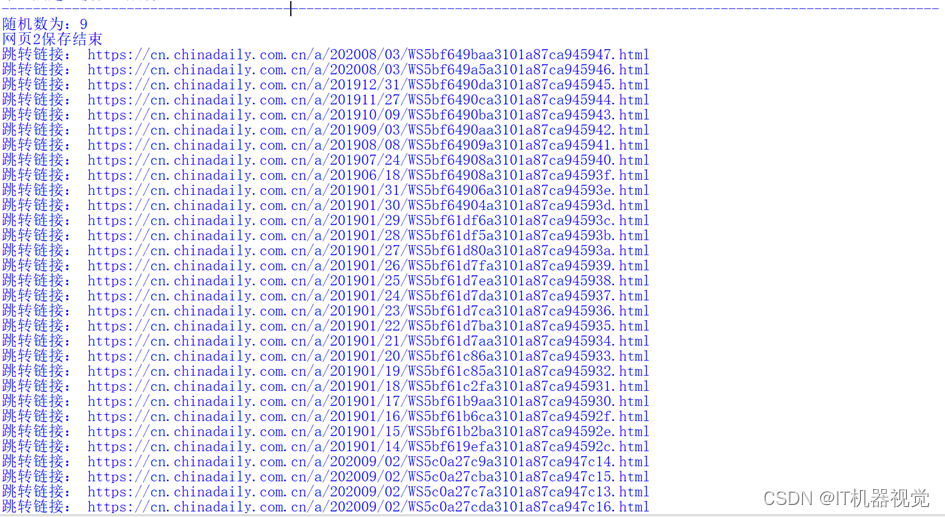
3.提取第二层超链接结果如图所示:
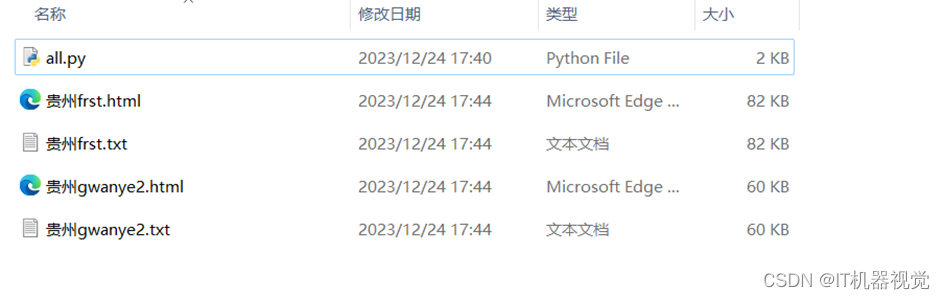
4.爬取后文件的保存结果如下图所示:
5.保存的贵州frist.html文件打开结果如图所示:
6. 保存的贵州frist.txt文件打开结果如图所示:

四、总结
在本次作业中用到了python的一些功能:导入requests和re模块,设置请求头部信息,模拟真实浏览器的请求,用户输入关键字,使用requests库发送HTTP请求,获取Bing搜索结果页面设置响应内容的编码为utf-8,将响应内容保存为html文件和txt文件,使用正则表达式提取页面中的超链接,遍历超链接列表,并打印每个超链接。
在提取的过程中也出现了一些问题,以下是针对于爬取过程中一些问题的处理方法,在爬取的的过程中出现爬取的数据是乱码的,可以使用response.encoding = 'utf-8'去将爬取的字符编码格式改为和原网页一样的格式。爬取的过程中网页拒绝访问,不能获取到自己想要的数据时,可以先设置headers,headers中可以包含User-Agent,Referer、Accept、Cookie等,然后在requests.get()中加入headers则可以解决。
五、代码
import requests
import re
#第一层
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0'
}
keyword = input("请输入关键字:")
response = requests.get(f'https://cn.bing.com/search?q={keyword}',headers =headers )
response.encoding = 'utf-8'
pagetext = response.text
with open(f'./{keyword}frst.html', 'w', encoding='utf-8') as fp:
fp.write(pagetext)
print('网页1html格式保存结束')
with open(f'./{keyword}frst.txt', 'w', encoding='utf-8') as fp:
fp.write(pagetext)
print('网页1txt格式保存结束')
urls = re.findall(r'target="_blank" href="(.*?)"', pagetext)
#print(urls)
for i in range(0,len(urls)):
print('跳转链接:',urls[i])
print('第一层超链接提取成功')
print('--'*60)
#第二层
import random
j=random.randint(0,len(urls))
print('随机数为:j')
ur = urls[j]
response = requests.get(ur,headers=headers)
response.encoding = 'utf-8'
pagetext1 = response.text
with open(f'./{keyword}gwanye2.html', 'w', encoding='utf-8') as fp:
fp.write(pagetext1)
with open(f'./{keyword}gwanye2.txt', 'w', encoding='utf-8') as fp:
fp.write(pagetext1)
print('网页2保存结束')
ur2 = re.findall(r'target="_blank" href="(.*?)"', pagetext1)
#print(ur2)
for i in range(0,len(ur2)):
print('跳转链接:',ur2[i])
print('第二层超链接提取成功')















 1945
1945











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









