






注:本文仅为兴趣爱好探究,请勿进行商业利用或非法研究,负责后果自负,与本文作者无关
一.简介
最近遇到了前端解密的一点困难,用python怎么逆向都无法解决,相反用go导包去进行解密反而得到了正确的结果。无奈,刚好本来就有想学go语言的想法,直接进军。
golang相比于python来说,有完整的并发机制,运行速度快,唯一麻烦的就是数据处理起来较为麻烦
废话不多说,开练
二.基本学习
1.简单请求
导包
import ( "net/http" "net/url" )
构造客户端
var client http.Client
get请求
req, err := http.NewRequest("GET",URL,nil)
存储cookie容器
jar err := cookiejar.New(nil)
if err != nil {
panic(err)
}
构造post请求
完整请求如下
var client http.Client
jar err := cookiejar.New(nil)
if err != nil {
panic(err)
}
Info := "user="+username+"&"+"passwd="+password
var data = strings.NewReader(Info)
req, err := http.NewRequest("POST",URL,data)
resp, _ := client.Do(req)
bodyText, _ := ioutil.ReadAll(resp.Body)
请求头可以如此添加
req.Header.Set("Connection", "keep-alive")
req.Header.Set("Pragma", "no-cache")
req.Header.Set("Cache-Control", "no-cache")
req.Header.Set("Upgrade-Insecure-Requests", "1")
req.Header.Set("Content-Type", "application/x-www-form-urlencoded")
req.Header.Set("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36")
req.Header.Set("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9")
req.Header.Set("Accept-Language", "zh-CN,zh;q=0.9")
当发送请求结束之后,cookie会自动保存在client.jar这个容器内
myStr := fmt.Sprintf("%s",client.Jar)
req.Header.Set("Cookie",myStr)
强制转换进行添加
2.解析网页
python的时候习惯了xpath,这里我们依旧还是xpath,有很多种解析的,像什么正则这些,只需要把其中一个方向的精通即可,当然,正则还是可以练练的,毕竟以后可能会有很多的用武之地
https://github.com/antchfx/htmlquery
这里讲一下golang导包的技巧,一般来说直接go get即可
大多数时候你创建的项目根目录下需要
go mod init <模块名> 然后引入github对应模块地址 go mod tidy go mod vendor
当然更大多数时候,目标网站都是被墙了的
windows的话建议可以直接在安装到环境变量gopath src目录下

external library可以直接看到
解析方法
root, _ := htmlquery.Parse(resp.Body)
3.获取节点信息
tr := htmlquery.Find(root, "//*[@id='LB_kb']/table/tbody/tr/td") //使用Xpath进行结点信息的获取
for _, row := range tr { //len(tr)=13
classNames := htmlquery.Find(row, "./font")
classPosistions := htmlquery.Find(row,"./text()[4]")
classTeachers := htmlquery.Find(row,"./text()[5]")
if len(classNames)!=0 {
className = htmlquery.InnerText(classNames[0])
classPosistion = htmlquery.InnerText(classPosistions[0])
classTeacher = htmlquery.InnerText(classTeachers[0])
fmt.Println(className)
fmt.Println(classPosistion)
fmt.Println(classTeacher)
}
}
接下来还有存取数据库的一些操作,这里不进行讲解,毕竟我们只是单纯爬成文档即可
三.实战演练
这里我们爬取的目标是豆瓣top250的电影
1.效果展示

还是分成了四块,电影title,描述,评分以及评论
大致思路就是用容器保存数据最后交给csvwriter进行写入
不足的地方就是->无多线程,没有陷入数据库
需要用到的库
github.com/antchfx/htmlquery
2.粗略讲解

保存函数

xpath语法
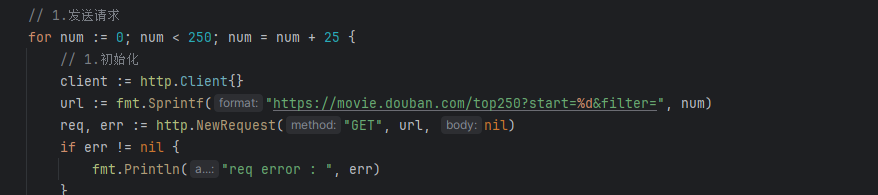
翻页逻辑

存储逻辑
接下来将会给大家带来更多的go实战项目
源码请关注公众号 剑客古月的安全屋
原文链接 爬虫实训-golang爬虫+项目实战
回复 豆瓣spider















 1579
1579











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









