






初始ES
什么是ES
elasticsearch是一款非常强大的开源搜索引擎,可以帮助我们从海量数据中快速找到需要的内容
elasticsearch结合kibana,Logstash,Beats,也就是elastic stack(ELK)。被广泛应用在日志数据分析,实时监控等领域。
elasticsearch是elastic stack的核心,负责存储,搜索,分析数据
正向索引和倒排索引
传统数据库(如MySQL)采用正向索引。
es采用倒排索引:
- 文档(document):每条数据就是一个文档
- 词条(term):文档按照语义分成的词语
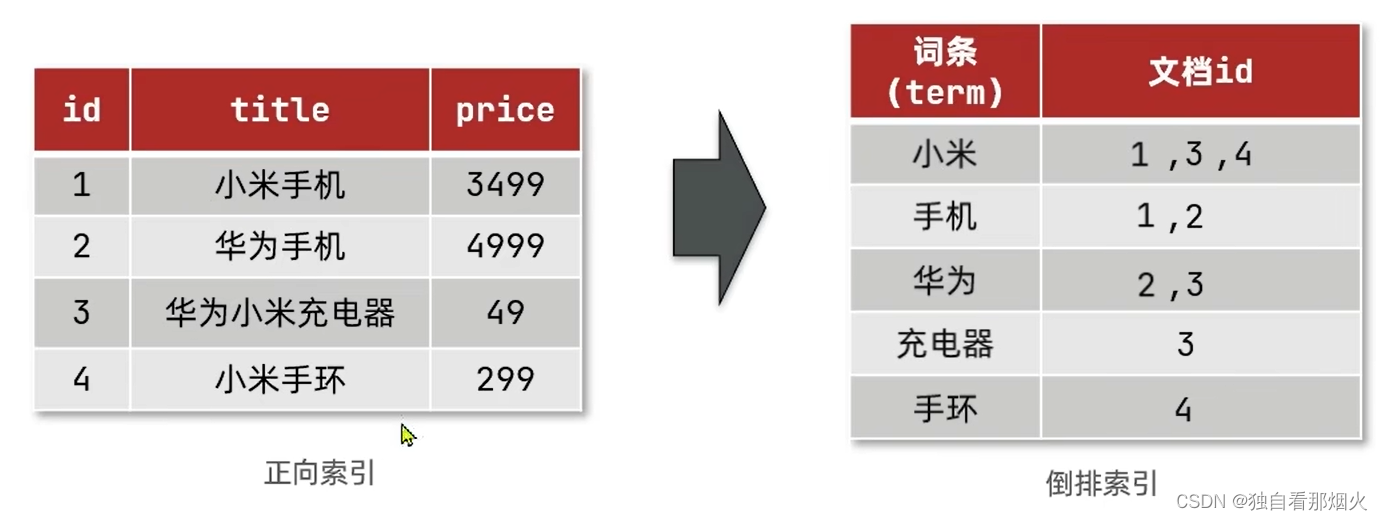
文档
es是面向文档存储的,可以是数据库中的一条商品数据,一个订单信息。文档数据会被序列化成json格式后存储在es中
索引
索引(index):相同类型的文档的集合
映射(mapping):索引中文档的字段约束信息,类似表的结构约束
概念对比
| MySQL | ES | 说明 |
|---|---|---|
| Table | Index | 索引(Index),就是文档的集合类似数据库的表(table) |
| Row | Document | 文档(Document’),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是es提供的JSON风格的请求语句,用来操作es,实现CRUD |
架构
MySQL:擅长事务类型操作,可以确保数据的安全和一致性
ES:擅长海量数据的搜索,分析,计算
索引库操作
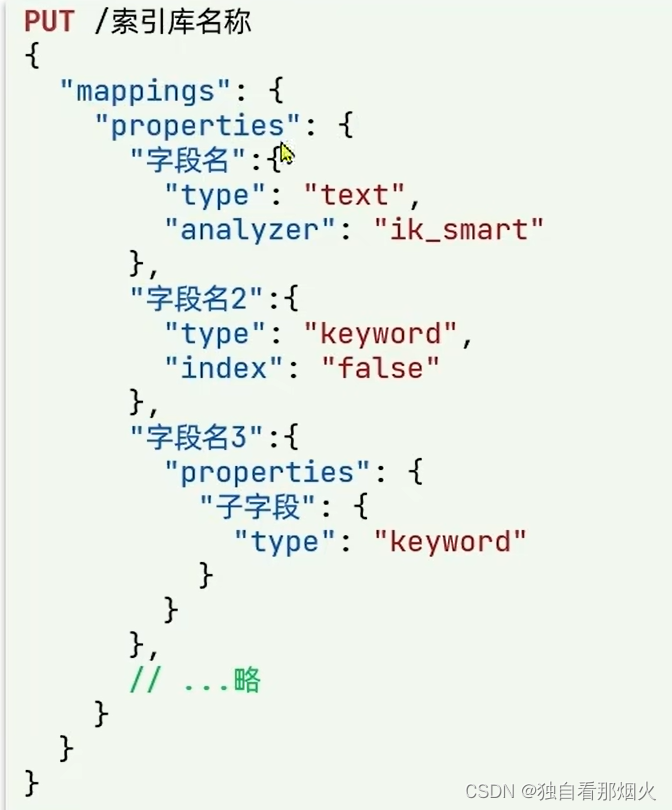
mapping映射
mapping是对索引库中文档的约束,常见的mapping属性包括:
- type:字段数据类型,常见的简单类型有:
- 字符串:text(可分词的文本)
- keyword(精确值,例如:品牌,国家,ip地址)
- 数值:long,integet,short,byte,double,float
- 布尔:boolean
- 日期:date
- 对象:object
- index:是否创建索引,默认味true
- analyzer:使用哪种分词器
- properties:该字段的子字段
创建索引库
ES中通过RESTful请求操作索引库,文档。请求内容用DSL语句来表示。创建索引库和mapping的DSL语法如下:

查看/删除索引库
查看索引库
GET /索引库名
删除索引库
DELETE /索引库名
修改索引库(只允许添加新的字段,不允许修改)
PUT /索引库名/_mapping
{
"properties":{
"新字段名":{
"type“:“integer”
}
}
}
文档操作
新增文档的DSL语法如下:
POST /索引库名/_doc/文档id
{
"字段1":"值1",
//....
}
查看/删除文档语法:
GET /索引库名/_doc/文档id
DELETE /索引库名/_doc/文档id
修改文档
方式一:全量修改,会删除旧文档,添加新文档
PUT /索引库名/_doc/文档id
{
"字段1":"值1"
//......
}
方式二:增量修改,修改指定字段值
POST /索引库名/_update/文档id
{
"doc":{
"字段名":"新的值"
}
}
RestClient操作索引库
什么是RestClient
ES官方提供了各种不同语言的客户端,用来操作ES。这些客户端的本质就是组装DSL语句,通过http请求发给ES。
操作索引库
public class test {
private RestHighLevelClient client;
@Test
void testInit(){
System.out.println(client);
}
@Test
void createHotelIndex() throws IOException {
// 1. 创建Request对象
CreateIndexRequest request = new CreateIndexRequest("hotel");
// 2.准备请求的参数:DSL语句
request.source("{\n" +
" \"mappings\": {\n" +
" \"properties\": {\n" +
" \"id\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"name\": {\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_max_word\"\n" +
" }\n" +
" }\n" +
" }\n" +
"}", XContentType.JSON);
// 3.发送请求
client.indices().create(request, RequestOptions.DEFAULT);
}
@Test
void testDeleteHotelIndex() throws IOException {
// 1. 创建Request对象
DeleteIndexRequest request = new DeleteIndexRequest("hotel");
// 2.发送请求
client.indices().delete(request, RequestOptions.DEFAULT);
}
@Test
void testExistHotelIndex() throws IOException {
// 1. 创建Request对象
GetIndexRequest request = new GetIndexRequest("hotel");
// 2.发送请求
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
// 3.输出
System.err.println(exists ? "索引库已经存在" : "索引库不存在");
}
@BeforeEach
void setUp(){
this.client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://101.35.251.74:9200")
));
}
@AfterEach
void tearDown() throws IOException {
this.client.close();
}
}
操作文档
public class DocumentTest {
private RestHighLevelClient client;
@Test
void testAddDocument() throws IOException {
Hotel hotel = new Hotel();
hotel.setId(1);
hotel.setName("测试酒店");
// 1.准备Request对象
IndexRequest request = new IndexRequest("hotel").id(hotel.getId().toString());
// 2.准备JSON文档
request.source(JSON.toJSONString(hotel), XContentType.JSON);
// 3.发送请求
client.index(request, RequestOptions.DEFAULT);
}
@Test
void testGetDocuemtById() throws IOException {
// 1.准备Request对象
GetRequest request = new GetRequest("hotel","1");
// 2.发送请求,得到结果
GetResponse response = client.get(request, RequestOptions.DEFAULT);
// 3.解析结果
String json = response.getSourceAsString();
Hotel hotel = JSON.parseObject(json, Hotel.class);
System.out.println(hotel);
}
@Test
void testUpdateDocumentById() throws IOException {
// 1.准备Request对象
UpdateRequest request = new UpdateRequest("hotel","1");
// 2.准备参数,每2个参数为一对key value
request.doc(
"name","测试酒店test"
);
// 3.更新文档
client.update(request, RequestOptions.DEFAULT);
}
@Test
void testDeleteDocument() throws IOException {
// 1.准备request对象
DeleteRequest request = new DeleteRequest("hotel","1");
// 2.发送请求
client.delete(request, RequestOptions.DEFAULT);
}
@Test
void testBulkRequest() throws IOException {
// 1.创建request
BulkRequest request = new BulkRequest();
// 2.准备参数,添加多个新增的Request
List<Hotel> list = new ArrayList<>();
Hotel hotel = new Hotel();
hotel.setId(1);
hotel.setName("测试酒店");
Hotel hotel1 = new Hotel();
hotel.setId(2);
hotel.setName("测试酒店2");
list.add(hotel);
list.add(hotel1);
for (Hotel hotelEntity : list){
request.add(new IndexRequest("hotel").id(hotelEntity.getId().toString()).source(JSON.toJSONString(hotelEntity), XContentType.JSON));
}
// 3.发送请求
client.bulk(request, RequestOptions.DEFAULT);
}
@BeforeEach
void setUp(){
this.client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://101.35.251.74:9200")
));
}
@AfterEach
void tearDown() throws IOException {
this.client.close();
}
}
DSL查询语法
DSL Query的分类
ES提供了基于JSON的DSL(Domain Specfic Language)来定义查询。常见的查询类型包括:
- 查询所有:查询出所有数据,一般测试用。例如:match_all
- 全文检索(full text)查询:利用分词器和用户输入内容分词,然后去倒排索引库中匹配。例如:match_query,multi_match_query
- 精确查询:根据精确词条值查询数据,一般是查找keyword,数值,日期,boolean等类型字段。例如:ids,range,term
- 地理(geo)查询:根据经纬度查询。例如:geo_distance,geo_bounding_box
- 复合(compound)查询:复合查询可以将上述各种查询条件组合起来,合并查询条件。例如:bool,function_score
全文检索查询
全文检索查询,会对用户输入内容进行分词,常用语搜索框搜索:
- match查询:全文检索查询的一种,会对用户输入的内容分词,然后去倒排索引库检索,语法:

- multi_match:与match查询类似,只不过允许同时查询多个字段,语法:

精确查询
精确查询一般是查找keyword,数值,日期,boolean等类型字段。所以不会对搜索条件分词。常见的有:
-
term:根据词条精确值查询

-
range:根据值的范围查询

地理查询
根据经纬度查询,例如:
- geo_boundin_box

- geo_distance:查询到指定地点小于某个距离值的所有文档

复合查询
复合(compound)查询:复合查询可以将其他的简单查询组合起来,实现更复杂的搜索逻辑,例如:
- function score:算分函数查询,可以控制文档相关性算分,控制文档排名。
- boolean query:布尔查询是一个或多个查询子句的组合。子查询的组合方式有:
- must:必须匹配每个子查询,类似“与”
- should:选择性匹配查询,类似“或”
- must_not:必须不匹配,不参与算分,类似“非”
- filter:必须匹配,不参与算分
搜索结果处理
排序
ES支持对搜索结果排序,默认是根据相关度算分(_score)来排序。可以排序字段类型有:keyword类型,数值类型,地理坐标类型,日期类型等。
分页
ES默认情况下只返回top10的数据。而如果要查询更多数据就需要修改分页参数了。
ES中通过修改from,size参数来控制要返回的分页结果:
深度分页问题
ES是分布式的,所以会面临深度分页问题。
如果搜索页数过深,或者结果集(from+size)越大,对内存和CPU的消耗也越高。因此ES设定结果集查询的上线是10000
针对深度分页,ES提供了两种解决方案:
- search after:分页时需要排序,原理是从上一次的排序值开始,查询下一页的数据。官方推荐使用的方式
- scroll:原理将排序数据形成快照,保存在内存,官方已经不推荐使用
高亮
高亮:就是在搜索结果中把关键字突出显示
原理是这样的:
- 将搜索结果中的关键字用标签标记出来
- 在页面中的标签添加CSS样式
语法:

RestClient查询文档
public class HotelSearchTest {
private RestHighLevelClient client;
@Test
void testMatchAll() throws IOException {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
request.source().query(QueryBuilders.matchAllQuery());
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
handleResopnse(response);
}
@Test
void testMatch() throws IOException {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
request.source().query(QueryBuilders.matchQuery("name","测试"));
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
handleResopnse(response);
}
@Test
void testBool() throws IOException {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
// 2.1准备BooleanQuery
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
// 2.2 添加term
boolQuery.must(QueryBuilders.termQuery("name", "测试酒店"));
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
handleResopnse(response);
}
@Test
void testPageAndSort() throws IOException {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
request.source().query(QueryBuilders.matchAllQuery());
// 2.1 排序
request.source().sort("price", SortOrder.ASC);
// 2.2分页
request.source().from(0).size(5);
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
handleResopnse(response);
}
@Test
void testHighlight() throws IOException {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
request.source().query(QueryBuilders.matchQuery("name","酒店"));
request.source().highlighter(new HighlightBuilder().field("name").requireFieldMatch(false));
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
handleHighlightResopnse(response);
}
@BeforeEach
void setUp(){
this.client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://101.35.251.74:9200")
));
}
@AfterEach
void tearDown() throws IOException {
this.client.close();
}
void handleResopnse(SearchResponse response){
// 4.解析结果
SearchHits searchHits = response.getHits();
// 4.1查询的总条数
long value = searchHits.getTotalHits().value;
System.out.println("总条数:" + value);
// 4.2文档数据
SearchHit[] hits = searchHits.getHits();
// 4.3 遍历
for (SearchHit hit : hits) {
// 获取文档source
String json = hit.getSourceAsString();
// 反序列化
Hotel hotel = JSON.parseObject(json, Hotel.class);
System.out.println(hotel);
}
}
void handleHighlightResopnse(SearchResponse response){
// 4.解析结果
SearchHits searchHits = response.getHits();
// 4.1查询的总条数
long value = searchHits.getTotalHits().value;
System.out.println("总条数:" + value);
// 4.2文档数据
SearchHit[] hits = searchHits.getHits();
// 4.3 遍历
for (SearchHit hit : hits) {
// 获取文档source
String json = hit.getSourceAsString();
// 反序列化
Hotel hotel = JSON.parseObject(json, Hotel.class);
// 获取高亮结果
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
// 根据名字获取高亮结果
HighlightField highlightField = highlightFields.get("name");
// 获取高亮值
String name = highlightField.getFragments()[0].string();
// 覆盖非高亮结果
hotel.setName(name);
System.out.println(hotel);
}
}
}
聚合
聚合的分类
聚合(aggregations)可以实现对文档数据的统计,分析,运算。聚合常见的有三类:
- 桶(Bucket)聚合:用来对文档做分组
- TermAggregation:按照文档字段值分组
- Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
- 度量(Metric)聚合:用以计算一些值,比如:最大值。最小值,平均值等
- avg:求平均值
- max:求最大值
- min:求最小值
- Stats:同时求max,min,avg,sum等
- 管道(pipeline)聚合:其他聚合的结果为基础做聚合
DSL实现Bucket聚合
现在,我们要统计所有数据中的酒店品牌有几种,此时可以根据酒店品牌的名称做聚合
类型为term类型,DSL示例:

默认情况下,Bucket聚合会统计Bucket内的文档数量,记为_count,并且按照_count降序排序。
我们可以修改结果排序方式:

默认情况下,Bucket聚合是对索引库的所有文档做聚合,我们可以限定要聚合的文档范围,只要添加query条件即可:

DSL实现Metrics聚合
例如,我们要求获取每个品牌的用户评分的min,max,avg等值。
我们可以利用stats聚合:

RestAPI实现聚合
我们以品牌聚合为例,演示java的RestClient使用
@Test
void testAggregation() throws IOException {
// 1.准备request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
// 2.1 设置size
request.source().size(0);
// 2.2聚合
request.source().aggregation(AggregationBuilders.terms("brand").field("brand").size(20));
// 3.发出请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析结果
Aggregations aggregations = response.getAggregations();
// 4.1根据聚合名称获取聚合结果
Terms brandTerms = aggregations.get("brand");
// 获取buckets
List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();
for (Terms.Bucket bucket : buckets) {
String key = bucket.getKeyAsString();
System.out.println(key);
}
}
自动补全
自定义分词器
ES中的分词器(analyzer)的组成包含三部分:
- character filters:在tokenizer之前对文本进行处理。例如删除字符,替换字符
- tokenizer:将文本按照一定的规则切割成词条(term)。例如keyword,就是不分词;还有ik_smart
- tokenizer filter:将tokenizer输出的词条做进一步处理。例如大小写转换,同义词处理,拼音处理等。
我们可以在创建索引库时,通过settings来配置自定义的analyzer(分词器)

completion suggester查询
ES提供了completion suggester查询来实现自动补全功能。这个查询会匹配以用户输入内容开头的词条并返回。为了提高补全查询的效率,对于文档中字段的类型有一些约束:
- 参与补全查询的字段必须是completion类型
- 字段的内容一般是用来补全的多个词条形成的数组。

RestAPI
@Test
void testSuggest() throws IOException {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
request.source().suggest(new SuggestBuilder().addSuggestion(
"suggestion"
, SuggestBuilders.completionSuggestion("suggestion").prefix("cs").skipDuplicates(true).size(10)));
// 3.发起请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析结果
System.out.println(response);
Suggest suggest = response.getSuggest();
// 4.1 根据名称获取补全结果
CompletionSuggestion suggestion = suggest.getSuggestion("suggestion");
// 4.2 获取options并遍历
for (CompletionSuggestion.Entry.Option option : suggestion.getOptions()) {
// 4.3获取一个option中的text,也就是补全的词条
String text = option.getText().string();
System.out.println(text);
}
}
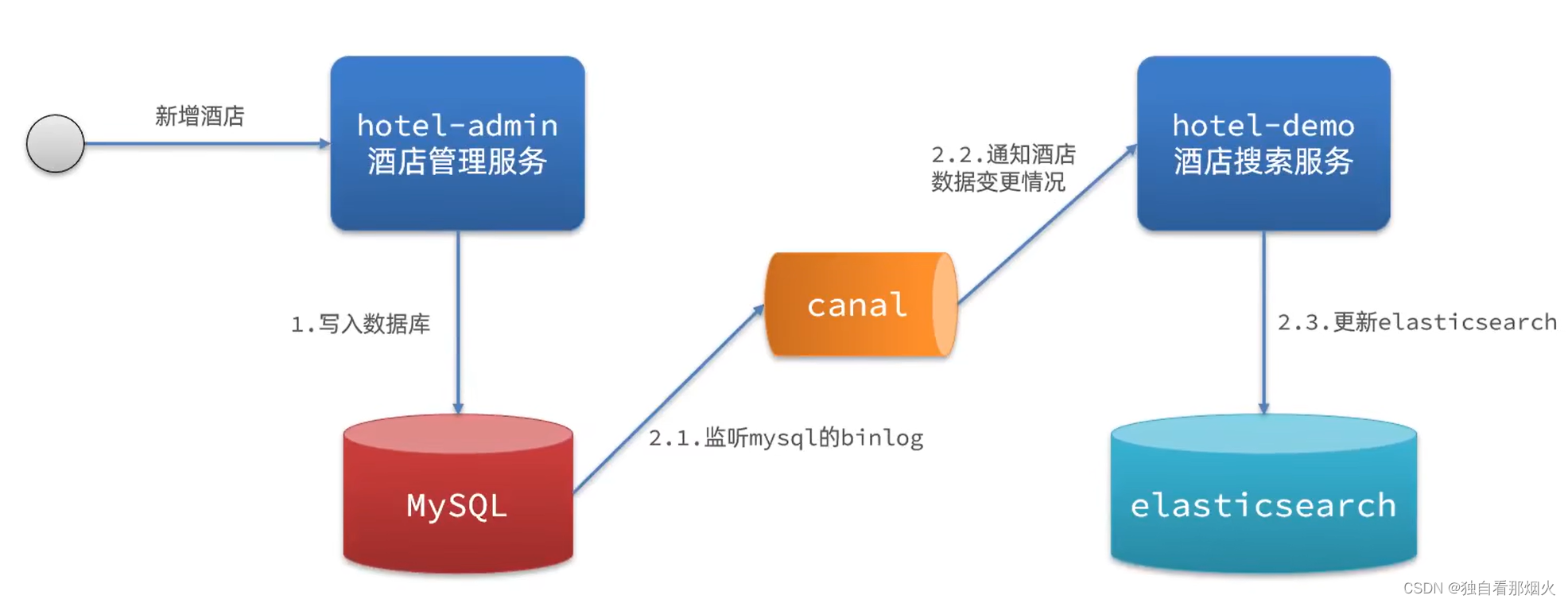
数据同步
问题分析
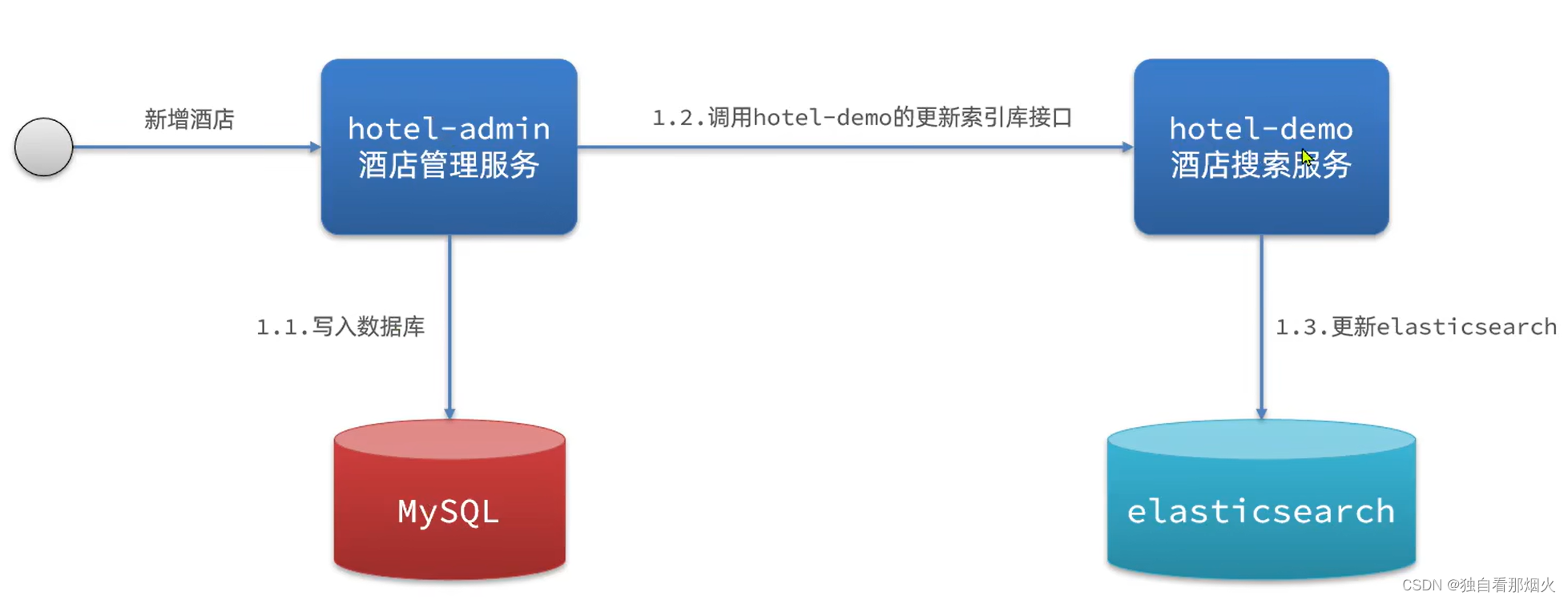
ES中的酒店数据来自于mysql数据库,因此mysql数据发生改变时,ES也必须跟着改变,这个就是ES与mysql之间的数据同步。
方案一:同步调用
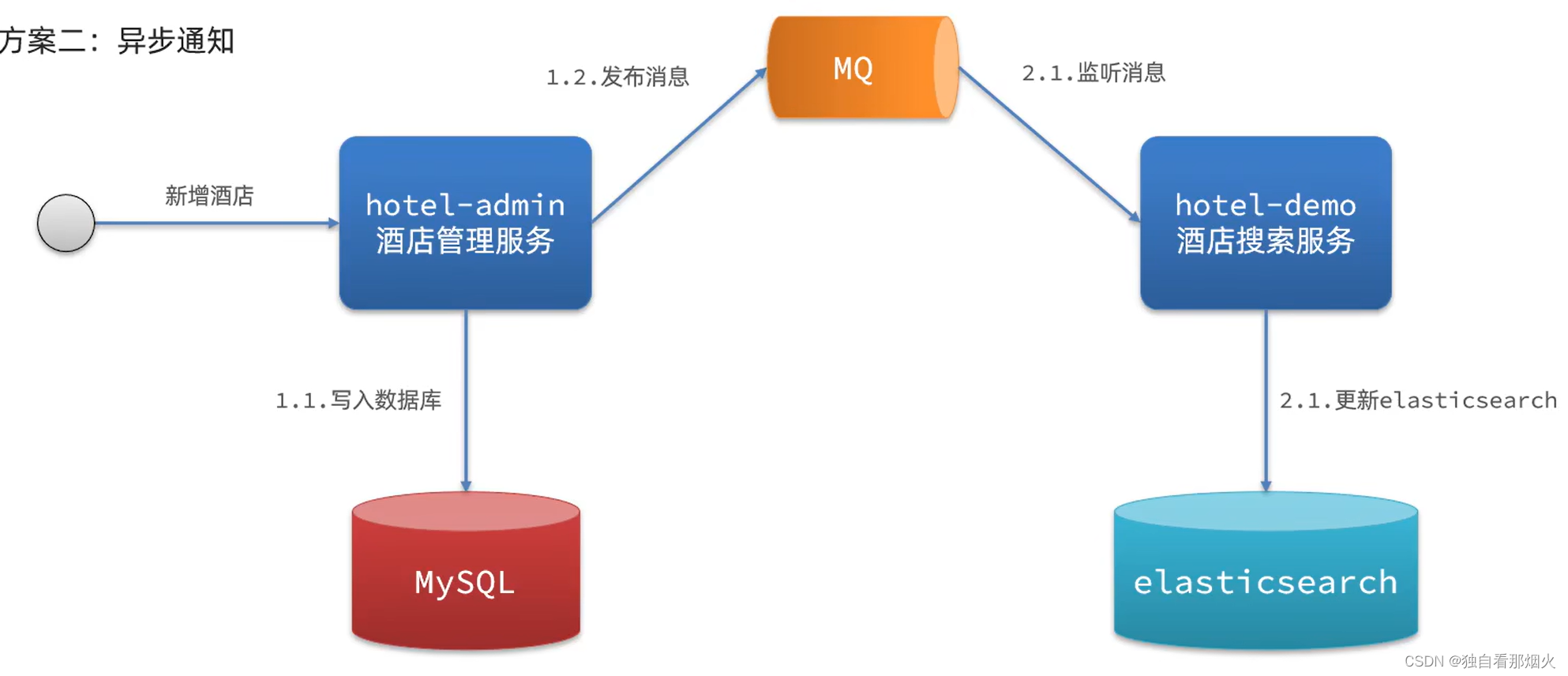
方案二:异步通知
方案三:监听binlog














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









