






一、课程设计目的
Python是计算机科学与技术专业学生进行数据分析所需要掌握基础性语言和分析工具,是未来学生掌握大数据分析技术的学习基础。本课程在教学内容方面着重以Python语言讲解及Python语言数据分析工具包应用为主。通过一系列的Python语言数据分析训练项目,培养学生具有一定的Python语言数据分析理解和应用实践能力。
二、课程设计内容
- 数据采集:从数据源(如API、数据库、文件)中获取数据,并将其导入Python中。
- 数据清洗:对数据进行预处理,清除重复值、缺失值,进行数据类型转换等操作。
- 数据转换:根据需求进行数据处理,包括分组、聚合、计算指标等操作,以便后续分析。
- 数据分析:利用可视化工具如matplotlib、seaborn进行数据可视化,分析并解释结果,包括数据趋势、相似性、异同。
- 数据挖掘:对数据进行深入挖掘和分析,并使用机器学习算法进行预测和模型构建,如回归、分类、聚类等。
- 数据可视化:使用Dash、Plotly等库进行交互式可视化,展示数据分析结果。
三、课程设计步骤
# 代码8-1
import numpy as np
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import HeatMap
# 读取数据
income_data = pd.read_csv('../data/income_tax.csv', index_col=0)
# 保留两位小数
data_cor = np.round(income_data.corr(method = 'pearson'), 2)
y_data = list(data_cor.columns) # 获取y轴标签
x_data = list(data_cor.index) # 获取x轴标签
# 相关系数矩阵转为列表
values = data_cor.values.tolist()
# 对应相关系数的位置
value = [[i, j, values[i][j]] for i in range(len(x_data))
for j in range(len(y_data))]
heatmap = (
# 导入热力图
HeatMap()
# 设置x轴
.add_xaxis(x_data)
# 设置y轴
.add_yaxis(
'', y_data,
value,
label_opts=opts.LabelOpts(
is_show=True, position='inside'),
)
.set_global_opts(
# 设置标题
title_opts=opts.TitleOpts(title='相关系数热力图'),
# 设置图例
visualmap_opts=opts.VisualMapOpts(
is_show = False, pos_bottom='center',
max_=1, min_=0.9
)
)
)
heatmap.render('../tmp/相关系数热力图.html')
# 代码8-2
import pandas as pd
import numpy as np
from sklearn.linear_model import Lasso
income_data = pd.read_csv('../data/income_tax.csv', index_col=0) # 读取数据
data_train = income_data.iloc[: , 0:13].copy() # 取2005年~2019年的数据建模
data_mean = data_train.mean()
data_std = data_train.std()
data_train = (data_train - data_mean) / data_std # 数据标准化
lasso = Lasso(alpha=1000, random_state=1234) # 构建Lasso回归模型
lasso.fit(data_train, income_data['y'])
print('Lasso回归系数为:', np.round(lasso.coef_, 5)) # 输出结果,保留5位小数
# 计算系数非零的个数
print('系数非零个数为:', np.sum(lasso.coef_ != 0))
mask = lasso.coef_ != 0 # 返回系数非零特征
print('系数非零特征:', income_data.columns[:-1][mask])
# 返回系数非零的数据
new_reg_data = income_data.iloc[:, 0: 13].iloc[:, mask]
new_reg_data.to_csv('../tmp/new_reg_data.csv') # 存储数据
print('输出数据的维度为:', new_reg_data.shape) # 查看输出数据的维度
# 代码8-3
import numpy as np
import pandas as pd
from gm11 import gm11 # 引入自编的灰色预测函数
# 读取经过特征选择后的数据
new_reg_data = pd.read_csv('../tmp/new_reg_data.csv', index_col=0)
# 读取数据
income_data = pd.read_csv('../data/income_tax.csv', index_col=0)
new_reg_data.index = range(2005, 2020)
new_reg_data.loc[2020] = None
new_reg_data.loc[2021] = None
c = []
p = []
# 进行灰色预测
for i in list(new_reg_data.columns):
f = gm11(np.array(new_reg_data.loc[range(2005, 2020), i]))[0]
c.append(gm11(np.array(new_reg_data.loc[range(2005, 2020), i]))[4])
p.append(gm11(np.array(new_reg_data.loc[range(2005, 2020), i]))[5])
new_reg_data.loc[2020, i] = f(len(new_reg_data) - 1)
new_reg_data.loc[2021, i] = f(len(new_reg_data))
new_reg_data[i] = new_reg_data[i].round(2) # 保留两位小数
new_reg_data = pd.concat([new_reg_data, income_data['y']], axis=1)
new_reg_data.to_csv('../tmp/new_reg_data_GM11.csv') # 结果输出
print('预测结果为:\n', new_reg_data.iloc[-2:, :6]) # 预测结果展示
# 代码8-4
# 读取灰色预测数据
from sklearn.svm import LinearSVR
from sklearn.metrics import explained_variance_score,\
mean_absolute_error, median_absolute_error, r2_score
gm11_data = pd.read_csv('../tmp/new_reg_data_GM11.csv', index_col=0)
feature = gm11_data.columns[: -1]
# 取2005~2019年的数据建模
data_train = gm11_data.loc[range(2005, 2020)].copy()
data_mean = data_train.mean()
data_std = data_train.std()
data_train = (data_train - data_mean) / data_std # 数据标准化
x_train = np.array(data_train[feature]) # 特征数据
y_train = np.array(data_train['y']) # 标签数据
linearsvr = LinearSVR(random_state=1234) # 调用LinearSVR类
linearsvr.fit(x_train, y_train)
# 预测,并还原结果
x = np.array(((gm11_data[feature] - data_mean[feature]) / data_std[feature]))
gm11_data['y_pred'] = linearsvr.predict(x) * data_std['y'] + data_mean['y']
# SVR预测后保存的结果
gm11_data.to_csv('../tmp/new_reg_data_GM11_revenue.csv')
print('真实值与预测值分别为:\n', gm11_data[['y', 'y_pred']])
print('可解释方差值:',
explained_variance_score(gm11_data['y'][:-2], gm11_data['y_pred'][:-2]))
print('平均绝对误差:',
mean_absolute_error(gm11_data['y'][:-2], gm11_data['y_pred'][:-2]))
print('中值绝对误差:',
median_absolute_error(gm11_data['y'][:-2], gm11_data['y_pred'][:-2]))
print('R2值:',
r2_score(gm11_data['y'][:-2], gm11_data['y_pred'][:-2]))
# 代码8-5
from pyecharts.charts import Grid
from pyecharts.charts import Scatter, Line
from pyecharts import options as opts
# 设置x轴的值
x_data = ['2005', '2006', '2007', '2008', '2009', '2010',
'2011', '2012', '2013', '2014', '2015', '2016',
'2017', '2018', '2019', '2020', '2021']
# 绘制线
line = (Line(init_opts=opts.InitOpts(width='800px', height='310px'))
# 设置x轴
.add_xaxis(x_data)
# 真实值的线
.add_yaxis('真实值', gm11_data['y'].tolist(),
label_opts=opts.LabelOpts(is_show=False))
# 预测值的线
.add_yaxis('预测值', gm11_data['y_pred'].tolist(),
label_opts=opts.LabelOpts(is_show=False))
)
# 绘制点
scatter = (
Scatter(init_opts=opts.InitOpts(width='800px', height='310px'))
.add_xaxis(x_data)
# 真实值的点
.add_yaxis('真实值', gm11_data['y'].tolist(),
label_opts=opts.LabelOpts(is_show=False),
symbol_size=10, symbol='diamond')
# 预测值的点
.add_yaxis('预测值', gm11_data['y_pred'].tolist(),
label_opts=opts.LabelOpts(is_show=False),
symbol_size=10, symbol='pin')
# 标题
.set_global_opts(
title_opts=opts.TitleOpts(title='真实值与预测值对比'),
yaxis_opts=opts.AxisOpts(name='企业所得税(万元)',
name_location='middle',
name_gap=70),
xaxis_opts=opts.AxisOpts(name='年份',
name_location='middle',
name_gap=30),
)
)
# 叠加图
scatter.overlap(line)
grid=Grid()
# 修改相对位置
grid.add(scatter, grid_opts=opts.GridOpts(pos_top='10%', pos_left='12%',
pos_bottom='35%'))
grid.render('../tmp/真实值与预测值对比.html')
四、数据及结果分析
从已有数据,可知道共有10个因素会影响企业所得税,需要计算各影响因素与目标特征之间的相关系数,进而判断企业所得税与选取特征之间的相关性。这里,我们计算10
特征间的Pearson相关系数,结果如下:
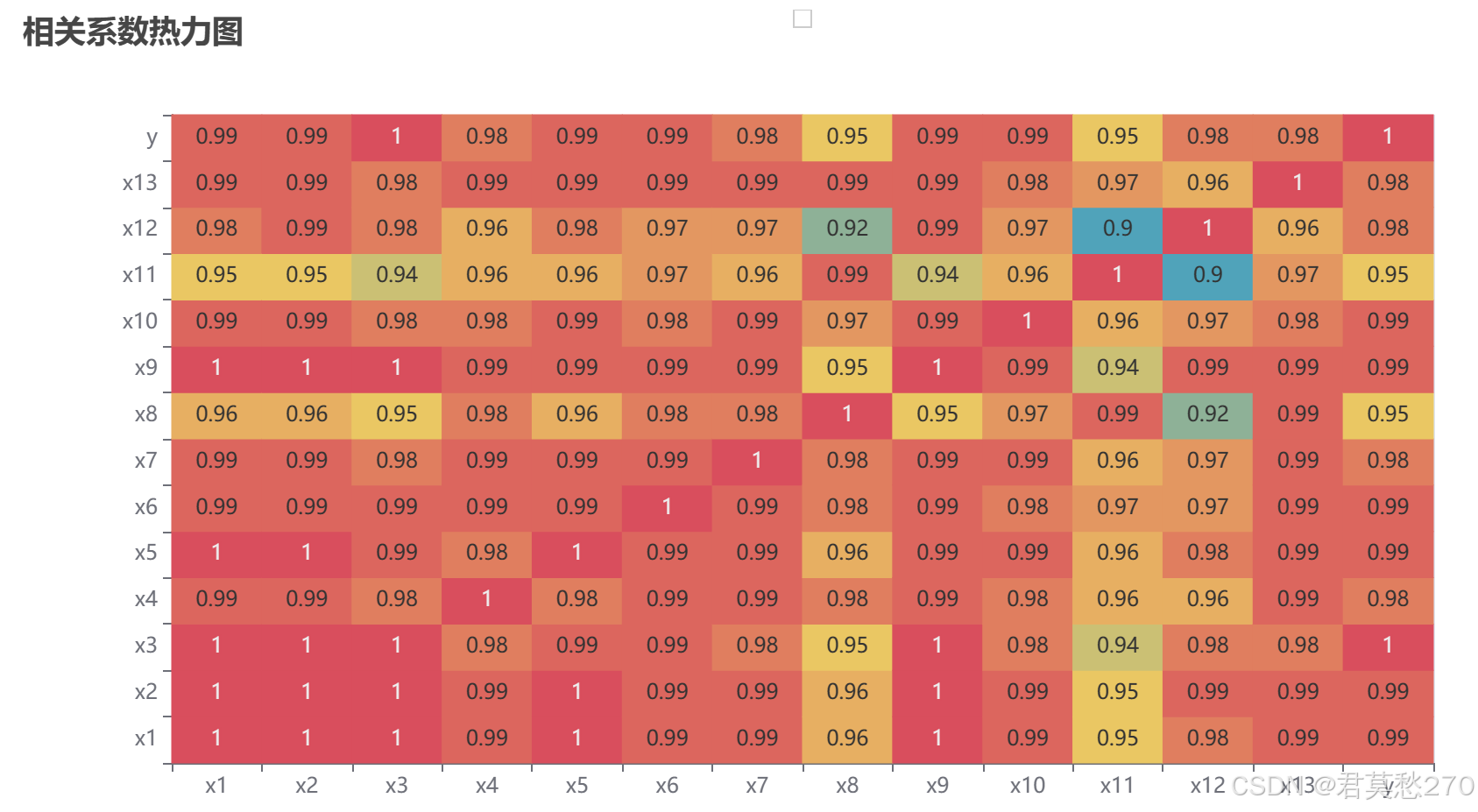
由上可知,x6与企业所得税(y)呈负相关关系,其余特征均与y呈正相关关系,且各个特征间存在严重的多重共线性,如x1,x2,x3,x4,x7,x8,x10。因此,需要对这些特征进行进一步筛选,避免信息重复。
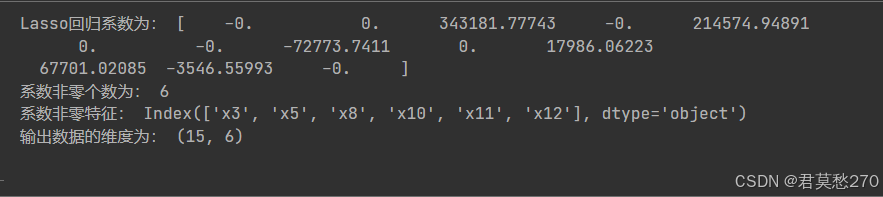
Lasso回归方法属于正则化方法的一种,是一种收缩估计方法,它可以将特征的系数进行压缩并使某些回归系数变为0,从而达到特征选择的目的。Lasso对数据类型没有太多限制,一般不需要对数据进行标准化处理,可以有效的解决多重共线性问题,但它倾向于选择多个特征中的一个特征,会导致结果的不稳定性。本例中,多重共线性的问题较为严重,因此使用Lasso进行特征选择是一个恰当的方法。
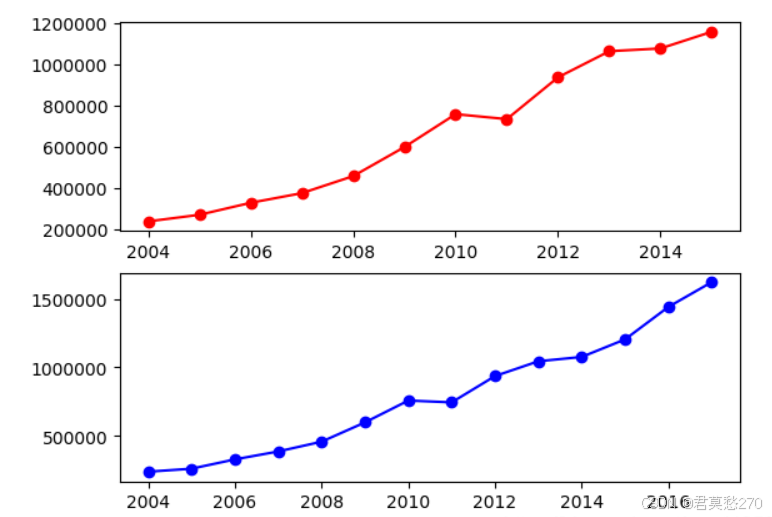
SVR(支持向量回归)不仅适用于线性模型,也能很好的抓住数据和特征之间的非线性关系,可避免局部最小问题,但计算复杂度较高,数据量大时,耗时较长。模型预测后,可通过R2值来判断模型效果,R2越接近1,表示模型拟合效果越好。
五、总结及心得体会
因为之前学习python课程的时候,其实已经完成对于python这个算法的简单入门了,也就是说学习利用python进行数据分析的基本过程前已经算是对这门语言入门了. 而我们知道进入一个新的领域最难的往往就在于开头。因为学习新领域就要不断的遇到挫折和失败,这对于很多在自己擅长领域已经做的不错的人来说是个极大的挑战。本书围绕三个库进行讨论——numpy,pandas和matplotlib。Numpy是个模仿R的库,对python的独特的数组进行向量操作——将数组作为矩阵进行切片,换行,变换,转置,计算等一系列操作。Numpy的强大之处建立在python的天生优势——一切皆对象的基础之上,这也正是numpy的强大——一切皆数组(矩阵)。所以numpy是未来python做SVD,SVM等机械学习的基础——变量矩阵化。
六、主要参考书
[1] Lee Vaughan Python编程实战.人民邮电出版社 2021
[2] 曾文权,张良均.Python数据分析与应用.人民邮电出版社,2021
[3] 董付国,Python程序设计基础(第2版),清华大学出版社 2021

















 1077
1077

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









