






 命名空间用于解决标识符名称冲突,提供了一种隔离全局作用域的方法。例如,`std::cin`和`std::cout`是C++中的输入输出流对象,用于从键盘读取数据和向控制台输出。在使用这些流时,需要包含`<iostream>`头文件并使用命名空间。此外,命名空间可以被展开或通过`using`声明来访问其内容。
命名空间用于解决标识符名称冲突,提供了一种隔离全局作用域的方法。例如,`std::cin`和`std::cout`是C++中的输入输出流对象,用于从键盘读取数据和向控制台输出。在使用这些流时,需要包含`<iostream>`头文件并使用命名空间。此外,命名空间可以被展开或通过`using`声明来访问其内容。
目录
1.为什么会需要命名空间?
在C语言中,因为变量、函数和后面的类都是大量存在的,这些变量、函数和类的名称将都存在于全局作用域中,可能会导致很多冲突。使用命名空间的目的是对标识符的名称进行本地化,以避免命名冲突或名字污染,namespace关键字的出现就是针对这种问题的。
在C语言中无法处理以下类似的问题
#include <stdio.h>
#include <stdlib.h>
int rand = 10;
int main()
{
printf("%d\n", rand);
return 0;
}运行后出现如下结果
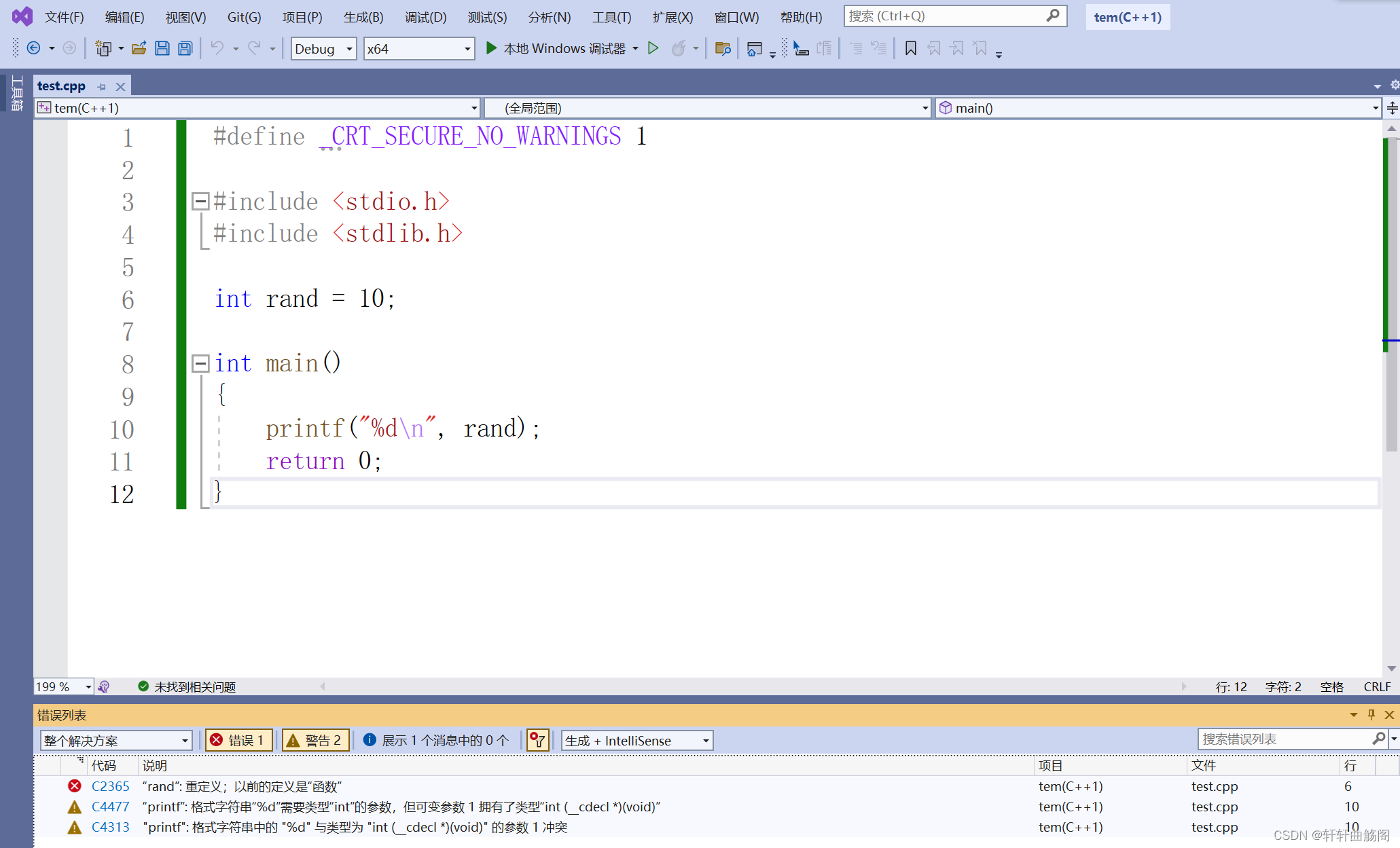
因此,C++采用namespace来解决此问题
2.命名空间的使用
下面我们来举一个最简单的例子
namespace xxqsg
{
int rand = 10;
int Add(int left, int right)
{
return left + right;
}
struct Node
{
struct Node* next;
int val;
};
}1.xxqsg是命名空间的名字
2.命名空间中可以定义变量/函数/类型
①域作用限定符::
当我们需要访问在不同域(域分为类域、命名空间域、局部域和全局域等)中相应的元素时,可以使用::来访问,如
int a = 0;
namespace xxqsg
{
int a = 10;
int Add(int left, int right)
{
return left + right;
}
struct Node
{
struct Node* next;
int val;
};
}
int main()
{
int a = 3;
printf("%d\n", a);
printf("%d\n", ::a);
printf("%d\n", xxqsg::a);
return 0;
}有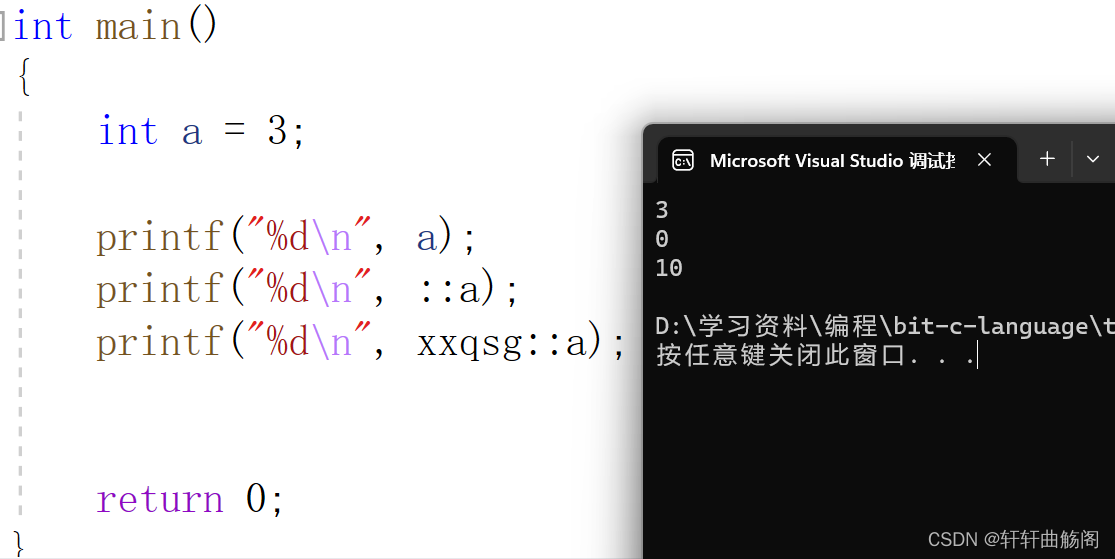
②命名空间域的展开
在使用变量时,程序搜索变量是有先后顺序的,一般来说是 局部域->全局域 -> 展开了命名空间域 or 指定访问命名空间域 且如果在全局中没有搜索到对应变量后,不会自动到命名空间域中去寻找,因此需要我们使用using namespace xxqsg手动展开,如下
namespace xxqsg
{
int a = 10;
int tmp = 20;
int Add(int left, int right)
{
return left + right;
}
struct Node
{
struct Node* next;
int val;
};
}
using namespace xxqsg;
int main()
{
int a = 3;
printf("%d\n", tmp);
return 0;
} 有如下结果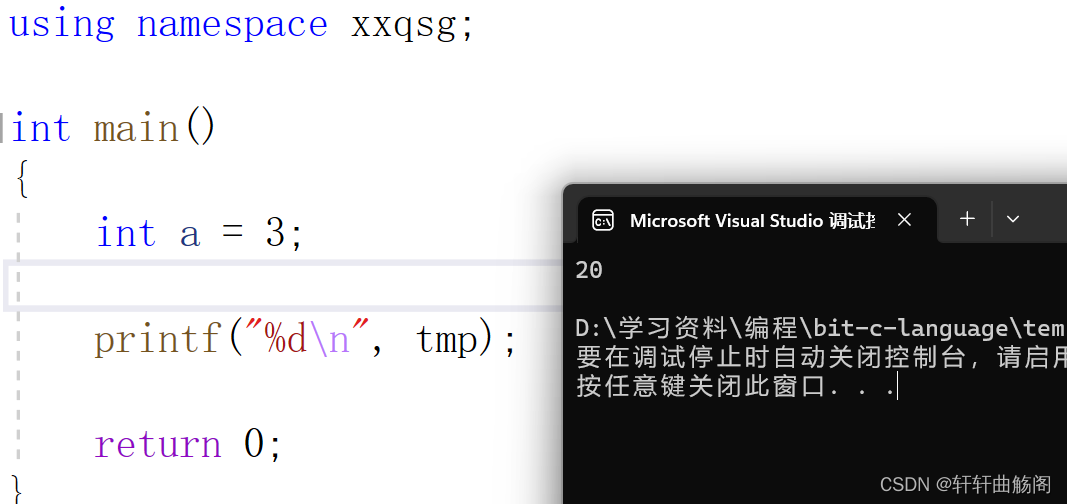
③命名空间内部的细节
命名空间内部可以进行嵌套,如
namespace N1
{
int a = 0;
int b = 1;
int Add(int left, int right)
{
return left + right;
}
namespace N2
{
int c = 3;
int d = 4;
int Sub(int left, int right)
{
return left - right;
}
}
}通过这样的方式进一步限制变量所在的域。
注:可以通过以下方式访问c
int main()
{
int a = 3;
printf("%d\n", N1::N2::c);
return 0;
}同一个工程中允许存在多个相同名称的命名空间,编译器最后会合成同一个命名空间中。如在A文件内名为namespace N定义了a元素,在B文件内也有名为namespace N定义了b元素,在最后运行时,系统会自动将它们合成在一起,因此如果使用了相同名字的变量则会报错。
④补充
如果我们在编写大型项目的后期时,发现了简单而低级的错误,如
#include <iostream>
int main()
{
cout << "hello world" << endl;
cout << "hello world" << endl;
cout << "hello world" << endl;
cout << "hello world" << endl;
cout << "hello world" << endl;
cout << "hello world" << endl;
cout << "hello world" << endl;
cout << "hello world" << endl;
cout << "hello world" << endl;
}在此代码中所有的cout与endl前没有std::因此无法使用,在此我们可以采用using将命名空间中某个成员引入,即
using std::cout;
using std::endl;3.输入输出流的形式与使用
①std::cin
举一个简单的例子
#include <iostream>
int main()
{
int a = 0;
double b = 3.1415926;
cin >> a >> b;
cout << a << ' ' << b << endl;
}其中,>>是流提取运算符,形象地表示提取输入的数据。
注:cin可以自动识别输入的类型,即
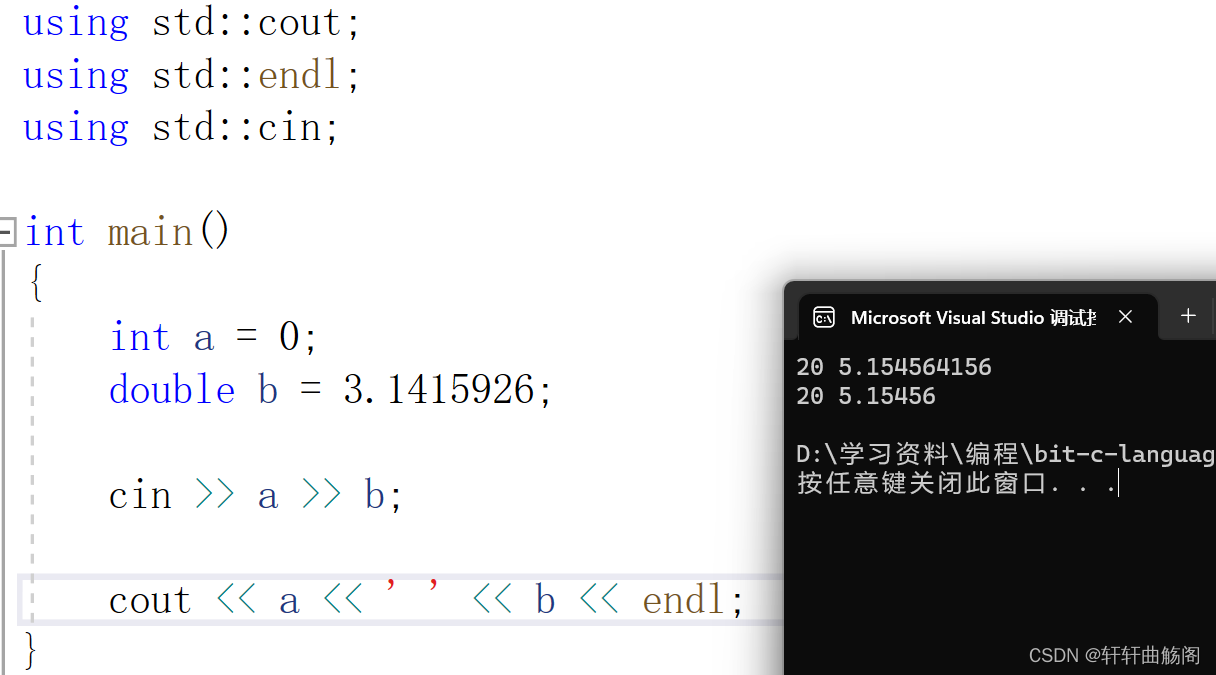
②std::cout
举一个简单的例子
#include <iostream>
int main()
{
int a = 0;
cout << "the value of a is " << a << endl;
}其中,<<是流插入运算符,形象的表示了数据的流出
注:cout与cin一样,可以自动识别数据类型,即
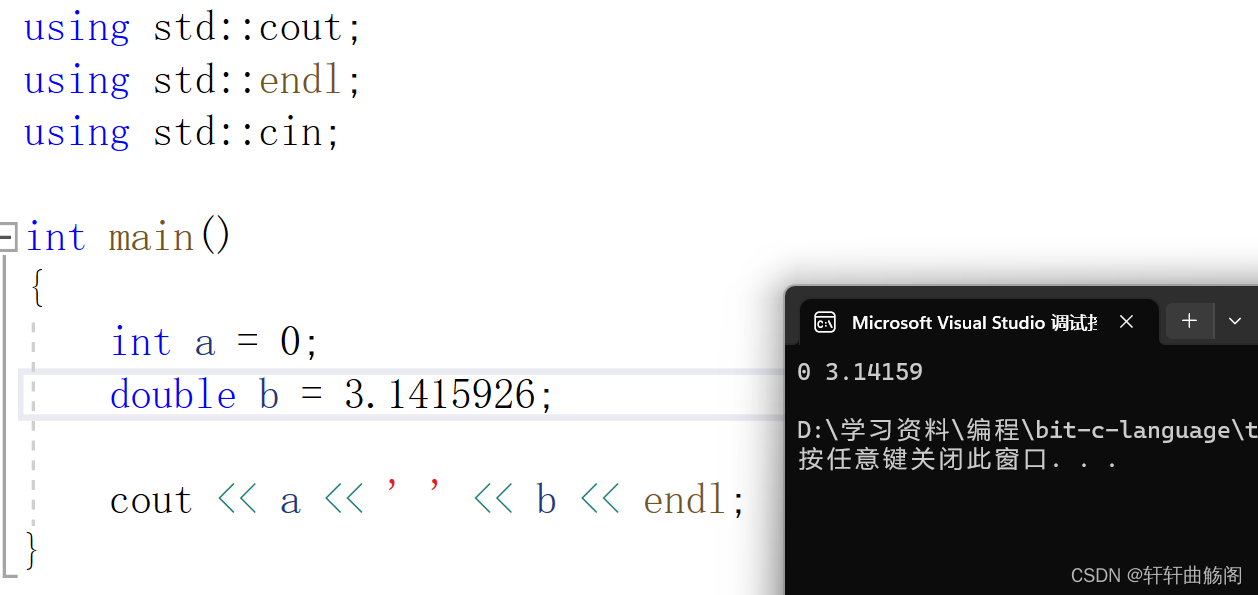
注意,cout控制浮点数精度很复杂,可以使用printf来控制精度,相对来说较为简单。
③补充
1. 使用 cout 标准输出对象 ( 控制台 ) 和 cin 标准输入对象 ( 键盘 ) 时,必须 包含 < iostream > 头文件 以及按命名空间使用方法使用std 。2. cout 和 cin 是全局的流对象, endl 是特殊的 C++ 符号,表示换行输出,他们都包含在包含 <iostream >头文件中。3. 使用 C++ 输入输出更方便,不需要像 printf/scanf 输入输出时那样,需要手动控制格式。C++的输入输出可以自动识别变量类型。4. 实际上 cout 和 cin 分别是 ostream 和 istream 类型的对象, >> 和 << 也涉及运算符重载等知识,这些知识我们后续会学习,所以我们这里只是简单学习他们的使用。

















 1113
1113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









