






1、数据库基本认知
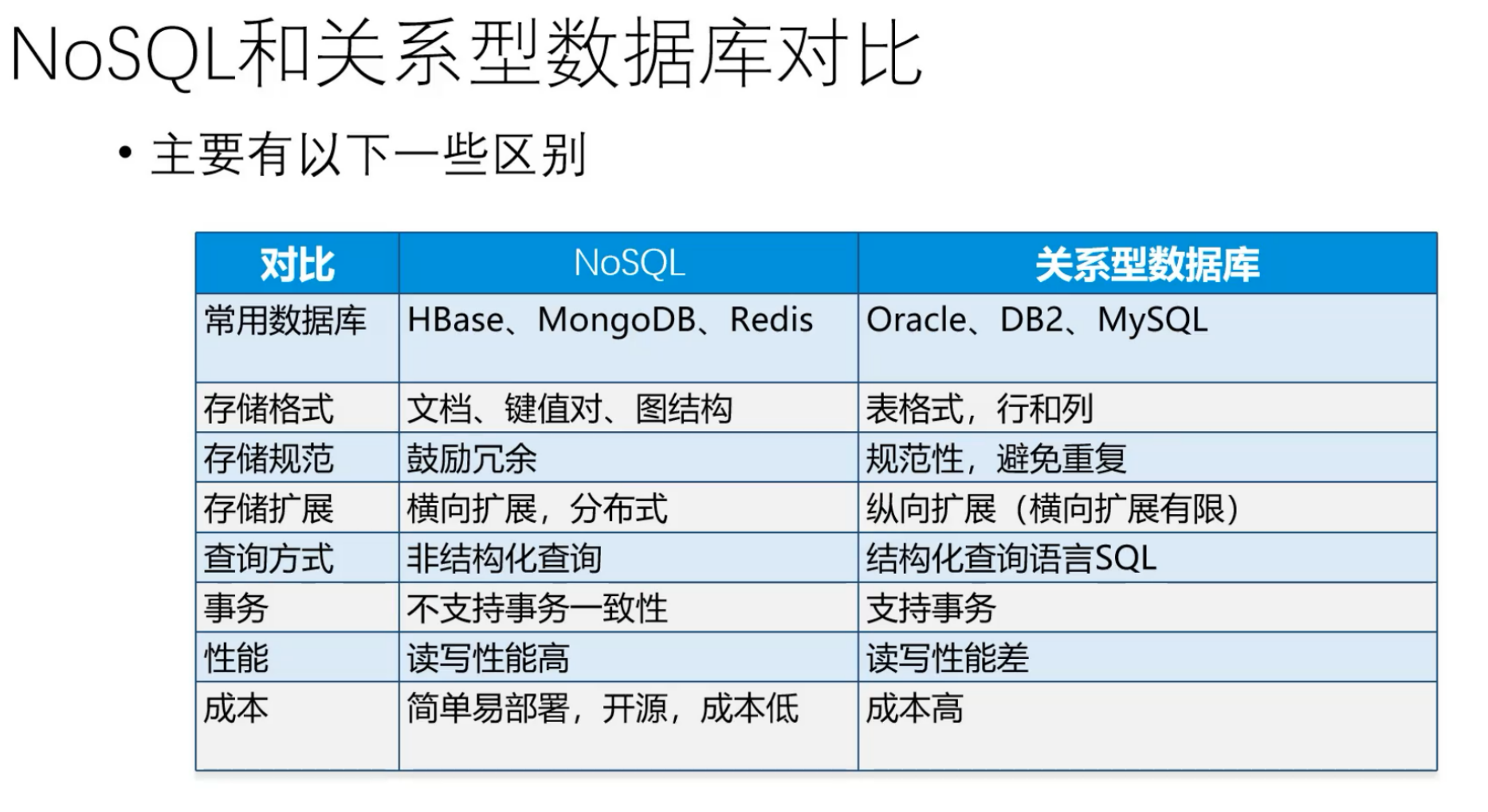
一:数据库分类
关系型数据库:SQL
主要有MySQL,Oracle,Sql Server等,其主要通过表与表之间,行与列之间的关系进行数据的存储。可以通过外键来建立表之间的关联。
非关系型数据库:NoSQL
主要有HBase,MongoDB等,其数据是非关系的,且不使用SQL作为主要的查询语言。
NoSQL与SQL之间的对比
二:MySQL介绍
Mysql是一个具体的关系型数据库管理系统(RDBMS),其支持使用SQL来进行数据的增删改查等操作。Mysql具有许多的优势,包括可移植性,安全性,可跨平台等,适用于各个规模的应用和项目。
三:MySQL基本概念
前言
此处所展示的是MySQL数据库基本的系统库
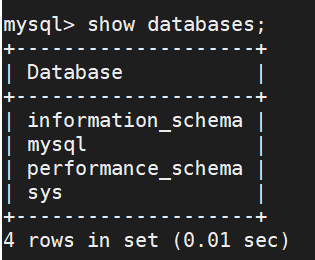
注意:当你初次打开MySQL服务时,会看见mysql,performance_schema,sys,information_schema这四个基本的系统库【不可进行删除修改等操作,即:不要动着四个系统库】。
基本理论
整个数据库的基本组成
【库】 => 表 => 字段(列) => (名字+数据类型+约束) => 数据
1:数据库(database)
数据库是按照数据结构来组织,存储和管理结构化数据的仓库,这些数据可以是文本、数字等。在MySQL中,一个数据库由多个表、视图等对象组成。
2:表(table)
表是数据库中的基本存储单元,用于存储数据。表由行(记录)和列(字段)组成。
3:字段(field)
字段是表中的一列,用于存储某一类型的数据。每个字段都有一个唯一的名称和数据类型,以及可能的其他属性(如默认值、是否允许为空等)。
4:数据(Data)
数据是实际存储在表中的内容或记录,是表的实例化的表现。
权限列表
##权限列表:
对象级别(库,表):
增:create
删:drop
改:alter
查:show
数据级别(表内的数据):
增:insert
删:delete | truncate
改:update
查:select
2、数据库的常规操作
DCL操作
何为DCL?
数据库控制语言,用于【设置或更改】数据库【用户或角色权限】的语言
DCL具体操作
A、*管理用户操作
【创建用户】
语法:create user '用户名'@'主机名' identified BY '密码';
案例:create user 'tang'@'localhost' identified by '123456';
注意点:
连接本地机时,主机名 => localhost
远程连接时,主机号 => %
【删除用户】
语法:drop user '用户名'@'主机名';
案例:drop user 'tang'@'localhost';
【获取当前登录用户者的信息】
语法:select current_user();
B、*权限操作
1.查看权限:
语法:show grants for '用户名'@'主机名'
案例:show grants for 'tang'@'localhost';
2.授予权限:
授予部分权利:
语法:grant 权限列表 on 数据库名.表名 to '用户名'@'主机名';
案例:grant create on yb.yb_score to 'tang'@'localhost';
授予全部权利:
语法:grant all on 数据库名.表名 to '用户名'@'主机名';
案例:grant all on yb.yb_score to 'tang'@'localhost';
3.撤销权限:
语法:remove 权限列表 on 数据库名.表名 from '用户名'@'主机名';
案例:revoke create on yb.yb_score from 'tang'@'localhost';
DDL操作(面向对象级别)
必备知识
1.数据类型
文本字符串类型:
char(N) | varchar(N) ✔ | text(N)
整数类型:
tinyint | smallint | int(N)/int ✔ | bigint
浮点类型:
float | double | money | numeric
定点数值类型:
decimal(m,n)【m:整数加小数的长度,即总长;n:精度】 ✔
位类型(boolean值):
bit【只有0(false)和1(true)】 ✔
日期时间类型:
date【年月日】 ✔ |time【时分秒】 ✔ | datetime ✔ | timestamp【自带默认值】 ✔
2.约束
目的:数据的完整性
1.类型
2.长度
3.是否允许为空:可以为空:NULL / 不可为空:not NULL
4.默认值:default 默认值[VALUE]
5.唯一键:unique key
6.主键(唯一且不能为空):primary key =>没有意义的字段做主键,以不变应万变
单一主键
组合主键
7.外键(从表中的外键引用主表中的主键,主外键的数据类型与约束必须一致):foreign key
8.零填充:zerofill => 高位自动补零【若为1号,则以00001形式】
9.自增列(面向数值):auto_increment【组合使用:auto_increment primary key】
10.无符号数值:unsigned【正数】
A、*库的操作:
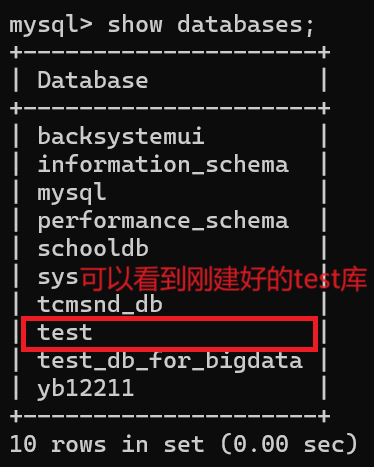
【建】库
语法:create database if not exists 库名;
案例:create database if not exists test;

【查】看所有的库
show databases;
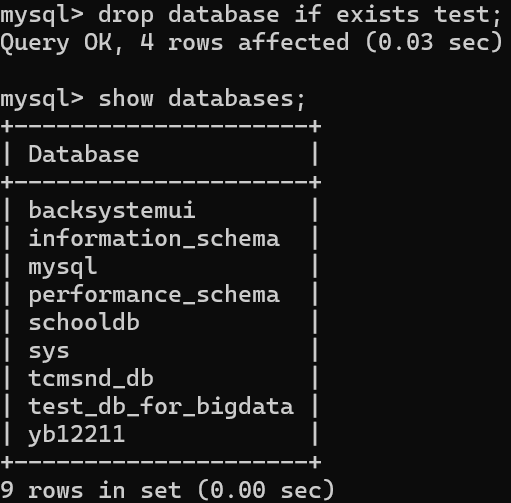
【删】库
语法:drop database if exists 库名;
案例:drop database if exists test;
【进入】库
重点:完成这步之后才可在库里面进行建表等操作。
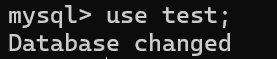
语法:use 库名;
案例:use test;
B、*表的操作:
【建】表
基本语法:
create table TABLE_NAME(
FIELD_NAME字段名 DATA_TYPE1数据类型 CONSTRAINT1约束 (comment '注释'),
FIELD_NAME字段名 DATA_TYPE2数据类型 CONSTRAINT2约束 (comment '注释'),
FIELD_NAME字段名 DATA_TYPE3数据类型 CONSTRAINT3约束 (comment '注释'),
...
);
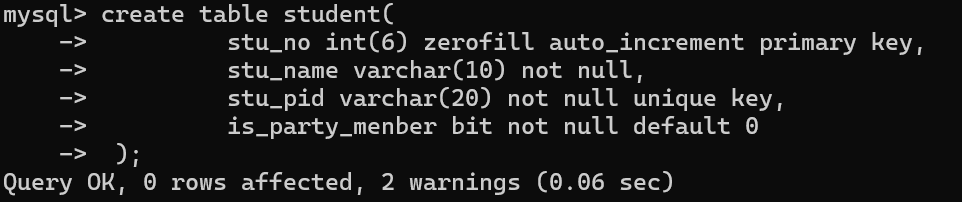
案例:
create table student(
stu_no int(6) zerofill auto_increment primary key,
stu_name varchar(10) not null,
stu_pid varchar(20) not null unique key,
is_party_menber bit not null default 0
);
【查】表
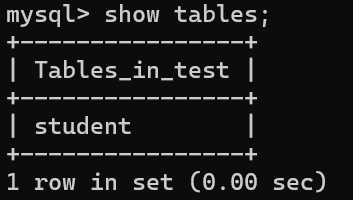
1、显示当前数据库中所有的表
基本语法:show tables;
效果展示:
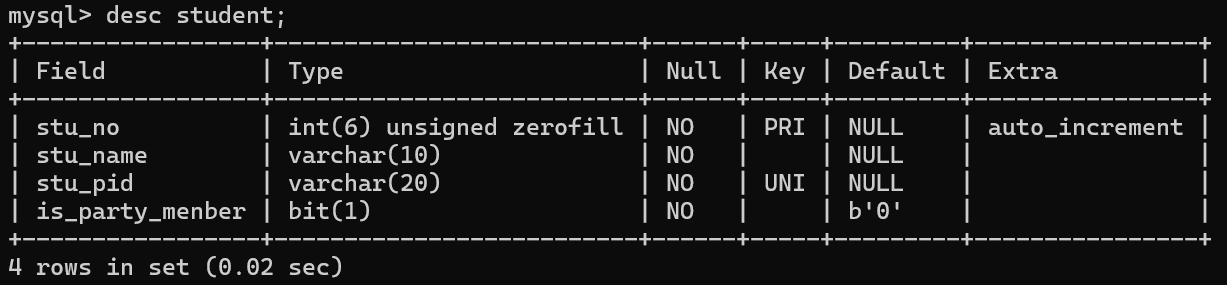
2、展示表结构的结构定义
基本语法:desc 表名;
案例:
desc student;
效果展示:
【改】表
基本语法:alter table 表名;
一般在【表外】添加一个外键的约束:
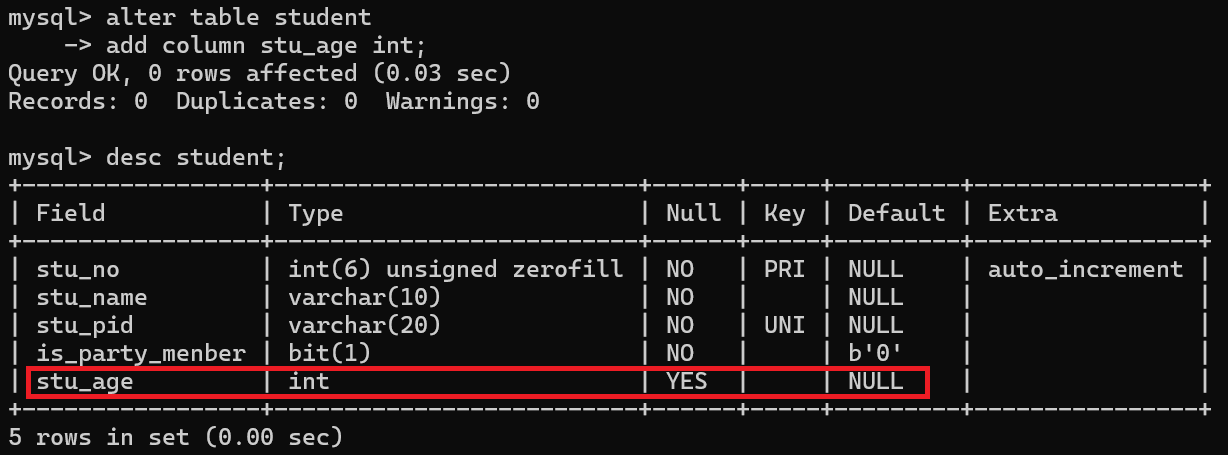
案例:添加stu_age属性,表示学生年龄
alter table student
add column stu_age int;
【删】表
基本语法:drop table if exists 库名.表名
案例:drop table if exists test.student;

DML操作(面向数据级别【增,删,改】)
1.何为DML
对数据进行操作的语言
2.注意点
所有修改与删除都是基于主键,主键不可删改
3.具体操作
*添加数据
基本语法:
insert into TABLE_NAME(FIELD_NAME_1,...,FIELD_NAME_N) values
(VALUE_1,...,VALUE_N)[,(VALUE_1,...,VALUE_N)]\*N;
案例讲解:
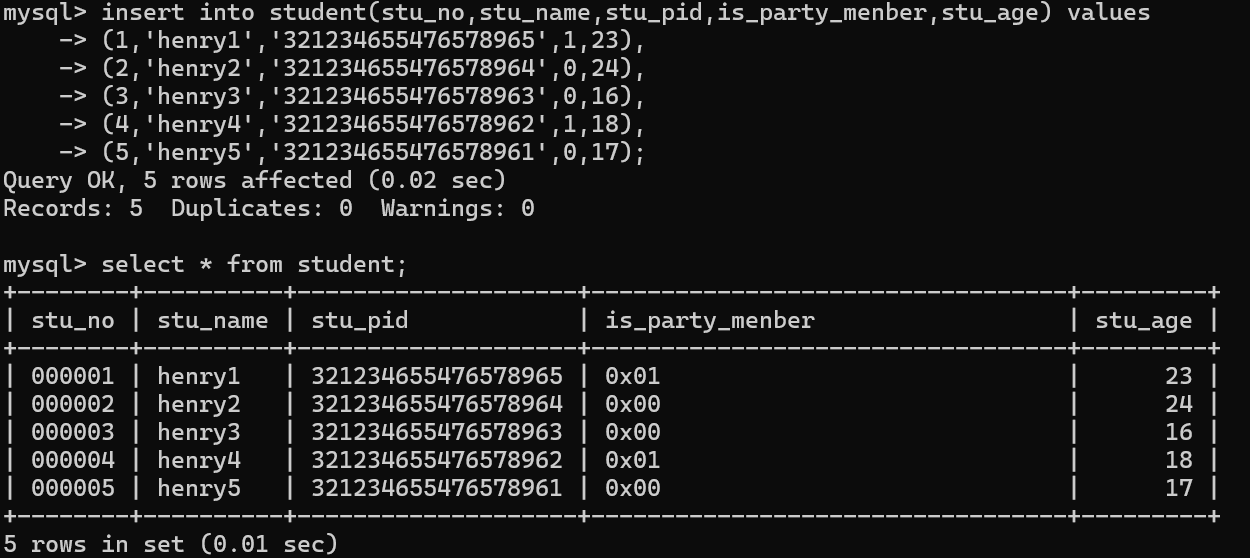
A.常规操作:
insert into student(stu_no,stu_name,stu_pid,is_party_menber,stu_age) values
(1,'henry1','321234655476578965',1,23),
(2,'henry2','321234655476578964',0,24),
(3,'henry3','321234655476578963',0,16),
(4,'henry4','321234655476578962',1,18),
(5,'henry5','321234655476578961',0,17);
B.在两张表之间进行数据的迁移:
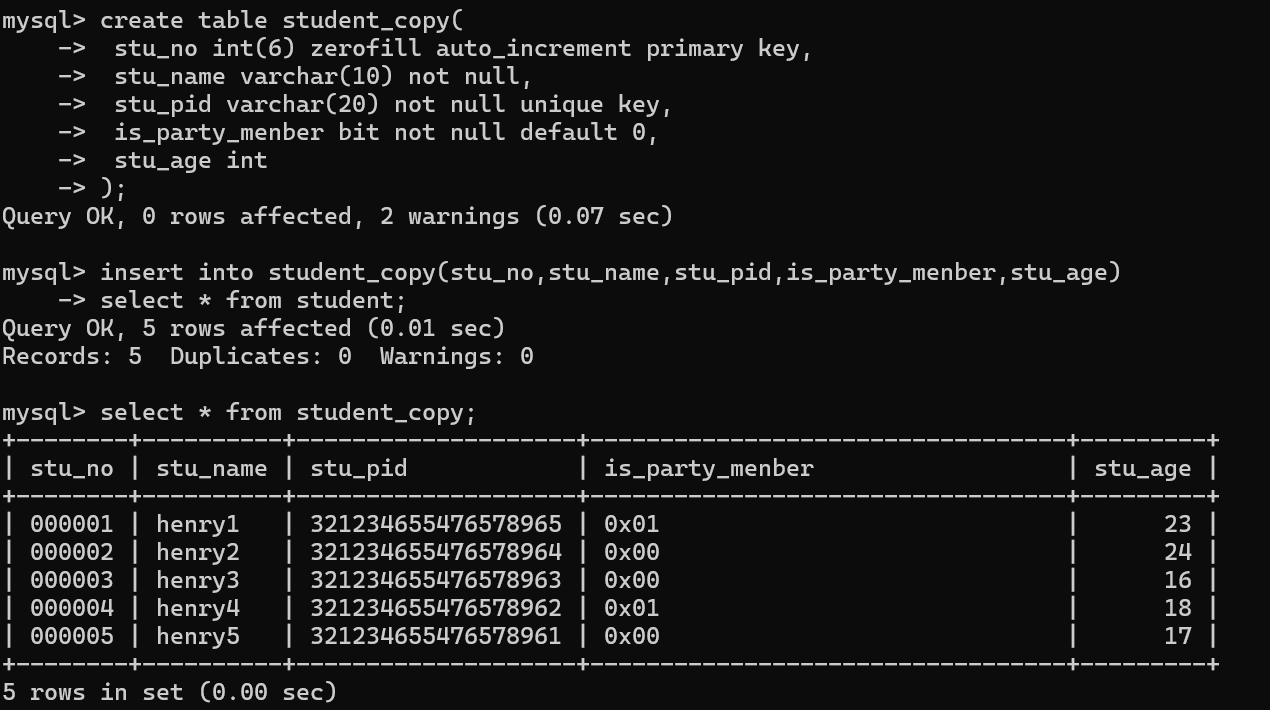
1.建立一个附表:
create table student_copy(
stu_no int(6) zerofill auto_increment primary key,
stu_name varchar(10) not null,
stu_pid varchar(20) not null unique key,
is_party_menber bit not null default 0,
stu_age int
);
2.将数据导进附表
insert into student_copy(stu_no,stu_name,stu_pid,is_party_menber,stu_age)
select * from student;
*修改数据
基本语法:
1、简化描述:update 表明 set 字段名=值 [ where 条件子句 ]
2、具体描述:
update TABLE_NAME
set 字段名_1 = 值1,.....,字段名_N = 值N
where 条件【primary_key|unique_key = VALUE;】
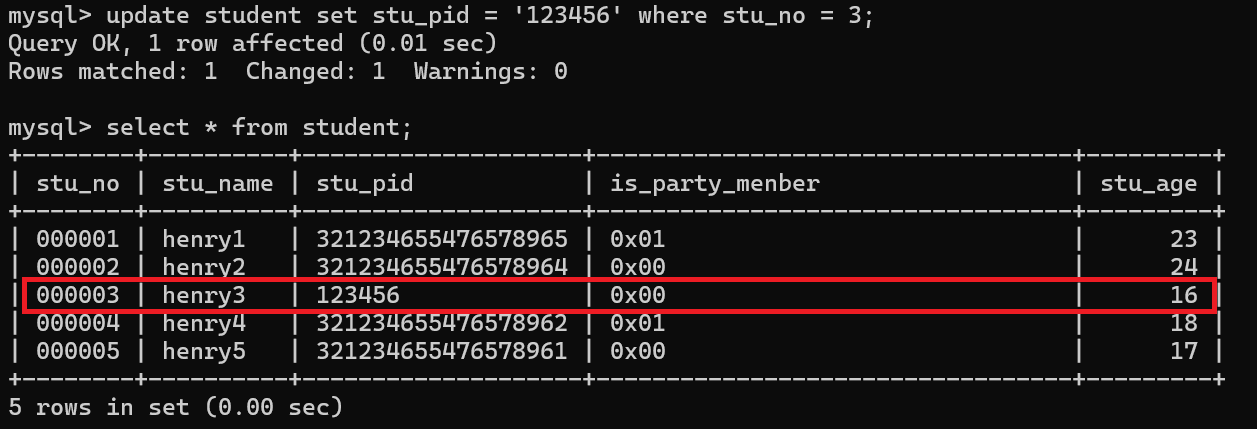
案例:
update student set stu_pid = '123456' where stu_no = 3;
*删除数据
A、delete:
基本语法:
delete from 表名 where 条件【 primary_key|unique_key = VALUE;【最多一次删一条数据】 】
案例:
delete from student_copy where stu_no = 3;
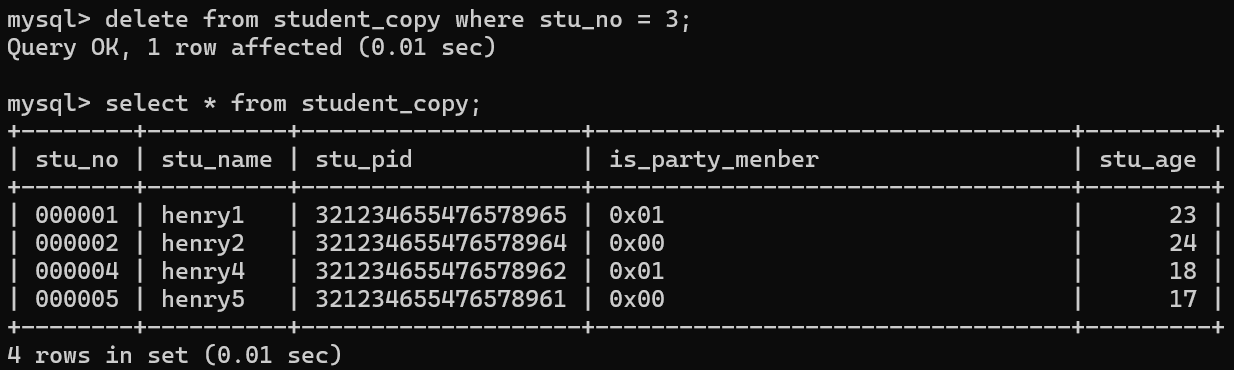
B、truncate:
基本语法:truncate table 表名;
案例:
truncate table student_copy;
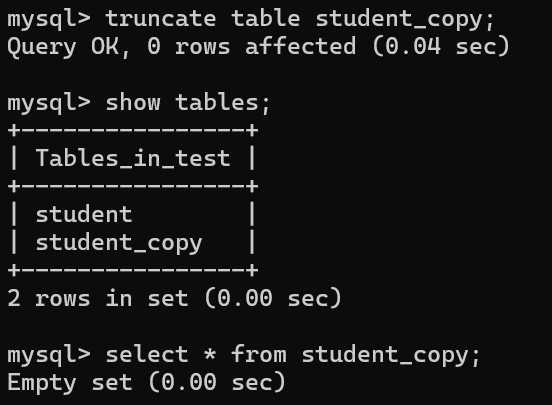
区别:
* delete【可恢复,位置扔占着】
* truncate【不可恢复】
DQL操作(面向数据级别【查】)
A、*简单查询
1、基本语法
select 字段名1 [as] 别名,字段名2 [as] 别名,...
from 表 | 子查询
where 条件
order by 字段名 asc|desc
limit OFFSET,SIZE
说明:limit用于【行区间的裁剪】(分页),不可用于子查询中。其通俗讲解:跳过前 OFFSET 条记录,然后返回接下来的 SIZE 条记录。
2、别名介绍
2.1、解释:
别名就是非表的原始部分
2.2、基本语法:
[as] 表达式别名
【说明】:as可添加,也可不添加
2.3、别名的用处:
表达式字段 => 表达式别名
多表关联 => 表别名
2.4、基本案例:
select stu_name name from student;
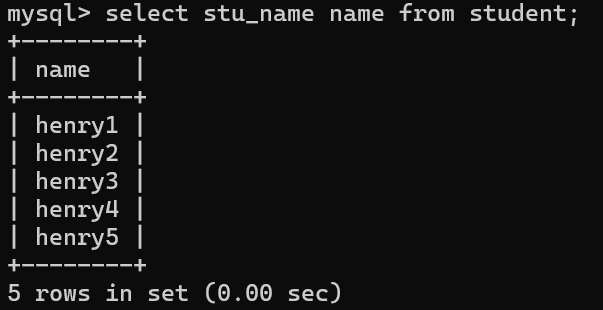
3、where条件格式
名词介绍:
EXP:表达式
VALUE:值
VALUE_BIG: 比较大的值
VALUE_SMALL: 比较小的值
基本格式:
1.等于:EXP【表达式】 = VALUE;
2.不等于:EXP <> VALUE;
3.表字段为空值|不为空:EXP is [not] NULL
4.关系运算符:
EXP >[=] VALUE;
EXP <[=] VALUE;
EXP between VALUE_SAMLL and VALUE_BIG
等同于 EXP >= VALUE_SMALL and EXP <= VALUE_BIG
5.范围:EXP in (VAL_1,...,VAL_N | SUBQUERY)【in为范围,满足在范围中的一个即可】
6.逻辑运算符:
与:and
或:or
非:not
7.模糊查询:【面向字符串】
EXP [not] like '通配符LIKE_EXP'【通配符的位置没有硬性要求】
通配符:
% : 任意个任意内容 【姓张:name like '张%'】
_ : 一个任意内容 【姓张且名字为两个字:name like '张_'】
B、*分页查询
背景介绍
针对student表而言,现有5条数据
pageNumber:页码(哪一页)
pageSize:页容(每一页显示多少条数据)
1、情景一
1.基本语法:
select cell(count(1)/pageSize) from 表名;
案例:
条件:每一页放三条数据,查看一共有几页
语句:select ceil(count(1)/3) as total_page from student;
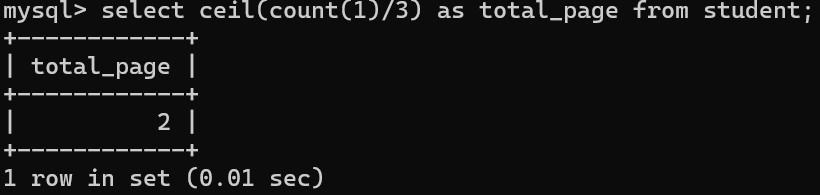
2、情景二
2.基本语法:
select * from 表名 limit (pagenNumber-1)*pageSize,pageSize;
案例:查某一页的数据
条件:查找第一页的数据
语句:select * from student limit 0,3;
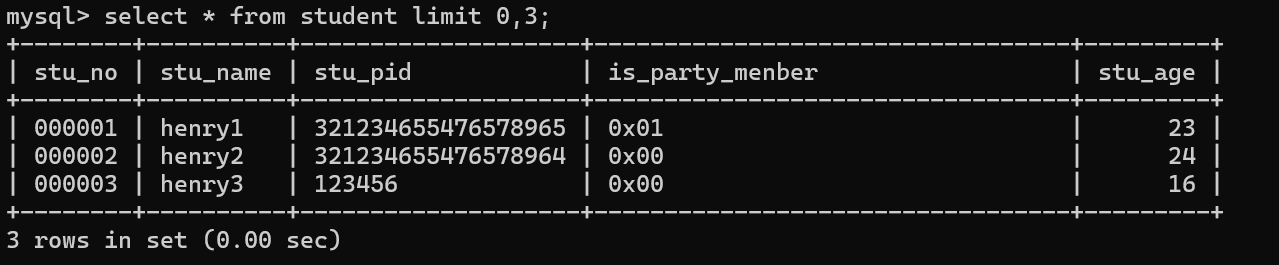
C、*分组聚合查询
1、基本语法:
select 字段名1 [as] 别名,字段名2 [as] 别名,...
from 表 | 子查询
where 条件 针对表的原始行,进行初步的筛选
group by (字段名 as 别名)*N 多字段分组:左为主,右为次
having 条件 针对聚合后的值,进行二次筛选,产生聚合后的新列
order by 字段名 asc|desc
limit OFFSET,SIZE
2.注意点:
group by分组后,SELECT 子句中只能包含【被 GROUP BY 列出的列】或者【聚合函数】,否则,会报错。
D、*子查询
1.基本语法
select 字段名1 [as] 别名,(select...) [as] 别名, ... ✔
from 表 | 子查询 ✔
where 条件【如:exists (select ...)|expA in (select expB ...)】 ✔
group by 字段名
order by 字段名 asc|desc
limit OFFSET,SIZE
【说明】:
一:exp 可以表示为 field【字段】,partof(field)【字段的一部分】,concat(fa,fb,…) 【拼接后的】,cal(field)【数值】,…
二:打✔处,表示可以运用子查询
三:【group by】通常与【聚合函数】一起使用
2.具体讲解
数据准备
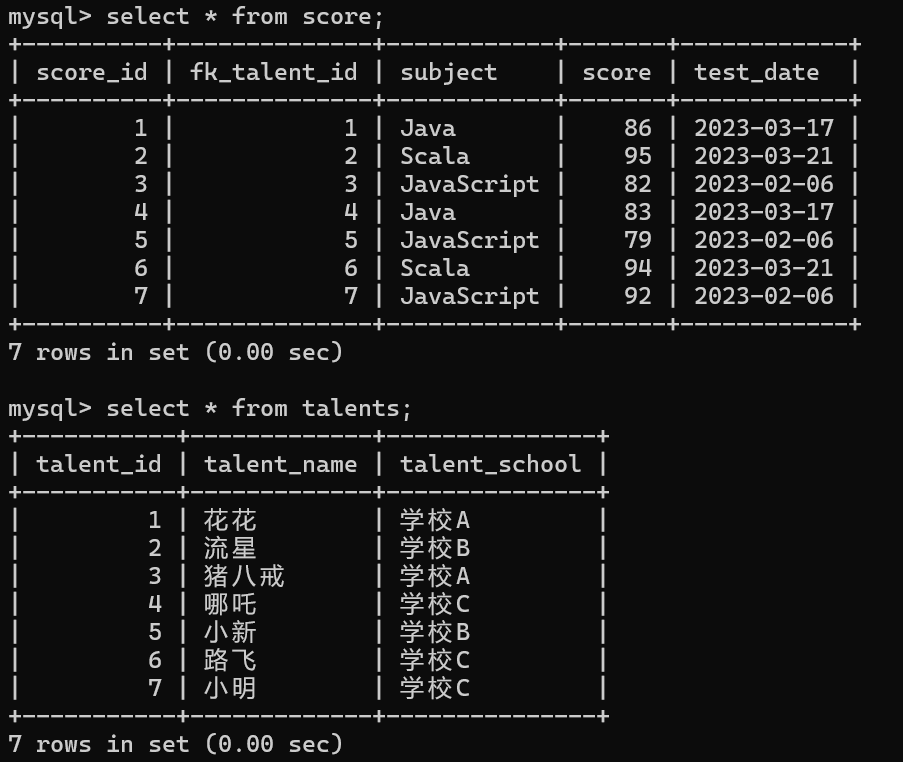
2.1:对于select的子查询
案例(两表联系):
select
fk_talent_id,
(select talent_name from talents where talent_id=fk_talent_id) as talent_name,
subject,
score
from score;

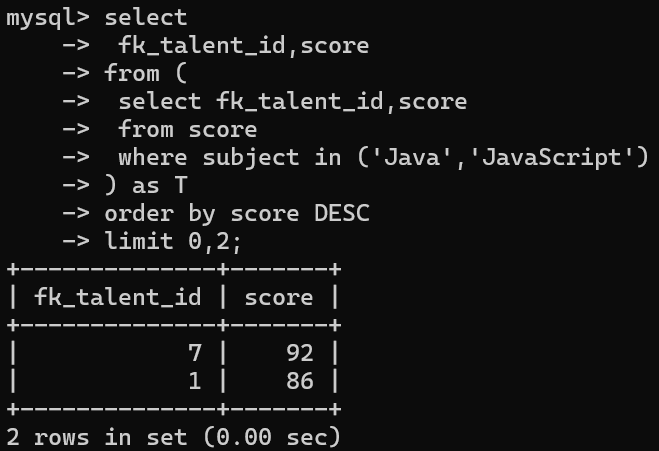
**2.2:对于from的子查询 **
案例(数据表可以由子查询代替):
select
fk_talent_id,score
from (
select fk_talent_id,score
from score
where subject in ('Java','JavaScript')
) as T
order by score DESC
limit 0,2;
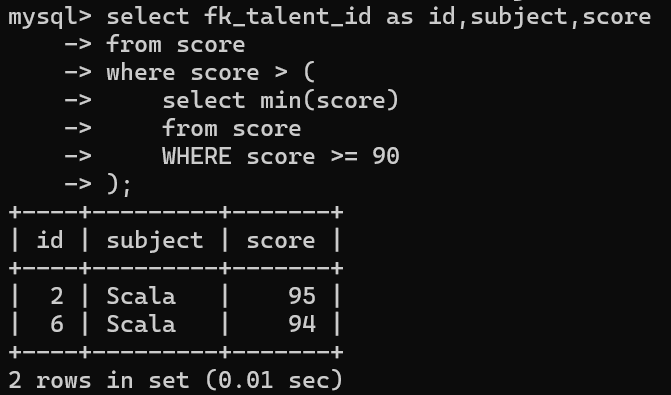
2.3:对于where的子查询
案例:
select fk_talent_id as id,subject,score
from score
where score > (
select min(score)
from score
WHERE score >= 90
);
E、*连接查询
1.原则:即可【子查询】又可【连接查询】,【首选连接查询】
2.解释:
多表联合查询
join:横向拼接表,宽变大
3.操作:
两个主要形式:
1.内连接(交集,两表都有的数据):
基本语法:
select A.内容,....,B.内容,... =>字段别名:提高筛选的性能
from tablea as A
inner join tableb as B
on A.主键=B.外键 (and A.fa = VALUE;) 多表√ 两表√ =>【连接条件】
where A.fa = VALUE; 两表√ =>合并后进行【条件筛选】
2.外连接(全集):
左外连接:【主表全集,主表都展示】
基本语法:
select A.内容,....,B.内容,... =>字段别名:提高筛选的性能
from tablea as M =>左表【主表】
left [outer] join tableb as S =>从表
on M.主键|外键=B.外键|主键 (and A.fa = VALUE;) 多表√ 两表√ =>【连接条件】
where A.fa = VALUE; 两表√ =>合并后进行【条件筛选】
右外连接:【主表全集,主表都展示】
基本语法:
select A.内容,....,B.内容,... =>字段别名:提高筛选的性能
from tablea as M =>从表
right [outer] join tableb as S =>主表
on M.主键|外键=B.外键|主键 (and A.fa = VALUE;) 多表√ 两表√ =>【连接条件】
where A.fa = VALUE; 两表√ =>合并后进行【条件筛选】
全外连接:full join【mysql不支持】
笛卡尔积【典型:比赛时间表】
基本语法:
select A.内容,....,B.内容,... =>字段别名:提高筛选的性能
from tablea as A
cross join tableb as B
on A.主键|外键=B.外键|主键 (and A.fa = VALUE;) 多表√ 两表√ =>【连接条件】
where A.fa = VALUE; 两表√ =>合并后进行【条件筛选】
F、*联合查询
1.解释:
纵向拼接表,高变大
查询字段的数量与类型必须相同,字段名是以第一张表为准。‘
2.union与union all的区分:
联合 UNION:去重,排序,效率低
联合所有 UNION ALL:不去重,不排序,效率高 √
3.相关知识点:行转列与类转行。
案例:
列转行:
方法:使用union all 来合并两个或多个select语句
如:
select stu_name, JavaEE as score,'JavaEE' as subject from temp_wide_score
union all
select stu_name, Hadoop as score,'Hadoop' as subject from temp_wide_score
union all
select stu_name, Spark as score,'Spark' as subject from temp_wide_score
union all
select stu_name, Python as score,'Python' as subject from temp_wide_score
union all
select stu_name, Project as score,'Project' as subject from temp_wide_score;
类转行:
注意:
根据实际需求结合【聚合函数】使用
操作:
方法一:使用case..when..then语句
如:
select user_id,
sum(case when subject='语文' then score end) as '语文',
sum(case when subject='数学' then score end) as '数学',
sum(case when subject='英语' then score end) as '英语'
from tb_score
group by user_id;
方法二:使用if()函数
如:
select user_id,
sum(if(subject='语文',score,0)) as '语文',
sum(if(subject='数学',score,0)) as '数学',
sum(if(subject='英语',score,0)) as '英语'
from tb_score
group by user_id;
















 3614
3614











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









