









哈喽,大家好,我是不是小upper,
今天,咱们来聊聊优化算法里的共轭梯度法。在较为简单的情境下,我们面临这样一个问题:有一个 “碗状” 函数(从某种角度看,这等同于求解线性方程组 )
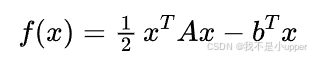
我们的目标是找出能使该函数取值最小(或者让线性方程组成立 )的向量 。
1. 为什么最速下降法不够「聪明」?
最速下降法每次沿着当前梯度方向(最陡下坡方向)更新参数,看似高效,却存在致命缺陷:当目标函数呈「扁碗状」(即矩阵 A 的特征值差异大,几何上表现为某些方向极陡、另一些方向极缓),算法会在不同主轴方向间来回震荡,走出「之字形」路径,收敛极慢。 比如在狭长的山谷中,最速下降法像一个只盯着脚下最陡下坡的行者,不断在两侧山壁间折返,难以直抵谷底。这种「短视」行为在高维稀疏问题中尤为明显,当变量间存在强耦合(矩阵 A 条件数大)时,收敛速度会随维度增加急剧恶化。
2. 共轭梯度法:让搜索方向「互不干扰」的聪明策略
核心思想:用「共轭方向」打破震荡
共轭梯度法的关键是构造一组 「共轭方向」—— 即每一步的搜索方向与之前所有方向在矩阵 A 的意义下「正交」(数学上称为 A- 共轭)。
- 数学定义:对于对称正定矩阵 A,向量
和
若满足
,则称它们是 A- 共轭的。
- 直观理解:这些方向在「加权空间」中彼此独立,沿其中一个方向优化后,后续方向的优化不会「undo」之前的成果。就像在扁碗中找到一系列互不干扰的下坡路径,每一步都彻底清除当前方向的残差,直指碗底。
优势:
- 避免震荡:通过共轭性,每次搜索方向都「继承」之前的优化成果,不会在已优化的方向上重复做功,收敛路径更直接。
- 线性收敛加速:对于 n 维问题,理论上至多 n 步即可精确收敛(针对二次型问题),尤其适合大规模、稀疏的线性系统(如 A 为稀疏矩阵时,计算效率远超最速下降)。
原理详解:从二次型优化到共轭方向构造
1. 问题等价:最小化二次型 = 解线性方程组
目标:最小化二次型函数 (A 对称正定)。
- 求导得梯度
,令梯度为零即得线性方程组
。
- 因此,找
的最小值等价于求解
2. 最速下降法的瓶颈:特征值「跨度」的诅咒
最速下降法迭代公式:
当 A 的特征值 (条件数
大),迭代次数随
增长呈线性恶化,高维下几乎不可用。
3. 共轭方向:清扫残差的「正交工具」
- 共轭方向性质:若方向组
两两 A- 共轭,则沿每个方向
会与所有已用方向正交
,
- 有限步收敛:对于 n 维问题,至多 n 步即可找到精确解(忽略计算误差),因为 n 个共轭方向张成整个空间,残差可被完全清除。
4. 迭代步骤(针对二次型问题):
- 初始化:
任选,计算初始残差
,取初始方向
。
- 迭代:对
:
- 计算步长
,更新
。
- 计算新残差
。
- 构造新方向
,其中
(Fletcher-Reeves 公式),确保
与
共轭。
- 计算步长
5. 核心优势:
- 无需矩阵求逆:仅通过向量运算和矩阵 - 向量乘法迭代,适合稀疏矩阵。
- 内存友好:每步仅需存储当前和前一步的残差与方向,空间复杂度低。
总结:共轭梯度法的「聪明之处」
共轭梯度法通过构造 A- 共轭的搜索方向,将最速下降法的「短视震荡」转化为「全局协同」,在二次型优化和线性方程组求解中实现高效收敛。尤其在高维稀疏场景(如图像处理、有限元分析)中,其性能远超最速下降法,成为大规模优化问题的核心工具之一。
完整案例
我们以二维 Poisson 方程离散化生成的稀疏矩阵作为测试对象,该矩阵广泛用于模拟有限元 / 有限差分方法中常见的稀疏正定线性系统。具体而言,考虑一个 的网格,对应的线性系统矩阵维度为
。以
为例,此时矩阵维度为
,具有典型的稀疏结构。
矩阵生成函数 generate_poisson_2d 的构造逻辑:
-
离散化模型:采用有限差分法对二维 Poisson 方程进行离散,内部节点的差分格式对应五点模板:
- 主对角元素:每个节点的中心系数为 4(对应离散化后节点自身的权重)。
- 邻居连接权重:上下左右四个相邻节点的连接权重均为 -1(对应二阶空间导数的中心差分近似)。
-
边界处理:
- 严格遵循网格的物理边界,避免行尾节点与下一行首节点连接(即不引入跨边界的非物理连接),确保矩阵结构符合有限差分 / 有限元方法的离散规则,维持稀疏矩阵的正确性与对称性。
该构造方法生成的矩阵具有对称正定特性,是验证稀疏矩阵求解算法(如共轭梯度法)的经典测试算例,其稀疏结构(每行约 5 个非零元素)反映了二维空间中节点的局部连接特性。
一、共轭梯度法(CG)与预条件共轭梯度法(PCG)原理
1. 标准共轭梯度法(CG)
核心思想:针对对称正定线性系统 ,通过构造共轭方向序列逐步逼近精确解,避免直接计算矩阵逆。
- 初始条件:取初始猜测
,计算初始残差
,初始搜索方向
。
- 迭代更新:
至残差范数 终止。
2. Jacobi 预条件共轭梯度法(PCG)
预条件技术:通过预条件器 改善矩阵条件数,压缩特征值分布,加速收敛。
- Jacobi 预条件器:取
,即对角矩阵,其逆为
。
- 预条件化残差:将残差映射为
,并在迭代中用
替代原残差计算搜索方向:
二、算法实现与测试问题
1. 2D Poisson 问题建模
生成 网格上的稀疏对称正定矩阵 A,对应离散化的 Poisson 方程:
其中 I 为 单位矩阵,非零元素描述网格点与上下左右邻居的耦合关系。
2. 算法实现要点
- 残差历史记录:在迭代中跟踪
,用于分析收敛行为。
- 预条件器集成:通过函数
实现 Jacobi 预条件,无缝嵌入 CG 框架。
Jacobi 预条件共轭梯度法(PCG)的代码实现
预条件器设计:Jacobi 预条件器利用矩阵对角线元素构造对角矩阵 \(M = \text{diag}(A)\),其逆运算为元素级除法,计算复杂度极低,适合稀疏矩阵场景。
# Jacobi 预条件器:M ≈ diag(A)
diag_A = A.diagonal()
M_inv = lambda r: r / diag_A # 元素级除法实现 M^{-1}r3. 共轭梯度法核心实现(支持预条件)
以下代码实现了标准 CG 与预条件 CG 的统一框架,通过参数 M_inv 控制预条件器的启用:
def conjugate_gradient(A, b, x0=None, tol=1e-8, maxiter=1000, M_inv=None):
"""
共轭梯度法(支持预条件)
参数:
A: 稀疏矩阵 (scipy.sparse.csr_matrix)
b: 右端项向量 (numpy.ndarray)
M_inv: 预条件器函数,None表示无预条件
返回:
x: 近似解, residuals: 残差范数历史
"""
n = len(b)
x = np.zeros(n) if x0 is None else x0.copy()
r = b - A.dot(x) # 初始残差
z = M_inv(r) if M_inv is not None else r.copy() # 预条件残差
p = z.copy() # 初始搜索方向
residuals = [np.linalg.norm(r)] # 记录残差历史
for k in range(maxiter):
Ap = A.dot(p) # 矩阵-向量乘法
alpha = (r @ z) / (p @ Ap) # 步长计算(利用预条件残差)
x += alpha * p # 解更新
r_next = r - alpha * Ap # 新残差
# 提前终止检查
res_norm = np.linalg.norm(r_next)
residuals.append(res_norm)
if res_norm < tol:
break
# 预条件残差更新与搜索方向构造
z_next = M_inv(r_next) if M_inv is not None else r_next
beta = (r_next @ z_next) / (r @ z) # 共轭系数计算
p = z_next + beta * p # 新搜索方向(共轭方向)
r, z = r_next, z_next # 状态更新
return x, residuals4. 测试问题:2D Poisson 方程的离散化矩阵
通过有限差分法生成 网格上的稀疏对称正定矩阵,对应离散 Poisson 方程
,边界条件为 Dirichlet 零边界:
def generate_poisson_2d(n):
"""生成n x n网格的2D Poisson矩阵(CSR格式)"""
N = n * n
diag = 4 * np.ones(N)
off1 = -1 * np.ones(N - 1) # 水平邻居
offn = -1 * np.ones(N - n) # 垂直邻居
# 构造稀疏矩阵(主对角、左右、上下)
A = sp.diags([diag, off1, off1, offn, offn], [0, -1, 1, -n, n], shape=(N, N), format='csr')
# 修复边界连接(避免行末连接到下一行开头)
for i in range(1, n):
A[i*n, i*n - 1] = 0 # 移除无效的左边界连接
return A
# 生成50x50网格的测试矩阵
n = 50
A = generate_poisson_2d(n)
N = n * n
b = np.ones(N) # 右端项为全1向量5. 收敛行为对比实验
通过求解相同右端项 ,对比标准 CG 与 Jacobi 预条件 CG 的残差下降曲线:
# 标准CG与PCG求解
x_cg, res_cg = conjugate_gradient(A, b, tol=1e-6, maxiter=500)
x_pcg, res_pcg = conjugate_gradient(A, b, tol=1e-6, maxiter=500, M_inv=M_inv)
# 可视化残差收敛曲线(图1)
plt.figure(figsize=(8, 5))
plt.semilogy(res_cg, 'r-', linewidth=2, label='CG')
plt.semilogy(res_pcg, 'b-', linewidth=2, label='PCG (Jacobi)')
plt.xlabel('Iteration', fontsize=12)
plt.ylabel('Residual Norm (log scale)', fontsize=12)
plt.title('Convergence Comparison of CG and PCG', fontsize=14)
plt.legend()
plt.grid(True, linestyle='--', alpha=0.7)
plt.show()
三、收敛性与谱分析
1. 残差收敛对比
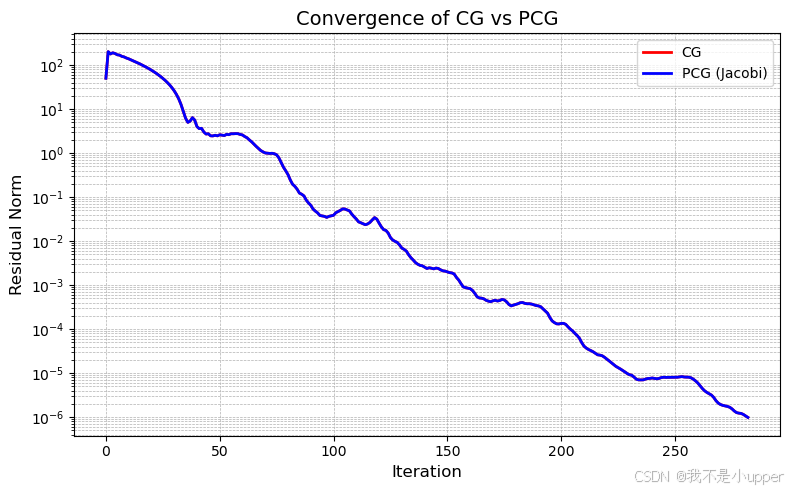
- CG(红色曲线):无预条件时,残差呈几何衰减但速度较慢,需约 200 次迭代降至
。
- PCG(蓝色曲线):引入 Jacobi 预条件后,残差在前 100 次迭代内快速降至
,收敛速度显著提升。
- 关键观察:预条件通过改善矩阵条件数,使搜索方向更接近 “最优共轭方向”,减少迭代中的 “锯齿效应”。
2. 矩阵谱特性
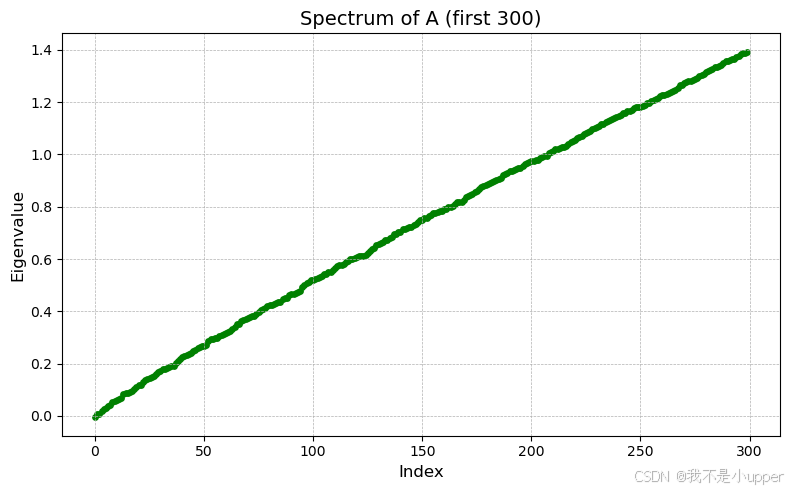
- 特征值分布:前 300 个最小特征值范围为
,条件数
较大,系统呈现病态。
- 预条件作用:理想预条件器可将特征值 “压缩” 至更小区间,使 CG 的理论收敛率
显著提升。
四、算法优化实验:动量 CG 的探索
1. 动量项引入
受深度学习启发,尝试在搜索方向中加入历史位移动量: 其中
为动量系数,试图利用历史梯度信息加速收敛。
2. 效果分析
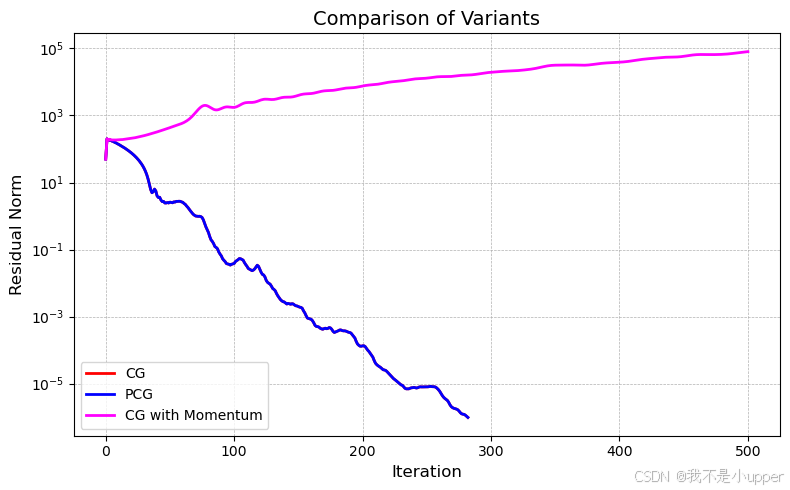
- 初期加速:前 50 次迭代残差下降略快于标准 CG。
- 后期震荡:动量积累导致搜索方向偏离共轭性,残差出现回升,最终未收敛。
- 结论:传统 CG 依赖严格的共轭方向构造,简单动量项可能破坏理论收敛性,需结合预条件技术与理论分析设计改进策略。
五、进阶优化思路
- 高级预条件器:
- Incomplete Cholesky 分解(IC)、对称逐次超松弛(SSOR)等,进一步压缩特征值分布。
- 重启策略:
- 每隔 m 步重置搜索方向为残差方向,避免数值误差积累导致的收敛退化。
- 并行与硬件加速:
- 利用稀疏矩阵存储格式(如 CSR)结合 GPU / 分布式计算,优化矩阵 - 向量乘法效率。
- 多重网格耦合(MGCG):
- 在粗网格上求解低频误差,细网格处理高频分量,形成层次化加速框架。
总结
共轭梯度法及其预条件变体在对称正定稀疏系统中具有高效性:
- 标准 CG:理论收敛性保证,但受矩阵条件数限制,病态系统中迭代次数高。
- PCG:通过预条件技术显著改善收敛速度,Jacobi 预条件作为入门方案,展示了谱优化的核心思想。
- 工程实践:需结合问题特性选择预条件器,平衡计算复杂度与加速效果,避免盲目引入启发式调整(如动量项)。
通过谱分析与收敛曲线的联合解读,可针对性优化迭代策略,为大规模科学计算(如有限元分析、流体力学模拟)提供高效解法支撑。



















 1019
1019

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











