






hardmax
a = np.array([1, 2, 3, 4, 5]) # 创建ndarray数组
a_max = np.max(a)hardmax最大的特点就是只选出其中一个最大的值,即非黑即白。但是往往在实际中这种方式是不合情理的,比如对于文本分类来说,一篇文章或多或少包含着各种主题信息,我们更期望得到文章对于每个可能的文本类别的概率值(置信度),可以简单理解成属于对应类别的可信度。所以此时用到了soft的概念。
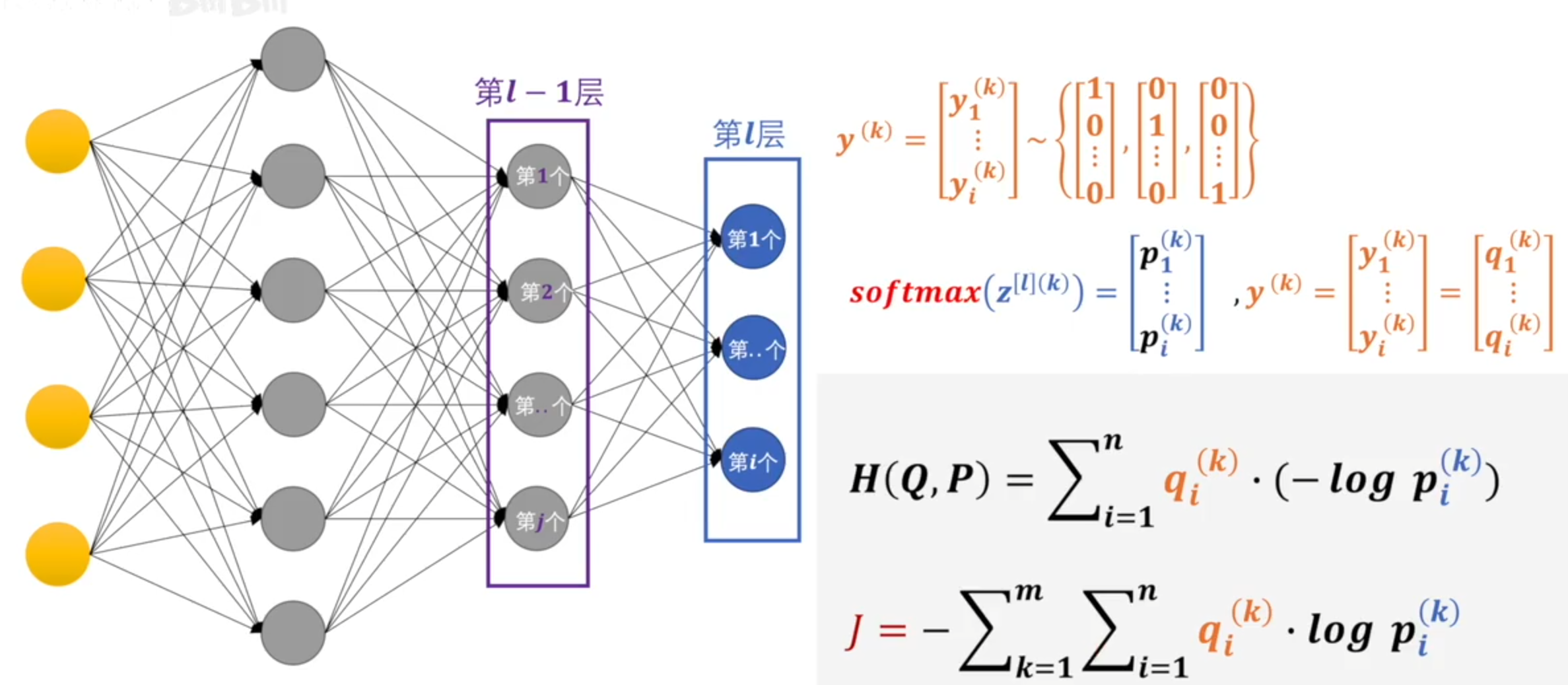
Softmax的含义就在于不再唯一的确定某一个最大值,而是为每个输出分类的结果都赋予一个概率值,表示属于每个类别的可能性。

这里需要注意一下,当使用Softmax函数作为输出节点的激活函数的时候,一般使用交叉熵作为损失函数。由于Softmax函数的数值计算过程中,很容易因为输出节点的输出值比较大而发生数值溢出的现象,在计算交叉熵的时候也可能会出现数值溢出的问题。为了数值计算的稳定性,TensorFlow提供了一个统一的接口,将Softmax与交叉熵损失函数同时实现,同时也处理了数值不稳定的异常,使用TensorFlow深度学习框架的时候,一般推荐使用这个统一的接口,避免分开使用Softmax函数与交叉熵损失函数。

分类问题都是计算交叉熵的。

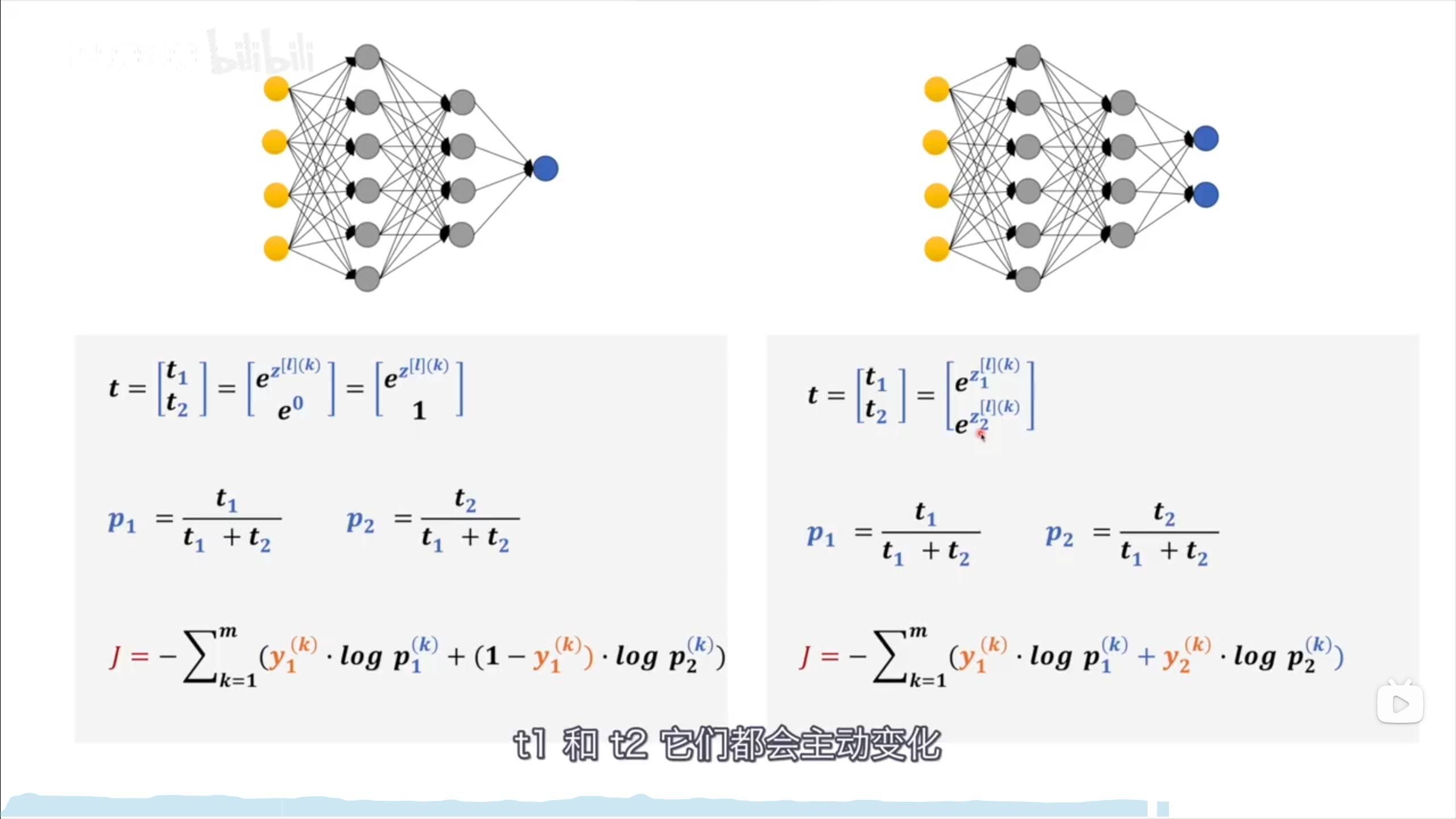
sigmoid相当于是一个是一个二分类的softmax
但它们的意义却不相同,举个例子:
sigmoid分别为是狗的概率和不是狗的概率的信息熵
softmax为是狗和是猫的概率的信息熵
虽然某种意义上,它们一样,但是意义却不相同。
Softmax函数求导

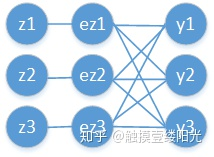


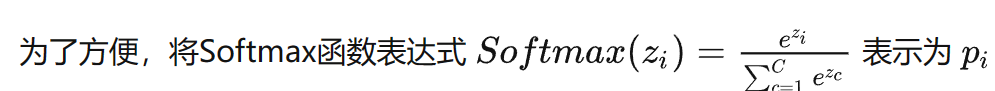
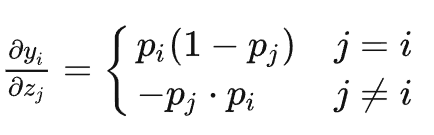

往往在真实中,如果只预测一个结果,那么在目标中只有一个结点的值为1,比如我认为在该状态下,我想要输出的是第四个动作(第四个结点),那么训练数据的输出就是a4 = 1,a5=0,a6=0,哎呀,这太好了,除了一个为1,其它都是0,那么所谓的求和符合,就是一个幌子,我可以去掉啦!
![]()
注意:log一般就指的ln
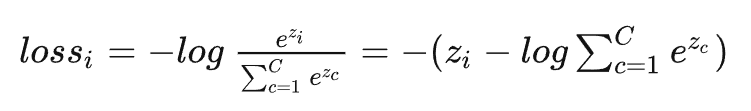
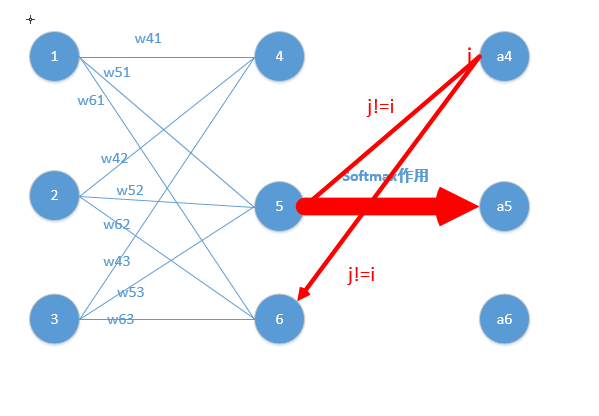
注意:上面的损失函数只针对正确类别的对应的输出节点,将这个位置的Softmax值最大化,而交叉熵则是直接衡量真实分布和实际输出的分布之间的距离。 one-hot那么就完全等价了。

接下来用交叉熵来求,更具有普遍性:
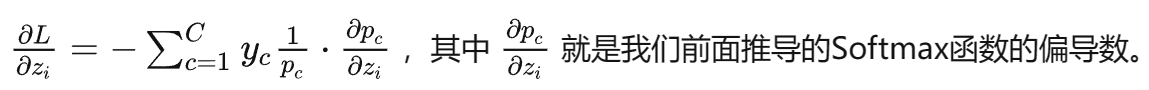
softmax偏导数左边那一串就是损失函数对softmax得到的概率求导,Yc是标签。
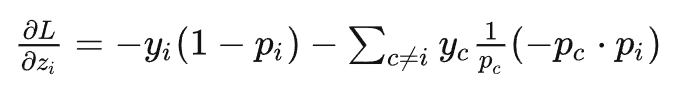
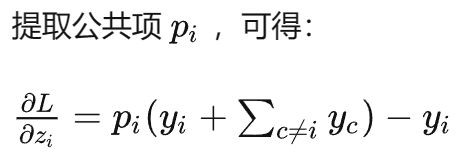
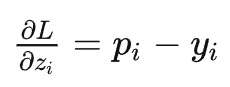
结果就出来了。 也就是softmax得到的概率—标签概率,非常简单















 341
341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









