






一、引言
在了解逻辑回归之前,要先认识到什么是回归问题,什么又是分类问题!
1.1 回归问题和分类问题的区别
他们都是监督学习中的两大类问题,主要区别在于输出变量的类型和预测目标的不同。
- 回归问题的输出变量是连续性变量,而分类问题的输出变量则是离散型变量。
- 回归问题的目的是为了预测或者估计一个数值,如房价、股票价格等等;而分类问题则是将获得的输入数据划分为不同的类别,如判断邮件是否为垃圾邮件、识别图片中的对象等等。
- 回归问题和分类问题是监督学习中的两大类问题,它们的主要区别在于输出变量的类型和预测目标的不同。
逻辑回归是一种广泛应用于分类问题的机器学习算法,特别是在二分类问题中。尽管它的名字包含“回归”,但它实际上是一种分类方法,用于估计一个实例属于某个特定类别的概率。
1.2 逻辑回归与线性回归的区别
-
线性回归:用于预测一个连续的数值,例如房价或体重。它通过建立一个线性模型来预测输出值,模型形式通常是
,其中
y是预测值,x是输入特征,是权重,
b是偏差。 -
逻辑回归:用于分类问题,预测概率(通常是二分类中的正类概率)。它通过使用Sigmoid函数将线性回归的输出映射到0和1之间,模型形式通常为
其中 p 是预测的概率,是权重,
b 是偏差。
二、 逻辑回归算法原理
2.1 Sigmoid函数
公式:
自变量为任意实数,值域为[0,1]。
下图给出了Sigmod 函数在不同坐标尺度下的两条曲线图。当 x 为 0 时,Sigmoid 函数值为 0.5 。随着x的增大,对应的Sigmoid值将逼近于 1 ; 而随着 x 的减小,Sigmoid 值将逼近于 0 。如果横坐标刻度足够大(如图5-1所示 ),Sigmoid 函数看起来很像一个阶跃函数。
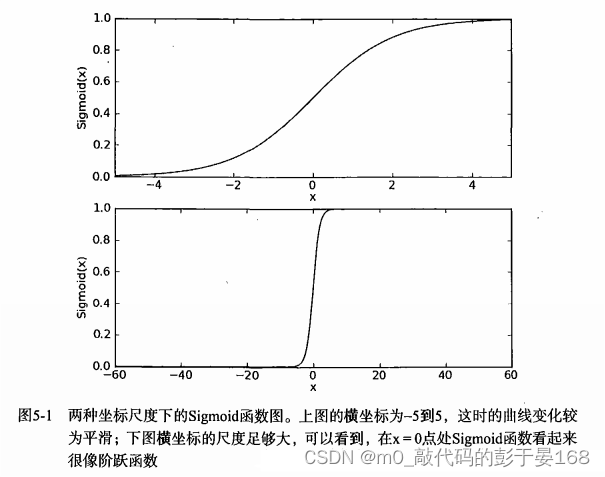
为了实现Logistic回归分类器,我们可以在每个特征上都乘以一个回归系数,然后把所有的结果值相加,将这个总和代入Sigmoid函数中,进而得到一个范围在0~1之间的数值。任何大于0.5的数据被分入1类,小于0.5即被归入0类。所以,Logistic回归也可以被看成所示一种概率估计。
在具体的逻辑回归问题时,z通常是输入变量的线性组合,可以表示为 。其中,
是模型的权重(系数),
是输入变量的值。
2.2 基于最优化方法的最佳系数确定
训练模型的过程中,通过最大化似然函数来估计模型的权重。似然函数是一个关于模型参数的函数,表示给定模型中样本的Galvan。在逻辑回归中,似然函数可以表示为
其中,是第i个样本的特征线性组合,
是对应的类别标签(0或1,此处指二分类问题)。
为了最大化似然函数,下面将会用梯度下降算法来更新模型的权重。梯度下降算法是通过反复迭代来最小化损失函数,直到找到最优解。
梯度下降算法的基本思想是:选择一个初始参数值,然后逐步调整这些参数,以减少损失函数的值。每次调整的幅度由损失函数相对于参数的梯度(即导数)和学习率(learning rate)的参数决定。梯度指向损失函数增长最快的方向,因此沿着梯度的反方向调整参数将会减少损失函数的值。
损失函数通常是使用对数损失函数(log loss)来衡量模型的性能。对数损失函数可以表示为:
其中,是第
个样本的线性组合,
是对应样本的类别标签。
最后,根据上述确定好的最佳系数来训练模型。训练模型后,我们可以使用模型来预测新样本的类别标签,预测类别标签的方法是,将新样本的特征向量代入Sigmoid函数,计算出该样本点的概率,如果概率大于0.5,则预测为正例(类别1);反之,则预测为负例(类别0)。
三、LogisticRegression算法实现
3.1 导入库包
对于逻辑回归来说,我们主要引入的库有:
-
NumPy:用于进行数值计算,包括矩阵运算、数组操作等。用到的包有:
numpy -
Pandas:用于数据处理,如读取数据、数据清洗、数据预处理等。用到的包有:
pandas -
scikit-learn:提供了一个广泛的机器学习算法集合,包括逻辑回归。用到的包是:sklearn.datasets,用于导入训练需要的数据集。
-
Matplotlib :用于数据可视化,可以帮助理解数据和模型性能。用到的包是:
matplotlib
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split3.2 Sigmoid函数
# Sigmoid函数
def sigmoid(z):
return 1 / (1 + np.exp(-z))3.3 创建逻辑回归模型
3.3.1 初始化参数
对于逻辑回归使用的公式为,该算法的核心就是得到最佳系数
,为此我们定义两个参数,分别为权重
和偏值
。
# 初始化模型参数
self.weights = np.random.randn(X.shape[1])
self.bias = 03.3.2 正向传播
我们现在是用逻辑回归处理鸢尾花数据集的二分类问题,因此我们希望可以得到对应样本点的概率,则将计算结果送到Sigmoid函数中得到对应概率值,公式如下所示:
# 计算sigmoid函数的预测值 y_hat = w * x + b
y_hat = sigmoid(np.dot(X, self.weights) + self.bias)3.3.3 损失函数
损失函数(Loss Function)是机器学习中的关键概念,用于量化模型预测值与真实值之间的不一致程度。在训练过程中,损失函数的目的是指导模型如何调整参数以减少这种不一致性,从而提高模型的预测准确性。对于二分类问题,我们通常使用二元交叉熵损失(Binary Cross-Entropy)。
我们这里使用损失函数(Loss Function)来不断优化最佳系数。在每次迭代中,模型通过计算损失函数来确定当前参数下的预测误差。然后,通过梯度下降优化算法,根据损失函数的梯度来调整模型参数,以减少损失值。损失函数的公式上面有提到是:
# 计算损失函数
loss = (-1 / len(X)) * np.sum(y * np.log(y_hat) + (1 - y) * np.log(1 - y_hat))3.3.4 反向传播
我们先通过正向传播计算模型的预测值和损失函数的值。然后,再通过反向传播来计算损失函数相对于每个权重参数的导数,以便于参数的更新。我们使用梯度下降算法来更新权重参数,使损失函数最小化。
# 计算梯度
dw = (1 / len(X)) * np.dot(X.T, (y_hat - y))
db = (1 / len(X)) * np.sum(y_hat - y)
# 更新参数
self.weights -= self.learning_rate * dw
self.bias -= self.learning_rate * db3.3.5 模型预测
对于逻辑回归,为了得到对应样本的类别,我们需要将最后计算出的概率二值化。如果大于0.5,将其转化为类别1,小于0.5则转化为类别0。并在模型训练后,用准确率来评估模型。
# 预测
def predict(self, X):
y_hat = sigmoid(np.dot(X, self.weights) + self.bias)
y_hat[y_hat >= 0.5] = 1
y_hat[y_hat < 0.5] = 0
return y_hat
# 精度
def score(self, y_pred, y):
accuracy = (y_pred == y).sum() / len(y)
return accuracy3.3.6 LogisticRegression模型(完整代码)
# 逻辑回归算法
class LogisticRegression:
# 定义迭代次数和学习率 得到最佳系数
def __init__(self, learning_rate=0.003, iterations=100):
self.learning_rate = learning_rate # 学习率
self.iterations = iterations # 迭代次数
def fit(self, X, y):
# 初始化模型参数
self.weights = np.random.randn(X.shape[1])
self.bias = 0
# 梯度下降优化算法
for i in range(self.iterations):
# 计算sigmoid函数的预测值, y_hat = w * x + b
y_hat = sigmoid(np.dot(X, self.weights) + self.bias)
# 计算损失函数
loss = (-1 / len(X)) * np.sum(y * np.log(y_hat) + (1 - y) * np.log(1 - y_hat))
# 计算梯度
dw = (1 / len(X)) * np.dot(X.T, (y_hat - y))
db = (1 / len(X)) * np.sum(y_hat - y)
# 更新参数
self.weights -= self.learning_rate * dw
self.bias -= self.learning_rate * db
# 打印损失函数值
if i % 10 == 0:
print(f"Loss after iteration {i}: {loss}")
# 预测
def predict(self, X):
y_hat = sigmoid(np.dot(X, self.weights) + self.bias)
y_hat[y_hat >= 0.5] = 1
y_hat[y_hat < 0.5] = 0
return y_hat
# 精度
def score(self, y_pred, y):
accuracy = (y_pred == y).sum() / len(y)
return accuracy# 逻辑回归算法
class LogisticRegression:
# 定义迭代次数和学习率 得到最佳系数
def __init__(self, learning_rate=0.003, iterations=100):
self.learning_rate = learning_rate # 学习率
self.iterations = iterations # 迭代次数
def fit(self, X, y):
# 初始化模型参数
self.weights = np.random.randn(X.shape[1])
self.bias = 0
# 梯度下降优化算法
for i in range(self.iterations):
# 计算sigmoid函数的预测值, y_hat = w * x + b
y_hat = sigmoid(np.dot(X, self.weights) + self.bias)
# 计算损失函数
loss = (-1 / len(X)) * np.sum(y * np.log(y_hat) + (1 - y) * np.log(1 - y_hat))
# 计算梯度
dw = (1 / len(X)) * np.dot(X.T, (y_hat - y))
db = (1 / len(X)) * np.sum(y_hat - y)
# 更新参数
self.weights -= self.learning_rate * dw
self.bias -= self.learning_rate * db
# 打印损失函数值
if i % 10 == 0:
print(f"Loss after iteration {i}: {loss}")
# 预测
def predict(self, X):
y_hat = sigmoid(np.dot(X, self.weights) + self.bias)
y_hat[y_hat >= 0.5] = 1
y_hat[y_hat < 0.5] = 0
return y_hat
# 精度
def score(self, y_pred, y):
accuracy = (y_pred == y).sum() / len(y)
return accuracy3.4 数据集预处理
3.4.1 获取数据集
为了训练模型,我们使用的数据是从Python库中自带的鸢尾花数据集中获取的。
鸢尾花数据集(Iris dataset)是一个非常著名的多类分类问题数据集。它包含150个样本,分为三个类,每个类50个样本。每个样本包含四个特征:花萼长度(sepal length)、花萼宽度(sepal width)、花瓣长度(petal length)和花瓣宽度(petal width),这些特征的单位是厘米。三个类分别是山鸢尾(Iris setosa)、变色鸢尾(Iris versicolor)和维吉尼亚鸢尾(Iris virginica)。
因为我们这里要用逻辑回归算法处理二分类问题,而鸢尾花数据集有三个类别,因此要对数据集进行处理:将类别1归为1类,类别2和类别3归为0类。
# 导入鸢尾花数据集
iris = load_iris()
# 提取前两个特征(花萼长度和花萼宽度)作为特征集X
X = iris.data[:, :2]
# 将目标类别转换为 类别0 或 类别1 的二分类问题
y = (iris.target != 0) * 1
3.4.2 划分数据集
这里我们将获取的数据集划分为训练集和测试集,用于训练和测试创建的LogisticRegression模型。
# 划分训练集、测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.15, random_state=seed_value)3.5 模型训练和评估
# 训练模型
model = LogisticRegression(learning_rate=0.03, iterations=1000)
model.fit(X_train, y_train)
# 结果
y_train_pred = model.predict(X_train)
y_test_pred = model.predict(X_test)
# 模型评估 用 "准确率" 作为评估指标
score_train = model.score(y_train_pred, y_train)
score_test = model.score(y_test_pred, y_test)
print('训练集Accuracy: ', score_train)
print('测试集Accuracy: ', score_test)3.6 可视化决策边界
为了更直观的感受逻辑回归对于二分类问题的处理,我们利用matplotlib包编写可视化决策边界的代码。通过结果可视化的方式,来加深我们的理解。
# 可视化决策边界
x1_min, x1_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5
x2_min, x2_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5
xx1, xx2 = np.meshgrid(np.linspace(x1_min, x1_max, 100), np.linspace(x2_min, x2_max, 100))
Z = model.predict(np.c_[xx1.ravel(), xx2.ravel()])
Z = Z.reshape(xx1.shape)
# 指定字体为Microsoft YaHei
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
# 正常显示负号
# plt.rcParams['axes.unicode_minus'] = False
plt.contourf(xx1, xx2, Z, cmap=plt.cm.Spectral)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Spectral)
plt.xlabel("花萼长度")
plt.ylabel("花萼宽度")
plt.title("逻辑回归 鸢尾花数据集")
plt.show()3.7 代码结果展示
对于创建的逻辑回归模型,我们已经通过鸢尾花数据集进行了模型训练并进行逻辑回归的处理,接下来我们就通过可视化决策边界来看看逻辑回归模型分类的效果,决策边界可视化图如下所示:
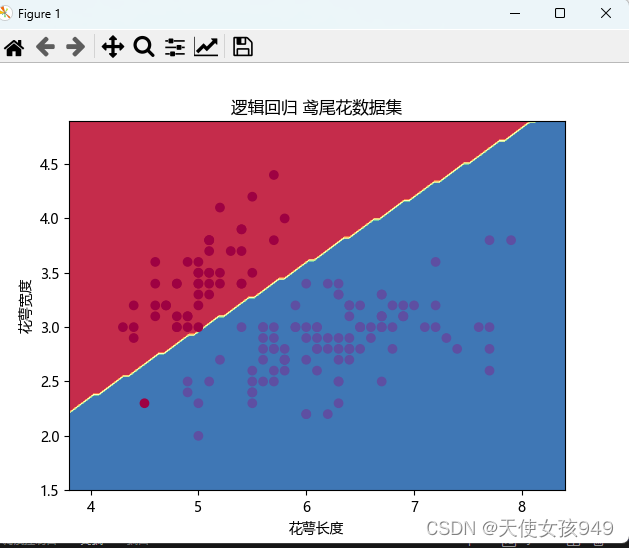
该模型的准确率评估指标结果如下所示: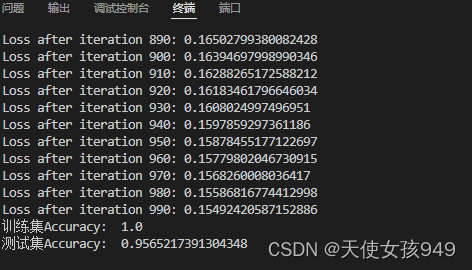















 732
732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









