







目录
前言
接下来要学习模型评价与优化得,来提升模型
一、过拟合和欠拟合
(一)引入
任务:
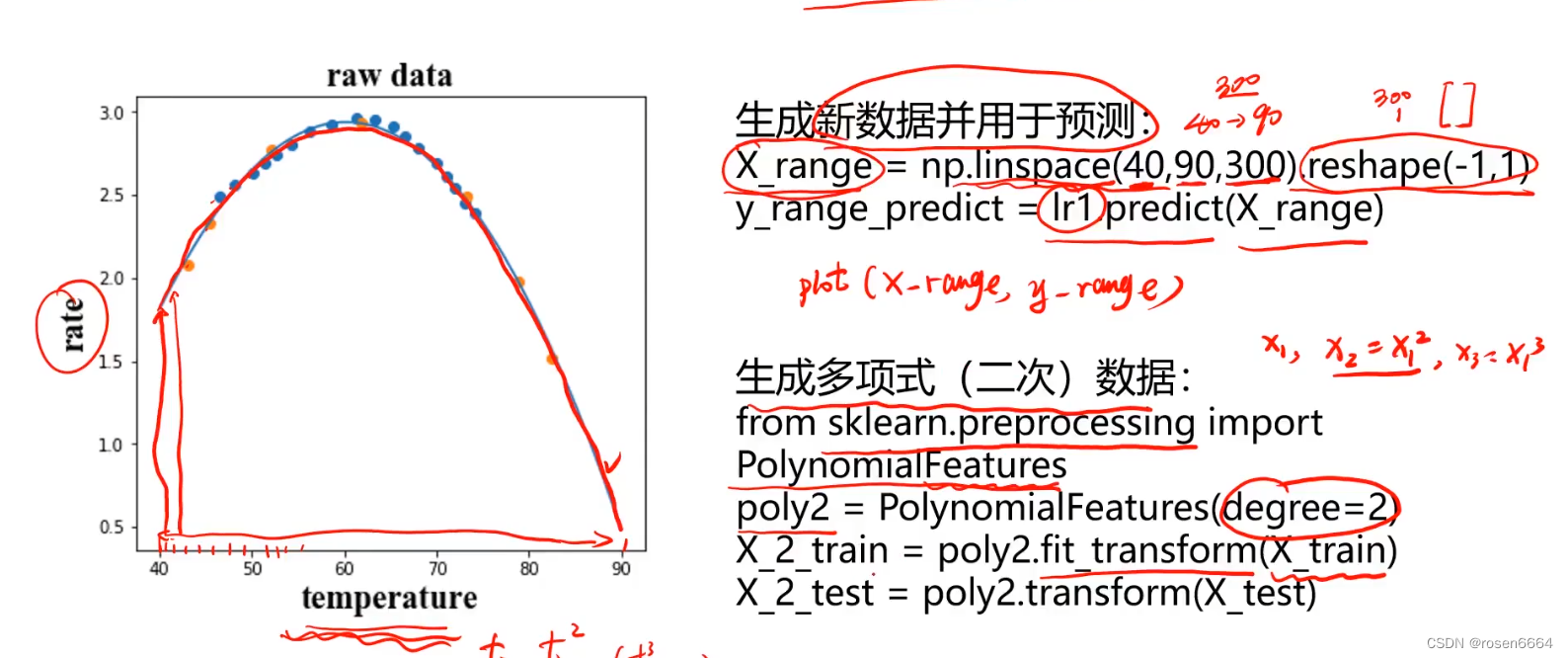
拟合反应速率与温度数据,预测85摄氏度时得反应速率
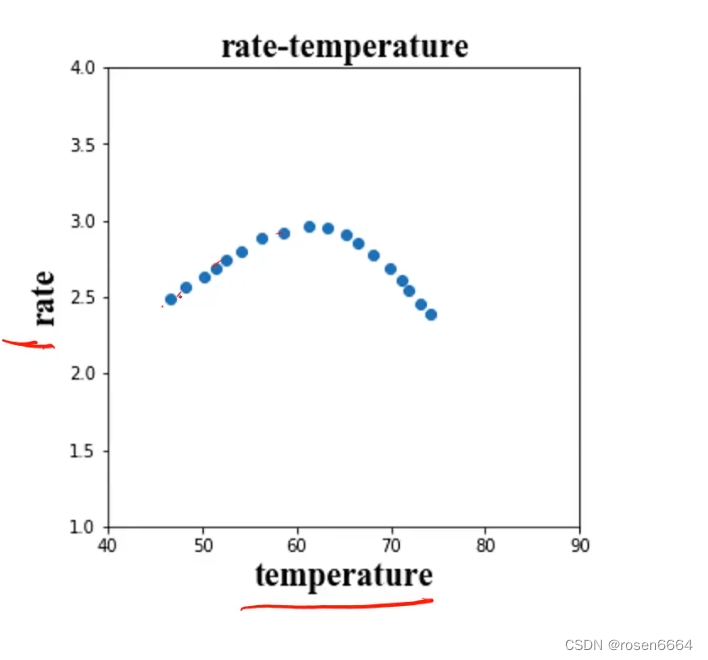
因为不是线性的,所以是多项式回归,二次的回归
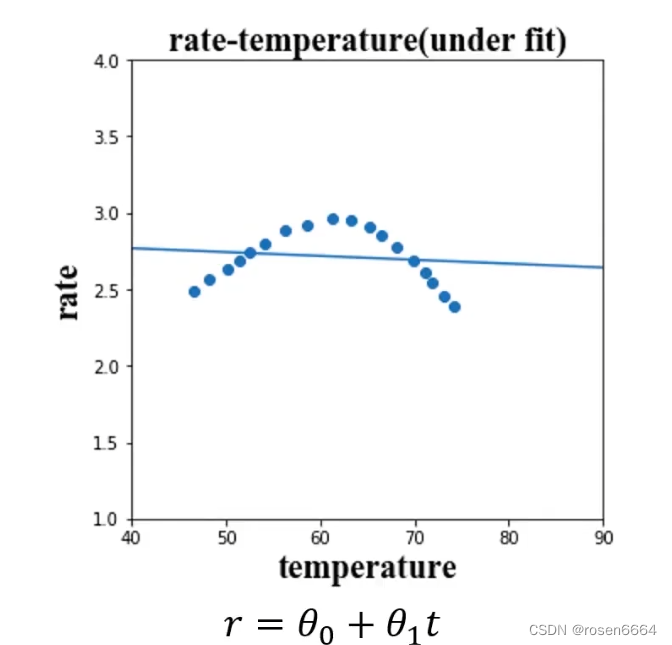
开始不知道,所以尝试用线性回归。
但是如果这个曲线继续下降下去,距离就会越来越远,欠拟合。
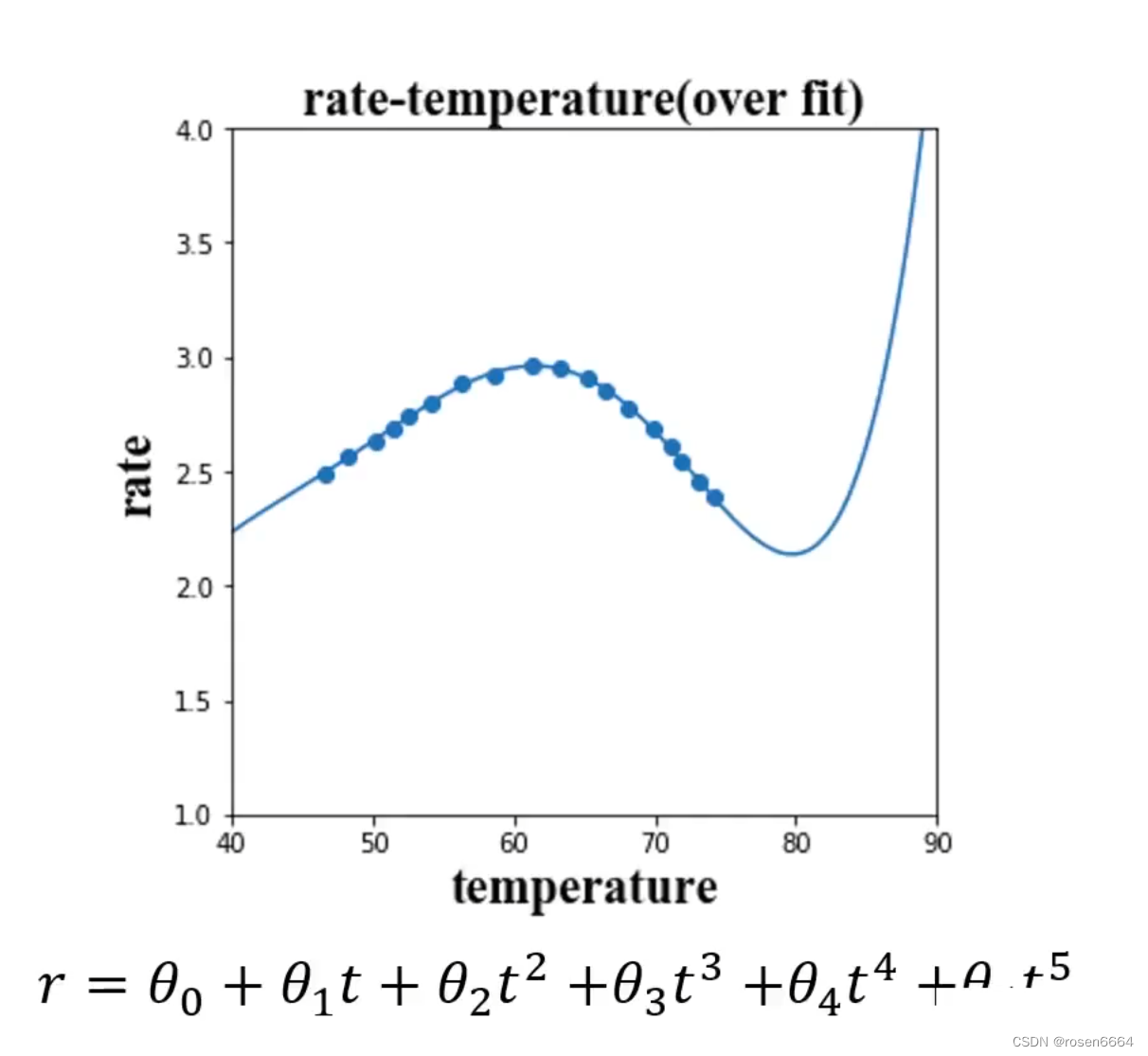
过拟合,发现数据开始拟合的很好啊,但是超出数据的范围不对啊,应该往下啊,怎么上升了?
(二)欠拟合与过拟合
模型不合适,导致其无法对数据实现有效预测 。
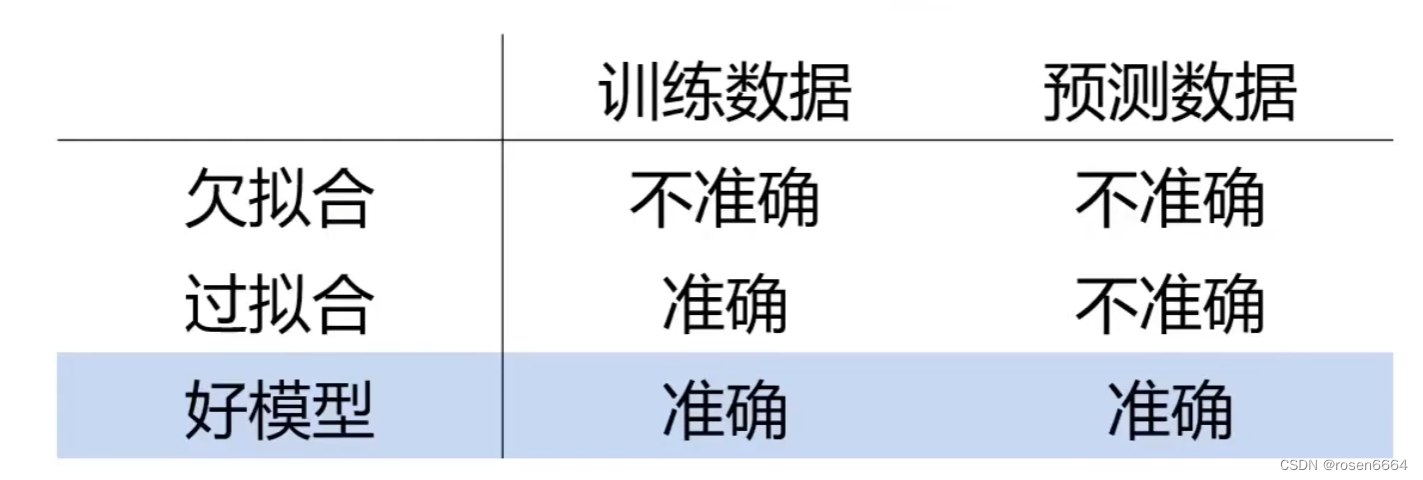
欠拟合可以通过观察训练数据及时发现,通过优化模型结果解决
过拟合可能看不出来,要用其他方法
(三)过拟合
原因
模型结构过于复杂(维度过高)
使用了过多属性,模型训练时包含了干扰信息
解决办法
简化模型结构(使用低阶模型,比如线性模型)
在数据预处理,保留主成分信息(数据PCA处理)
在模型训练时,增加正则化项
增加正则化项
以前要最小化损失函数

在原来基础上又加上了一项

二、数据分离

如果全部用来训练模型,那没有数据来评估数据那怎么办啊
对全数据分离,部分用于训练,部分用来评估

具体代码

三、混淆矩阵
最后模型评估是通过尊亲率来评估模型的表现。
局限性:无法真实反映模型针对各个分类的预测准确度

混淆矩阵,又称为误差矩阵,用于衡量分类算法的准确程度
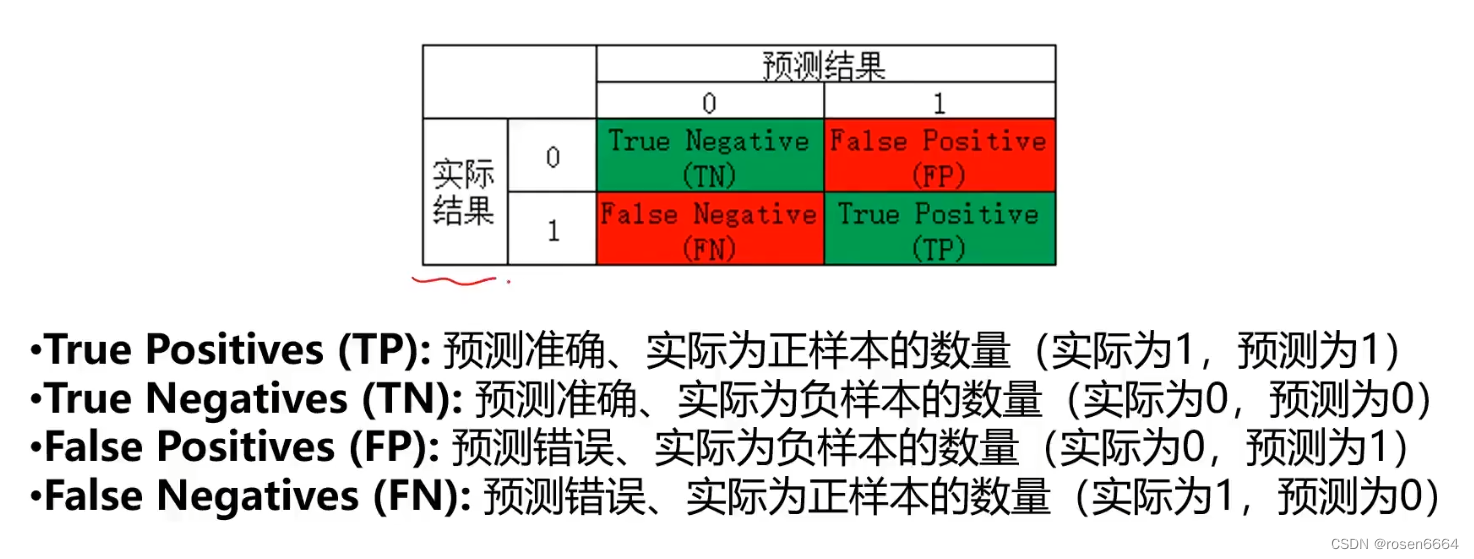
而且也有很多模型评估参数
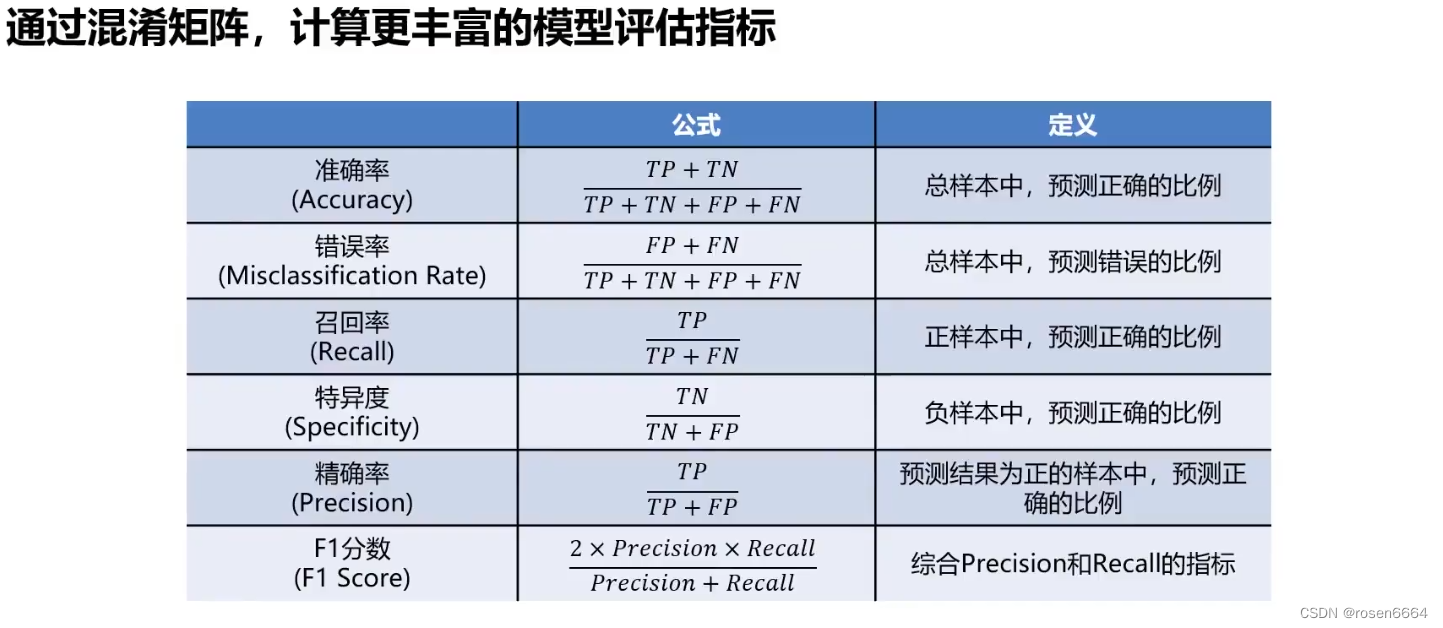
混淆矩阵的特点

没有说那个指标更加重要,要看是在哪个场景中
具体代码


四、模型优化
前面两个都是评估模型,接下来要说怎么优化了
问题1.用什么算法啊?
问题2:具体算法的模型参数怎么选择啊?
问题3:模型不好,怎么办
(一)保证数据质量
数据质量决定模型表现得上限
一些建议


(二)查找异常数据
通过可视化可以看到,但是高维度,就可以用高斯分布得方法去除
(三)确认数据维度是否可以减少
PCA方法,看可以去除维度不
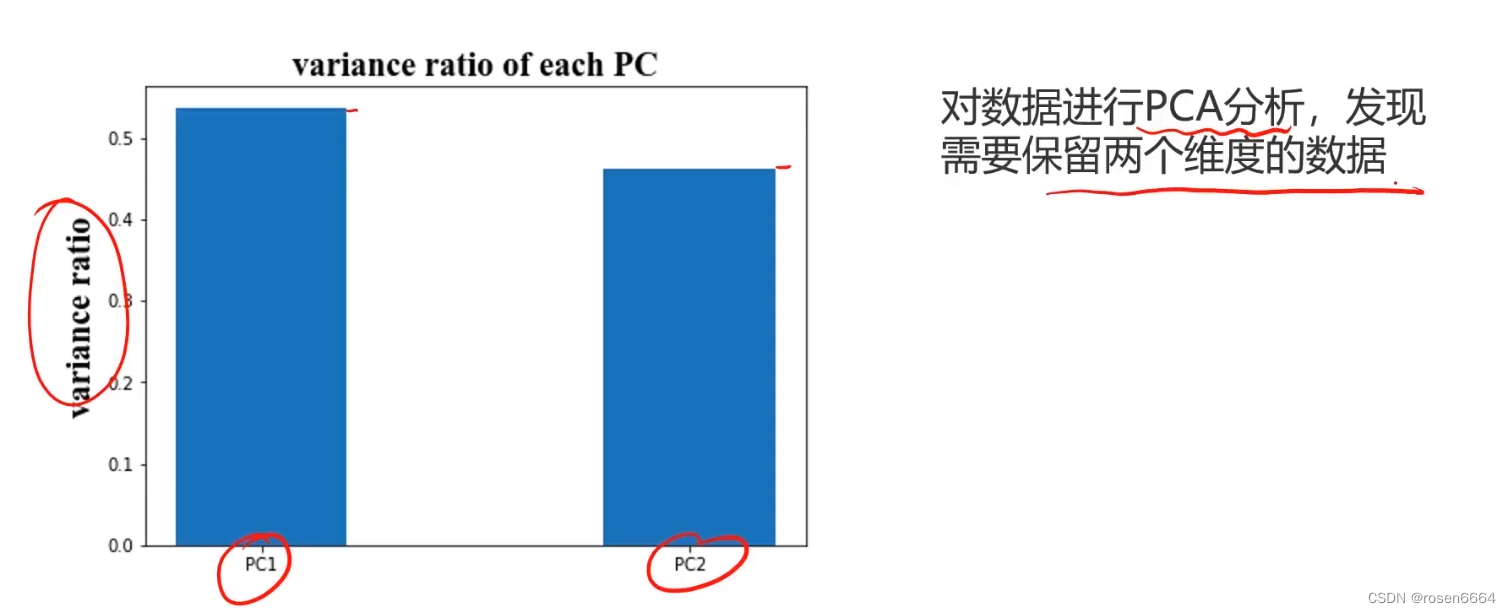
(四)尝试不同模型
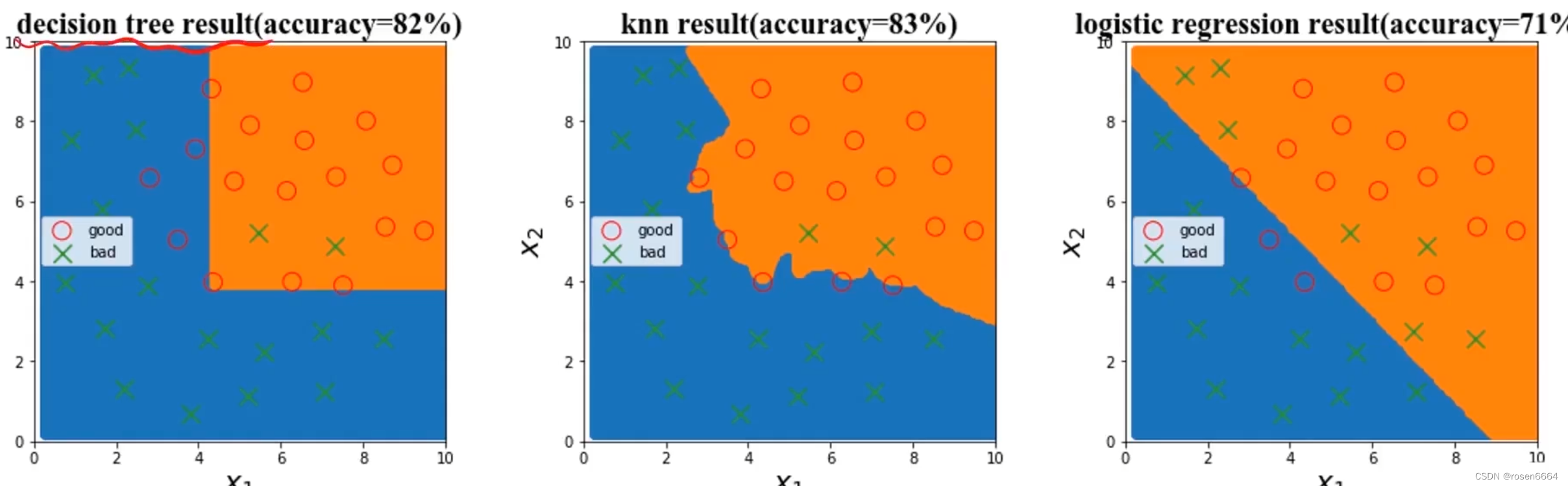
(五)优化模型

五、实现代码
1.生成新数据并用于预测
40到90,300个数据点,快速形成二阶得,就不用开始X1*X1了,degree就是几次方
2.生成决策数据
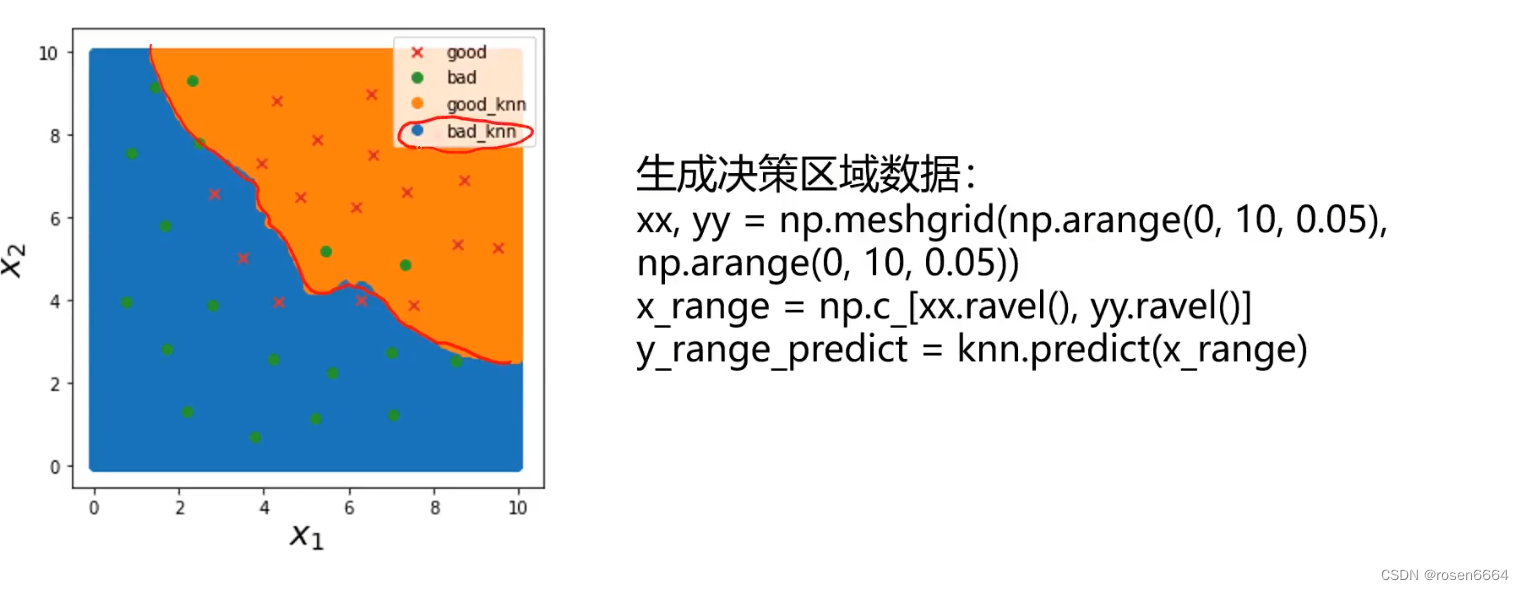

















 1632
1632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











