






前面的基于策略梯度的算法REINFORCE、Actor-Critic以及两个改进算法-TRPO和PPO,它们都是在线策略算法,这意味着它们的样本效率比较低。而之前的DQN算法直接估计最优函数Q,可以做到离线学习,但是它需要从所有动作中选取Q值最大的动作,能处理的动作空间有限,也有局限性。本章要学的深度确定性策略梯度(DDPG)算法,就能很好的解决这些问题。
之前我们学习的策略是随机性的,可以表示为![]() ,而如果策略是确定的,则可以记为
,而如果策略是确定的,则可以记为![]() 。与策略梯度定理类似,我们可以推导出确定性策略梯度定理:
。与策略梯度定理类似,我们可以推导出确定性策略梯度定理: 
其中,π(β)是用来收集数据的行为策略。我们可以这样理解:假设现在已经有函数Q,给定一个状态s,但由于动作空间是无限的,我们无法遍历所有动作来得到Q值最大的动作,因此我们想使用策略μ来帮助我们找到使得Q(s,a)最大的动作a,即![]() 。换个角度想,函数Q就是Critic,μ就是Actor,这是一个Actor-Critic框架,DDPG也属于一种Actor-Critic算法。
。换个角度想,函数Q就是Critic,μ就是Actor,这是一个Actor-Critic框架,DDPG也属于一种Actor-Critic算法。
更新方式与策略梯度定理其实很相近,只不过DDPG使用了经验回放池来训练网络,从而直接预测Q值,通过最大化Q网络的输出,从而最大化状态价值V,而不是使用蒙特卡洛采样计算价值
与DQN算法相同,Actor和Critic两个网络都会有各自的目标网络(因为估计该状态动作对的Q值需要使用参数更新之前的网络,所以我们需要用目标网络来估计Q值)。不过与DQN不同的是,此次目标网络采取软更新的方式,即让目标Q网络缓慢更新,逐渐靠近Q网络,其公式为: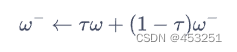
通常τ是一个比较小的数,当τ=1时,DDPG和DQN更新方式就一致了。
还有,由于函数Q同样也会存在Q值过高估计的问题,因此DDPG采用了Double DQN中的技术来更新Q网络。同时,由于DDPG采用确定性策略,它本身的探索也十分有限。DQN算法探索主要由epsilon-贪婪策略产生,而同样作为离线策略方法,DDPG在行为策略上引入一个随机噪声![]() 来进行探索。
来进行探索。
我们采用倒立摆的环境进行试验
导入库
import random
import gym
import numpy as np
import torch
from tqdm import tqdm
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
import rl_utils下面定义策略网络和价值网络,策略网络的输出层用双曲正切函数(y=tanhx)作为激活函数,这是因为双曲正切函数的值域是[-1,1],方便按比例调整成环境可以接受的动作范围。价值网络的输入是状态动作对,即状态和动作拼接后的向量,输出是一个值,表示状态动作对的价值。
class PolicyNet(torch.nn.Module):
def __init__(self,state_dim,hidden_dim,action_dim,action_bound):
super(PolicyNet,self).__init__()
self.fc1=torch.nn.Linear(state_dim,hidden_dim)
self.fc2=torch.nn.Linear(hidden_dim,action_dim)
self.action_bound=action_bound #action_bound是环境可以接受的动作最大值
def forward(self,x):
x=F.relu(self.fc1(x))
#双曲正切函数的值域是[-1,1],乘上action_bound后即成为环境可以接受的动作范围
return torch.tanh(self.fc2(x))*self.action_bound
class QValueNet(torch.nn.Module):
def __init__(self,state_dim,hidden_dim,action_dim):
super(QValueNet,self).__init__()
#这里是输出状态动作对的价值,而根据forward我们可以看出输入的是状态和动作然后拼接,所以输入层的层数应为state_dim+hidden_dim
self.fc1=torch.nn.Linear(state_dim+action_dim,hidden_dim)
self.fc2=torch.nn.Linear(hidden_dim,hidden_dim)
self.fc_out=torch.nn.Linear(hidden_dim,1)
def forward(self,x,a):
cat=torch.cat([x,a],dim=1) #拼接状态和动作
x=F.relu(self.fc1(cat))
x=F.relu(self.fc2(x))
return self.fc_out(x)接下来定义DDPG算法的主体部分,在用策略网络采取动作时我们向动作中加入高斯噪声。
class DDPG:
''' DDPG算法 '''
def __init__(self, state_dim, hidden_dim, action_dim, action_bound, sigma, actor_lr, critic_lr, tau, gamma, device):
self.actor = PolicyNet(state_dim, hidden_dim, action_dim, action_bound).to(device)
self.critic = QValueNet(state_dim, hidden_dim, action_dim).to(device)
self.target_actor = PolicyNet(state_dim, hidden_dim, action_dim, action_bound).to(device)
self.target_critic = QValueNet(state_dim, hidden_dim, action_dim).to(device)
# 初始化目标价值网络并设置和价值网络相同的参数
self.target_critic.load_state_dict(self.critic.state_dict())
# 初始化目标策略网络并设置和策略相同的参数
self.target_actor.load_state_dict(self.actor.state_dict())
self.actor_optimizer = torch.optim.Adam(self.actor.parameters(), lr=actor_lr)
self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), lr=critic_lr)
self.gamma = gamma
self.sigma = sigma # 高斯噪声的标准差,均值直接设为0
self.tau = tau # 目标网络软更新参数
self.action_dim = action_dim
self.device = device
def take_action(self, state):
state = torch.tensor([state], dtype=torch.float).to(self.device)
action = self.actor(state).item()
# 给动作添加噪声,增加探索
action = action + self.sigma * np.random.randn(self.action_dim)
return action
#软更新目标网络
def soft_update(self, net, target_net):
for param_target, param in zip(target_net.parameters(), net.parameters()):
param_target.data.copy_(param_target.data * (1.0 - self.tau) + param.data * self.tau)
def update(self, transition_dict):
states = torch.tensor(transition_dict['states'], dtype=torch.float).to(self.device)
actions = torch.tensor(transition_dict['actions'], dtype=torch.float).view(-1, 1).to(self.device)
rewards = torch.tensor(transition_dict['rewards'], dtype=torch.float).view(-1, 1).to(self.device)
next_states = torch.tensor(transition_dict['next_states'], dtype=torch.float).to(self.device)
dones = torch.tensor(transition_dict['dones'], dtype=torch.float).view(-1, 1).to(self.device)
next_q_values = self.target_critic(next_states, self.target_actor(next_states))
q_targets = rewards + self.gamma * next_q_values * (1 - dones)
critic_loss = torch.mean(F.mse_loss(self.critic(states, actions), q_targets))
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
#在线策略和离线策略的区别在于更新方式不同,在线策略是每次交互都进行计算价值,然后进行网络更新,
#而离线策略是通过经验回放池,然后利用网络加以预测Q值(或者价值),然后进行更新
#同样都是最大化价值为目标,REINFORCE是探索计算出价值然后将其最大化,而DDPG是直接用价值网络预测Q值并且将其最大化,通过最大化每一个Q值从而最大化最终的价值
actor_loss = -torch.mean(self.critic(states, self.actor(states)))
self.actor_optimizer.zero_grad()
actor_loss.backward()
self.actor_optimizer.step()
self.soft_update(self.actor, self.target_actor) # 软更新策略网络
self.soft_update(self.critic, self.target_critic) # 软更新价值网络设置超参数,进行倒立摆试验
actor_lr = 3e-4
critic_lr = 3e-3
num_episodes = 200
hidden_dim = 64
gamma = 0.98
tau = 0.005 # 软更新参数
buffer_size = 10000
minimal_size = 1000
batch_size = 64
sigma = 0.01 # 高斯噪声标准差
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
env_name = 'Pendulum-v1'
env = gym.make(env_name)
random.seed(0)
np.random.seed(0)
env.reset(seed=0)
torch.manual_seed(0)
replay_buffer = rl_utils.ReplayBuffer(buffer_size)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
action_bound = env.action_space.high[0] # 动作最大值
agent = DDPG(state_dim, hidden_dim, action_dim, action_bound, sigma, actor_lr, critic_lr, tau, gamma, device)
return_list = rl_utils.train_off_policy_agent(env, agent, num_episodes, replay_buffer, minimal_size, batch_size)
绘图
episodes_list = list(range(len(return_list)))
plt.plot(episodes_list, return_list)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('DDPG on {}'.format(env_name))
plt.show()
mv_return = rl_utils.moving_average(return_list, 9)
plt.plot(episodes_list, mv_return)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('DDPG on {}'.format(env_name))
plt.show()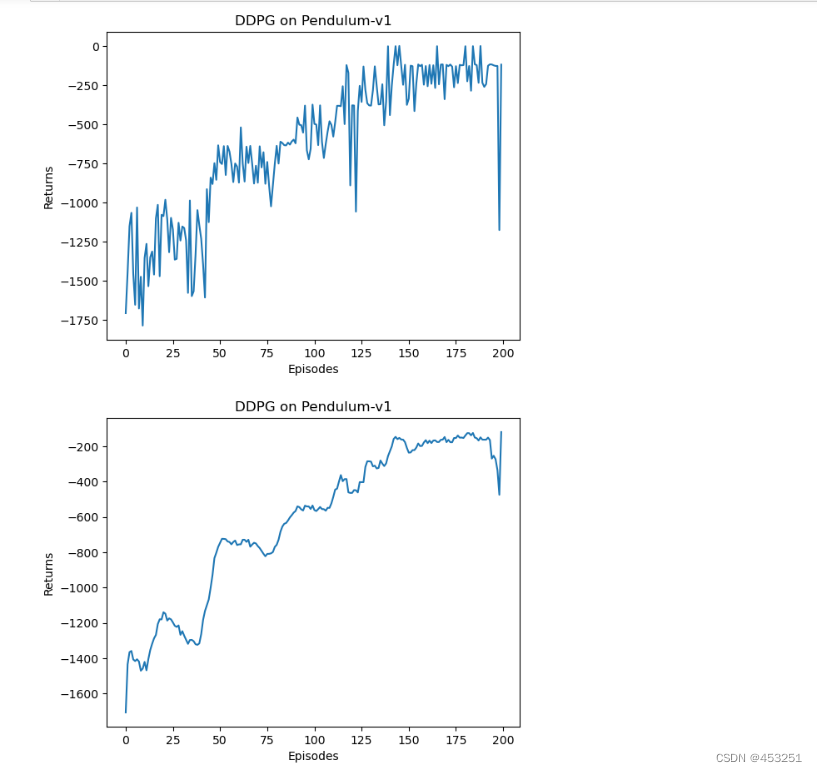
可以发现DDPG算法在倒立摆环境中的效果不错,其学习速度非常快,并且不需要太多样本。















 4553
4553











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









