






- 实验目的
了解Linux操作系统基本操作、网络配置和Hadoop平台安装配置方法,理解大数据平台的运行基础。
- 实验内容
- 安装至少3台虚拟机的一个集群
- 配置集群网络
- 在集群中安装Hadoop并配置
- 成功启动Hadoop
- 测试HDFS命令
(1) 在HDFS根目录中创建一个Files目录
(2) 在Linux中创建两个文件(或在Windows中创建文件并传至Linux节点),将其上传至HDFS中的/Files目录
(3) 在HDFS中执行ls命令查看/Files目录中的内容
- 实验步骤
- Centos的安装
- 网络配置
- 安装jdk和hadoop
四、实验结果
我用的wifi,把wifi共享给VMnet1
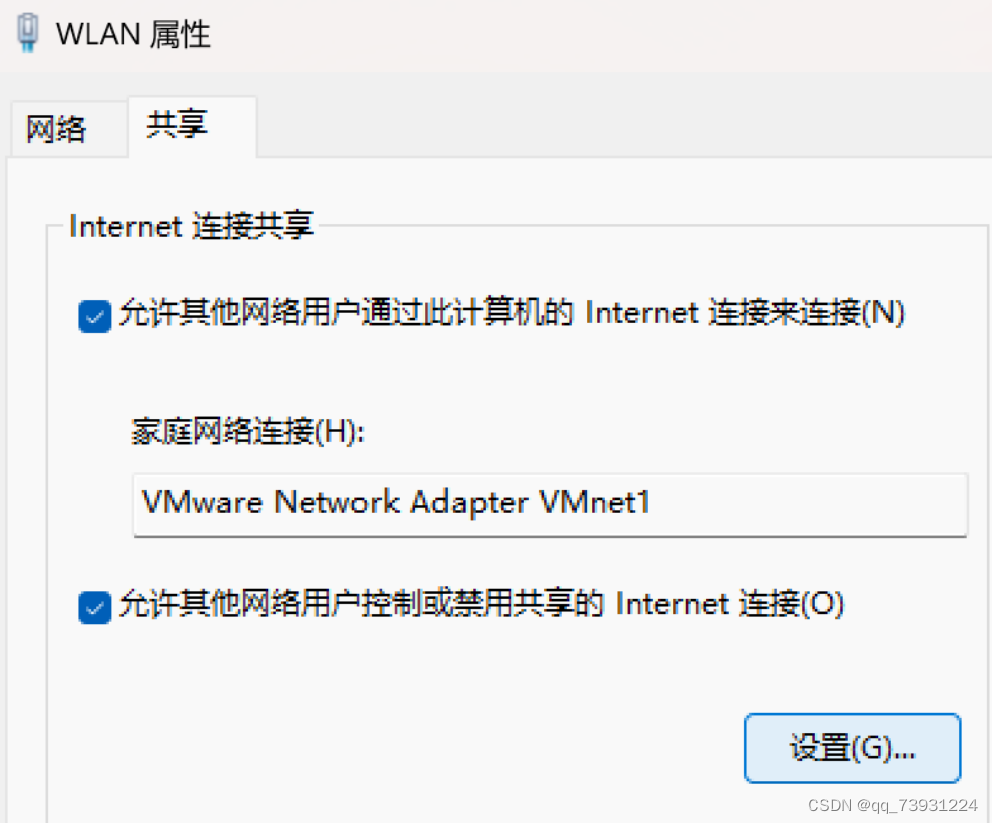
IP地址自动变成192.168.137.1

为了避免后面ping网站时被防火墙阻拦,所以先直接关了

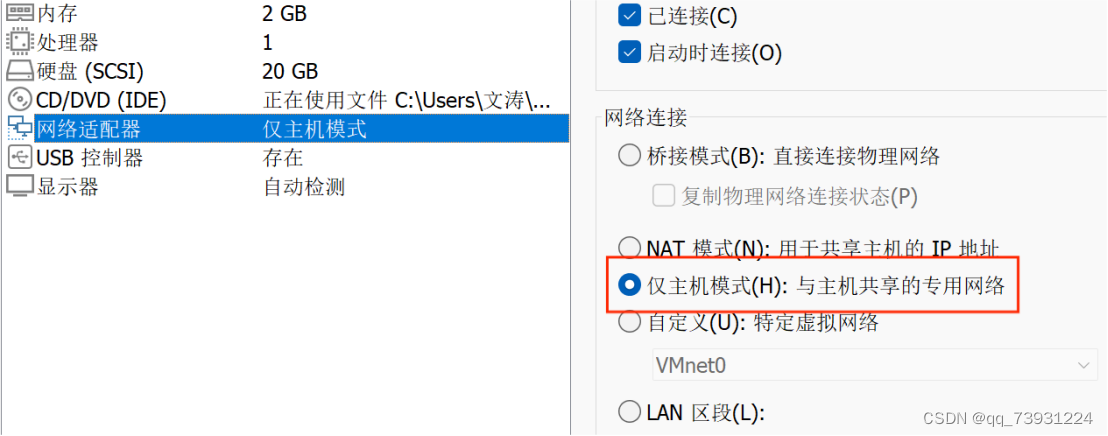
虚拟机网络模式选择仅主机模式
cd /etc/sysconfig/network-scripts进入对应目录
ll命令查看网卡名 vi ifcfg-ens33进入编辑

修改BOOTPROTO为static 表示使用静态IP
修改ONBOOT为yes 表示开机启动配置
增加IPADDR=192.168.137.2 实际地址须与GATEWAY在同一网段
增加NETMASK=255.255.255.0 代表不划分子网
增加GATEWAY=192.168.137.1 即刚才设置共享网络后的IP地址

修改DNS
vi /etc/resolv.conf进行编辑,这里的DNS我用的61.139.2.69,114.114.114.114和8.8.8.8在我的虚拟机上都ping不通。之前用的183.221.253.100,这个ip虽然能ping通,但是在ping www.baidu.com或者www.sina.com等用域名的网站时ping不通,如果ping他们对应的ip地址则可以ping通,所以最后换成61.139.2.69,ping网站就可以直接ping通了

配置完后用service network restart重启网络服务

再克隆两个当前虚拟机作为从节点,要选择完全克隆,克隆之后要去vi ifcfg-ens33编辑ipaddr,每个节点的ip是不同的,我node2节点的ip为192.168.137.3,node3节点的ip为192.168.137.4

修改主机名
vi /etc/hostname,把原本有的内容全部删除,写入node1

hostname显示主机名,这样就修改好了

还要修改host映射文件
命令:vi /etc/hosts
编辑主机和ip地址的映射,只留下面的内容

安装ifconfig
先搜索命令ifconfig命令的名称是什么
命令:yum search ifconfig
然后再安装
命令:yum intstall net-tools
安装后可以通过ifconfig查看虚拟机的网络信息

尝试ssh登录
命令:ssh root@192.168.137.3 远程登录我的node2,登陆成功,这个时候还不能免密登录,需要输入密码

再登录一下我的node3节点,IP地址为192.168.137.4,与前面的映射相对应

命令:exit 退出ssh
网络配置完成
开始设置SSH免密登录
命令:vi /etc/ssh/sshd_config
增加这两条配置即可

生成密钥对
1.命令:ssh-keygen -t rsa 生成key,不用输入密码,一直回车,生成密钥对放在 ~/.ssh 目录(ls -al可查看)
2.将主节点上的公钥发到其他所有节点(包括主节点自己)
id_rsa.pub是公钥文件,将公钥文件内容复制到authorized_keys文件,并复制到其他节点的~/.ssh目录
命令:cd ~/.ssh 进入到.ssh目录
命令:cat id_rsa.pub>> authorized_keys
命令:scp -r authorized_keys root@node2:~/.ssh/authorized_keys 将公钥文件复制到其他节点,节点名以具体设置的名称为准
命令:scp -r authorized_keys root@node3:~/.ssh/authorized_keys
3.检查ssh
命令:ssh node1(检查自己)
命令:ssh node2(检查其他节点)
命令:ssh node3
此时登录不需要密码,完成免密登录

下载安装JDK
我宿主机原本的jdk版本是17,所以linux我也安装的jdk17。但是建议不要装太高版本,后面实验可能会不支持,而且太高版本jdk会导致使用jps命令时,与yarn相关的resourcemanager等不显示
再宿主机上同时下载jdk-17-linux-x64.tar.gz和jdk-17-windows-x64.exe,虚拟机和宿主机要安装相同版本的JDK
再使用putty传输压缩文件,putty设置如下,192.168.137.2是node1的ip,port选择22,连接类型为ssh,在default settings输入ip后,注意点save保存,这样不用每次都输入。


使用putty连接时可能会出现remote side unexpected closed network-connection错误,或者是使用xshell传输文件时出现Connection closed by foreign host. Disconnected from remote host错误
这时需要vi /etc/ssh/sshd_config ,找到如下两行,我的ClientAliveInterval (ClientAliveInterval 参数数值是秒 , 是指超时时间 , 这里设置的是一分钟)之前默认设置的是0,所以连接失败,这里的CLientAliveCountMax我没有修改。修改之后就可以连接上了。

压缩文件都上传到了root下

解压文件时尽量使用tab辅助补齐,自己有可能拼错
命令:tar -zxvf jdk-17.0.11_linux-x64_bin.tar.gz
命令:mv jdk-17.0.11 /home/ 将解压后的目录移动至指定目录

配置环境变量
命令:vi /etc/profile
在profile文件下面追加写入下面信息:
export JAVA_HOME=/home/jdk-17.0.11 JDK实际的安装目录

命令:source /etc/profile 使配置文件生效,一定要先使用这个命令
命令:java -version 若能显示版本则JDK安装配置完成,否则检查前面的步骤是否正确,这里正确显示java version

下载安装Hadoop
在宿主Windows中下载了,通过PuTTY上传到Linux

文件解压
- 命令:tar -zxvf hadoop-3.1.2.tar.gz
- 命令:mkdir /home/hadoop
然后再将解压后的目录移动至想要放置的位置, mv hadoop-3.1.2 /home/hadoop/hadoop-3.1.2
在/home/hadoop目录下创建数据存放的文件夹,tmp、dfs、dfs/data、dfs/name
命令:cd /home/hadoop
mkdir tmp mkdir dfs mkdir dfs/data mkdir dfs/name

配置hadoop-env.sh
Vi /home/hadoop/hadoop-3.1.2/etc/hadoop/hadoop-env.sh,添加这一行

配置core-site.xml
Vi /home/hadoop/hadoop-3.1.2/etc/hadoop/core-site.xml 编辑如下内容

配置hdfs-site.xml
Vi /home/hadoop/hadoop-3.1.2/etc/hadoop/hdfs-site.xml 编辑如下内容

配置mapred-site.xml
Vi /home/hadoop/hadoop-3.1.2/etc/hadoop/mapred-site.xml 编辑如下内容

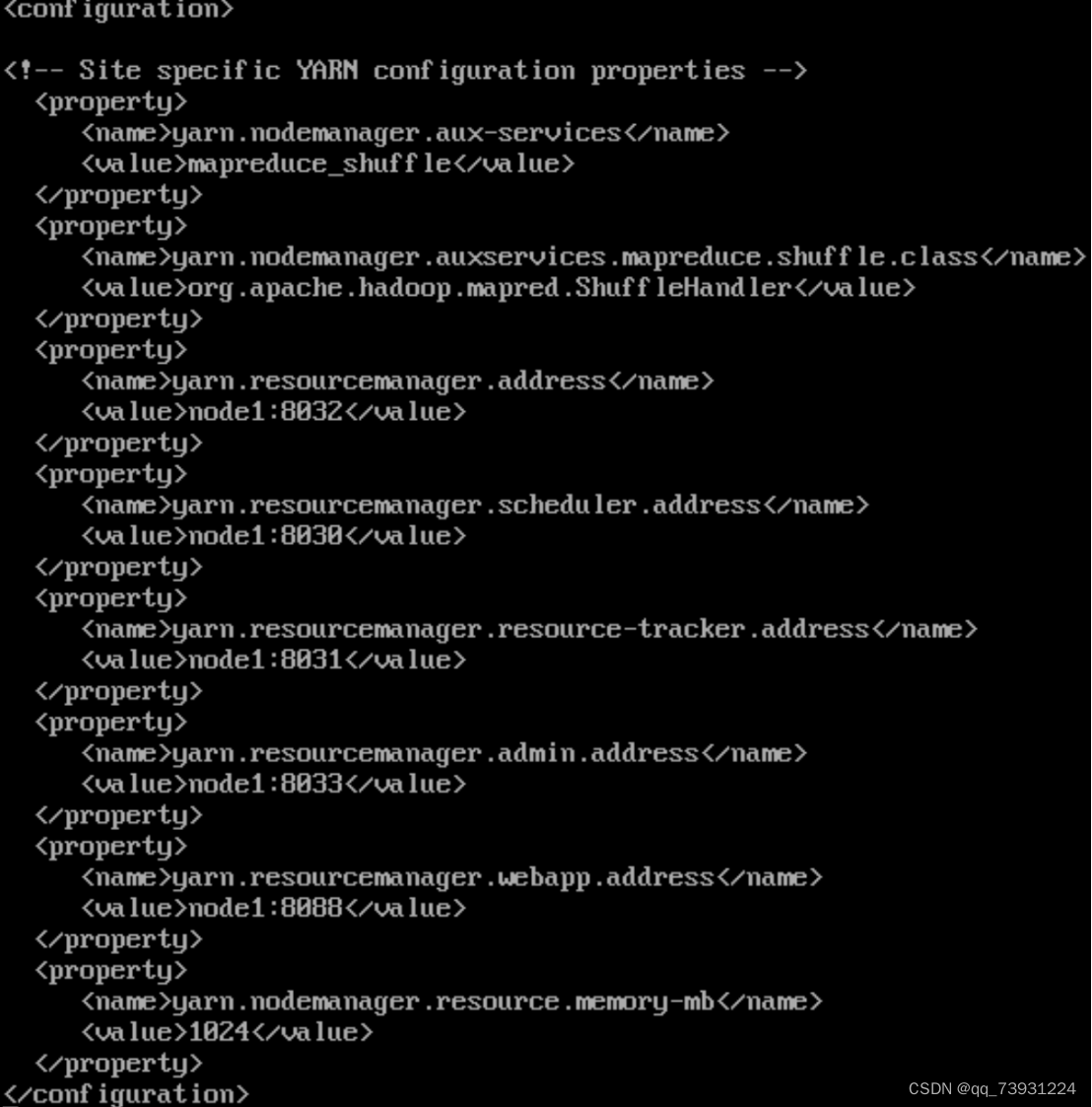
配置yarn-site.xml
Vi /home/hadoop/hadoop-3.1.2/etc/hadoop/yarn-site.xml 编辑如下内容
配置yarn-env.sh的JAVA_HOME
Vi /home/hadoop/hadoop-3.1.2/etc/hadoop/yarn-env.sh
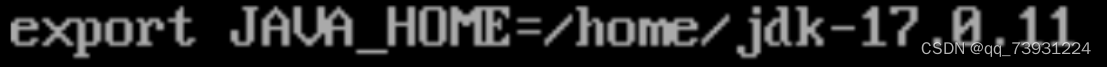
配置Hadoop命令环境变量
命令:vi /etc/profile
在profile文件下面追加写入下面信息:

执行命令:source /etc/profile 环境变量即生效
配置workers,删除默认的localhost
命令:vi //home/hadoop/hadoop-3.1.2/etc/hadoop/workers
配置了works的节点才会有DataNode守护进程,主机名以实际名称为准,也可以为IP地址。

将JDK、profile和Hadoop复制到各个节点对应位置上,通过scp传送,
直接拷贝即可,不要更改任何配置文件,所有节点上的配置文件都是一样的
scp -r /home/jdk1.8.0_211 node2:/home/
scp -r /home/jdk1.8.0_211 node3:/home/
scp -r /etc/profile node2:/etc/
scp -r /etc/profile node3:/etc/
scp -r /home/hadoop node2:/home/
scp -r /home/hadoop node3:/home/
(1)初始化,在主节点输入命令:bin/hdfs namenode -format
注意不要随意执行format
(2)全部启动sbin/start-all.sh,也可以分开sbin/start-dfs.sh、sbin/start-yarn.sh,停止服务,输入命令,sbin/stop-all.sh
提示:there is no HDFS_NAMENODE_USER defined,则添加用户
vi sbin/start-dfs.sh
vi sbin/stop-dfs.sh
在顶部空白处添加内容:

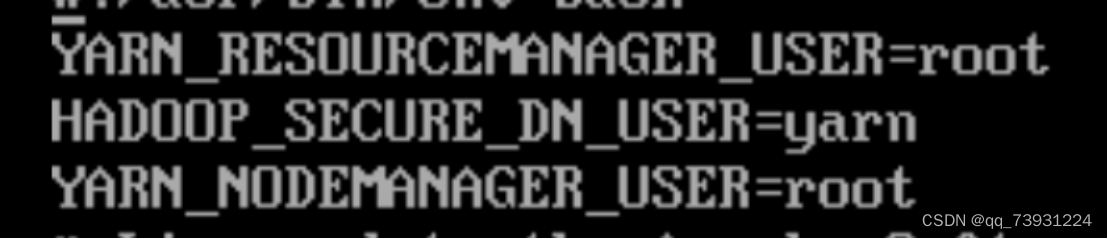
提示:ERROR: there is no YARN_RESOURCEMANAGER_USER defined.,则添加用户
vi sbin/start-yarn.sh
vi sbin/stop-yarn.sh
关闭防火墙
命令:systemctl stop firewalld.service 停止firewall
命令:systemctl disable firewalld.service 禁止firewall开机启动
三个节点都要关闭,不然启用Hadoop进行操作时会报错

















 981
981

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











